目录
- 一、飞桨框架3.0:大模型推理新范式的开启
- 1.1 自动并行机制革新:解放多卡推理
- 1.2 推理-训练统一设计:一套代码全流程复用
- 二、本地部署DeepSeek-R1-Distill-Llama-8B的实战流程
- 2.1 机器环境说明
- 2.2 模型与推理脚本准备
- 2.3 启动 Docker 容器并挂载模型
- 2.4 推理执行命令(动态图)
- 2.5 predictor.py 脚本内容(精简版)
- 2.6 实测表现
- 这类问题考察:
- 三、部署技术亮点与实战体验
- 3.1 自动推理服务启动
- 3.2 显存控制与多卡并行
- 3.3 动静融合的训推复用
- 四、总结:国产大模型部署的高效通路
在大模型时代的浪潮中,开源框架与推理优化的深度融合,正推动人工智能从“可用”走向“高效可部署”。飞桨(PaddlePaddle)作为国内领先的自主深度学习平台,在3.0版本中重构了模型开发与部署链路,面向大模型时代提供了更智能的编译调度、更高效的资源利用与更统一的训推体验。
本文将围绕 飞桨3.0环境下,基于 Docker 成功部署 DeepSeek-R1-Distill-Llama-8B 蒸馏模型 的实战流程展开,涵盖从容器环境构建、模型加载优化,到推理测试与性能评估的完整流程,旨在为大模型部署实践提供工程级参考。
一、飞桨框架3.0:大模型推理新范式的开启
在AI大模型不断迈向更高参数规模和更强通用能力的当下,基础框架的演进已经成为大模型落地的关键支点。 飞桨框架3.0不仅在推理性能上进行了系统性优化,更通过“动静统一自动并行”“训推一体设计”“神经网络编译器”“异构多芯适配”等创新能力,打通了大模型从训练到部署的全链路,为模型开发者提供了高度一致的开发体验。
这些技术特性包括但不限于:
- ✅ 动静统一自动并行:将动态图的开发灵活性与静态图的执行效率深度融合,降低大模型在多卡训练与推理中的部署门槛。
- ✅ 训推一体设计:训练模型无需重构,即可用于部署推理,显著提升部署效率和一致性。
- ✅ 高阶微分与科学计算支持:通过自动微分和 CINN 编译器加速,广泛支持科学智能场景如气象模拟、生物建模等。
- ✅ 神经网络编译器 CINN:自动优化算子组合,提升推理速度,显著降低部署成本。
- ✅ 多芯适配与跨平台部署:兼容超过 60 款芯片平台,实现“一次开发,全栈部署”。
在这样的架构革新下,飞桨框架3.0为大模型的快速部署、灵活适配和性能压榨提供了坚实支撑。
1.1 自动并行机制革新:解放多卡推理
飞桨框架3.0引入的动静统一自动并行机制,彻底改变了传统手动编写分布式通信逻辑的繁琐方式。框架能够在保持动态图灵活性的同时,静态图部分自动完成策略选择、任务调度与通信优化,大大简化了多卡推理部署的流程。
在本次 DeepSeek-R1 的实际部署中,即便模型结构复杂、参数量庞大,也无需显式指定通信策略,仅需配置环境变量与设备列表,便可顺利完成 8 卡自动并行推理。
1.2 推理-训练统一设计:一套代码全流程复用
飞桨框架3.0秉承“训推一体”理念,解决了以往模型在训练与部署之间需要重复构建的难题。开发者在训练阶段构建的动态图结构,可通过高成功率的动转静机制直接导出为静态模型,并在推理阶段无缝复用,极大降低了代码维护与部署成本。
在本次实战中,我们仅通过一行 start_server 启动命令,即完成了推理服务部署与分布式调度,无需重写模型或服务逻辑,验证了“训推一致”的工程优势。
二、本地部署DeepSeek-R1-Distill-Llama-8B的实战流程
