一、系统调用sys_mmap
系统调用mmap用来创建内存映射,把创建内存映射主要的工作委托给do_mmap函数,内核源码文件处理:mm/mmap.c

二、系统调用sys_munmap
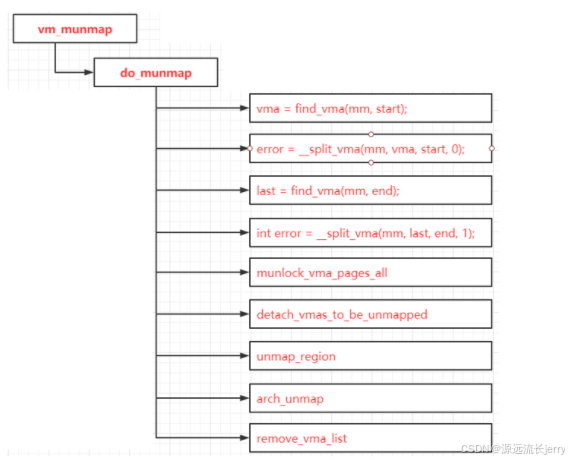
1、vma = find_vma (mm, start); // 根据起始地址找到要删除的第一个虚拟内存区域 vma
2、如果只删除虚拟内存区域 vam 的部分,那么分裂虚拟内存区域 vma
3、根据结束地址找到要删除的最后一个虚拟内存区域 vma
4、如果只删除虚拟内存区域 last 的一部分,那么分裂虚拟内存区域 vma
5、针对所有删除目标,若虚拟内存区域被锁定在内存中(不允许换出到交换区),调用函数解除锁定。
6、调用函数,将所有删除目标从进程虚拟内存区域链表和树中删除,单独组成临时链表。
7、调用函数,针对所有删除目标,在进程页表中删除映射,且从处理器页表缓存中删除映射。
8、调用函数执行处理器架构特定处
三、物理内存组织结构
1.体系结构
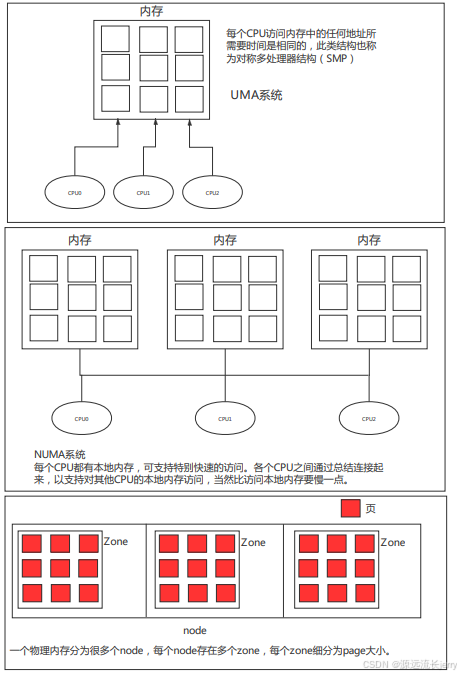
目前多处理器系统有两种体系结构:
1)非一致内存访问(Non-Unit Memory Access,NUMA):指内存被划分成多个内存节点的多处理器系统,访问一个内存节点花费的时间取决于处理器和内存节点的距离。
2)对称多处理器(Symmetric Multi-Processor,SMP):即一致内存访问(Uniform Memory Access,UMA),所有处理器访问内存花费的时间相同。
示例图如下:
2.内存模型
内存模型是从处理器角度看到的物理内存分布,内核管理不同内存模型的方式存在差异。内存管理子系统支持 3 种内存模型:
1)平坦内存(Flat Memory)
2)不连续内存(Discontiguous Memory)
3)稀疏内存(Space Memory)
平坦内存(Flat Memory)
- 结构特点:将系统的物理内存视为一个连续的整体,所有内存地址线性排列,不存在内存分段或区间划分。虚拟地址空间和物理地址空间映射直接,就像一条连续的、没有断点的道路 。
- 管理方式:简单直接,通常使用一个数组(如
struct page mem_map数组 )来管理所有内存页,通过简单的地址偏移就能找到对应的物理内存页。- 优势:
- 简单高效:内存管理实现不复杂,地址转换简单,系统可直接访问内存,减少地址转换开销 。
- 易于实现:适用于内存较小、硬件资源有限的架构,在早期计算机系统或一些小型嵌入式系统中应用较多。
- 劣势:如果物理地址空间存在空洞(如某些地址范围不能被使用),会造成内存浪费,因为要为所有地址创建对应的管理结构 。
- 举例:早期个人计算机内存容量较小且硬件相对简单,内存模型近似平坦内存模型,操作系统可简单地将内存按顺序划分和管理 ;一些简单的嵌入式设备,如简单的单片机系统,也常采用这种内存模型,因为其内存需求单一、硬件资源有限 。
不连续内存模型(Non-contiguous Memory Model)
