1.lock和try_lock
lock是一个函数模板,可以支持多个锁对象同时锁定同一个,如果其中一个锁对象没有锁住,lock函数会把已经锁定的对象解锁并进入阻塞,直到多个锁锁定一个对象。
try_lock也是一个函数模板,尝试对多个锁对象进行同时尝试锁定,如果锁对象全部锁定,返回-1,如果某一个锁对象尝试锁定是失败,把已经锁定成功的锁对象解锁,并返回这个对象的下标(第一个参数对象,下标从0开始)
代码示例
template<class Mutex1,class Mutex2,class... Mutexes>
void lock(Mutex1& a, Mutex2& b, Mutexes&... cde);
template<class Mutex1,class Mutex2,class... Mutexes>
int tyr_lock(Mutex1& a, Mutex2& b, Mutexes&... cde);
#include<iostream>
#include<thread>
#include<mutex>
using namespace std;
std::mutex foo, bar;
void task_a()
{
std::lock(foo, bar);
std::cout << "task a" << endl;
foo.unlock();
bar.unlock();
}
void task_b()
{
std::lock(bar,foo);
std::cout << "task b" << std::endl;
foo.unlock();
bar.unlock();
}
int main()
{
foo.lock();
std::thread t1(task_a);
std::thread t2(task_b);
std::cout << "xxxxxxxxxxx" << endl;
bar.lock();
foo.unlock();
std::cout << "yyyyyyyyyy" << endl;
bar.unlock();
t1.join();
t2.join();
return 0;
}代码解释:
主线程先锁定了foo,然后走两个线程任务,因为foo锁已经被申请了,两个线程就会阻塞在std::lock这里,主线程就会继续执行,锁定bar,然后解锁foo。两个线程可以申请foo锁资源了,但是bar申请不到,所以两个线程还是阻塞住,然后主线程申请bar锁并释放了foo锁,这两个线程还是会阻塞,task_b虽然拿到了bar锁,但是foo锁拿不到就会释放掉bar锁,重新申请这两个锁,所以主线程就能拿到bar锁,打印yyyy,然后释放bar锁,这时候,线程就开始争夺这两个锁资源,进而执行线程任务。
代码二
template<class Mutex1,class Mutex2,class... Mutexes>
void lock(Mutex1& a, Mutex2& b, Mutexes&... cde);
template<class Mutex1,class Mutex2,class... Mutexes>
int tyr_lock(Mutex1& a, Mutex2& b, Mutexes&... cde);
#include<iostream>
#include<thread>
#include<mutex>
using namespace std;
std::mutex foo, bar;
void task_a()
{
foo.lock();
std::cout << "task a\n";
bar.lock();
foo.unlock();
bar.unlock();
}
void task_b()
{
int x = try_lock(bar, foo);
if (x == -1)
{
std::cout << "task b\n";
bar.unlock();
foo.unlock();
}
else
{
std::cout << "task b failed:mutex:" << (x ? "foo" : "bar") << endl;
}
}
int main()
{
std::thread t1(task_a);
std::thread t2(task_b);
t1.join();
t2.join();
return 0;
}代码解释:
首先线程先执行a任务,先拿foo锁,然后再那bar锁,然后把拿到的锁都释放了,b任务是尝试申请foo和bar锁,如果锁都没拿到就返回-1,存在没申请到的就返回下标。这时就会存在两种结果,如果a任务快的话,把两个锁都拿了,那么任务b执行if,如果a任务拿到锁并释放了,b任务执行else
结果一

结果二

2.call_once函数
多线程执行时,让第一个线程执行任务,其它线程不再执行这个任务。(多线程去争夺唯一机会且只执行一次任务)
template< class Function, class... Args >
void call_once( std::once_flag& flag, Function&& f, Args&&... args );
-
std::once_flag:一个标志,用于记录函数是否已经被调用过。 -
Function:要执行的函数。 -
Args...:传递给函数的参数。
std::once_flag winner_flag;
-
std::once_flag是一个无状态的标志,用于记录std::call_once是否已经被调用。 -
它不需要显式初始化,只需要声明即可。
代码示例
template<class Mutex1,class Mutex2,class... Mutexes>
void lock(Mutex1& a, Mutex2& b, Mutexes&... cde);