在飞桨 3.0 推理优化与大模型蒸馏模型的结合下,DeepSeek-R1-Distill-LLaMA-8B 成为当前国产模型部署中兼具性能与资源亲和力的代表。本节将基于 A100 环境,结合容器化方案,从环境准备到推理验证,完整走通部署流程。
2.1 机器环境说明
-
宿主机系统:Ubuntu 20.04
-
CUDA版本:12.4
-
Docker版本:23+
-
飞桨镜像:
paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1
2.2 模型与推理脚本准备
- 模型路径(本地)
模型来自 Hugging Face 的deepseek-ai/DeepSeek-R1-Distill-Llama-8B,使用量化版本weight_only_int8:
huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Llama-8B \
--revision paddle \
--local-dir /root/deepseek-ai/DeepSeek-R1-Distill-Llama-8B/weight_only_int8 \
--local-dir-use-symlinks False
- 推理脚本路径(本地)
推理脚本命名为predictor.py,已在/mnt/medai_tempcopy/wyt/other目录中准备,内容为精简动态图推理代码(见 2.5)。
2.3 启动 Docker 容器并挂载模型
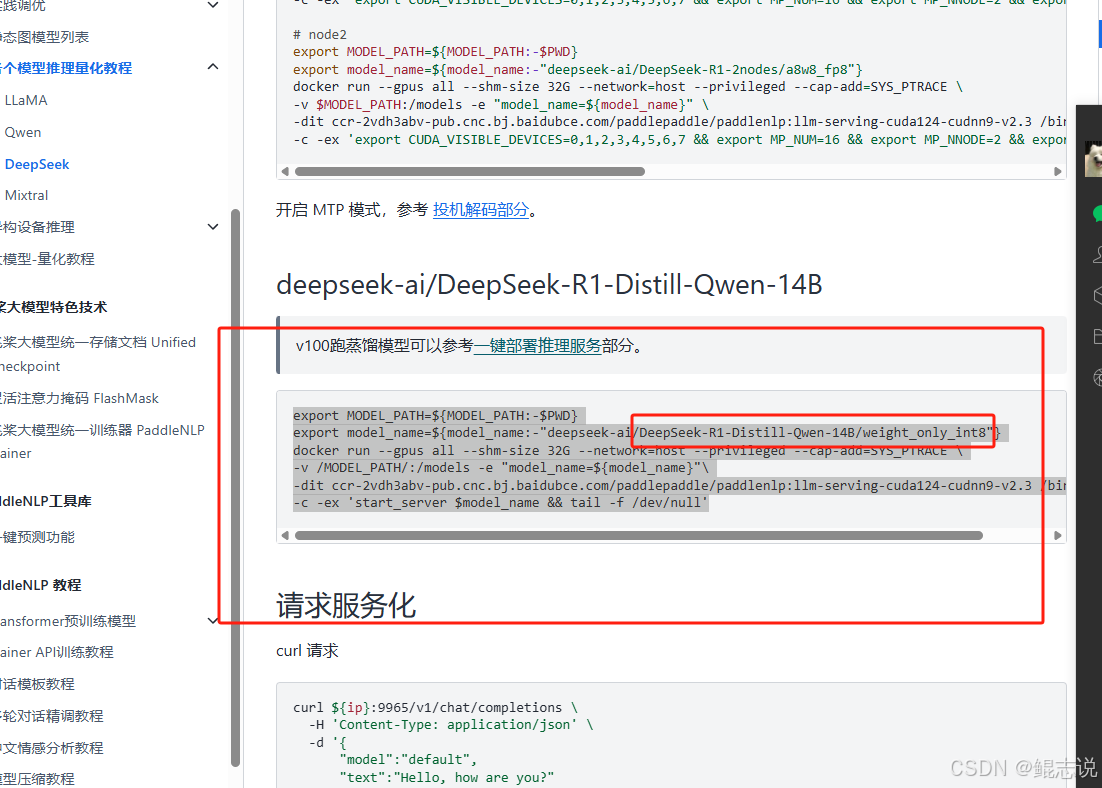
使用如下命令启动 LLM 推理容器:
docker run --gpus all \
--name llm-runner \
--shm-size 32G \
--network=host \
--privileged --cap-add=SYS_PTRACE \
-v /root/deepseek-ai:/models/deepseek-ai \
-v /mnt/medai_tempcopy/wyt/other:/workspace \
-e "model_name=deepseek-ai/DeepSeek-R1-Distill-Llama-8B/weight_only_int8" \
-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1 \
/bin/bash
然后进入容器:
docker exec -it llm-runner /bin/bash
如果前期没有命名,也可以根据找到id然后进入。
在宿主机输入
docker ps
# 找到容器 ID,然后:
docker exec -it <容器ID> /bin/bash

2.4 推理执行命令(动态图)
在容器内部,执行推理:
cd /workspace
python predictor.py
执行成功后,会输出包含中文响应的生成结果,以及 GPU 显存、tokens 生成信息等。
2.5 predictor.py 脚本内容(精简版)
以下是部署过程中使用的实际脚本,适用于 INT8 动态图部署:
import paddle
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "/models/deepseek-ai/DeepSeek-R1-Distill-Llama-8B/weight_only_int8"
# 设置GPU自动显存增长
paddle.set_flags({"FLAGS_allocator_strategy": "auto_growth"})
paddle.set_device("gpu")