不连续内存模型是一种内存管理方式,内存分配的各个区域不要求在物理内存中连续,进程虚拟内存空间可映射到物理内存中分散、不连续的任意位置。
特点:
- 物理内存不连续:内存无需物理连续,操作系统可将进程虚拟内存映射到物理内存的多个不连续区域。
- 内存管理灵活:支持更灵活的内存分配,高效使用内存,减少碎片。
- 页面管理:常见实现为分页内存管理,虚拟地址空间和物理内存划分为页面与页框,虚拟页通过页表映射到任意物理页。
例子:
- 分页(Paging):内存划分为固定大小页面(如 4KB),虚拟地址与物理地址通过页表映射,虚拟页可映射到任意物理页,虚拟内存与物理内存不连续。
稀疏内存模型(Sparse Memory Model)
稀疏内存模型指虚拟内存中部分区域不映射物理内存,甚至完全为空,虚拟内存空间非每块都对应物理地址,呈 “稀疏” 状态。
特点:
- 内存区域稀疏:虚拟内存部分区域无实际物理内存映射,部分虚拟地址不对应物理地址。
- 懒加载:操作系统按需分配物理内存,如进程访问无对应物理内存的虚拟地址时,触发缺页异常后再分配内存。
- 高效内存使用:允许区域不映射物理内存,在大内存系统中减少不必要分配,提升内存使用效率。
例子:
- 稀疏虚拟内存:操作系统不为大虚拟地址空间(如 64 位系统)全部分配物理内存,Linux 中
mmap或mprotect系统调用可创建无实际物理内存映射的稀疏区域。
3.三级结构
内存管理子系统使用节点(node)、区域(zone)、页(page)三级结构描述物理内存。
a、内存节点 —— 分为两种情况:
(1)NUMA 体系的内存节点,根据处理器和内存的距离划分;
(2)在具有不连续内存的 NUMA 系统中,表示比区域级别更高的内存区域,根据物理地址是否连续划分,每块物理地址连续的内存是一个内存节点。
1.内存节点使用pglist_data结构体描述物理内存布局:(该结构体对应上图中的node)

node_mem_map 此成员指向页描述符数组,每个物理页对应一个页描述符。
Node 是内存管理最顶层的结构,在 NUMA 架构下,CPU 平均划分为多个 Node,每个 Node 有自己的内存控制器及内存插槽。CPU 访问自己 Node 上内存速度快,而访问其他 CPU 所关联 Node 的内存速度慢。UMA 被当做只一个 Node 的 NUMA 系统。
2.内存区域(zone)

结构体关系总结:
pglist_data是管理一个 NUMA 节点的结构体,包含该节点所有的zone。zone代表内存的一个区域,管理着这个区域的页面和空闲页面的链表。zonelist是一个zone的列表,表示多个内存区域的优先级顺序。zoneref是对某个zone的引用,通常在内存分配上下文中使用。pglist_data(对应内存节点 node) | |——> zone(多个 zone 组成内存节点的内存区域,如 ZONE_DMA、ZONE_NORMAL 等) | | | |——> page(每个物理页面由 struct page 描述符管理) | |——> zonelist(独立于 zone 的数据结构,是多个 zone 组成的链表,定义内存分配时 zone 的优先级查找顺序) | | | |——> zoneref(作为 zonelist 的元素,指向具体 zone,用于在内存分配流程中引用 zone)内存分配的流程:
在内核进行内存分配时,通常按以下流程:
- 查找可用的
zone:内核先根据zonelist顺序查找可用的zone。- 从
zone获取页面:在选定的zone中查找空闲页面,若无空闲页面,可能触发慢路径(如回收页面)。- 返回页面:找到空闲页面后,内核分配页面。
zone包含的内存类型:
- 普通内存(ZONE_NORMAL)
定义:普通内存区域是指可以直接被内核和用户程序访问的内存,通常涵盖物理内存地址空间中从低端开始的一段连续区域。
特点:- 访问速度相对较快,因直接映射到内核的线性地址空间。
- 适用于大部分内核数据结构和用户进程的数据存储。
- 在 32 位系统中,若未启用高端内存(ZONE_HIGHMEM),ZONE_NORMAL 可能占据大部分物理内存。
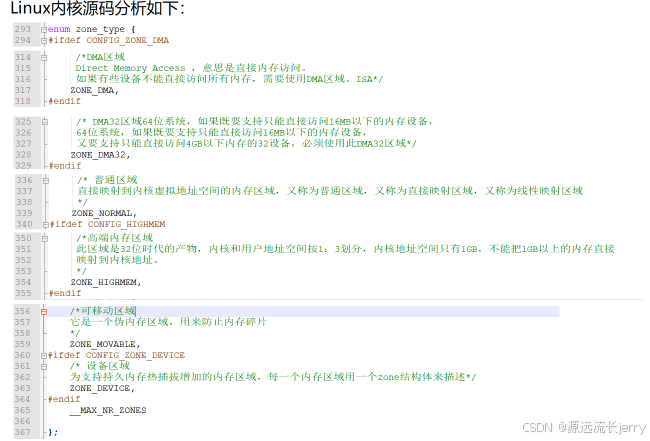
- DMA 区域(ZONE_DMA)
定义:为满足设备进行 DMA(直接内存访问)操作而保留的内存区域。
特点:- 位于物理内存的较低地址部分,因一些老式 DMA 控制器只能访问物理内存的低地址区域(如 ISA 总线下的设备)。
- 区域大小通常较小,用于存储需通过 DMA 方式传输的数据(如网络数据包、磁盘数据等)。
- 确保设备可不经过 CPU 干预直接访问内存,提高数据传输效率。
- 高端内存(ZONE_HIGHMEM)
定义:在 32 位系统中,因内核线性地址空间限制(通常仅 1GB 或 2GB 留给内核,取决于内核配置),物理内存超出内核线性地址空间能直接映射范围的部分。
特点:- 高端内存不能被内核直接访问,需通过特殊映射机制(如临时映射)访问。
- 在 64 位系统中,因线性地址空间充足,高端内存概念可能不再适用或重要性降低。
- 主要用于 32 位系统管理超出内核直接映射范围的物理内存。
- 可移动内存(ZONE_MOVABLE)
定义:特殊内存区域,主要用于存放可移动的内存页。
特点:- 便于内存碎片整理,通过集中放置可移动内存页,整理时更易移动这些页,腾出连续物理内存空间。
- 通常用于用户空间的匿名内存(如堆和栈),这些内存页必要时可移动到其他物理位置。
- 这些不同类型内存区域满足不同硬件和软件需求,确保系统高效、稳定运行。
在 Linux 内核中,通常一个内存节点(NUMA node,对应结构体
pglist_data)中的每个内存区域(zone)只会描述一个特定的内存类型(如ZONE_NORMAL、ZONE_DMA、ZONE_HIGHMEM等)。因此,通常情况下,一个内存节点不会有多个相同类型的内存区域(比如两个ZONE_NORMAL或两个ZONE_DMA区域)。为什么一个节点中只有一个
ZONE_NORMAL或ZONE_DMA?在内核的内存管理中,内存区域(
zone)用于区分不同类型的内存,这些内存类型的访问方式、大小和用途各不相同。例如:
ZONE_NORMAL:普通内存区域,用于应用程序内存分配,内核空间和用户空间均可使用。ZONE_DMA:为 DMA(直接内存访问)设备保留的内存区域,这类设备通常只能访问低于特定物理地址的内存,需单独划分区域。ZONE_HIGHMEM:高端内存区域,指超过内核线性地址空间限制的内存,主要用于 32 位系统。这些内存区域依内存物理地址范围、用途及硬件限制划分,每个区域有独立物理地址范围限制,因此一个物理内存节点通常只有一个
ZONE_NORMAL、一个ZONE_DMA和一个ZONE_HIGHMEM区域。
struct pglist_data和struct zone之间的关系在 NUMA 架构中,每个内存节点(
struct pglist_data)包含多个内存区域(struct zone)。例如,一个内存节点可能包含以下区域:
ZONE_NORMAL(普通内存)ZONE_DMA(DMA 内存)ZONE_HIGHMEM(高端内存)在此情况下,每个内存节点有一个
ZONE_NORMAL区域、一个ZONE_DMA区域和一个ZONE_HIGHMEM区域,这些zone相互独立,分别描述不同内存类型。每个struct zone表示特定类型的内存区域,而非整个内存节点。为什么不会有多个相同类型的
zone?内存区域(
zone)基于物理内存特性划分,一个物理内存区域只能属于特定类型。例如:
ZONE_NORMAL:包含地址空间内大部分可用内存,是应用程序和内核的主要内存区域。ZONE_DMA:针对 DMA 设备划分,包含低于特定物理地址的内存(如低于 1GB 或 4GB,取决于架构和硬件限制)。ZONE_HIGHMEM:为超出内核虚拟地址空间限制的内存保留,常见于 32 位系统。可能的例外情况
尽管一般情况下,每个内存节点只含一个特定类型的
zone,但以下情况可能导致变化:
- 区域类型调整:特定硬件配置或适配可能允许多个物理内存区域被视为一个逻辑区域,取决于硬件支持和内核实现。
- 动态调整:内核在内存分配管理中,可能通过区域划分调整、内存回收等机制动态调整或合并内存区域,但不意味着同一节点会有多个相同类型的
zone。- NUMA 节点间重叠:复杂硬件平台上,内存节点的物理地址空间可能重叠,导致节点共享内存区域。此时,内核可能处理区域合并或重映射,但每个节点内仍通常只有一个
ZONE_NORMAL、一个ZONE_DMA和一个ZONE_HIGHMEM。
3.物理页
每个物理页对应一个 page 结构体,称为页描述符,内存节点的 pglist_data 实例的成员 node_mem_map 指向该内存节点包含的所有物理页的页描述符组成的数组。Linux 内核源码分析:include/linux/mm_types.h

页是内存管理当中的最小单位,页面中的内存其物理地址是连续的,每个物理页由 struct page 描述。为了节省内存,struct page 是个联合体。
页,又称为页帧,在内核当中,内存管理单元 MMU(负责虚拟地址和物理地址转换的硬件)是把物理页 page 作为内存管理的基本单位。体系结构不同,支持的页大小也相同。
32 位体系结构支持 4kb 的页
64 位体系结构支持 8kb 的页
MIPS64 架构体系支持 16kb 的页。
https://github.com/0voice