0 要点总结
- Meta发布 Llama 4 系列的首批模型,帮用户打造更个性化多模态体验
- Llama 4 Scout 是有 170 亿激活参数、16 个专家模块的模型,同类中全球最强多模态模型,性能超越以往所有 Llama 系列模型,能在一张 NVIDIA H100 GPU 上运行。该模型支持业界领先的 1000 万上下文窗口,在多个权威测试中表现优于 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1
- Llama 4 Maverick 也拥有 170 亿激活参数,但配置多达 128 个专家模块,是同类中最强的多模态模型,在多个广泛测试中超越 GPT-4o 和 Gemini 2.0 Flash,推理和编程能力可与 DeepSeek v3 相当,但激活参数数量不到其一半。其聊天版在 LMArena 上取得了 1417 的 ELO 分数,性能与成本比行业领先
- 这些出色的模型得益于“教师模型” Llama 4 Behemoth 的知识蒸馏。Behemoth 拥有 2880 亿激活参数和 16 个专家模块,是我们最强大的模型,在多项 STEM 基准测试中超越 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。目前该模型仍在训练中,我们将持续分享更多细节。
- 立即前往 llama.com 或 Hugging Face 下载 Llama 4 Scout 与 Maverick。也可在 WhatsApp、Messenger、Instagram 私信体验基于 Llama 4 构建的 Meta AI。
随 AI 在日常生活中的广泛应用,确保领先的模型与系统开放可用,对推动个性化体验创新至关重要。支持整个 Llama 生态 的最先进模型组合。正式推出的 Llama 4 Scout 和 Llama 4 Maverick,是首批开放权重、原生多模态、支持超长上下文窗口、采用 MoE架构构建的模型。“巨兽”—— Llama 4 Behemoth,不仅是迄今最强大的模型之一,也是新一代模型的“老师”。
这些 Llama 4 模型的发布标志着 Llama 生态迈入新纪元。Llama 4 系列中的 Scout 和 Maverick 都是高效设计的模型:
- 前者能以 Int4 量化方式部署在单张 H100 GPU 上
- 后者则适配于单个 H100 主机
训练了 Behemoth 教师模型,在 STEM 基准(如 MATH-500 和 GPQA Diamond)中表现优于 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。