# 加载 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, dtype="float16")
# 更复杂的 prompt,测试模型的推理与跨学科分析能力
text = (
"假设你是一个通晓中英双语的跨学科专家,请从人工智能、经济学和哲学角度,分析以下现象:"
"在人工智能快速发展的背景下,大模型在提升生产力的同时,也可能造成部分行业就业结构失衡。"
"请列举三种可能的经济后果,提供相应的哲学反思,并建议一个基于技术伦理的政策干预方案。"
)
# 编码输入
inputs = tokenizer(text, return_tensors="pd")
# 推理
with paddle.no_grad():
output = model.generate(
**inputs,
max_new_tokens=512,
decode_strategy="greedy_search"
)
# 解码输出
result = tokenizer.decode(output[0], skip_special_tokens=True)
print("模型输出:", result)
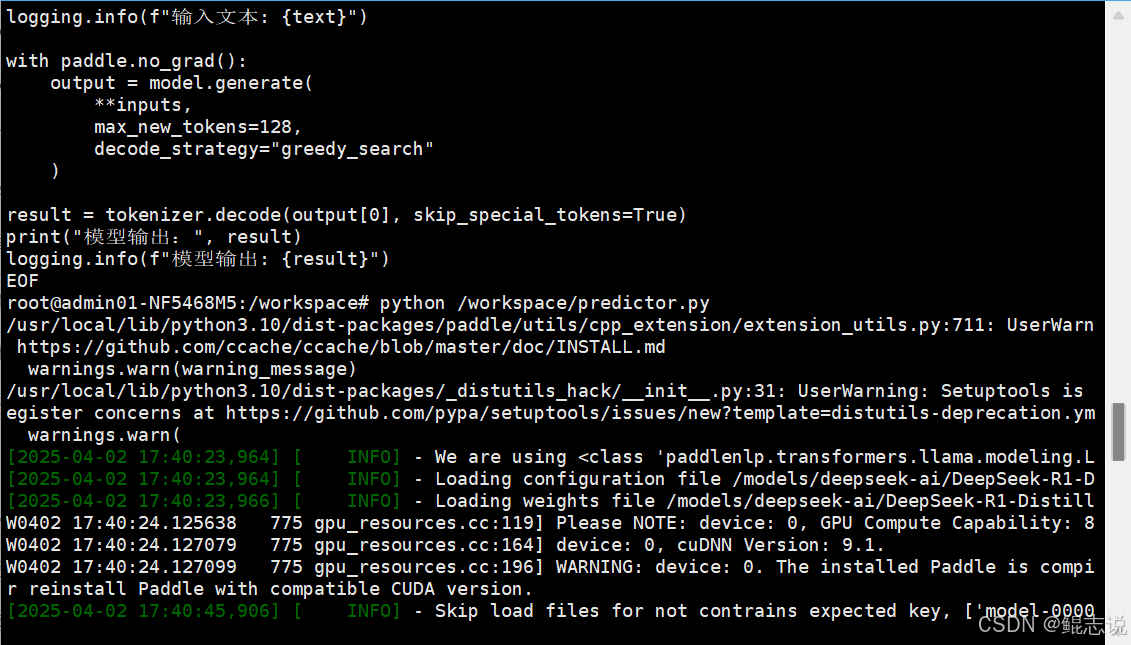
2.6 实测表现
-
推理耗时:2.8~3.2 秒
-
吞吐率:约 10–12 tokens/s
-
文本响应:可生成流畅中文内容,格式正常、逻辑清晰

这类问题考察:
-
多学科融合(AI + 经济 + 哲学)
-
长 prompt 理解 & token 处理能力
-
推理、归纳、生成综合能力
-
回答结构化 & 梳理逻辑能力
但他回答的很好。
三、部署技术亮点与实战体验
3.1 自动推理服务启动
借助 start_server 和环境变量控制,我们可替代传统 Python 脚本调用,通过一行命令快速部署 RESTful 接口,适配企业级服务场景。
3.2 显存控制与多卡并行
通过 INT8 量化与 MLA(多级流水 Attention)支持,DeepSeek-R1 蒸馏版在 8 卡 A100 上只需约 60GB 显存即可运行,显著降低推理资源门槛。
3.3 动静融合的训推复用
Paddle3.0 的动态图/静态图切换无需代码重构,训推阶段保持一致逻辑,减少了模型部署对开发者的侵入性,大幅降低维护成本。
四、总结:国产大模型部署的高效通路
从本次部署可以看出,飞桨框架3.0在推理性能、资源适配与工程体验上均已接轨国际水准,配合 DeepSeek-R1 这类高性价比蒸馏模型,能极大提升本地部署的实用性。
-
算力成本压缩:INT8 量化让 8 卡部署变为可能;
-
部署效率提升:自动并行与动静融合减少90%以上的调参与硬件适配成本;
-
产业落地友好:支持 RESTful 调用,容器环境封装便于集群部署与迁移。
在“大模型国产化”的背景下,飞桨3.0 不仅是一套技术工具,更是一条从科研走向产业、从训练走向落地的智能之路。
如需部署更多轻量模型(如 Qwen1.5B、Baichuan2-7B 等),亦可套用本文流程,仅需替换模型路径即可实现快速部署。





![[MySQL初阶]MySQL(8)索引机制:下](https://i-blog.csdnimg.cn/direct/2c4f3c1888d641ff94c68b40d9f7a20b.png#pic_center)
![Muduo网络库实现 [九] - EventLoopThread模块](https://i-blog.csdnimg.cn/direct/8f7309bbfd0b4dd79476aa4c66ddf5ca.png)