人无完人,持之以恒,方能见真我!!!
共同进步!!
文章目录
- 一、堆排引入之使用堆排序数组
- 二、真正的堆排
- 1.向上调整算法建堆
- 2.向下调整算法建堆
- 3.向上和向下调整算法建堆时间复杂度比较
- 4.建堆后的排序
- 5.堆排序和冒泡排序时间复杂度以及性能比较
- 三、Top-K问题
一、堆排引入之使用堆排序数组
我们之前说过,堆除了是一个完全二叉树之外,还有一个重要特性就是,它的每一颗子树的根节点都是整颗子树的最大或最小值,那么一提到它的这个特性,我们可以想到什么呢?
是不是我们会自然而然的想到使用堆进行排序,在讲解使用堆进行排序之前说明一下,一般我们排序都是对数组进行排序,所以我们要先将数组中的内容先全部入堆,处理完之后再放入数组中
那么是不是我们每次使用堆进行排序必须先写一个堆,把数组中的内容放入堆,排完序之后再把数据放回数组呢?其实并不会,这个问题到后面真正的堆排部分就知道了,现在先暂时留留悬念
现在我们还是继续刚刚的思路,毕竟现在属于堆排的引入部分,我们要先知道用堆进行排序的大致逻辑后,才能将真正的堆排理解透彻
当前的思路就是,我们将数组中的数据放入堆中,然后循环地取堆顶、出堆顶元素,每取到一次堆顶就放回数组中,直到堆为空,这样我们每次都可以从当前堆中取到最值,将它们依次放回数组自然就可以实现排序
接下来我们以升序为例,来画个简图模拟一下我们上面的思路,如下:
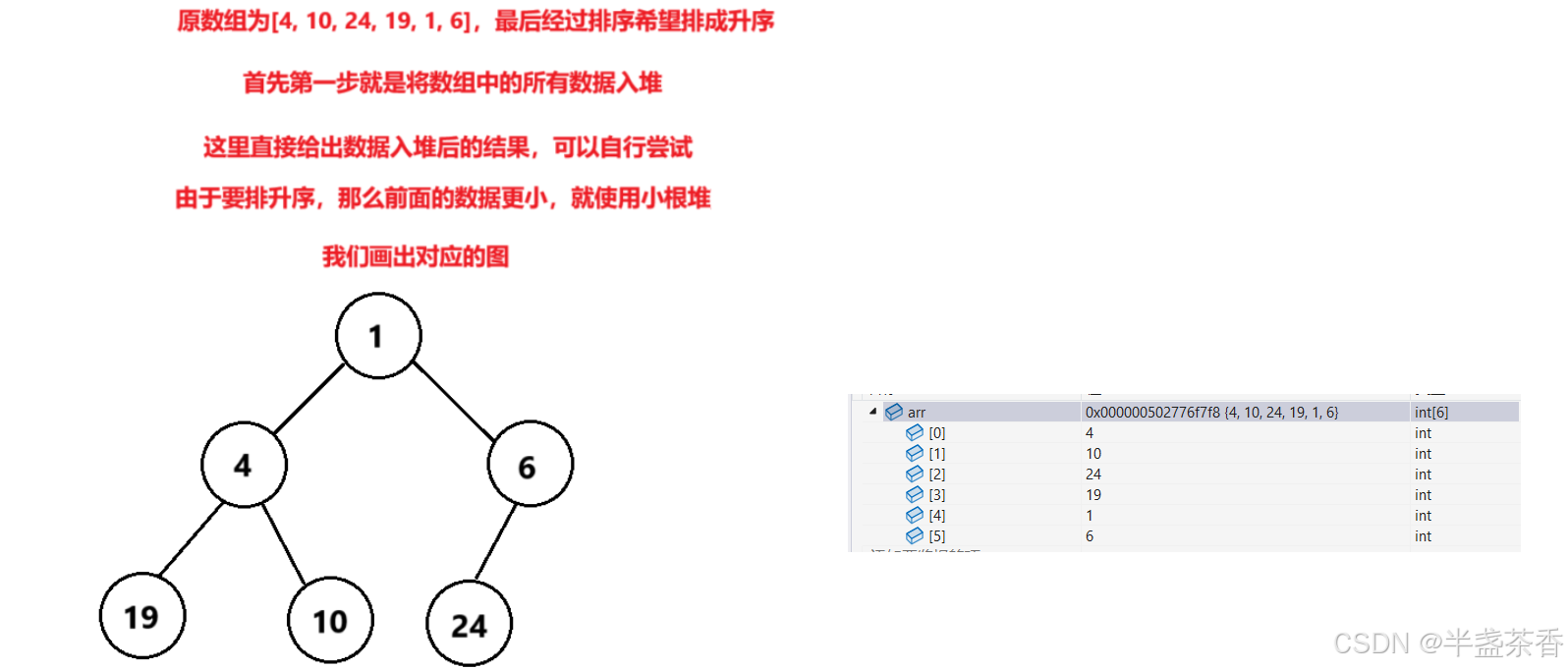
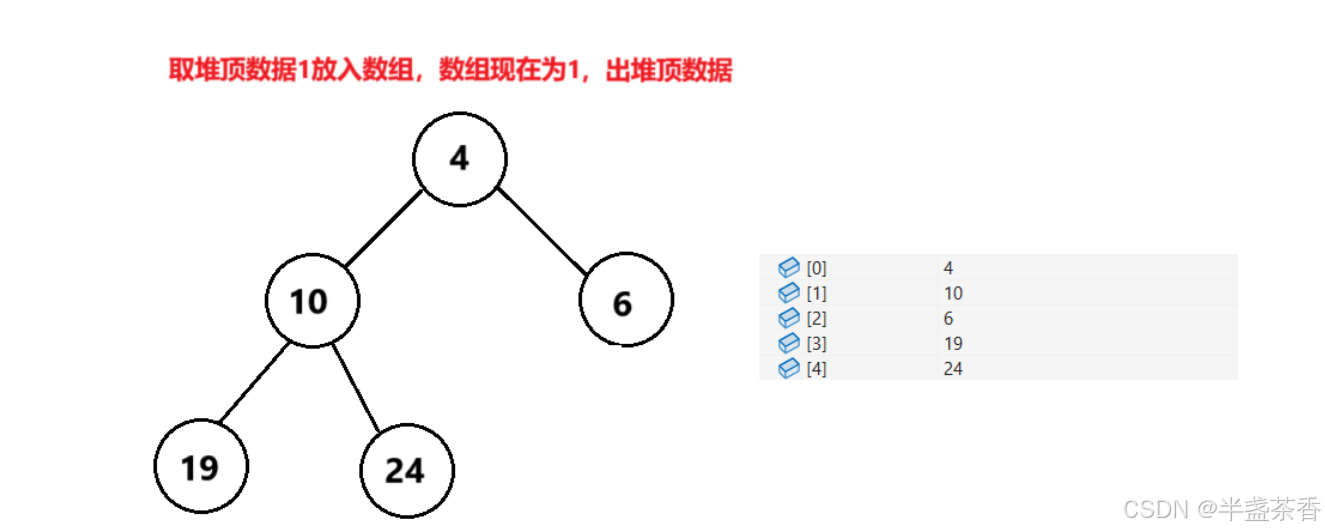
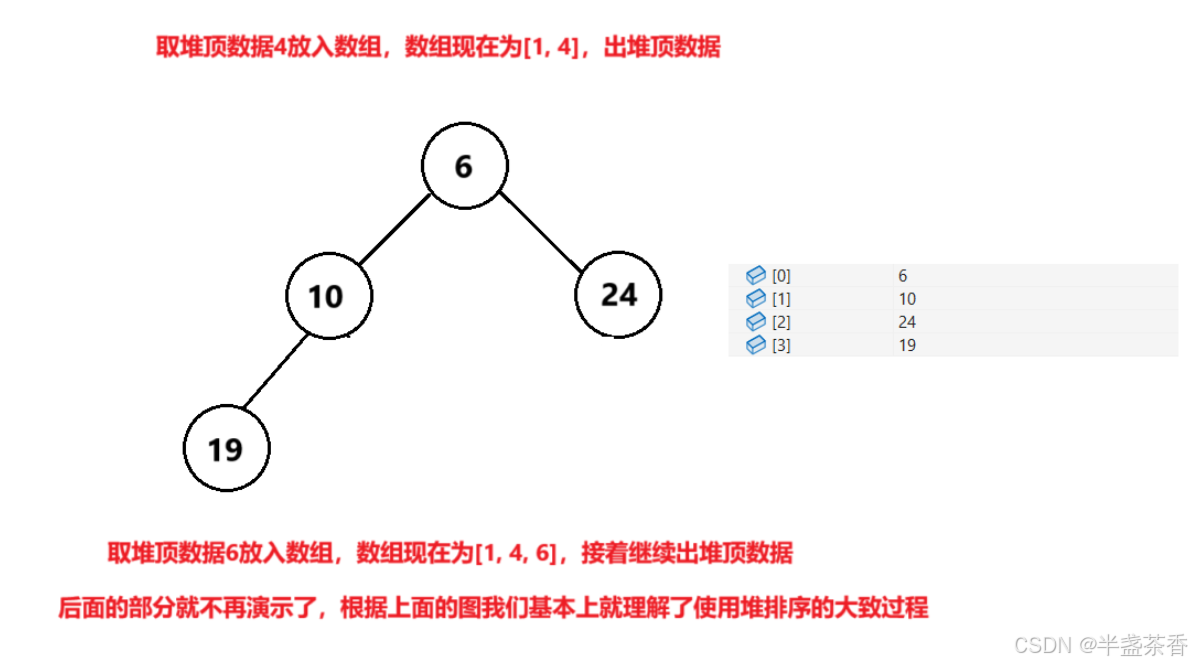
根据上面的示意图,我们大致了解了整个使用堆进行排序的过程,可以发现确实可以使用堆来进行排序,那么有了思路我们就开始动手写代码:
//使用现有堆进行排序
void HeapSort(int* arr, int n)
{
HP hp;
HPInit(&hp);
size_t i = 0;//记录下标
