本节代码定义了一个 CMN 类,它继承自 PyTorch 的 Dataset 类,用于处理英文和中文的平行语料库。这个类的主要作用是将文本数据转换为模型可以处理的格式,并进行必要的填充操作,以确保所有序列的长度一致。
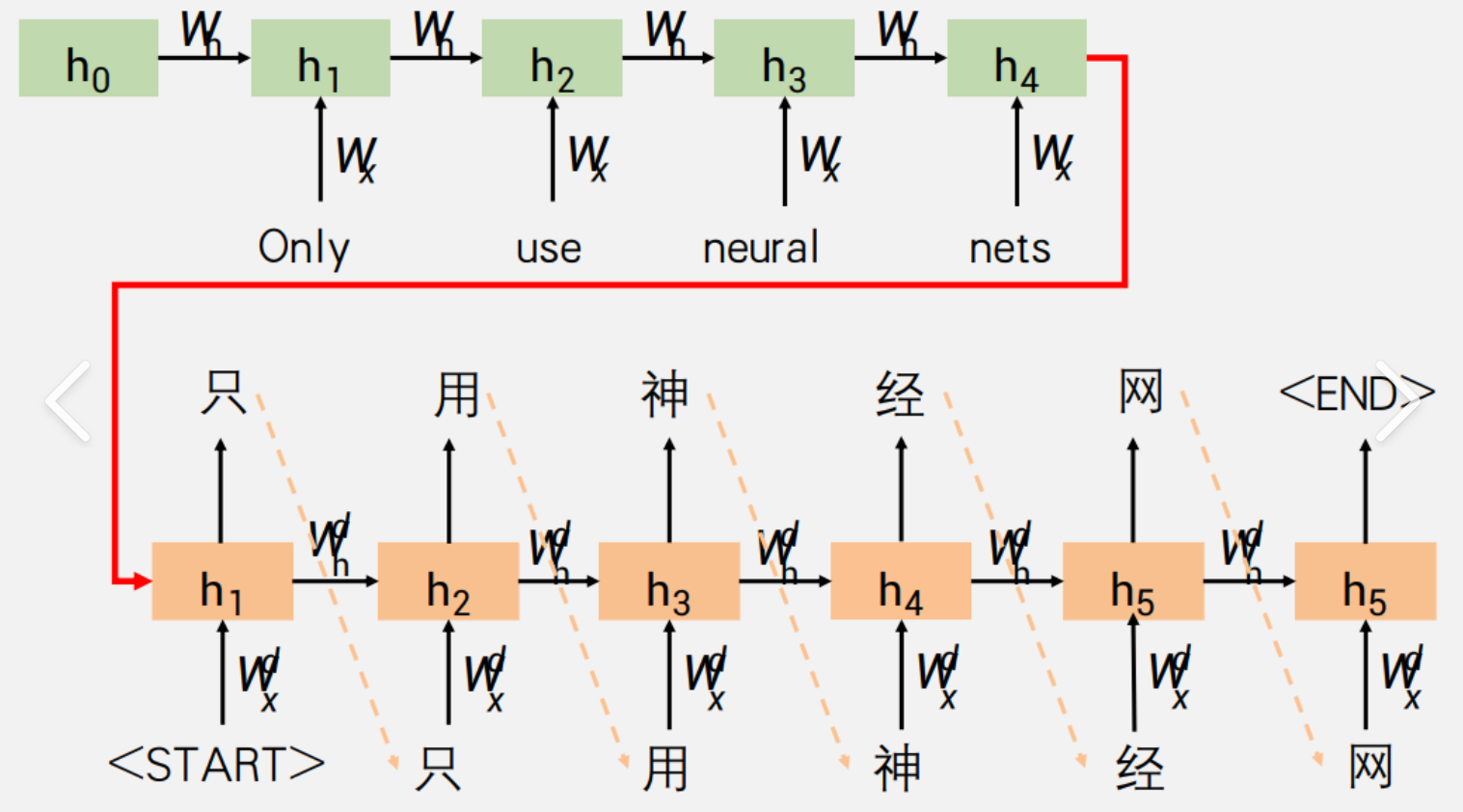
⭐重写Dataset类是模型训练的重中之重请务必掌握!
