理解词嵌入
重要的是,进行one-hot编码时,你做了一个与特征工程有关的决策。你向模型中注入了有关特征空间结构的基本假设。这个假设是:你所编码的不同词元之间是相互独立的。事实上,one-hot向量之间都是相互正交的。对于单词而言,这个假设显然是错误的。单词构成了一个结构化的空间,单词之间共享信息。在大多数句子中,“movie”和“film”这两个词是可以互换的,所以表示“movie”的向量与表示“film”的向量不应该正交,它们应该是同一个向量,或者非常相似。说得更抽象一点,两个词向量之间的几何关系应该反映这两个单词之间的语义关系。例如,在一个合理的词向量空间中,同义词应该被嵌入到相似的词向量中,一般来说,任意两个词向量之间的几何距离(比如余弦距离或L2距离)应该与这两个单词之间的“语义距离”有关。含义不同的单词之间应该相距很远,而相关的单词应该相距更近。词嵌入是实现这一想法的词向量表示,它将人类语言映射到结构化几何空间中。
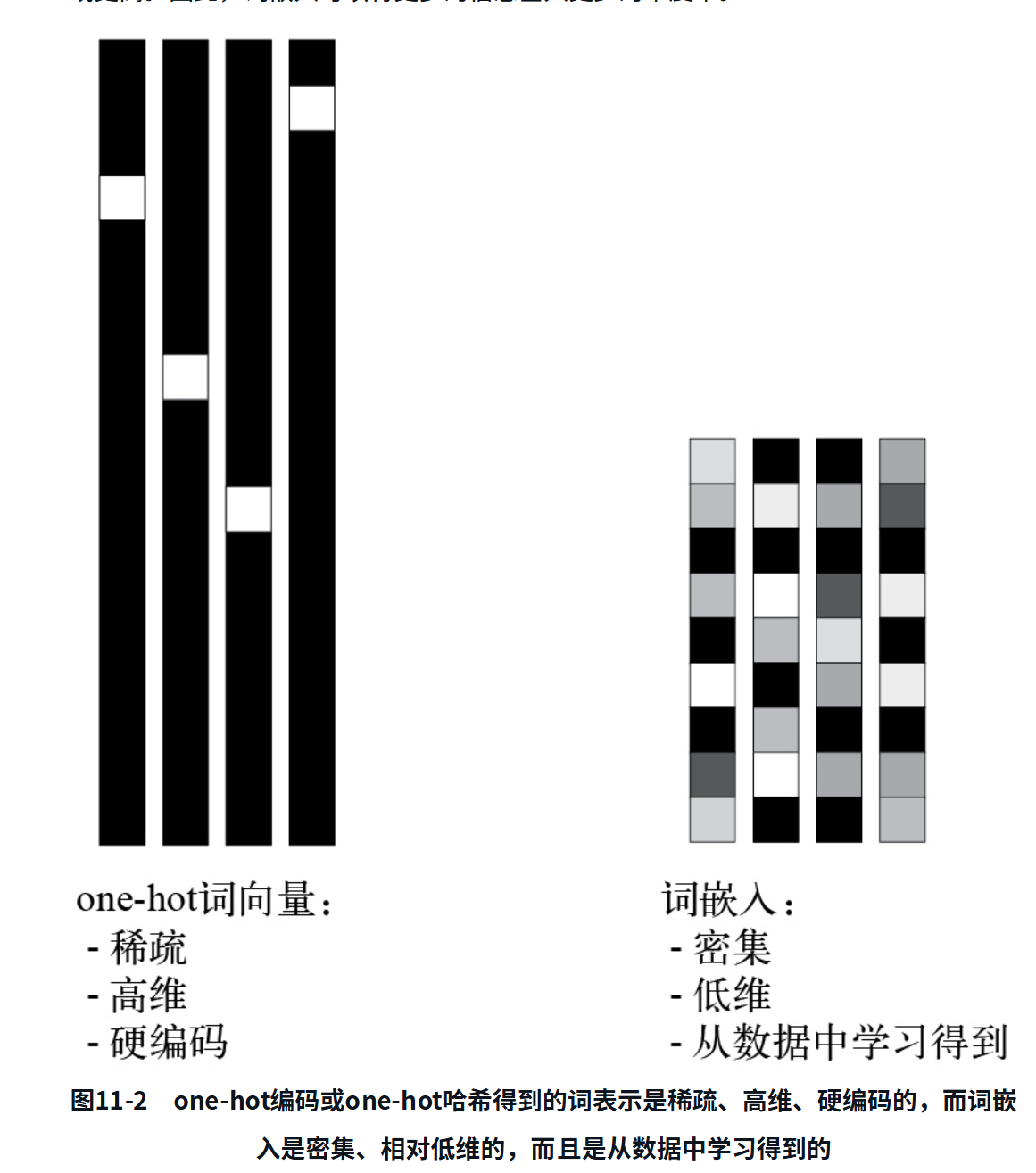
one-hot编码得到的向量是二进制的、稀疏的(大部分元素是0)、高维的(维度大小等于词表中的单词个数),而词嵌入是低维的浮点向量(密集向量,与稀疏向量相对),如图11-2所示。常见的词嵌入是256维、512维或1024维(处理非常大的词表时)。与此相对,one-hot编码的词向量通常是20 000维(词表中包含20 000个词元)或更高。因此,词嵌入可以将更多的信息塞入更少的维度中。
词嵌入是密集的表示,也是结构化的表示,其结构是从数据中学习得到的。相似的单词会被嵌入到相邻的位置,而且嵌入空间中的特定方向也是有意义的。为了更清楚地说明这一点,我们来看一个具体示例。在图11-3中,4个词被嵌入到二维平面中:这4个词分别是Cat(猫)、Dog(狗)、Wolf(狼)和Tiger(虎)。利用我们这里选择的向量表示,这些词之间的某些语义关系可以被编码为几何变换。例如,从Cat到Tiger的向量与从Dog到Wolf的向量相同,这个向量可以被解释为“从宠物到野生动物”向量。同样,从Dog到Cat的向量与从Wolf到Tiger的向量也相同,这个向量可以被解释为“从犬科到猫科”向量。