for (i = 0; i < n; i++)
{
//循环入堆
HPPush(&hp, arr[i]);
}
//循环取堆顶数据
i = 0;//重置下标
while (!HPEmpty(&hp))
{
//堆不为空,取出堆顶数据放入数组
int top = HPTop(&hp);
arr[i++] = top;
HPPop(&hp);
}
//销毁
HPDestroy(&hp);
}
void Print(int* arr, int n)
{
for (size_t i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[] = { 4,10,24,19,1,6 };
int sz = sizeof(arr) / sizeof(arr[0]);
HeapSort(arr, sz);
Print(arr, sz);
return 0;
}
那么我们来看看上面代码的运行结果,看看能否排序成功:

可以看到,最后我们成功将数组排成了降序序,但是我们也反复强调,这并不是真正的堆排,只是引出堆排的一种思路,因为我们如果直接使用堆这种数据结构进行排序的话,每次都必须写一个堆来辅助排序,太麻烦了
所以真正的堆排是借助了堆的算法思想,直接对数组进行调整,而不需要专门写一个堆来辅助完成堆排,那么接下来我们就来学习一下真正的堆排
二、真正的堆排
真正的堆排并不是使用堆这种数据结构来实现排序,而是借鉴了堆的算法思想,可以让数组模拟为一个堆进行排序,虽然实现可能麻烦一点点,但是它的效率非常高,等到我们和冒泡排序进行对比就知道了,下面我们就开始正式学习
首先我们要对数组进行排序,那么大概率我们会拿到一个乱序的数组,我们需要通过调整,将这个乱序的数组模拟成为一个堆,因为堆的底层也是用数组存储的,我们要是能让数组模拟成为一个堆,就可以不必再写一个堆这样的数据结构辅助排序了
我们将一个乱序数组模拟成为一个堆的过程称为建堆,建堆有两种思路,当我们讲解完之后我们再来对比它们有什么区别
1.向上调整算法建堆