重写时格式固定为三件套 __init__ __len__ __getitem__重点记忆!
1. 类定义
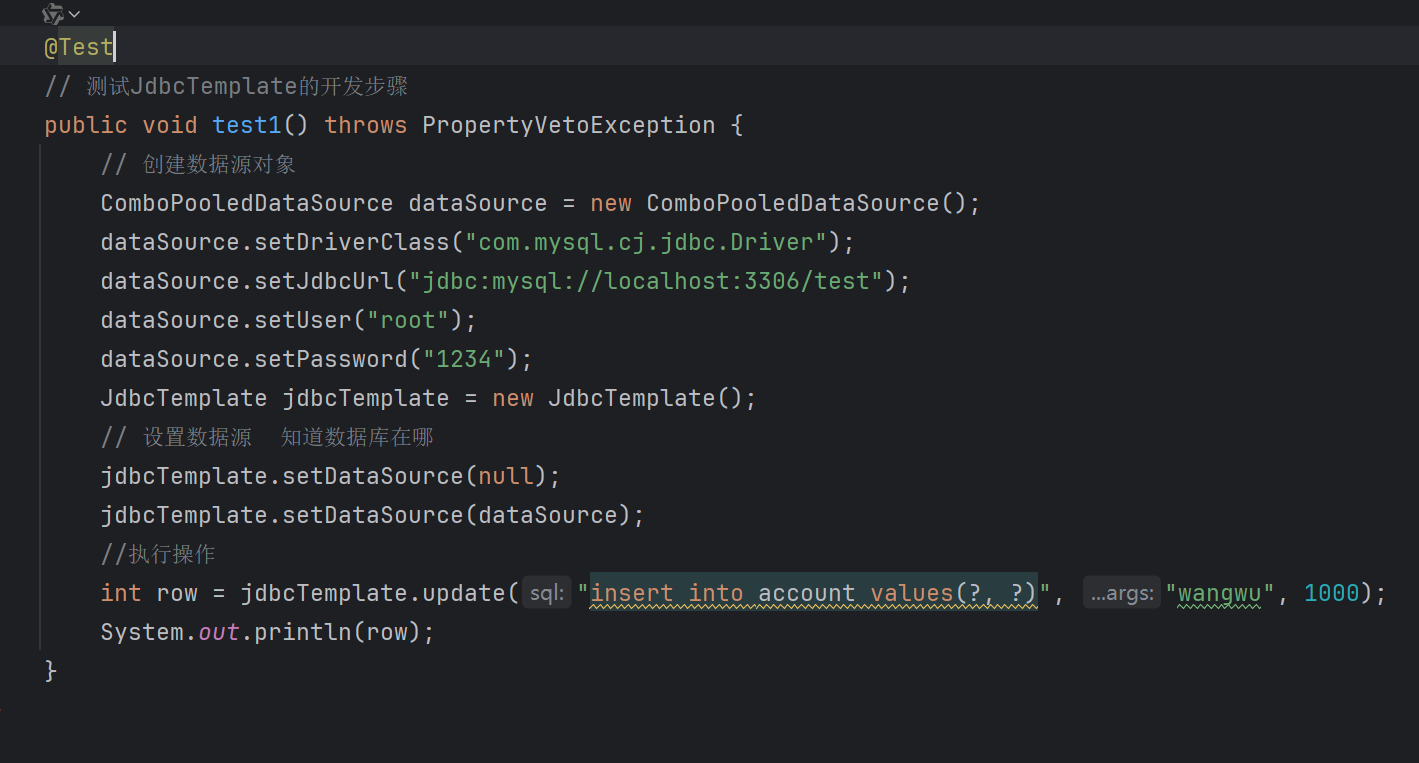
class CMN(Dataset):
def __init__(self, en_corpus, cn_corpus, en_tokenizer: Tokenizer, cn_tokenizer: Tokenizer, seq_len):
self.en_corpus = en_corpus
self.cn_corpus = cn_corpus
self.en_tokenizer = en_tokenizer
self.cn_tokenizer = cn_tokenizer
self.seq_len = seq_len
self.pad_id = self.en_tokenizer.vocab["[PAD]"]
self.bos_id = self.en_tokenizer.vocab["[BOS]"]
self.eos_id = self.en_tokenizer.vocab["[EOS]"]参数
-
en_corpus:英文语料库,是一个字符串列表。 -
cn_corpus:中文语料库,是一个字符串列表。 -
en_tokenizer:英文分词器,用于将英文文本转换为索引。 -
cn_tokenizer:中文分词器,用于将中文文本转换为索引。 -
seq_len:序列的最大长度,用于填充或截断序列。
属性
-
self.pad_id:填充标记[PAD]的索引。 -
self.bos_id:序列开始标记[BOS]的索引。 -
self.eos_id:序列结束标记[EOS]的索引。
2. 数据集长度(__len__)
def __len__(self):
return len(self.en_corpus)-
功能:返回数据集的长度,即语料库中句子的数量。
-
返回值:数据集的长度。
3. 获取数据项(__getitem__)
def __getitem__(self, idx):
en_text = self.en_corpus[idx]
cn_text = self.cn_corpus[idx]
en_ids = self.en_tokenizer.encode(en_text)
cn_ids = self.cn_tokenizer.encode(cn_text)
encoder_input = self.pad_to_seq_len([self.bos_id] + en_ids) # batch * seq_len
decoder_input = self.pad_to_seq_len([self.bos_id] + cn_ids)
labels = self.pad_to_seq_len(cn_ids + [self.eos_id])
return {
"encoder_input": encoder_input,
"decoder_input": decoder_input,
"labels": labels,
"en_text": en_text,
"cn_text": cn_text
}在 CMN 类的 __getitem__ 方法中,代码的主要目的是将英文和中文文本转换为模型可以处理的格式,并进行必要的填充操作,以确保所有序列的长度一致。以下是对 __getitem__ 方法中各个部分的详细解释:
1. 获取文本
en_text = self.en_corpus[idx]
cn_text = self.cn_corpus[idx]-
功能:从语料库中获取索引为
idx的英文句子en_text和中文句子cn_text。 -
目的:为每个索引提供一对对应的英文和中文句子,用于后续的编码和解码。
2. 文本编码
en_ids = self.en_tokenizer.encode(en_text)
