网上关于该算法的解析都停留在大概流程上,但是具体解析细节未知,由于代码是PipeLine形式因此阅读起来比较麻烦,本文希望通过阅读项目代码来解析其算法的具体实现细节,特别是如何利用大模型来完成图谱生成和检索增强的实现细节。
GraphRag的创新
RAG的目标是通过知识库增强内容生成的质量,通常做法是将检索出来的文档作为提示词的上下文,一并提供给大模型让其生成更可靠的答案。传统的Rag方法在大部分情况下效果都很好,但在处理复杂任务时却面临一些挑战,如多跳推理(multi-hop reasoning)或联系不同信息片段全面回答问题。不适用于摘要、总结性的问题。
GraphRAG将知识图谱技术应用到RAG,利用大模型,同时在知识图谱的基础上使用图社区摘要解决总结性查询任务的问题。
一、数据加载
支持csv和txt的格式。

二、分割文档
分割参数包括分割的每一块的token数、块之间的重叠数。使用 tiktoken 库来对文本进行编码和解码,并基于token进行分割。
使用Tokenizer对输入文本进行编码,得到一个令牌ID列表。根据设定的每个块的最大令牌数(tokensperchunk)和块之间的重叠令牌数(chunkoverlap)来迭代分割文本。在每次迭代中,它会取出一定数量的令牌ID,使用Tokenizer的解码方法将其转换回字符串,形成一个文本块。然后更新起始索引,跳过重叠的令牌,继续分割剩余的文本,直到所有文本都被处理。

补充:
其他的分词方法
tiktoken 是一个用于 OpenAI 模型的快速 BPE(字节对编码)标记器。
BPE 是一种简单的数据压缩算法,它通过迭代地合并最频繁出现的字节对来构建词汇表。
WordPiece:由 Google 开发,用于处理未知词汇和稀有词汇。
在训练数据上统计单词、子词和其他字符序列的出现频率。选择能够最大化训练数据似然的字符序列,将其添加到词汇表中。
SentencePiece:是一个无监督的文本编码器,可以用于子词分词和语言建模。
其他的chunk计算方法

三、形成嵌入向量
1.分割后的文本片段被发送到LLM以生成嵌入向量
2.LLM如何生成嵌入向量
大模型形成的特征作为嵌入向量。
3.生成的向量如何存储
VectorStoreDocument对象,该对象包含文本的ID、文本内容、嵌入向量以及其他属性(如标题)。嵌入之后的向量存储:文本嵌入向量的存储方式取决于是否配置了向量存储(vector store)以及具体的存储配置。如果在策略配置中提供了vector_store部分,那么文本嵌入向量将被存储在向量存储中。如果没有提供vector_store配置,那么嵌入向量将直接存储在内存中的DataFrame里。
azure_ai_search, lancedb
4.有哪些嵌入的大模型,如何选择
bge and nomic embed text
BGE通常是指使用BERT或其变体来生成文本嵌入的方法,适用于文本相似性分析、文档分类、情感分析等。
nomic embed text:支持多种任务,包括分类、检索、聚类、重排序和语义文本相似度(STS)计算。
四、调用大模型生成实体、关系和摘要等
最终生成实体-摘要-社区-社区摘要。
实体和关系
1.在什么数据的基础上生成实体和关系
输入数据是文本,具体来说,是一个包含多个文档的列表,每个文档是一个字典,其中包含文档的ID和文本内容。
2.如何生成实体和关系
定义一个默认的实体类型列表DEFAULT_ENTITY_TYPES,包括组织、人物、地理位置和事件。
实体格式:("entity"<>实体标识<>实体类型<>实体描述)
关系格式:("relationship"<>实体1标识<>实体2标识<>关系描述<>关系强度)
可以选择两种方式来生成实体:
graph_intelligence:使用图智能库提取实体。调用大模型。
![]()
run_extract_entities--GraphExtractor