现在我们要对一个乱序的数组使用向上调整算法建堆,我们之前讲过的向上调整算法都是建立在原本的堆上,也就是在向上调整之前,除了最后一个元素以外,其它的元素已经构成一个堆了,是在堆的基础上向上调整
而我们现在要对一个乱序的数组建堆也要沿用这种思想,具体思路就是,将一个乱序数组看作一颗完全二叉树,默认从根节点开始,将每一个节点都看作需要调整孩子节点,都进行一次向上调整(如果不懂可以直接看下面画的图)
为什么说这样就可以让乱序数组成堆了呢?我们可以仔细分析一下,第一次将根当作要调整的节点时,由于只有它一个节点,所以默认它自己就能成一个堆
然后第二次将根的左孩子当作要调整的节点时,就将根节点加左孩子这颗小的子树调整成了一个堆,第三次将根的右孩子当作要调整的节点时,就将根节点加左右孩子这颗子树调整成了一个堆(如果不懂可以直接看下面画的图)
这样一个节点一个节点地调整,每调整一个节点,就让这个节点和上面的节点成一个堆,当我们将每个节点都这样调整一次后,就能得到一个堆,我们来画图理解一下(这里以建小堆为例):
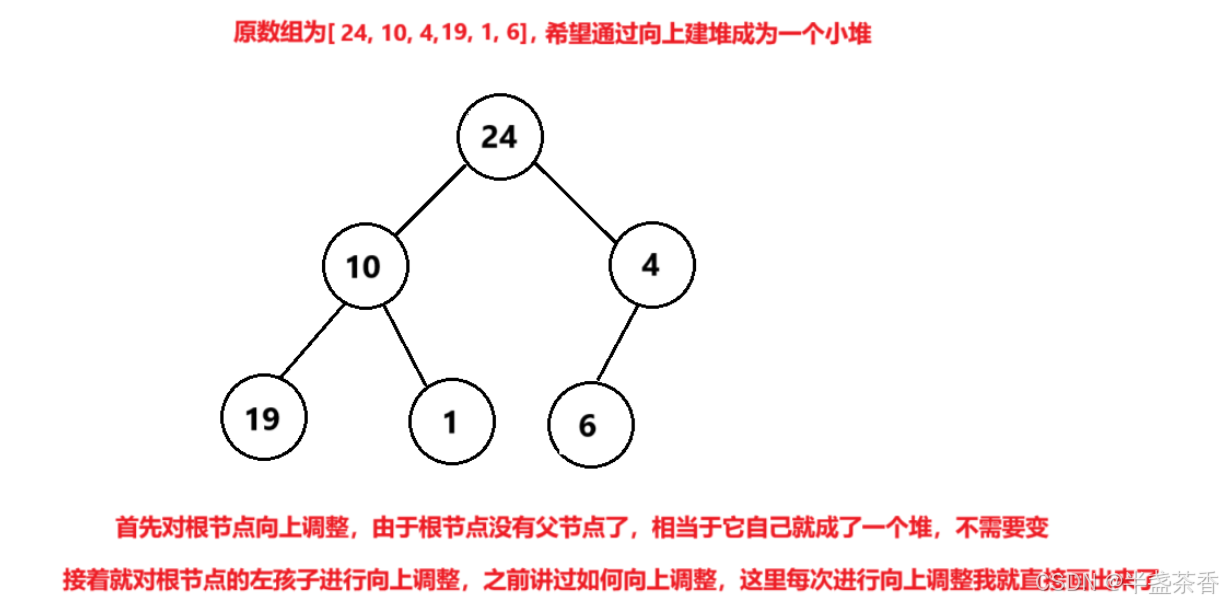
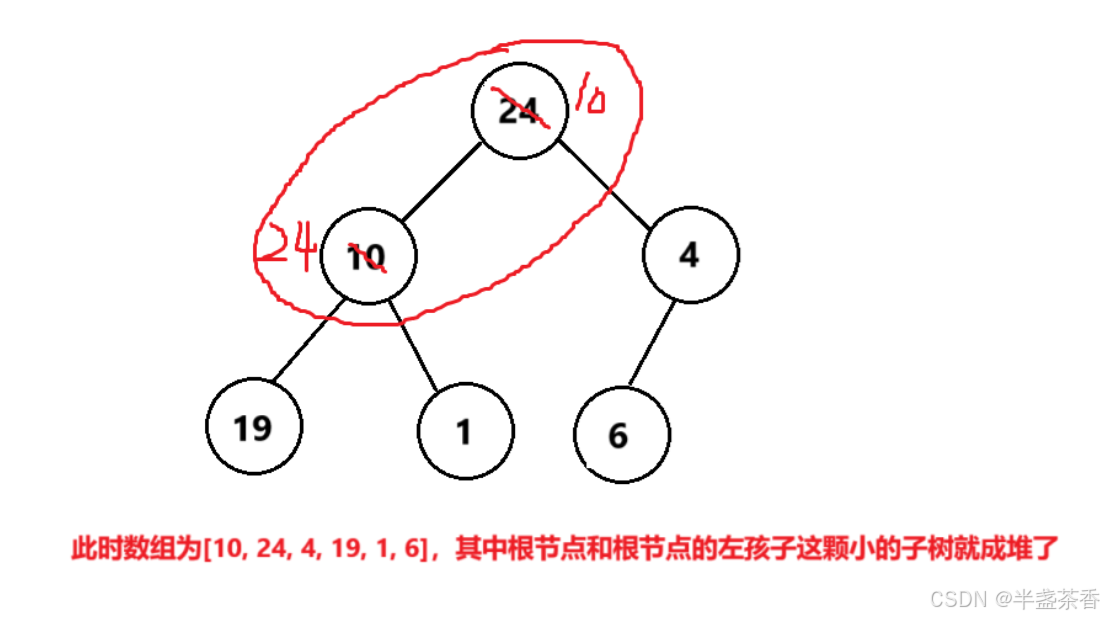
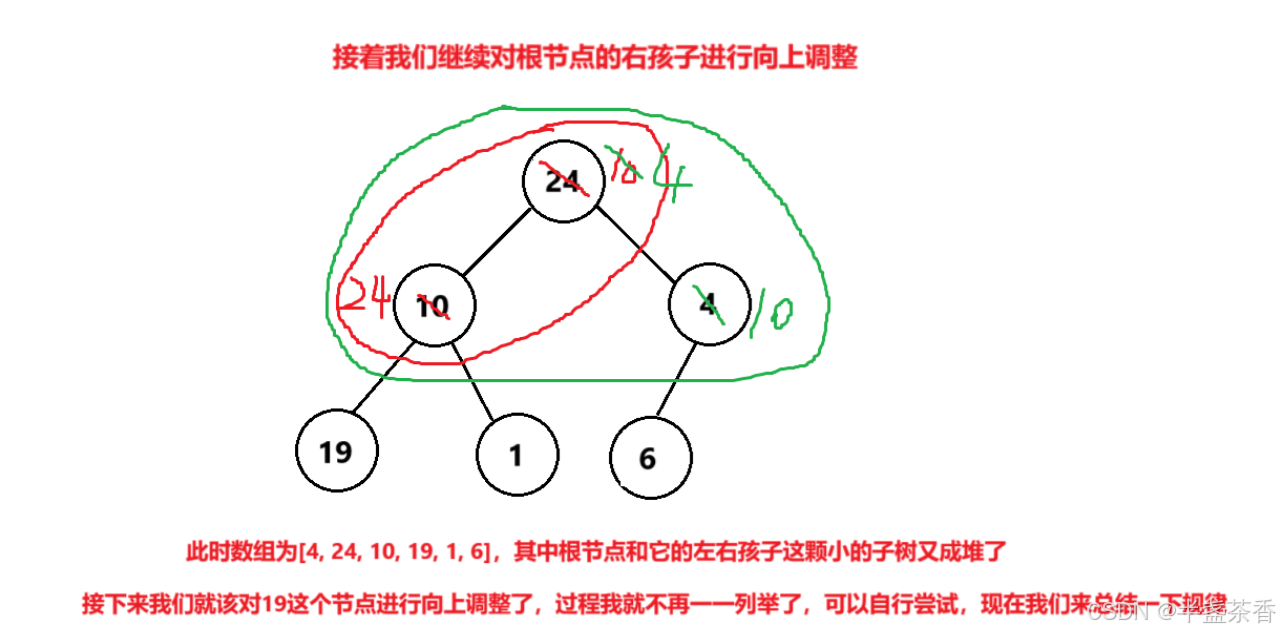
根据上图的样例,应该能更好地理解向上建堆的思想了,这里我们总结一下规律,向上建堆的本质就是从根节点开始,每让一个节点向上调整一次,就能使得这个节点和前面的节点构成的小子树成堆
那么是不是我们将所有节点都向上调整之后,就能将整个乱序数组建成一个堆,那么接下来有了思路我们就可以来写对应的代码了,具体做法就是创建一个循环,从根节点开始,依次对每个节点进行向上调整,如下:
//向上调整建堆
for (int i = 0; i < n; i++)
{
AdjustUp(arr, i);
}
是不是看起来很简单呢?那么又是不是只能使用向上调整算法建堆呢?其实还可以使用向下调整算法来建堆,我们马上就来讲讲向下调整算法建堆