开放才能推动创新,对开发者、Meta 和整个世界都是利好。可通过 llama.com 和 Hugging Face 下载 Scout 与 Maverick。同时,Meta AI 也已在 WhatsApp、Messenger、Instagram 私信启用 Llama 4 模型。
这只是 Llama 4 系列的开始。最智能的系统应能泛化行动、自然对话并解决未曾遇到的问题。赋予 Llama 在这些领域的“超能力”,将催生更优质的产品和更多开发者创新机会。
无论你是构建应用的开发者,集成 AI 的企业用户,或是对 AI 潜力充满好奇的普通用户,Llama 4 Scout 和 Maverick 都是将下一代智能融入产品的最佳选择。接下来,介绍它们的四大研发阶段以及设计过程中的一些关键洞察。
1 预训练阶段
这些模型代表 Llama 系列的巅峰之作,具备强大多模态能力,同时在成本上更具优势,甚至性能超越了一些参数规模更大的模型。为打造 Llama 下一代模型,在预训练阶段采用了多项新技术。
MoE
Llama 4是首批采用MoE的模型。MoE架构的一个核心优势:每个 token 只激活模型中一小部分参数,从而大幅提高训练与推理的效率。在给定的 FLOPs(浮点运算)预算下,MoE 模型的效果优于传统的密集模型。
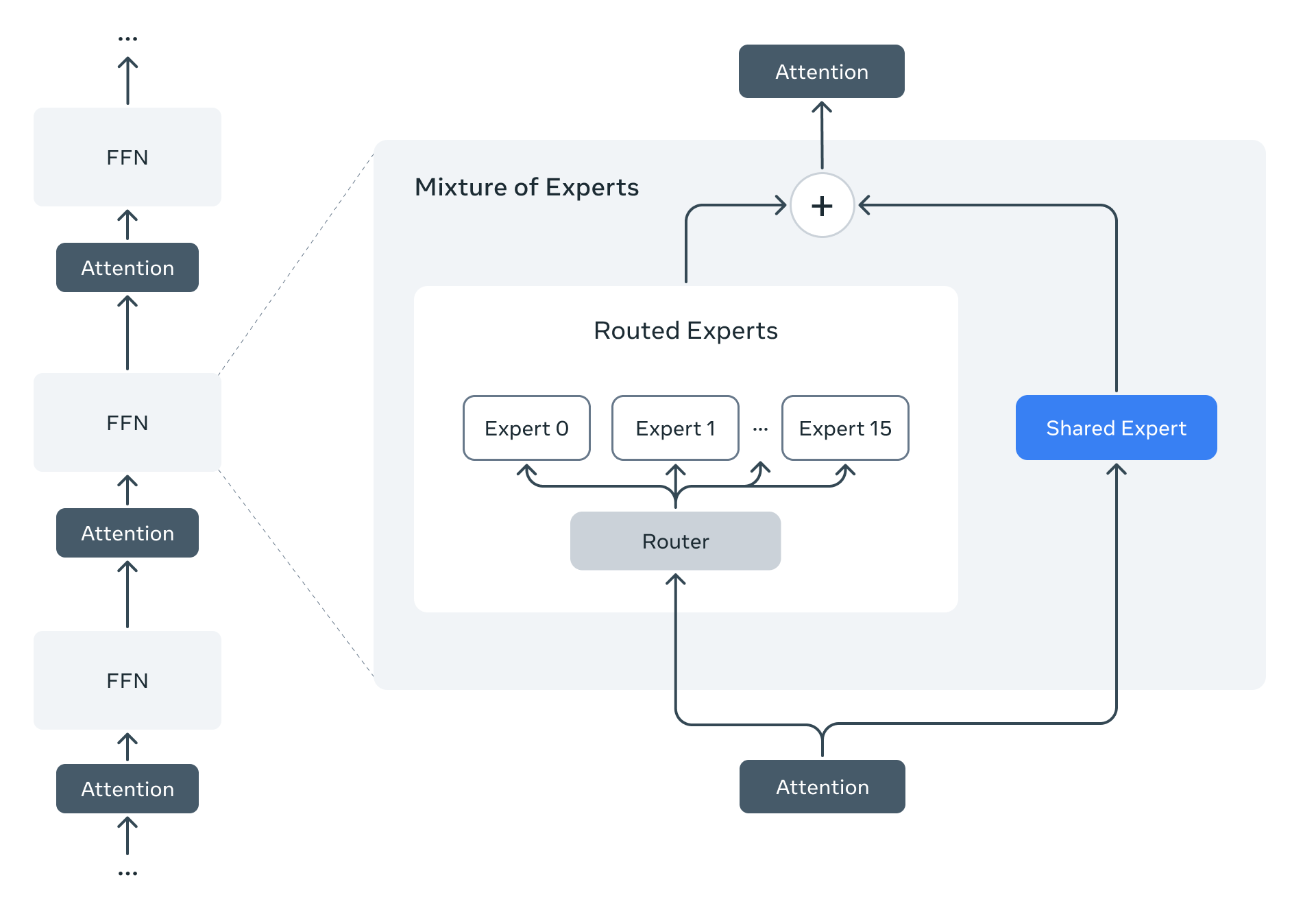
以 Llama 4 Maverick 为例:它拥有 170 亿激活参数,总参数数为 4000 亿。其网络结构在推理过程中交替使用密集层与 MoE 层。每个 token 会被送入一个共享专家和一个 128 个路由专家之一,这种机制确保模型在保持全参数存储的同时,仅激活必要部分,从而提升运行效率、降低成本与延迟。Maverick 可在一台 NVIDIA H100 DGX 主机上运行,也支持分布式部署以实现最大效率。
Llama 4 天生支持多模态输入,采用 早期融合(early fusion)机制,将文本与视觉 token 一体化输入模型主干。使得能用大量未标注的文本、图像和视频数据对模型进行联合预训练。同时,升级视觉编码器,基于 MetaCLIP 的改进版,在预训练阶段与冻结的 Llama 主干协同优化。
新训练方法MetaP
精确控制每层学习率和初始化比例。这些超参数在不同 batch size、模型宽度、深度和 token 数下都具有良好的迁移性。Llama 4 预训练涵盖 200 多种语言,其中 100 多种语言的数据量超过 10 亿 tokens,总体上多语种训练 token 数量是 Llama 3 的 10 倍。
FP8 精度
用 FP8 精度 进行训练,保持模型质量的同时提高训练效率。如训练 Behemoth 时,用 32000 张 GPU,并实现 390 TFLOPs/GPU 的高效能。整个训练数据超过 30 万亿个 token,是 Llama 3 的两倍,数据类型包含多样的文本、图像和视频内容。
训练中期,采用“mid-training”阶段,通过专门数据集提升模型的核心能力,如支持更长上下文的能力。得益于这些改进,Llama 4 Scout 实现 业界领先的 1000 万 token 输入长度。
2 后训练阶段
新模型有大小多种选择,以满足不同应用场景与开发者需求。Llama 4 Maverick 在图像和文本理解方面表现卓越,是多语言 AI 应用和创意写作的理想选择。
后训练阶段最大的挑战是保持不同输入模态、推理能力与对话能力之间的平衡。为此,设计“多模态课程”训练策略,确保模型不因学习多模态而牺牲单一模态性能。更新了后训练流程,采取轻量监督微调(SFT)> 在线强化学习(RL)> 轻量偏好优化(DPO)的方式。发现SFT 与 DPO 若使用不当,会限制模型在 RL 阶段的探索,特别是在推理、编程和数学领域会导致效果下降。
为解决这问题,剔除超过 50% 的“简单样本”,仅对更难数据进行 SFT。之后 RL 阶段用更具挑战性提示,实现性能飞跃。采用 持续在线 RL 策略:训练模型 → 用模型筛选中等难度以上的提示 → 再训练,如此循环,有效平衡计算成本与精度。最终,我们通过轻量 DPO 优化边缘情况,全面提升模型的智能与对话能力。
Llama 4 Maverick 拥有 170 亿激活参数、128 个专家模块与 4000 亿总参数,在性能上超越 Llama 3.3 的 70B 模型。它是目前最顶级的多模态模型,在编程、推理、多语言、长文本与图像等任务中优于 GPT-4o 与 Gemini 2.0,与 DeepSeek v3.1 的表现不相上下。
[外链图片转存中…(img-Y4bYAPfr-1743952046715)]
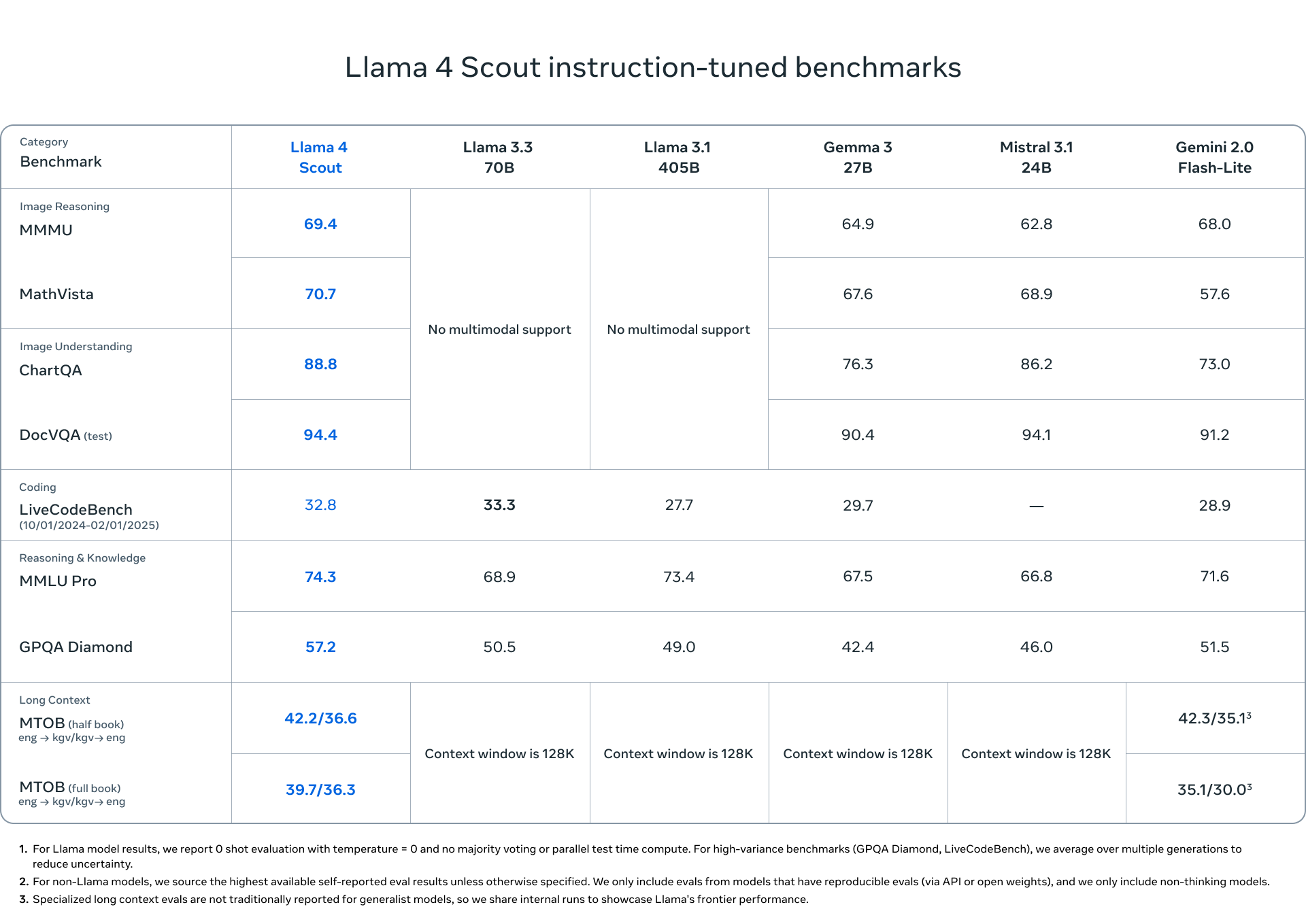
Llama 4 Scout 是一款通用模型,具备 170 亿激活参数、16 个专家模块、1090 亿总参数,性能在同类模型中首屈一指。它将上下文长度从 Llama 3 的 128K 大幅提升至 1000 万 tokens,支持多文档摘要、个性化任务解析、大型代码库推理等复杂应用。
Scout 在预训练和后训练阶段都使用了 256K 上下文长度,从而拥有出色的长文本泛化能力。在文本检索、代码负对数似然(NLL)评估等任务中均表现优秀。其一大创新是采用了 不使用位置嵌入的交错注意力机制(iRoPE),通过 温度调节推理机制 提升了对超长输入的处理能力。