template<class Mutex1,class Mutex2,class... Mutexes>
int tyr_lock(Mutex1& a, Mutex2& b, Mutexes&... cde);
#include<iostream>
#include<thread>
#include<mutex>
#include<chrono>
using namespace std;
std::mutex foo, bar;
int winner;
void set_winner(int x) { winner = x; }
std::once_flag winner_flag;
void wait_time(int id)
{
for (int i = 0; i < 1000; i++)
{
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
std::call_once(winner_flag, set_winner, id);
}
int main()
{
std::thread threads[10];
for (int i = 0; i < 10; i++)
{
threads[i] =std::thread(wait_time, i + 1);
}
for (auto& s : threads)
{
s.join();
}
std::cout << "winner thread:" << winner << endl;
return 0;
}代码解释:
主线程创建10个线程,然后都执行一个函数,并设置id号,进入到wait函数都要进行休眠,然后公平竞争唯一机会,休眠结束后,同一执行任务call函数,只有一个线程会进入到set函数,并改变winner_flag标志,使其它线程进不到这个函数,打印id知道哪一个线程执行了这个任务。
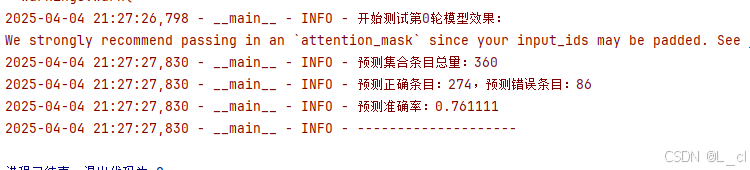
3.atomic
atomic是一个模板的实例化和全特化定义的原子类型,保证对一个原子对象的操作是线程安全的。
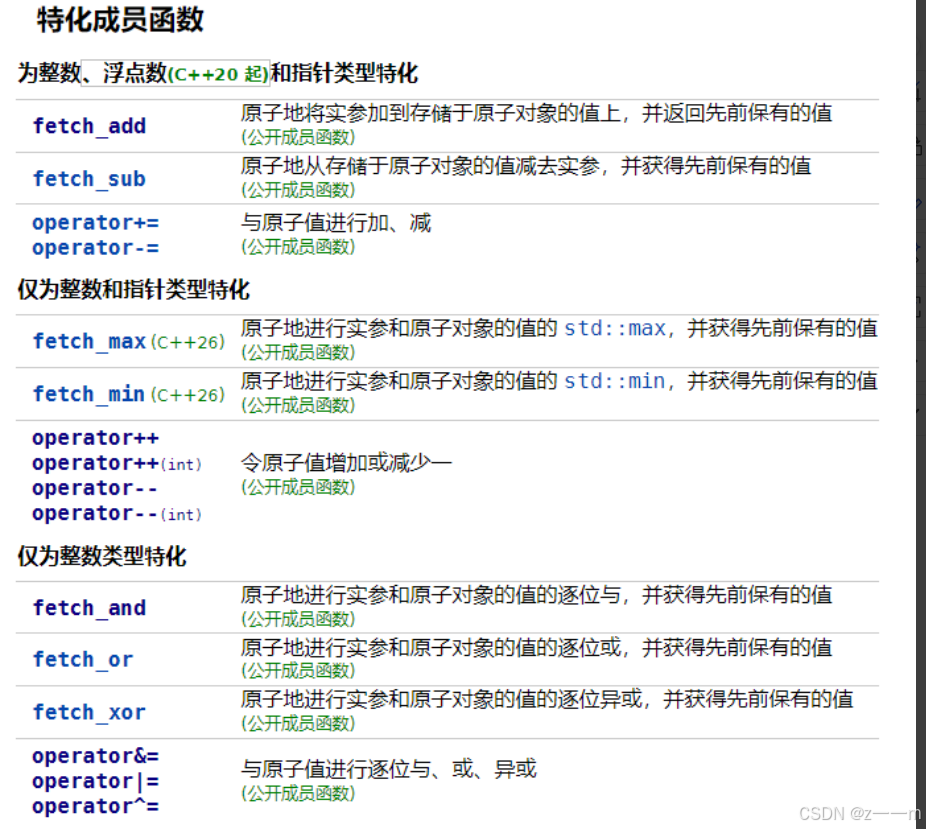
load和store可以原子的读取和修改atomic封装存储的T对象。
atomic的原理主要是硬件层面支持,现代处理器提供了原子指令来支持原子操作。如x86架构,有CMPXCHG(比较并交换)指令。这些原子指令能够在一个不可分割的操作中完成对内存的读取,比较和写入操作,简称CAS,Compare And Set,或是Compare And Swap。另外为了处理多个处理器缓存之间的数据一致性问题,硬件采用了缓存一致性协议,当一个atomic操作修改了一个变量的值,缓存一致性协议会确保其它处理器缓存中相同的变量副本被正确的更新还在标记为无效。
template < class T >bool atomic_compare_exchange_weak (atomic<T>* obj, T* expected, T val)noexcept ;template < class T >bool atomic_compare_exchange_strong (atomic<T>* obj, T* expected, T val)noexcept ;// C++11 中 atomic 类的成员函数bool compare_exchange_weak (T& expected, T val,memory_order sync = memory_order_seq_cst) noexcept ;bool compare_exchange_strong (T& expected, T val,memory_order sync = memory_order_seq_cst) noexcept ;
C++11的CAS操作支持,atomic对象跟expected按位比较相等,则用val更新atomic对象并返回值true,若atomic对象跟expected按位比较不相等,则更新expected为当前的atomic对象并返回false。(就是多个线程进来,每个线程都有一样的初始值,总有先后,先的改了值,回来的修改值但要先比较初始值是否相等,不相等就说明被改了,就要更换初始值,然后再来一次,只有相等才可以修改这个值)
compare_exchange_weak在某些平台上,即使原子变量的值等于expected,也可能"虚假"的返回。这是因为底层硬件和编译器优化导致的。compare_exchange_strong是不会的,但是有代价(硬件的缓存一致性协议EMSI),所以一般是weak,在考虑性能的情况下。安全情况下可以用strong/。
C++11标准库中,std::atomic提供了多种内存顺序(memory_order)选项,用于控制原子操作的内存同步行为。这些顺序选项允许开发者在性能与正确性之间进行权衡,特别是多线程编程中。
1.memory_order_relaxed最宽松的内存顺序,保证原子操作的原子性,不提供任何同步或者顺序约束。适用计数器。
std::atomic< int > x ( 0 );x. store ( 42 , std::memory_order_relaxed); // 仅保证原⼦性
2.memory_order_consume
3.memory_order_acquire保证当前操作之前的所有读写操作(在当前线程中)不会被重排序到当
template<class Mutex1,class Mutex2,class... Mutexes>
void lock(Mutex1& a, Mutex2& b, Mutexes&... cde);