当然,学到这里我们已经建好堆了,如果想提前学一下将我们建好堆的数组进行最后的排序,可以先看建堆后的排序,没有看向下调整算法也不影响观看
2.向下调整算法建堆
在上面我们使用向上调整算法建堆了,就是将每个节点都当作孩子来向上调整,每调整一个节点,这个节点和之前的节点构成的小子树就能构成堆,到最后一个节点向上调整之后,整颗树就成了堆
那么我们能不能将每个节点当作父节点都进行一次向下调整呢?我们从最后一个节点往前开始向下调整,这样每向下调整一个节点,这个节点和之后的节点构成的小子树也能成堆,到堆顶节点向下调整之后,整颗树也就成了堆,可以自行
但是我们其实可以对上面的思路进行优化,因为最后一层的节点都是叶子节点,它们都没有孩子,自然就不能进行向下调整,所以我们要找到从下至上的,第一个可以作为父节点的节点
其实也不难想到,这个节点就是最后一个节点的父节点,最后一个节点的父节点一定是从下至上的,第一个可以作为父节点的节点
那么有了思路之后我们就可以来直接写出代码了,至于整个向下调整算法建堆的示例图可以自行去挑战一下,只有自己能把整个过程画出来了之后,才是真正懂了向下调整算法建堆,那么这里我们直接给出代码:
//向下调整算法建堆
//n-1是最后一个节点,(n-1-1)/2是最后一个节点的父节点
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, i, n);
}
3.向上和向下调整算法建堆时间复杂度比较
我们先来简单看看一次向上调整和向下调整的时间复杂度,按照最坏的情况来算,一次向上或向下调整都要调整满二叉树的层数次,我们之前说过二叉树的层次为log2(n+1),所以我们可以得出,一次向上或向下调整的时间复杂度为O(log N)
我们向上调整建堆和向上调整建堆的外层循环大致都是一个n,所以我们猜测向上调整建堆的时间复杂度大致为O(N * log N)
那么它们之间是否就是没有区别呢?随意使用哪个都可以吗?其实并不是,向上调整算法建堆的时间复杂度确实为O(N * log N),但是向下调整算法建堆的时间复杂度其实是O(N),要更快一些