通过prompt来指导大模型生成实体。

不用大模型可以选择nltk:使用NLTK库提取实体和关系。没有使用大模型。
![]()
3.如何存储生成的结果
提取后的实体保存在一个列表中,每个实体是一个字典,包含实体的名称和其他属性。
如何处理实体歧义和关系重叠问题。
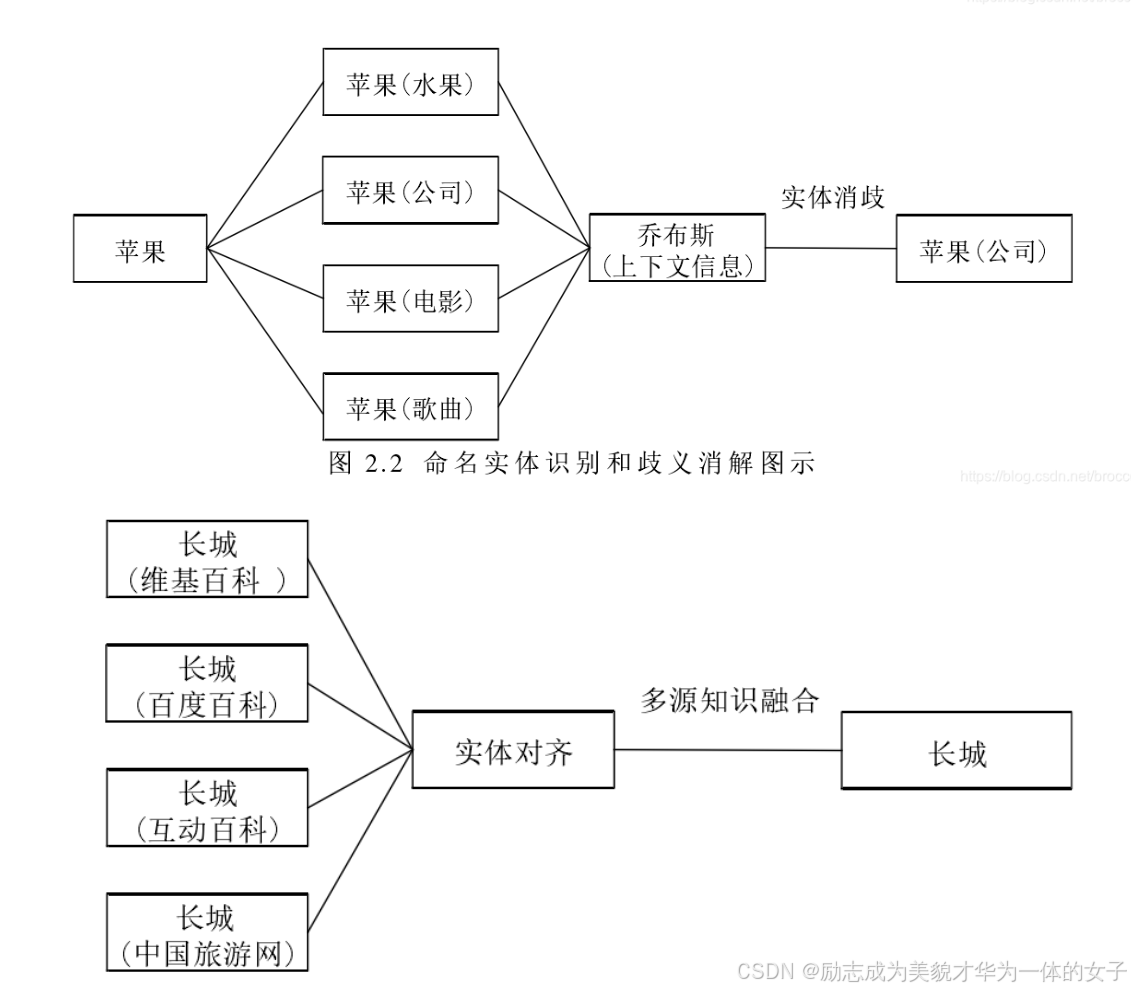
在GraphRag的实体生成过程中实体只有去除相同名称以及循环避免遗漏的处理,没有提醒大模型进行实体消歧和对齐,可以优化prompt。
实体描述
1.输入数据格式和内容
输入数据是一个 DataFrame,其中包含图的字符串表示。

2.如何生成摘要
使用语言模型(LLM)来提取和总结实体图中的实体描述。

3.保存的数据格式
提取后的实体内容保存在SummarizedDescriptionResult对象中,该对象包含两个属性:items和description。
它是一个简单的数据结构,用于封装提取结果。