template<class Mutex1,class Mutex2,class... Mutexes>
int tyr_lock(Mutex1& a, Mutex2& b, Mutexes&... cde);
#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
#include<chrono>
#include<vector>
using namespace std;
std::mutex foo, bar;
atomic<int> acnt;
int cnt;
void Add1(atomic<int>& cnt)
{
int old = cnt.load();
// 如果cnt的值跟old相等,则将cnt的值设置为old+1,并且返回true,这组操作是原⼦的。
// 那么如果在load和compare_exchange_weak操作之间cnt对象被其他线程改了
// 则old和cnt不相等,则将old的值改为cnt的值,并且返回false。
while (!atomic_compare_exchange_weak(&cnt, &old, old + 1));
}
void f()
{
for (int i = 0; i < 100000; i++)
{
++acnt;
++cnt;
}
}
int main()
{
std::vector<thread> pool;
for (int i = 0; i < 4; i++)
{
pool.emplace_back(f);
}
for (auto& e : pool)
{
e.join();
}
std::cout << "原子计数器:" << acnt << endl;
cout << "非原子计数器:" << cnt << endl;
return 0;
}
代码解释:
std::atomic 是 C++ 标准库中用于实现原子操作的模板类,它可以确保对变量的读写操作是原子性的,从而避免竞态条件(race conditions)。而全局变量cnt就会因为多线程并发导致数据不一致问题,计数不准确。atomic的原子操作就像Add1函数的实现,每次都要与旧值进行比较,只有相等才表示没有其它线程执行,就可以进行修改,而变了就会先修改旧值变为当前值,然后再循环判断是否与旧值相当,相等就可以进行修改了。
注意:这里不能使用push_back():
push_back 的工作原理是:
-
先构造一个临时对象。
-
然后将这个临时对象拷贝或移动到容器中。
但 std::thread 的拷贝构造函数是被删除的(delete),这意味着你不能拷贝一个 std::thread 对象。因此,如果你尝试使用 push_back,编译器会报错,因为 push_back 试图拷贝构造一个 std::thread 对象。
emplace_back 的工作原理是:
-
直接在容器的存储空间中构造对象。
-
避免了不必要的拷贝或移动。
因此,emplace_back 可以直接在 std::vector<std::thread> 中构造 std::thread 对象,而不需要先构造一个临时对象再移动。
在 C++ 中, 平凡可复制类型(Trivially Copyable Type) 是指可以安全地通过逐字节复制(如memcpy或memmove)来进行复制的类型。这种类型的对象在内存中的表示是连续的,并且复制操作不会导致未定义行为。
代码3
template<class Mutex1,class Mutex2,class... Mutexes>
void lock(Mutex1& a, Mutex2& b, Mutexes&... cde);
template<class Mutex1,class Mutex2,class... Mutexes>
int tyr_lock(Mutex1& a, Mutex2& b, Mutexes&... cde);
#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
#include<chrono>
#include<vector>
using namespace std;
std::mutex foo, bar;
atomic<int> acnt;
struct Node { int val; Node* next; };
std::atomic<Node*> list_head(nullptr);
void append(int val, int n)
{
for (int i = 0; i < n; i++)
{
Node* oldHead = list_head;
Node* newnode = new Node{ val + i,oldHead };
while (!list_head.compare_exchange_weak(oldHead, newnode))
newnode->next = oldHead;
}
}
int main()
{
std::vector<std::thread> threads;
threads.emplace_back(append, 0, 10);
threads.emplace_back(append, 10, 10);
threads.emplace_back(append, 20, 10);
threads.emplace_back(append, 30, 10);
threads.emplace_back(append, 40, 10);
for (auto& e : threads)
{
e.join();
}
for (Node* it = list_head; it != nullptr; it = it->next)
{
std::cout << ' ' << it->val;
}