那么是为什么呢?这里我们给出计算向下调整算法建堆时间复杂度的证明过程,需要用到高中学过的错位相减,至于向上调整算法建堆的证明过程可以参照这个方式,可以自行下去证明,那么现在我们直接给出向下调整算法建堆时间复杂度的证明过程,如下:
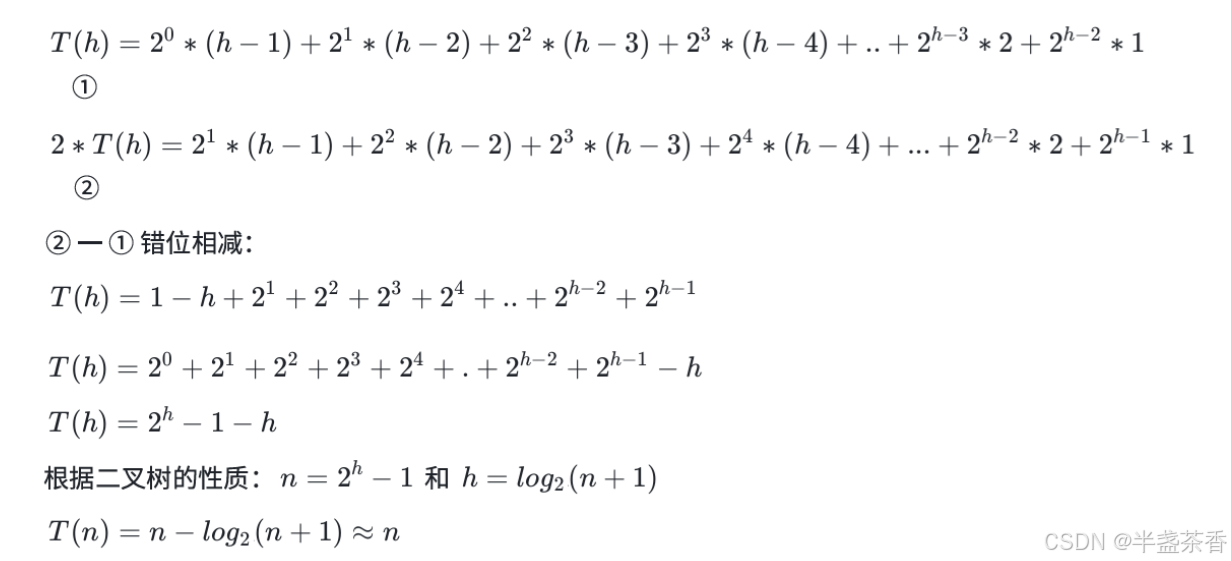
根据上面的证明,
我们可以得出向下调整算法建堆的时间复杂度确实为O(N),而不是O(N * log N),向上调整算法建堆的证明可以自行参照实现一下,最后结果为O(N * log N)
所以最后我们得出结论,
向下调整算法建堆优于向上调整算法建堆
4.建堆后的排序
当我们使用向上和向下调整算法建堆之后,我们现在需要对它进行最后的排序,具体的思路不难,但是可能有些抽象,需要我们细细分析,画画图
首先在引入部分我们是利用现有的数据结构堆进行排序,将堆顶取出放回数组,再出堆顶数据,直到堆为空,但是现在我们只有一个成堆的数组,该怎么操作呢?
核心其实还是一样的,我们可以在数组中模拟取堆顶数据,出堆顶数据,反复拿到最值,具体方法就是:
交换根节点和最后一个节点,此时最后一个节点就是最大或最小的值,随后对新的堆顶元素进行向下调整,注意向下调整时要除开最后一个节点,让剩下的节点继续成堆
然后就是交换根节点和倒数第二个节点,此时倒数第二个节点就是第二大或第二小的值,随后又对新的堆顶元素进行向下调整,此时向下调整时要除开倒数第二个节点,让剩下的元素继续成堆
随后重复进行以上步骤,直到将整个数组排成有序,可能这样纯文字不好描述,我们来画图理解一下,这里还是以小根堆为例:
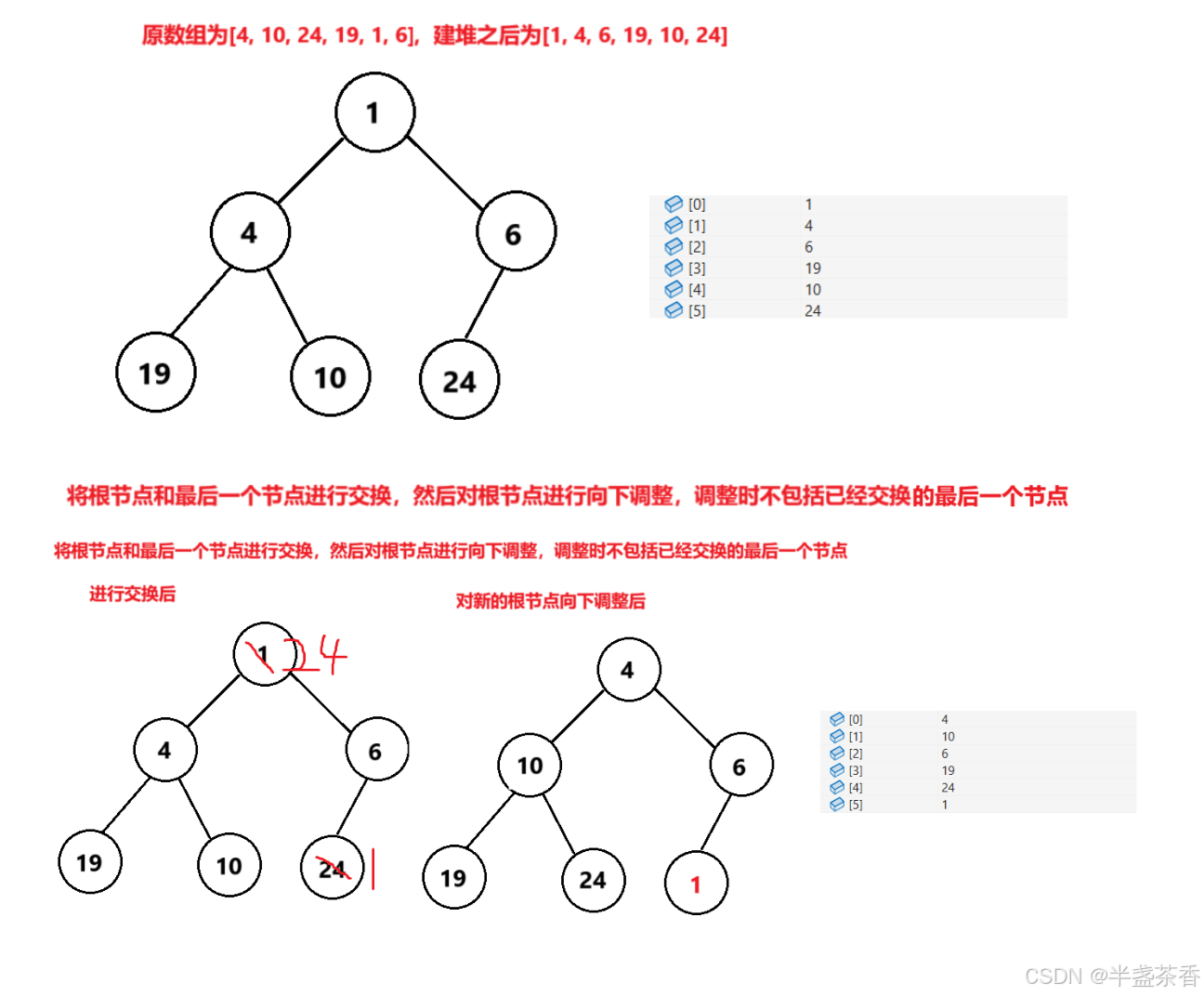
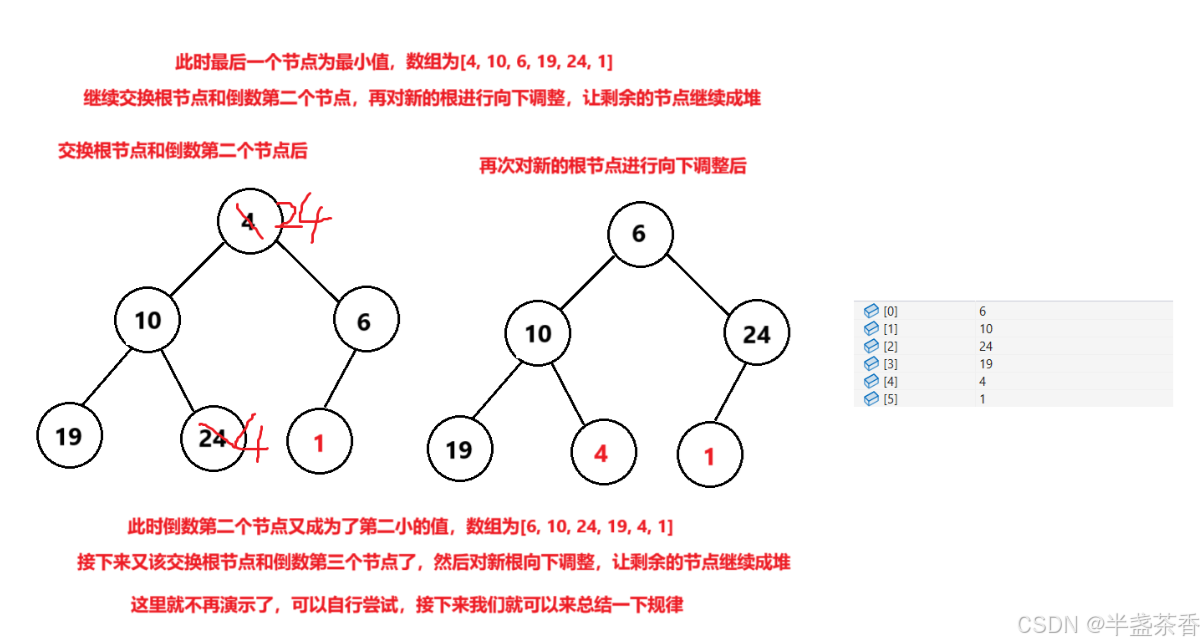
根据上图的演示,我们应该能够猜到如果我们把后面的操作做完会发生什么,应该会将整个数组排成降序,因为每次都将当前堆的最小值往后面拿,那么大的都在前面了,小的都在后面的,自然就成为了降序