我们对两个模型都进行了广泛的图像和视频帧训练,以增强它们对视觉内容的理解能力,包括时间相关活动和图像之间的关联。这让模型在处理多图输入时能轻松地结合文字提示进行视觉推理与理解。预训练阶段使用最多48张图像的输入,并在后期测试中验证模型在处理最多8张图像时的良好表现。
Llama 4 Scout 在图像定位方面表现尤为出色,能够将用户的提示准确对应到图像中的具体视觉元素,实现更精确的视觉问答。这款模型在编程、推理、长文本理解和图像处理等方面全面超越以往版本的 Llama 模型,性能领先同类模型。
3 推出更大规模的 Llama:2 万亿参数巨兽 Behemoth
Llama 4 Behemoth——拥有高级智能的“教师模型”,在同类模型中表现领先。Behemoth 是一个多模态专家混合(MoE)模型,激活参数达 2880 亿,拥有 16 个专家模块,总参数量接近两万亿。在数学、多语言和图像基准测试中表现一流,因此成为训练更小的 Llama 4 模型的理想“老师”。
从 Behemoth 模型中通过“共蒸馏”(codistillation)技术训练出了 Llama 4 Maverick,有效提升了最终任务表现。我们还研发了一种全新的损失函数,能在训练过程中动态调整软标签和硬标签的权重。此外,我们还通过在 Behemoth 上运行前向传递,生成用于训练学生模型的数据,大幅降低了训练成本。
对这样一个拥有两万亿参数的模型,其后期训练本身就是一项巨大挑战。我们从数据量级就开始彻底改革训练方法。为提升性能,我们将监督微调(SFT)数据削减了95%(相比于小模型只需要削减50%),以更专注于数据质量和效率。
还发现:先进行轻量级的 SFT,再进行大规模强化学习(RL),能够显著提升模型的推理和编程能力。RL策略包括:
- 使用 pass@k 方法选取具有挑战性的提示构建训练课程;
- 动态过滤无效提示;
- 混合多个任务的提示组成训练批次;
- 使用多种系统指令样本,确保模型能广泛适应不同任务。
为支持 2 万亿参数的 RL 训练,重构了整个强化学习基础设施。对 MoE 并行架构进行了优化,提高训练速度,并开发了完全异步的在线 RL 框架,提升了训练的灵活性和效率。通过将不同模型分配到不同 GPU 并进行资源平衡,实现训练效率的近10倍提升。
4 安全机制与防护措施
致力打造有用且安全的模型,同时规避潜在的重大风险。Llama 4 遵循《AI 使用开发指南》中的最佳实践,从预训练到系统级都融入了防护机制,以保障开发者免受恶意行为干扰,从而开发出更安全、可靠的应用。
4.1 预训练与后训练防护
- 预训练:使用数据过滤等方法保护模型。
- 后训练:通过一系列技术确保模型遵循平台政策,保持对用户和开发者的友好性和安全性。