Node* it;
while (it = list_head)
{
list_head = it->next;
delete it;
}
return 0;
}
代码解释:
全局创建原子对象,类型是Node*,头节点为空,append函数用来加入结点,oldHead=头节点,newnode是要链接的新结点,while循环保证原子操作,如果list_head的值与oldHead相等,就会把list_head的值变为newnode值,返回true;如果不相等,就把list_head的值变成oldHead的值,返回false,false取反为true,就会执行循环内容,新结点链接到链表。这样能保证原子性,因为只有头节点的值和oldHead相等,才能保证没有其它线程进入修改值,就可以放心链接。如果修改了,就说明有其它线程进入修改了头节点,而此线程的头节点没更新就会覆盖式插入进去,导致数据丢失了。
代码四
#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
//#include<chrono>
#include<vector>
using namespace std;
template<class T>
struct node
{
T data;
node* next;
node(const T& data):data(data),next(nullptr){}
};
namespace lock_free
{
template<class T>
class stack
{
public:
std::atomic<node<T>*> head = nullptr;
void push(const T& data)
{
node<T>* new_node = new node<T>(data);
new_node->next = head.load(std::memory_order_relaxed);
while (!head.compare_exchange_weak(new_node->next, new_node, std::memory_order_release, memory_order_relaxed))
;
}
};
}
namespace lock
{
template<class T>
class stack
{
public:
node<T>* head = nullptr;
void push(const T& data)
{
node<T>* new_node = new node<T>(data);
new_node->next = head;
head = new_node;
}
};
}
int main()
{
lock_free::stack<int> s1;
lock::stack<int> s2;
std::mutex mtx;
int n = 1000000;
auto lock_free_stack = [&s1, n]() {
for (size_t i = 0; i < n; i++)
{
s1.push(i);
}
};
auto lock_stack = [&s2, n, &mtx]() {
for (size_t i=0; i < n; i++)
{
std::lock_guard < std::mutex > lock(mtx);
s2.push(i);
}
};
size_t begin1 = clock();
std::vector<std::thread> threads1;
for (size_t i=0; i < 4; i++)
{
threads1.emplace_back(lock_free_stack);
}
for (auto& e : threads1)
{
e.join();
}
size_t end1 = clock();
std::cout << end1 - begin1 << endl;
size_t begin2 = clock();
std::vector<std::thread> threads2;
for (size_t i = 0; i < 4; i++)
{
threads2.emplace_back(lock_stack);
}
for (auto& e : threads2)
{
e.join();
}
size_t end2 = clock();
std::cout << end2 - begin2 << std::endl;
return 0;
}代码解释:
定义两种原子操作,一个是无锁模式,一个是有锁模式。无锁模式用compare_exchange_weak函数实现,定义原子对象头节点。无锁模式就是正常的插入结点。主函数中,定义了无锁对象和有锁对象,以及一把锁。接着实现了两个lambda分别对应有锁和无锁模式,接着用clock函数来计数时间差,获取消耗时间。
4.自旋锁实现
#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
//#include<chrono>
#include<vector>
using namespace std;
class SpinLock
{
private:
std::atomic_flag flag = ATOMIC_FLAG_INIT;
public:
void Lock()
{
// test_and_set将内部值设置为true,并且返回之前的值
// 第⼀个进来的线程将值原⼦的设置为true,返回false
// 后⾯进来的线程将原⼦的值设置为true,返回true,所以卡在这⾥空转,
// 直到第⼀个进去的线程unlock,clear,将值设置为false
while (flag.test_and_set())
;
}