在现实世界的词嵌入空间中,常见的有意义的几何变换示例包括“性别”向量和“复数”向量。例如,将“king”(国王)向量加上“female”(女性)向量,得到的是“queen”(女王)向量。将“king”(国王)向量加上“plural”(复数)向量,得到的是“kings”向量。词嵌入空间通常包含上千个这种可解释的向量,它们可能都很有用。我们来看一下在实践中如何使用这样的嵌入空间。有以下两种方法可以得到词嵌入。在完成主任务(比如文档分类或情感预测)的同时学习词嵌入。在这种情况下,一开始是随机的词向量,然后对这些词向量进行学习,学习方式与学习神经网络权重相同。在不同于待解决问题的机器学习任务上预计算词嵌入,然后将其加载到模型中。这些词嵌入叫作预训练词嵌入(pretrained word embedding)。我们来分别看一下这两种方法。
利用Embedding层学习词嵌入
是否存在一个理想的词嵌入空间,它可以完美地映射人类语言,并可用于所有自然语言处理任务?这样的词嵌入空间可能存在,但我们尚未发现。此外,并不存在人类语言这种东西。世界上有许多种语言,它们之间并不是同构的,因为语言反映的是特定文化和特定背景。但从更实际的角度来说,一个好的词嵌入空间在很大程度上取决于你的任务,英语影评情感分析模型的完美词嵌入空间,可能不同于英语法律文件分类模型的完美词嵌入空间,因为某些语义关系的重要性因任务而异。因此,合理的做法是对每个新任务都学习一个新的嵌入空间。幸运的是,反向传播让这种学习变得简单,Keras则使其变得更简单。我们只需学习Embedding层的权重,如代码清单11-15所示。
代码清单11-15 将Embedding层实例化
embedding_layer = layers.Embedding(input_dim=max_tokens, output_dim=256) ←---- Embedding层至少需要两个参数:词元个数和嵌入维度(这里是256)
你可以将Embedding层理解为一个字典,它将整数索引(表示某个单词)映射为密集向量。它接收整数作为输入,在内部字典中查找这些整数,然后返回对应的向量。Embedding层的作用实际上就是字典查询,
如图11-4所示。

Embedding层的输入是形状为(batch_size, sequence_length)的2阶整数张量,其中每个元素都是一个整数序列。该层返回的是一个形状为(batch_size,sequence_length, embedding_dimensionality)的3阶浮点数张量。将Embedding层实例化时,它的权重(内部的词向量字典)是随机初始化的,就像其他层一样。在训练过程中,利用反向传播来逐渐调节这些词向量,改变空间结构,使其可以被下游模型利用。训练完成之后,嵌入空间会充分地显示结构。这种结构专门针对模型训练所要解决的问题。我们来构建一个包含Embedding层的模型,为我们的任务建立基准,如代码清单11-16所示。
代码清单11-16 从头开始训练一个使用Embedding层的模型
inputs = keras.Input(shape=(None,), dtype="int64")
embedded = layers.Embedding(input_dim=max_tokens, output_dim=256)(inputs)
x = layers.Bidirectional(layers.LSTM(32))(embedded)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("embeddings_bidir_gru.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=10,
callbacks=callbacks)
model = keras.models.load_model("embeddings_bidir_gru.keras")
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")
模型训练速度比one-hot模型快得多(因为LSTM只需处理256维向量,而不是20 000维),测试精度也差不多(87%)。然而,这个模型与简单的二元语法模型相比仍有一定差距。部分原因在于,这个模型所查看的数据略少:二元语法模型处理的是完整的评论,而这个序列模型在600个单词之后截断序列。











![[MySQL初阶]MySQL(8)索引机制:下](https://i-blog.csdnimg.cn/direct/2c4f3c1888d641ff94c68b40d9f7a20b.png#pic_center)
![Muduo网络库实现 [九] - EventLoopThread模块](https://i-blog.csdnimg.cn/direct/8f7309bbfd0b4dd79476aa4c66ddf5ca.png)