那么我们如何把上面的功能写成代码呢?这里的难点就是如何每次都调整和交换时都不去影响已经排序好的数据,这里就直接给出思路
我们可以定义一个变量end作为下标来划分这个数组,在end之前的节点是还未处理好的节点,end指向的节点就是要交换的节点位置,end之后的节点是已经挪动过的、处理好的节点,如图:

此时数组都是还未处理的节点,让end指向最后一个节点处,表示end处的节点是要交换的节点,它之后还没有已经处理好的节点,之前都是未处理的节点,随后交换根节点和end位置的节点,如图:

然后将end作为向下调整时的堆中的数据个数,那么就只会调整end位置之前的节点,不会影响end位置的节点,如图:

那么有了整个建堆后的排序思路,我们接下来就直接写出代码,如下:
int end = n - 1;
while (end > 0)
{
Swap(&arr[0], &arr[end]);
AdjustDown(arr, 0, end);
end--;
}
那么整个完整的堆排就已经完成了,完整代码为:
void HeapSort(int* arr, int n)
{
//向上调整建堆
/*for (int i = 0; i < n; i++)
{
AdjustUp(arr, i);
}*/
//向下调整算法建堆
//n-1是最后一个节点,(n-1-1)/2是最后一个节点的父节点
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, i, n);
}
int end = n - 1;
while (end > 0)
{
Swap(&arr[0], &arr[end]);
AdjustDown(arr, 0, end);
end--;
}
}
我们来看看代码的运行结果:
-
我们建小堆会将数组排成降序,建大堆会将数组排成升序,因为最值都是放在最后的
-
