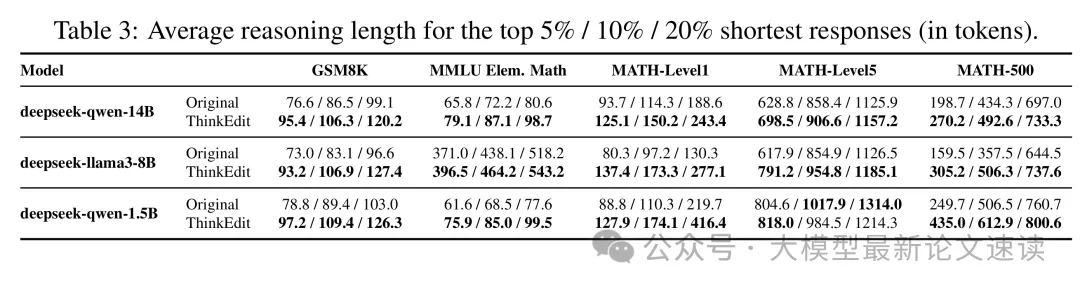
1.简介

流程就是:


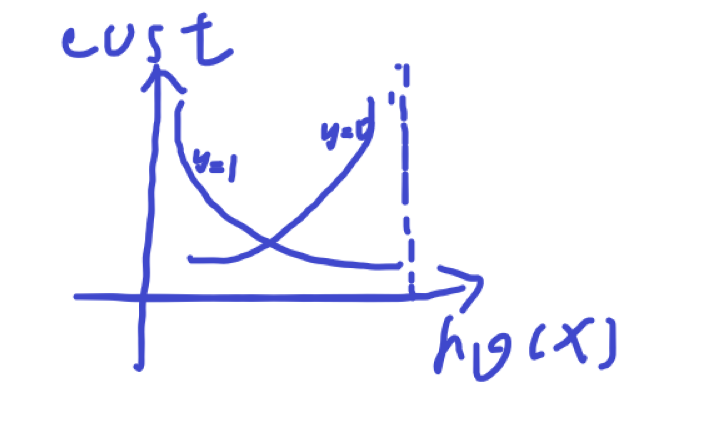

就是我们希望回归后激活函数给出的概率越是1和0.
2.API介绍
sklearn.linear_model.LogisticRegression 是 scikit-learn 库中用于实现逻辑回归算法的类,主要用于二分类或多分类问题。以下是对其重要参数的详细介绍:
2.1. API函数
sklearn.linear_model.LogisticRegression(solver='liblinear', penalty='l2', C = 1.0)
因为逻辑回归是先回归再使用激活函数,所以也涉及过拟合问题,所以后边会有正则化以及处罚力度。
2.2. 参数说明
- solver:用于优化问题的算法,可选参数为
{'liblinear', 'sag', 'saga', 'newton - cg', 'lbfgs'}。- 默认值:
'liblinear'。对于小数据集,'liblinear'是不错的选择 。 - 大数据集适用:
'sag'和'saga'对于大型数据集计算速度更快。 - 多类问题处理:对于多类问题,只有
'newton - cg'、'sag'、'saga'和'lbfgs'可以处理多项损失;'liblinear'仅限于 “one - versus - rest”(一对多)分类 。
- 默认值:
- penalty:指定正则化的种类 。通过对模型参数进行约束,防止模型过拟合。常见的正则化类型如
'l1'(lasso回归)、'l2'等(岭回归),不同类型对参数的约束方式有差异。 - C:正则化力度的倒数 。默认值:
1.0。C 值越小,正则化力度越强,模型越倾向于简单化,防止过拟合;C 值越大,正则化力度越弱,模型复杂度可能更高 。
2.3. 其他特性
- 默认将类别数量少的当做正例。
LogisticRegression方法相当于SGDClassifier(loss="log", penalty=" "),即损失函数是对数似然损失的回归,(这个api是回归里的api,默认是最小二乘法,是Day09里的)SGDClassifier实现了普通的随机梯度下降学习,而LogisticRegression(实现了SAG,随机平均梯度法 )在一些情况下能更高效地收敛,尤其对于大规模数据。
3.肿瘤预测案例