图社区
社区检测_和_知识图谱嵌入

使用社区检测算法将图划分为模块化社区。
1.在什么数据的基础上生成图社区
在实体数据上
2.生成图社区的过程
社区检测:生成实体社区的层次结构。
networkx库用于图处理,以及 graspologic.partition.hierarchical_leiden 用于社区检测。
社区检测(Community Detection)是一种常用的技术,用于发现图中的紧密相连的节点集合,这些节点集合在内部有较多的连接,而与集合外部的节点连接较少。
首先,需要有一个图(Graph),它由节点(Nodes)和边(Edges)组成。在代码中,这通常是通过 networkx 库来表示的。
import networkx as nx
# 创建一个图
G = nx.Graph()
# 添加节点和边
G.add_nodes_from([1, 2, 3, 4, 5])
G.add_edges_from([(1, 2), (2, 3), (3, 4), (4, 5), (5, 1)])定义聚类方法,处理聚类结果,聚类算法执行后,会返回一个包含社区信息的字典。这个字典通常以社区级别为键,以包含社区 ID 和节点列表的字典为值。
优化模块度(一个衡量社区质量的指标)来快速识别社区。


节点的度:对于无向图,一个节点的度是指与该节点相连的边的数量。在无向图中,每条边连接两个节点,因此每条边会为两个节点各增加一度。
知识图谱嵌入
使用 Node2Vec 算法生成知识图谱的向量表示。这将使我们能够理解我们的知识图谱的隐含结构,并提供一个额外的向量空间,用于在查询阶段搜索相关概念。
将图数据嵌入到向量空间中,使用 node2vec 算法生成节点的嵌入向量,并返回一个有序的字典,其中包含节点的标识符和它们的嵌入向量。
为什么要把图节点生成嵌入向量:

node2vec是一种随机游走的算法,
node2vec使用了一种灵活的随机游走策略,它结合了两种游走策略:深度优先搜索(DFS)和广度优先搜索(BFS)。这种策略允许算法在探索节点邻域时平衡局部和全局的结构信息。一旦生成了随机游走序列,node2vec使用Skip-Gram模型来学习节点的嵌入。Skip-Gram的目标是给定一个节点(中心节点),预测它的上下文节点。通过优化目标函数(例如,最大化上下文节点的对数概率),使用梯度下降等优化算法更新节点的嵌入向量。
一旦我们完成了知识图谱增强步骤,我们会对 实体 和 关系 表进行发射,之后再进行文本域的文本嵌入。
3.输出结果
社区信息,包括社区级别、社区ID和属于该社区的节点列表。
社区摘要
自下而上地生成每个社区层级及其组成部分的摘要。如果社区 A 是最高层级的社区,我们将获得有关整个知识图谱的报告。如果社区是较低级别的,则我们将获得有关局部集群的报告。
生成社区报告
使用 LLM 生成每个社区的摘要。这将使我们能够了解每个社区中包含的不同信息,并从高层次或低层次的角度提供对知识图谱的范围性理解。这些报告包含管理概述,并引用社区子结构中的关键实体、关系。
总结社区报告
在这一步中,每个_社区报告_会经过 LLM 进行摘要,供简要使用。
社区嵌入
通过生成社区报告、社区报告摘要和社区报告标题的文本嵌入,生成我们社区的向量表示。
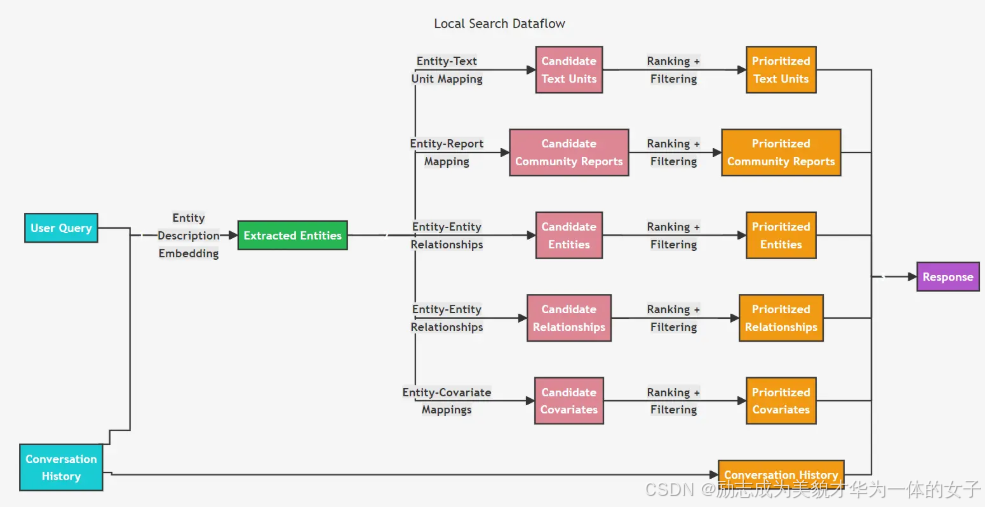
五、检索
局部检索
适用于需要理解文档中提到的特定实体的问题。
1.将query在存储实体信息的向量库中检索出相关实体。
代码路径:graphrag\query\context_builder\entity_extraction.py
提供了三种查询相关性实体的方法:
map_query_to_entities(默认用的是这个)
通过文本嵌入向量来查找与查询最相关的实体,查询文本嵌入向量(在文本分块后数据库中实际存储的向量)与查询向量的相关性,然后返回对应文本向量的实体。
graphrag\vector_stores\lancedb.py similarity_search_by_text。
其他实现实体检索的方法:
find_nearest_neighbors_by_entity_rank:通过实体的直接关系和排名来查找最相关的实体。
找出与目标实体直接相连的关系。
确定与目标实体有关系的实体名称,并排除掉排除列表中的实体。
从所有实体中检索这些相关实体的列表,并根据实体的排名进行排序。
返回前 k 个实体。
find_nearest_neighbors_by_graph_embeddings
通过图嵌入(graph embeddings)查找与给定实体最相似的实体。
2.将第一步实体相关的chunk信息、社区摘要、实体详情、实体关系、实体Covarites按一定的格式组织作为上下文。对这些候选数据源进行优先排序和过滤, 以适应预定义大小的单一上下文窗口, 用于生成对用户查询的响应。
怎么优先排序?
chunk信息:关系数量:文本单元与实体的关系数量是排序的一个重要因素,这表明代码旨在优先考虑与更多关系相关的文本单元。实体顺序:实体在列表中的顺序也是一个排序因素,这可能意味着先出现的实体可能更重要或更相关。上下文限制:通过max_tokens参数限制了上下文文本的长度,确保不会超出令牌限制。
社区摘要:

关系和协变量上下文:在build_relationship_context和build_covariates_context函数中,关系和协变量可能根据它们与实体的关联强度或其他属性(如权重或排名)进行排序。
3.如果有历史聊天记录想历史聊天记录也作为上下文的一部分。
graphrag\query\context_builder\conversation_history.py在对话系统中存储、管理和格式化对话历史。
4.让LLM根据上下文生成回答(prompt路径为graphrag/query/structured_search/local_search/system_prompt.py)。
如何高效地存储和查询嵌入向量,特别是在大规模知识图谱中。
向量存储的索引策略和数据结构。
全局检索
以 map-reduce 方式搜索所有 AI 生成的社区报告来生成答案。这是一种资源密集型方法,但通常对于需要整体理解数据集的问题能给出很好的响应。因为基准的 RAG 依赖于对数据集中语义相似文本内容的向量搜索。查询中没有任何指示它找到正确信息的内容。LLM 生成的知识图的结构告诉我们整个数据集的结构(因此也是主题)。这使得私有数据集可以被组织成有意义的语义聚类,并进行预摘要。

1.将所有社区摘要shuffle并分块作为上下文,另将历史对话构成的上下文与这些社区摘要块拼接在一起作为上下文。
2.用map机制将前一步的多个上下文让LLM评估它们对于回答用户问题是否有帮助并进行0-100的打分。过滤掉分数为0的上下文。
prompt:graphrag\query\structured_search\global_search\map_system_prompt.py
3.将前一步得到的结果合并且按照分数大小进行降序排序,并将这些信息加入到LLM上下文窗口,让LLM生成最终的回答。
全局搜索的响应质量很大程度上取决于所选的用于获取社区报告的社区层次结构级别。较低层次的层次结构带有其详细报告,往往会产生更详尽的响应,但可能也会增加生成最终响应所需的时间和 LLM 资源,因为需要处理更多的报告。
Global查询的步骤如下(如下图所示)(prompt在graphrag/query/structured_search/global_search/map_system_prompt.py 和 graphrag/query/structured_search/global_search/reduce_system_prompt.py:
写的比较好的笔记:
基于社区发现的GraphRAG思路_graphrag 社区-CSDN博客