cn_ids = self.cn_tokenizer.encode(cn_text)-
功能:将英文和中文句子分别通过对应的分词器编码为索引列表。
-
目的:将文本转换为模型可以处理的数值形式。分词器将每个字符(或单词)映射为词汇表中的索引。
3. 构建输入序列
encoder_input = self.pad_to_seq_len([self.bos_id] + en_ids) # batch * seq_len
decoder_input = self.pad_to_seq_len([self.bos_id] + cn_ids)-
功能:构建编码器和解码器的输入序列。
-
目的:
-
编码器输入:在英文索引列表的开头添加
[BOS]标记,表示序列的开始。然后对序列进行填充或截断,使其长度为seq_len。 -
解码器输入:在中文索引列表的开头添加
[BOS]标记,表示序列的开始。同样进行填充或截断,使其长度为seq_len。
-
-
为什么这样写:
-
[BOS]标记:在序列的开头添加[BOS]标记,是为了让模型知道序列的开始位置。这对于模型理解序列的起始点非常重要,尤其是在解码阶段。 -
填充或截断:为了确保所有序列的长度一致,需要对序列进行填充或截断。填充是通过添加
[PAD]标记来实现的,截断则是直接截取序列的前seq_len个元素。
-
4. 构建目标序列(标签)
labels = self.pad_to_seq_len(cn_ids + [self.eos_id])-
功能:构建解码器的目标序列(标签)。
-
目的:为目标序列添加
[EOS]标记,表示序列的结束。然后进行填充或截断,使其长度为seq_len。 -
为什么这样写:
-
[EOS]标记:在目标序列的末尾添加[EOS]标记,是为了让模型知道序列的结束位置。这对于模型在解码阶段生成完整的序列非常重要。 -
填充或截断:同样是为了确保所有序列的长度一致,需要对目标序列进行填充或截断。
-
5. 返回结果
return {
"encoder_input": encoder_input,
"decoder_input": decoder_input,
"labels": labels,
"en_text": en_text,
"cn_text": cn_text
}-
功能:返回一个字典,包含以下内容:
-
"encoder_input":编码器的输入序列。 -
"decoder_input":解码器的输入序列。 -
"labels":解码器的目标序列。 -
"en_text":原始英文句子。 -
"cn_text":原始中文句子。
-
-
目的:提供模型训练所需的所有输入和目标数据,同时保留原始文本以便后续验证和调试。
6. 填充序列(pad_to_seq_len)
def pad_to_seq_len(self, x):
pad_num = self.seq_len - len(x)
return torch.tensor(x + [self.pad_id] * pad_num)-
功能:将一个索引列表填充或截断到指定的序列长度
seq_len。 -
目的:确保所有序列的长度一致,以便模型可以批量处理。
-
为什么这样写:
-
填充:如果序列长度小于
seq_len,则在末尾添加[PAD]标记,直到长度达到seq_len。 -
截断:如果序列长度大于
seq_len,则直接截取前seq_len个元素。 -
转换为张量:将填充或截断后的列表转换为 PyTorch 张量,以便模型可以直接使用。
-
4. 填充序列(pad_to_seq_len)
def pad_to_seq_len(self, x):
pad_num = self.seq_len - len(x)
return torch.tensor(x + [self.pad_id] * pad_num)功能
