前言:本文将要讲解的高并发内存池,它的原型是Google的⼀个开源项⽬tcmalloc,全称Thread-Caching Malloc,近一个月我将以学习为目的来模拟实现一个精简版的高并发内存池,并对核心技术分块进行精细剖析,分享在专栏《高并发内存池》里,期待小伙伴们的热情支持与关注!
项目专栏:高并发内存池_敲上瘾的博客-CSDN博客
目录
一、CentralCache结构
二、CentralCache与ThreadCache的区别
三、CentralCache如何与ThreadCache联动
1.申请过程
2.释放过程
四、span结构与span链
五、CentralCache类
六、CentralCache类方法
七、源码
上期讲了Thread Cache的实现,但并未对在Central Cache中如何申请内存进行讲解。接下来让我们会对Central Cache的结构和如何在Central Cache中申请内存进行学习和代码实现。
一、CentralCache结构
Central Cache的结构和Thread Cache类似,同样是用一个哈希桶来管理内存,只不过更复杂了些。这种类似的结构也使得在Thread Cache层封装的各种处理方法可以直接拿过来用,方便了很多。
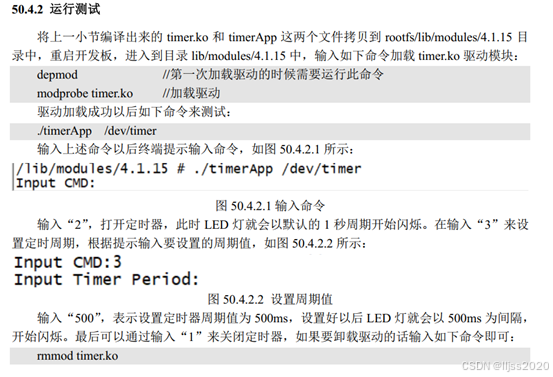
Central Cache的内存管理图如下:
这是一个哈希桶,里面储存的是一个span类型双向链表,span这个单词的意思是:跨度、宽度、跨距...... span是以页为单位的内存,里面又被分割成了多个小的内存块,即自由链表。然后又根据不同的对齐规则得到多个不同span双向链表组成一个桶。
当然一个span里面不单只有自由链表,里面还有各种管理信息,在下文会细讲。
二、CentralCache与ThreadCache的区别
ThreadCache在每个线程内各自有一份,不存在锁的竞争。
CentralCache是所有线程共用唯一一份,它是临界资源,需要加锁,但它不是直接就给哈希桶加一把大锁,而是在哈希桶内每一个span链有独立的锁,把它称为桶锁,所以锁竞争并不激烈。也就是只有当两个线程同类型内存块用完了,并且同时申请span桶,并映射到同一个span链上才会有锁竞争,所以触发概率非常小,效率依旧很高。
三、CentralCache如何与ThreadCache联动
1.申请过程
ThreadCache内自由链表桶没有相应的内存了,会到span桶中找,通过映射关系找到对应的span链,而在span链中只在一个span块中找内存,自由链表桶向span桶申请内存实际上是只要一块的,但是这样一个一个的给效率未免有些太低。就需要多给几块,那该怎么分呢?下文会解答。
当span链中没内存了再向下一层Page Cache申请。
2.释放过程
有时某些线程(线程1)可能需要大量的内存,不断地向span桶中申请。而用完后就被放回它自己的自由链表桶了,后面有线程再需要向span桶申请内存就没得了,大部分内存都堆积在线程1自由链表桶,而线程1又暂时用不了这么多,这个时候就需要还给span桶,来提供给其他线程使用。
因此在span链中,每个span里面的自由链表的节点个数是随机的,并不是第一个span的自由链表空间就是满,也可能是nullptr。
CentralCache在等线程把拿去用的空间全部还回来后,交个下一层PageCache进行整合,缓解内存碎片问题。这也是把span链做成双链表的一个原因,方便任意的span断开给PageCache。而span是怎么知道内存是否被全部还回来呢?其实在span内通过一个_useCount计数器来判断,在下文会提到。
所以CentralCache就起到一个承上启下均衡调度的作用。
四、span结构与span链
span链表的创建和自由链表一样我们放在common.h这个公共的文件里,因为span的内存单位是页,在span里面需要储存起始页的地址,那么这个地址要用什么类型来存是个问题。
地址实际上就是一个数字,假设以8kb为一页,在32位机器上的最大编址就是2^32/8kb = 2^19,如果是64位机器的话,最大的编址是2^64/8kb = 2^51,所以我们通过条件编译来做不同的储存方案。如下:
#ifdef _WIN64
typedef unsigned long long PANGE_ID;
#elif _WIN32
typedef size_t PANGE_ID;
#else
//linux
#endif接下来就只用拿着PANGE_ID这个类型去储存页号就行。
注意:32位机器有_WIN32的定义,但64位机器既有_WIN64的定义又有_WIN32的定义,所以_WIN64的判断必须放在第一位。
Span结构如下:
struct Span
{
PANGE_ID _pageId = 0;//⼤块内存起始⻚的⻚号
size_t _n = 0;//页的数量
struct Span* _prev = nullptr;
struct Span* _next = nullptr;
size_t _useCount = 0;
void* _freeList = nullptr;
//... ...
};- _pageId:内存起始⻚的⻚号
- _n:页的数量。
- _prev,_next:分别为前驱和后驱指针。
- _useCount:记录有多少内存块被使用,当有内存块被使用_useCount++,内存块还回来则_useCount--,所以就可以知道span中的内存是否被全部还回来了。
- _freeList:储存自由链表。
其余的成员函数在本章暂时用不到,就不列出来了。
然后封装一个类,用来做span链表的头,和提供一些操作方法:
class SpanList
{
public:
SpanList()
{}
void Insert(Span* pos, Span* newNode);
void Erase(Span* node);
private:
Span* _head;
public:
std::mutex _mtx;
};- void Insert(Span* pos, Span* newNode):在pos前面插入newNode。
- void Erase():删除节点node。
- Span* _head:链表头节点指针。
- std::mutex _mtx:该链表的锁(桶锁)。
这个是一个双向链表所以在构造函数时就需要申请节点空间,并把指针头尾做连接,如下:
SpanList()
{
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}剩下的两个接口实现就比较基础, 在这里就不再讲解,文末会给出源码。
五、CentralCache类
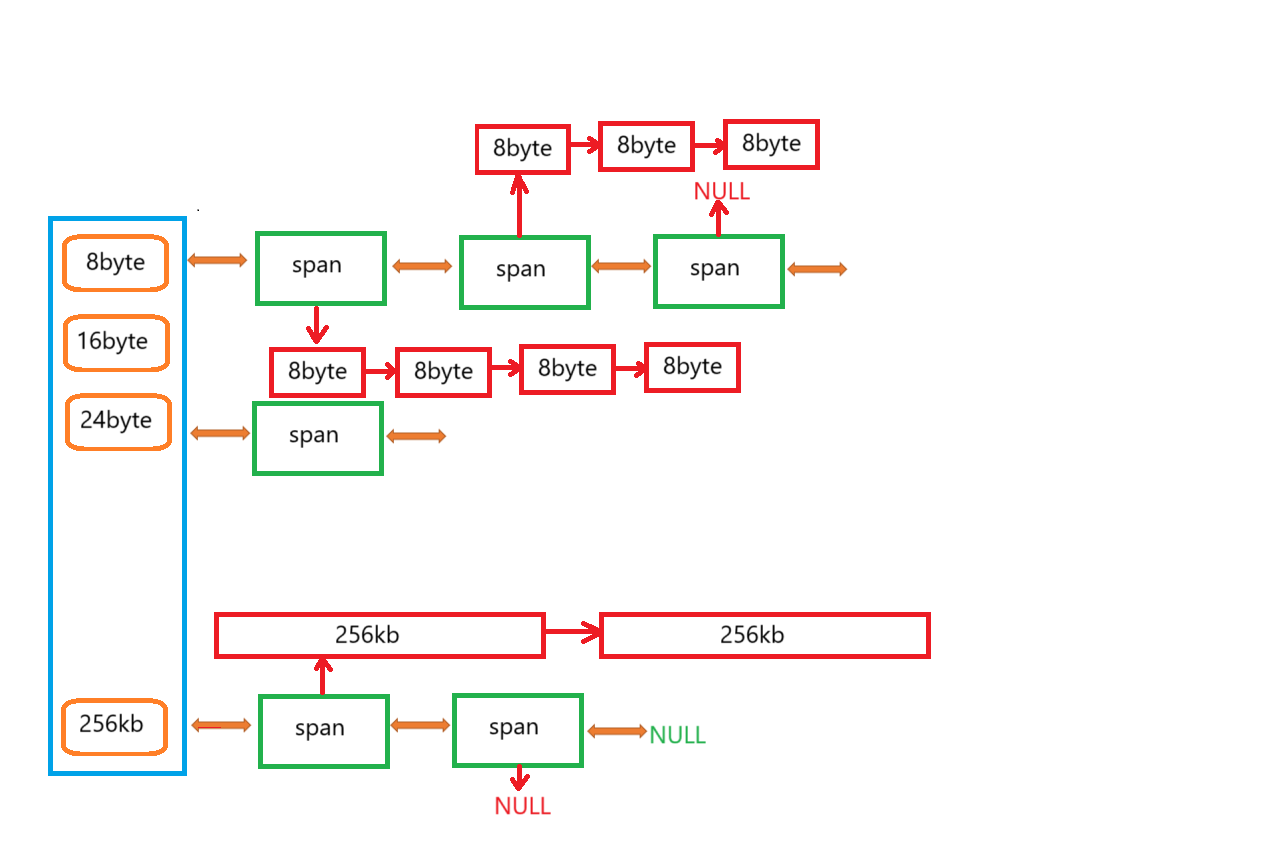
CentralCache类核心就是一个span链表桶,因为所有线程共用一份,所以把它作为单例模式(饿汉模式)防止被创建多份,创建在CentralCache.h文件里。
单例模式需要注意的事项:
- 把构造函数设为私有,不让它默认生成拷贝构造函数,拷贝赋值函数。
- 声明为静态全局变量,最好在.cpp文件里定义。
- 需要定义一个获取单例对象的方法。
class CentralCache
{
private:
CentralCache() {}
CentralCache(const CentralCache&) = delete;
CentralCache& operator=(const CentralCache&) = delete;
public:
static CentralCache* GetInstance();
//......
private:
SpanList _spanLists[FREE_LIST_SIZE];//span桶
static CentralCache _sInst;//CentralCache对象声明
};- GetInstance():获取CentralCache单例对象。
其它类方法在这里先不设,要不然挺突兀的,在下文分析如何申请内存时再根据需要添加。