堆排的时间复杂度为O(N * log N),建堆的时间复杂度为O(N * log N)或O(N),建堆后的排序的时间复杂度为O(N * log N),所以总体下来堆排的时间复杂度大致为O(N * log N)
-
由于我们将数组建堆后还是需要使用向下调整算法来进行最后的排序,再加上向下调整算法建堆又更快,所以在实现堆排时,我们往往只写一个向下调整算法,建堆和建堆后的排序都用它
5.堆排序和冒泡排序时间复杂度以及性能比较
那么现在我们新学了堆排这种排序方式,我们来对比一下堆排和冒泡排序,首先它们的时间复杂度一个为O(N * log N),一个为O(N^2)
我们来看看它们的差距到底有多大,我们来写一个代码随机生成10万个整型数据,看看最后它们分别用时多少,代码如下:
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
void TestOP()
{
srand((unsigned int)time(NULL));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
}
int begin1 = clock();
HeapSort(a1, N);
int end1 = clock();
int begin2 = clock();
BubbleSort(a2, N);
int end2 = clock();
printf("HeapSort:%d\n", end1 - begin1);
printf("BubbleSort:%d\n", end2 - begin2);
free(a1);
free(a2);
}
int main()
{
TestOP();
return 0;
}
为了保证测试出最真实的数据,我们要把debug版本调成release版本,然后运行代码,我们来见证一下最后排序的结果,如图:

整整10万个数据堆排只需要5毫秒,而冒泡排序则需要7秒多,差距达到了上千倍,所以堆排其实是很快的,是最优秀的几个排序算法之一,至于其他的排序算法我们在后面还会介绍
三、Top-K问题