4.2 系统级方法
开源了多种安全工具,方便集成进 Llama 模型或第三方系统:
- Llama Guard:与 MLCommons 联合开发的风险分类法构建的输入输出安全模型。
- Prompt Guard:一个可识别恶意提示(如 Jailbreak 和提示注入)的分类模型。
- CyberSecEval:帮助开发者了解和降低生成式 AI 网络安全风险的评估工具。
这些工具支持高度定制,开发者可根据应用需求进行优化配置。
4.3 安全评估与红队测试
我们在各种使用场景下进行系统化测试,并将测试结果反馈到模型后训练中。我们使用动态对抗性探测技术(包括自动和人工测试)来识别模型的潜在风险点。
一种新测试方式——生成式攻击智能代理测试(GOAT),可模拟中等技能水平的攻击者进行多轮交互,扩大测试覆盖范围。GOAT 的自动化测试能替代人工团队处理已知风险区域,让专家更专注于新型对抗场景,提高测试效率。
4.4 解决语言模型中的偏见问题
大型语言模型容易出现偏见,尤其在社会和政治话题上偏向自由派。这是因为网络训练数据本身就存在倾向性。
目标是消除偏见,让 Llama 能够公正地理解并表达有争议话题的不同观点,而非偏袒某一方。
Llama 4 在这方面取得了重大进展:
- 拒答比例从 Llama 3 的 7% 降低至 Llama 4 的 2% 以下;
- 对于具有争议性的问题,拒答不平衡的比例降至 1% 以下;
- 表现出强烈政治倾向的响应率仅为 Llama 3 的一半,与 Grok 相当。
继续努力,进一步降低偏见水平。
5 探索 Llama 生态系统
除了模型智能,用户还希望模型反应个性化、速度快。Llama 4 是迄今为止最先进的模型,已为此进行优化。模型只是打造完整体验的一部分。
本项目感谢以下 AI 生态伙伴的大力支持(按字母顺序排列):
Accenture、Amazon Web Services、AMD、Arm、CentML、Cerebras、Cloudflare、Databricks、Deepinfra、DeepLearning.AI、Dell、Deloitte、Fireworks AI、Google Cloud、Groq、Hugging Face、IBM Watsonx、Infosys、Intel、Kaggle、Mediatek、Microsoft Azure、Nebius、NVIDIA、ollama、Oracle Cloud、PwC、Qualcomm、Red Hat、SambaNova、Sarvam AI、Scale AI、Scaleway、Snowflake、TensorWave、Together AI、vLLM、Wipro。