void unlock()
{
// clear将值原⼦的设置为false
flag.clear();
}
};
void worker(SpinLock& lock, int& val)
{
lock.Lock();
for (int i = 0; i < 1000; i++)
{
val++;
}
lock.unlock();
}
int main()
{
SpinLock lock;
int val = 0;
std::vector<thread> threads;
for (int i = 0; i < 4; i++)
{
threads.emplace_back(worker, std::ref(lock), std::ref(val));
}
for (auto& thread : threads)
{
thread.join();
}
std::cout << "val:" << val << endl;
return 0;
}代码解释:
std::atomic_flag 是 C++ 标准库中的一个类型,它提供了一种轻量级的同步原语,通常用于实现锁或其他同步机制。std::atomic_flag 表示一个原子布尔变量,它可以处于两种状态之一:清零(false)或置一(true)。
自旋锁就是会卡在循环出不来,只有标志位改变了,才能出循环,第一个进入lock执行while就会改变标志位的值为true,只有解锁才能改变标志位的值为false,其它线程就会在while一直空转。
5.condition_variable
condition_variable需要配合互斥锁系列使用,主要提供wait和notify系统接口。
wait需要传递一个unique_lock<mutex>类型的互斥锁,wait会阻塞当前线程直到被notify。在进入阻塞的一瞬间,会解开互斥锁,给其它线程获取锁,访问条件变量。被notify唤醒,会继续获取锁,再继续往下执行。
notify_one会唤醒当前条件变量上等待的其中之一线程,使用时也需要用互斥锁保护,如果没有阻塞等待,就无事发生。notify_all会唤醒当前条件变量上等待的所有线程。
代码示例
#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
//#include<chrono>
#include<vector>
using namespace std;
std::mutex mtx;
std::condition_variable cv;
bool ready = false;
void print_id(int id)
{
std::unique_lock<std::mutex> lck(mtx);
while (!ready)
cv.wait(lck);
std::cout << "thread" << id << endl;
}
void go()
{
std::unique_lock<std::mutex> lck(mtx);
ready = true;
cv.notify_all();
}
int main()
{
std::thread threads[10];
for (int i = 0; i < 10; i++)
{
threads[i] = std::thread(print_id, i);
}
std::cout << "10 threads ready" << endl;
std::this_thread::sleep_for(std::chrono::milliseconds(100));
go();
for (auto& e : threads)
{
e.join();
}
return 0;
}
代码解释:
主线程创建的10个线程都会执行print函数,print函数会有wait挂起线程,并释放锁,所以每一个线程都能进来然后别挂起。主线程就延时保证全部线程都进入条件变量,再执行go函数,唤醒所有线程去争夺锁资源。
代码二两个线程交替打印奇数和偶数
#include<atomic>
#include<iostream>
#include<thread>
#include<mutex>
//#include<chrono>
#include<vector>
using namespace std;
int main()
{
std::mutex mtx;
std::condition_variable cv;
int n = 100;
bool flag = true;
std::thread t1([&]() {
int i = 0;
while (i < n)
{
std::unique_lock<std::mutex> lock(mtx);
while (!flag)
{
cv.wait(lock);
}
cout << i << endl;
flag = false;
i += 2;
cv.notify_one();
}
});
std::thread t2([&]() {
int j = 1;
while (j < n)
{
std::unique_lock<std::mutex> lock(mtx);
while (flag)
{
cv.wait(lock);
}
cout << j << endl;
flag = true;
j += 2;
cv.notify_one();
}
});
t1.join();
t2.join();
return 0;
}
代码解释:
两个线程一个打印偶数,一个打印奇数,用flag标志位来控制,开始为true,线程一就不会进入条件变量,而线程二会进入条件变量挂起,等待线程一唤醒,所以无论位置如何,都是线程一先打印,也不会出现一个线程结束唤醒其它线程,然后唤醒的线程没拿到锁,又被结束线程拿到,flag会解决问题。