六、CentralCache类方法
在上篇文章讲到如果ThreadCache中内存不够,需要到CentralCache中申请,大家简单回顾一下,文章链接:高并发内存池(一):项目介绍和Thread Cache实现-CSDN博客
接下来讲的所有内容都是对FetchFromCentralCache接口进行实现。
申请多少空间的问题
上文提到一次不能就只给一块空间,这样效率太低,而给多浪费,给少效率低,该怎么平衡呢?可以做这样的算法处理:
说明:
- size:对齐后用户申请空间的大小。
- batchNum:存申请的内存块个数。
慢开始反馈调节算法:
- size越大,一次向central cache要的batchNum就越小。
- size越小,一次向central cache要的batchNum就越大。
- 最开始不会一次向central cache一次批量要太多,因为要太多了可能用不完。
- 如果不断申请size大小的内存需求,那么batchNum就会不断增长,直到上限。
static int const MAX_BYTES = 256 * 1024;
static inline size_t NumMoveSize(size_t size)
{
int ret = MAX_BYTES / size;
//把个数控制在[2,512]之间
if (ret < 2) ret = 2;
if (ret > 512) ret = 512;
return ret;
}- MAX_BYTES / size:可以让小块内存申请得多一些,大块内存申请得少一些。
- if (ret < 2) ret = 2:申请太少了不足2就补充到2。
- if (ret > 512) ret = 512:申请太多了超过512就截断到512。
因为是对申请内存相关的计算所以把这个函数放到common.h的SizeClass类里,而MAX_BYTES定义放在文件开头更为合理。
以上满足了1,2点要求,针对3,4点,在ThreadCache的自由链表桶里添加成员变量来记录这次该申请多少,然后这个计数会根据申请的次数增加而增加。

注意:为了在外部对_maxSize修改,这个把返回值设为左值引用。
int batchNum = std::min(SizeClass::NumMoveSize(size), _freelists[index].MaxSize());
if (batchNum == _freelists[index].MaxSize())
_freelists[index].MaxSize() += 1;取两种方案得到的最小值,如果这个最小值是_maxSize则_maxSize增大,增大的幅度可以是1,2,3等等,这里就设为1。
内存申请
接下来就是去CentralCache里取batchNum个大小为size的内存,实际上就是取对应的span块中的一小段自由链表,用什么来存储呢?
因为是一段自由链表,就需要获得它的头尾,所以用这样两个变量:
- void* start = nullptr:指向自由链表的头。
- void* end = nullptr:指向自由链表的尾部。
先把代码实现给出,然后再来解释:
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
//计算batchNum大小和一些准备工作
int batchNum = std::min(SizeClass::NumMoveSize(size), _freelists[index].MaxSize());
if (batchNum == _freelists[index].MaxSize())
_freelists[index].MaxSize() += 1;
void* start = nullptr;
void* end = nullptr;
//向CentralCache申请内存
int actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);
assert(actualNum > 1);
if (actualNum == 1)
{
assert(start == end);
return start;
}
else
{
//插入到线程自己的自由链表桶中,因为start将要被使用所以不用插。
_freelists[index].PushRange(Nextobj(start), end);
return start;
}
}内存申请是在span桶内完成的所以在CentralCache中做一个类方法FetchRangeObj,这个函数我们待会来实现,现在先把当前函数逻辑走完。
注意:我们最终只在一个span节点上申请内存,所以span中自由链表节点个数可能不够batchNum个,不过没关系,我们把实际申请到的节点个数返回,这里使用actualNum记录。
现在申请到内存了,需要把它连接到线程自己的自由链表里面,但需要分两种情况:
- 只申请到一个,因为当前用户就需要一个所以不用连接到自由链表,直接返回给用户使用。
- 申请到多个,其中有一个要返回给用户使用,把start的下一个到end这一段连接到线程到自由链表。
这里封装了Nextobj接口用来取到自由链表的下一个节点,实现很简单如下:
static void*& Nextobj(void* obj)
{
return *(void**)obj;
}注意:把它做成静态函数放在common.h文件里供全局使用,返回值类型设为一个引用,这样就可以对节点进行修改。
然后在自由链表里面封装一个方法PushRange,用来实现插入一段自由链表,比较简单直接把它插到头节点后面就行,这里就不在展示,文末会附有源码。
FetchRangeObj的实现
FetchRangeObj是CentralCache的类方法,我们再做一个对应的源文件CentralCache.cpp,然后记得把CentralCache(单例模式)的定义放在这个.cpp文件里面。
在FetchRangeObj首先调用类方法得到span链表桶的下标从而确定相应的span链表,然后上锁。
此时我们只是找到了span链表,然后需要在span链表里找到一个span节点,找span节点这个过程我们再单独封装一个方法GetOneSpan,同样放CentralCache类里面,因为它比较复杂,如果没有可以用的span节点还需要向下一层PageCache申请,该函数在本文不会实现,请期待下一篇博客的讲解!
现在假设我们在GetOneSpan内已经申请到一个span节点,接下来去取内存,让start和end都指向span的自由链表头,然后end往后移并做计数,但是需要注意几个问题:
- 内存可能不够batchNum个,那么有多少取多少。
- 当内存不够时,end会指向空,此时不能再被解引用。
- 取完内存后要对span中自由链表指向进行更新,并把end的next指向nullptr。
实现如下:
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{
//... ...
return nullptr;
}
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{
//计算Span链表桶下标
int index = SizeClass::RoundUp(size);
//需要访问共享资源,加锁
_spanLists[index]._mtx.lock();
//获取一个Span节点
Span* span = GetOneSpan(_spanLists[index], size);
assert(span);
assert(span->_freeList);
//从Span节点中取到小块内存,如果足够batchNum个就取batchNum个,不足则全部取出。
start = end = span->_freeList;
int ret = 1;
while (ret < batchNum && Nextobj(end) != nullptr)
{
end = Nextobj(end);
ret++;
}
span->_freeList = Nextobj(end);
Nextobj(end) = nullptr;
_spanLists[index]._mtx.unlock();
return ret;
}当取完内存后需要做善后处理:
- 更新span自由链表是指向,把它被取走的内存从链表中断开,即span->_freeList = Nextobj(end);
- 把end的下一个节点指向空,目的是和原span中自由链表断开。
- 解锁,返回实际申请的内存数量。
到现在为止CentralCache还没有完全结束,只实现了内存申请部分,还有内存释放的逻辑并未涉及,后续将会持续输出,家人们敬请期待!💕💕
非常感谢您能耐心读完这篇文章。倘若您从中有所收获,还望多多支持呀!

七、源码
代码量比较大,就不放在这里了,需要的小伙伴到我的gitee上取:
ConcurrentMemoryPool/ConcurrentMemoryPool · 敲上瘾/ConcurrentMemoryPool - 码云 - 开源中国
![[Windows] VutronMusic v1.6.0 音乐播放器纯净版,可登录同步](https://i-blog.csdnimg.cn/direct/793b84441fb04ecbb99bf79793baa199.png)




![STM32单片机入门学习——第3-4节: [2-1、2]软件安装和新建工程](https://i-blog.csdnimg.cn/direct/9ebb69abc1a741e6aa2a884c159e7f94.png)