-
将一个索引列表填充或截断到指定的序列长度
seq_len。
过程
-
计算填充数量
-
pad_num是目标长度seq_len与当前列表长度的差值。 -
如果
pad_num为正数,则需要填充;如果为负数,则需要截断。
-
-
填充或截断
-
如果
pad_num为正数,将[self.pad_id]重复pad_num次,添加到列表的末尾。 -
如果
pad_num为负数,直接截断列表的末尾部分。
-
-
返回结果
-
将填充或截断后的列表转换为 PyTorch 张量并返回。
-
示例
假设 seq_len=10,x=[2, 3, 4],调用 pad_to_seq_len(x) 的结果:
pad_num = 10 - 3 = 7
result = [2, 3, 4] + [0, 0, 0, 0, 0, 0, 0] # 假设 pad_id=0
torch.tensor([2, 3, 4, 0, 0, 0, 0, 0, 0, 0])5. CMN 类实现了以下功能:
-
数据读取:从语料库中读取英文和中文句子。
-
文本编码:将文本转换为索引列表。
-
序列填充:将索引列表填充或截断到指定长度。
-
构建输入和标签:为编码器和解码器构建输入序列和目标序列。
这些步骤是构建 Seq2Seq 模型中数据预处理的重要环节,确保了数据可以被模型有效处理。
需复现完整代码如下:
class CMN(Dataset):
def __init__(self, en_corpus, cn_corpus, en_tokenizer: Tokenizer, cn_tokenizer: Tokenizer, seq_len):
self.en_corpus = en_corpus
self.cn_corpus = cn_corpus
self.en_tokenizer = en_tokenizer
self.cn_tokenizer = cn_tokenizer
self.seq_len = seq_len
self.pad_id = self.en_tokenizer.vocab["[PAD]"]
self.bos_id = self.en_tokenizer.vocab["[BOS]"]
self.eos_id = self.en_tokenizer.vocab["[EOS]"]
def __len__(self):
return len(self.en_corpus)
def __getitem__(self, idx):
en_text = self.en_corpus[idx]
cn_text = self.cn_corpus[idx]
en_ids = self.en_tokenizer.encode(en_text)
cn_ids = self.cn_tokenizer.encode(cn_text)
encoder_input = self.pad_to_seq_len([self.bos_id] + en_ids) #batch * seq_len
decoder_input = self.pad_to_seq_len([self.bos_id] + cn_ids)
labels = self.pad_to_seq_len(cn_ids + [self.eos_id])
return {
"encoder_input": encoder_input,
"decoder_input": decoder_input,
"labels": labels,
"en_text": en_text,
"cn_text": cn_text
}
def pad_to_seq_len(self, x):
pad_num = self.seq_len - len(x)
return torch.tensor(x + [self.pad_id] * pad_num)