import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
import ssl
# 解决SSL验证问题
ssl._create_default_https_context = ssl._create_unverified_context
# 1.获取数据
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",
names=names)
# 2.基本数据处理
# 2.1 缺失值处理
data = data.replace(to_replace="?", value=np.NaN)
data = data.dropna()
# 2.2 确定特征值,目标值
x = data.iloc[:, 1:10]
y = data["Class"]
# 2.3 分割数据
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 3.特征工程(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.机器学习(逻辑回归)
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 5.模型评估
y_predict = estimator.predict(x_test)
print("预测结果:", y_predict)
score = estimator.score(x_test, y_test)
print("模型得分:", score)names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape', 'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin', 'Normal Nucleoli', 'Mitoses', 'Class'] data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data", names=names)从提供的链接读取数据集时,若不指定
names,默认会将文件第一行数据当作列名,但该数据集可能无此默认列名信息,通过手动指定names列表,能准确对应各列含义,方便后续基于列名进行数据处理、特征提取等操作 。
提出疑问: 我们仅仅考虑准确率是不行的,我们相比准确率更加关注的是在所有样本中,是否能把所有是癌症患者检测出来,这是我们很关注的,所以评估分类模型还有一下评估办法也很重要(KNN也可以用)
4.分类模型评估方法

labels和target_names对应是为了让结果显示的更加容易观察。
但是有如下问题:如果我们有99个癌症,1个非癌症,不管如何预测为癌症,这样的话预测准确率就是99%,这样好吗,这个模型如果在其他数据上会出大错,因为全部预测为了癌症哈哈哈,这就是样本不均衡问题,一会我们会讲样本不均衡数据该怎么样做到样本均衡但是现在我们要看其他的评估指标来用于样本不均衡问题:
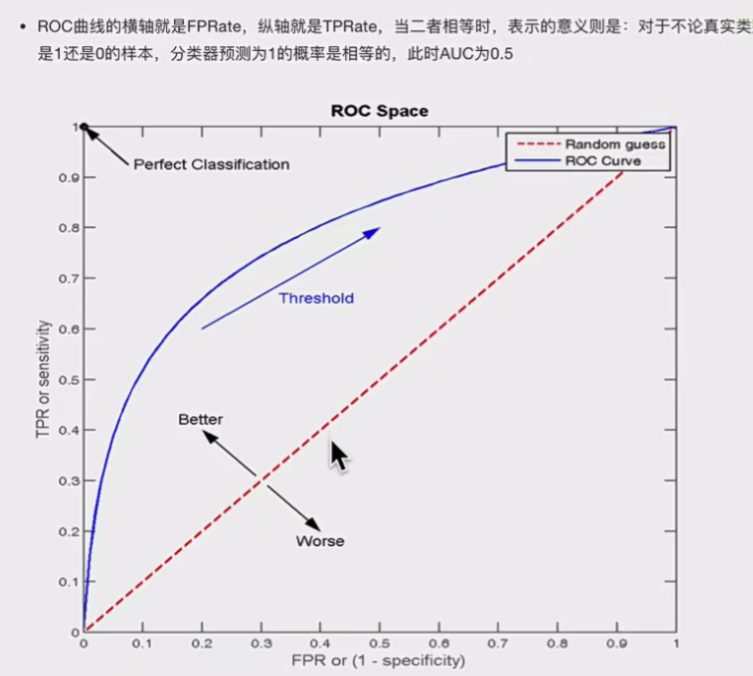
TPR就是召回率,就是模型识别正确能力,FPR就是模型识别错误的能力,下一节会详解ROC曲线是如何绘制的。

即AUC=0.5,模型就是瞎蒙
总结:

5.AUC如何绘制
就是你给我传入真实值(y_test)和预测值(y_pre),让它们一一对应起来,逻辑回归其实会转化概率,即每个预测值都会带有一个概率,我们让这些成对数据按照概率排序(概率仅用来排序,而具体的概率数值并不直接影响TPR和FPR的计算)
然后从第一个开始,我们将每个对预测结果都视为正(其实不一定为正),将原本的正/0进行比对,带入混淆矩阵,计算TRP与FRP作为一对,依次绘图即可:
比如原始真实数据是:![]()
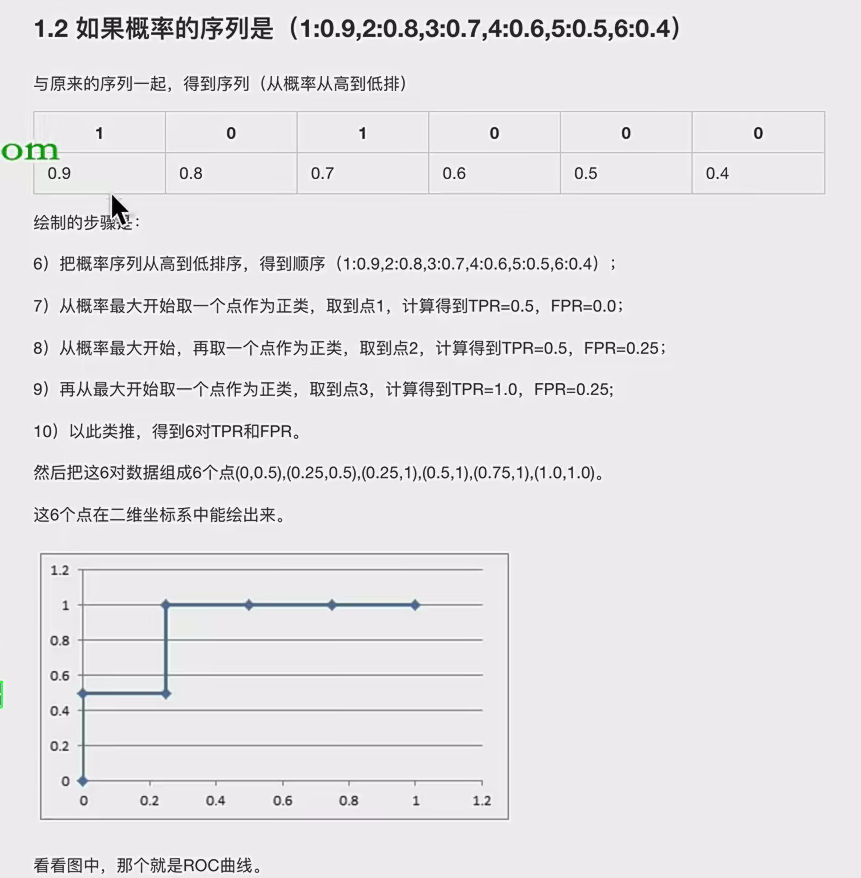
可以看到概率仅仅是排序作用,你正值概率越高,就会越排在前面,这样的话计算的TRP就会越接近1,而FPR就是0,这样的话ROC曲线就越靠近左上,效果越好,模型做的越好,因为损失小(正值概率越高,假值概率越低),这就是为什么ROC越靠左上越好。概率对ROC曲线的影响。而且每次计算都是将预测值视为正值,带入混淆矩阵,即:
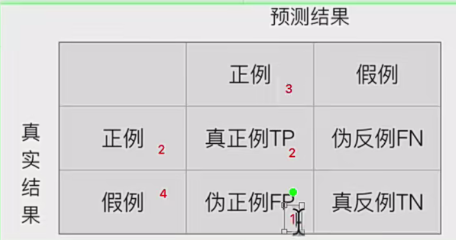
每次选取总是会填在预测结果的第一列(均视为正例),实际是什么决定天真第几行。
看我想到的一些深远的问题:
1.概率问题:正值概率越高,就会越排在前面,这样的话计算的TRP就会越接近1,而FPR就是0,这样的话ROC曲线就越靠近左上,效果越好,模型做的越好,因为损失小(正值概率越高,假值概率越低),所以ROC看重的是排序能力。
2.阈值不影响ROC绘制:

6.对于类别不平衡数据处理
6.1准备:
python中lmblearn库专门用来处理类别不平衡问题 。
1. 类别不平衡问题概述
类别不平衡是指数据集中不同类别的样本数量差异很大的情况。一个三分类问题,其中:
类别0: 64个样本(1.28%)
类别1: 262个样本(5.24%)
类别2: 4674个样本(93.48%)
这种极端不平衡会导致模型偏向多数类,忽视少数类。
2. 创建不平衡数据集
使用datasets库里的
make_classification函数创建人工不平衡数据集:from sklearn.datasets import make_classification import matplotlib.pyplot as plt # 创建5000个样本,2个特征,3个类别的不平衡数据集 X, y = make_classification( n_samples=5000, n_features=2, # 特征总数 n_informative=2, # 有意义的特征数 n_redundant=0, # 冗余特征数 n_repeated=0, # 重复特征数 n_classes=3, # 类别数 n_clusters_per_class=1, # 每个类别的簇数 weights=[0.01, 0.05, 0.94], # 各类别比例 random_state=0 # 随机种子 )特征总数需要等于后面的有意义,冗余,重复特征数3. 查看类别分布
使用
Counter函数可以查看各类别样本数量:from collections import Counter print(Counter(y)) # 输出: Counter({2: 4674, 1: 262, 0: 64})
6.2处理办法