在解决TOP-K问题之前,我们要了解TOP-K问题是什么,它是求数据结合中前K个最⼤的元素或者最⼩的元素,⼀般情况下数据量都⽐较⼤,⽐如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等
那么我们能不能对这些数据直接进行排序呢?很明显是不现实的,因为有一些TOP-K问题的数据量非常大,我们不能都加载到内存中去排序,效率也不高
所以我们要想一个办法,让我们能够在内存被限制到很小的情况下,也能找出大量数据结合中前K个最⼤的元素或者最⼩的元素,那么到底怎么解决呢?
我们现在来假设一个场景来辅助我们讲解,假设要求我们只能开k个内存空间,有10万个整型数据都存放在外存的磁盘文件上,我们要找到磁盘文件中前K个最大的数,这种情况下我们使用堆来解决
在我们着手来解决这个问题前,我们要先把环境模拟出来,就是要在我们当前目录下生成一个有10万个随机整数的文件,这里直接给出造数据文件的函数代码,这只是环境模拟,不是重点,重点是我们之后的TOP-K,造数据函数代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void CreateNDate()
{
// 造数据
int n = 100000;
srand((unsigned int)time(NULL));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (int i = 0; i < n; ++i)
{
int x = (rand() + i) % 1000000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
上面就是造数据的函数的代码了,注意,这个代码只需要运行一次就可以造出我们想要的文件,随后注释掉就好了,环境模拟好之后我们就进入真正的Top- K问题的解决了
首先我们要知道k是多少,它最好由用户决定,所以我们可以使用scanf来读取k,接着我们就来详细聊聊解决Top-K问题的基本思路: