CVPR 2025
创新
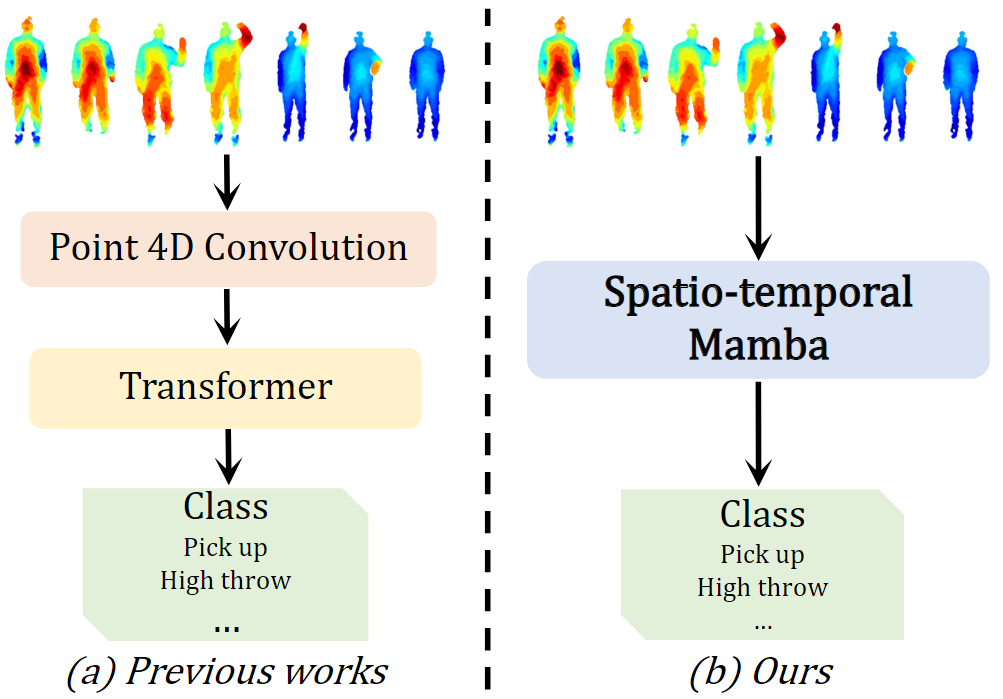
基于transformer的4D主干由于其二次复杂度而通常存在较大的计算成本,特别是对于长视频序列。
开发了帧内空间Mamba模块,建立时空相关性。
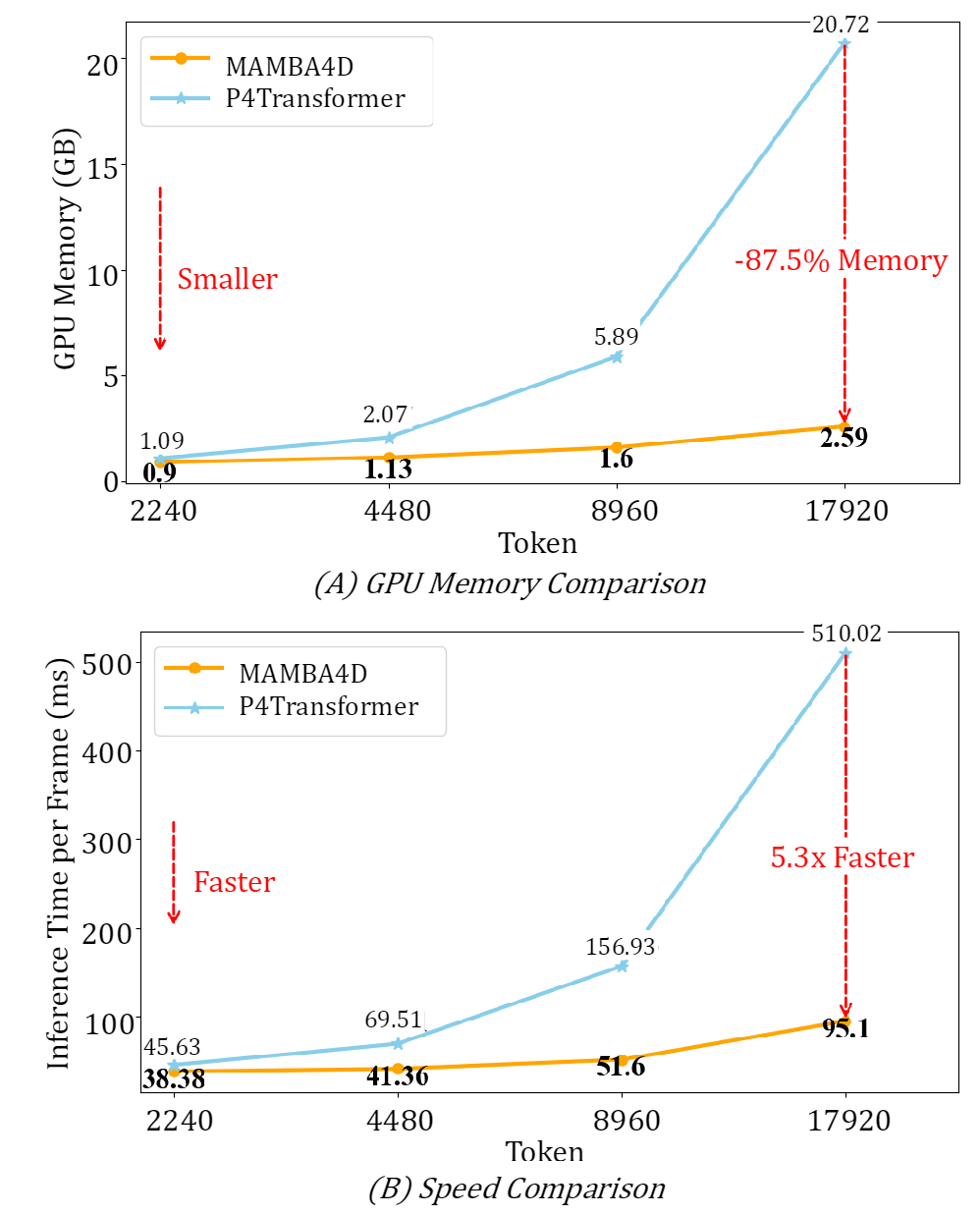
GPU占用和速度很有优势。
代码还没发。
Pipeline
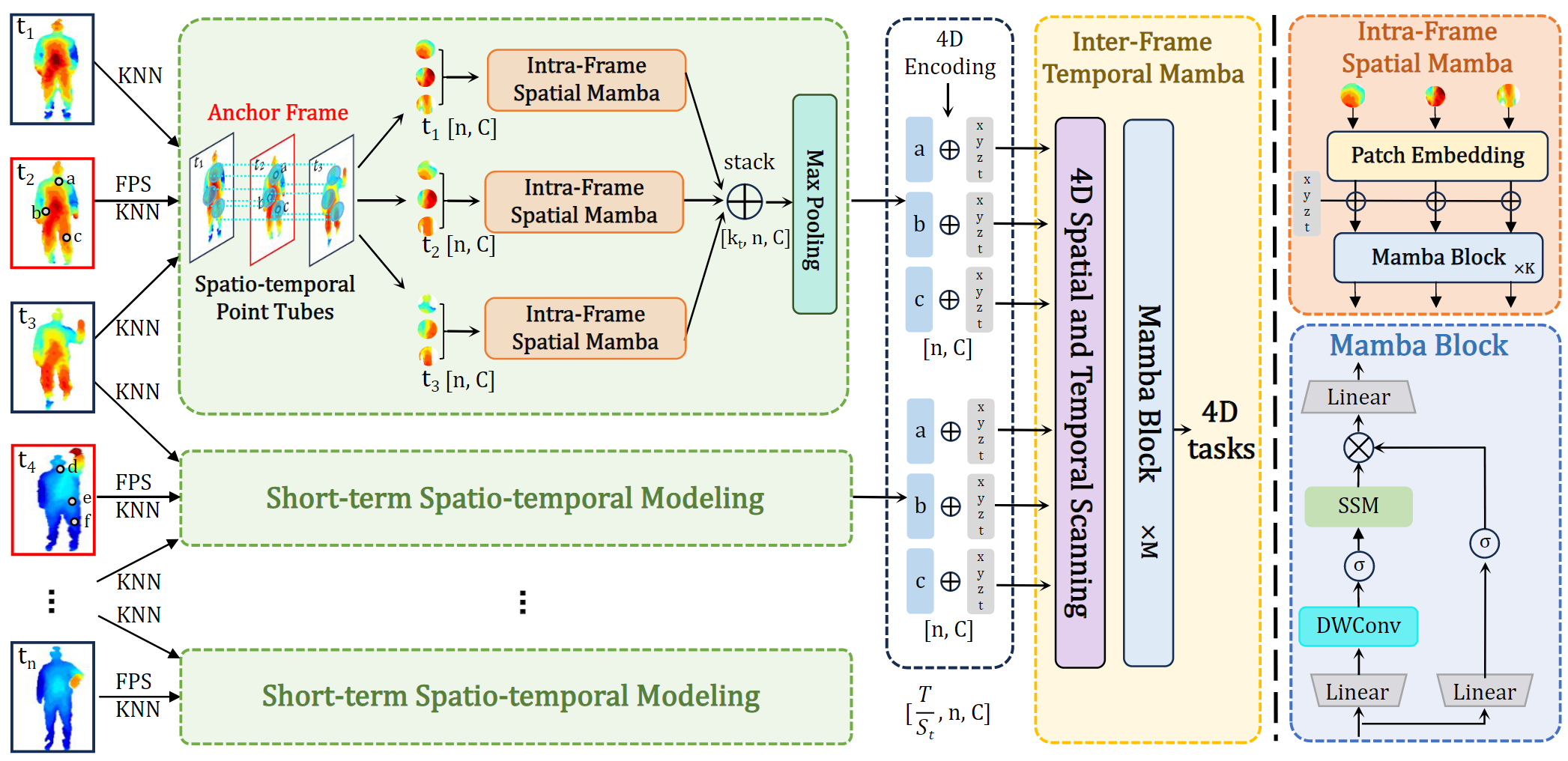
输入点云序列,根据超参数构建点管。
先进行帧内特征提取,每一帧tn,FPS采样后的n个点,它们所包含的邻域特征[n,c,(k)],经过空间mamba进行聚合得到点特征[n,c]。用stack聚合前后多帧形成点管特征[kt,n,c],并池化降维[n,c]。
然后进行帧间特征聚合,所有点管特征经过4D的位置编码,和后续的多个空间mamba块聚合时间信息。
Short-term Spatio-temporal Modeling就是原始PSTNet。
后续的Inter-frame Temporal Mamba就相当于PST-Transformer后续的Transformer。
Short-term Spatio-temporal Modeling
先进行锚点帧和帧内采样点的选择。
然后利用帧内mamba提取特征。
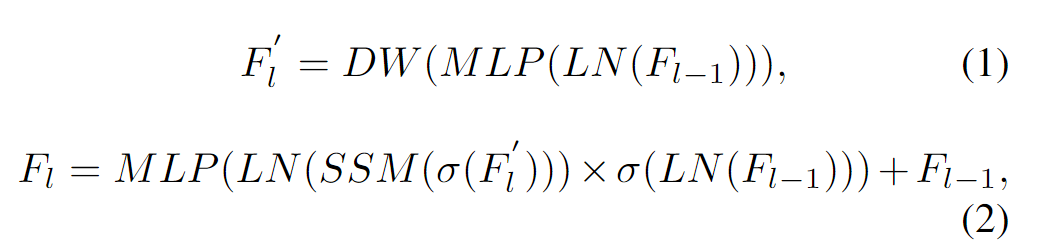
方程中部分过程在图片流程中没有体现,如MLP等。
使用时空解耦的方程表示为: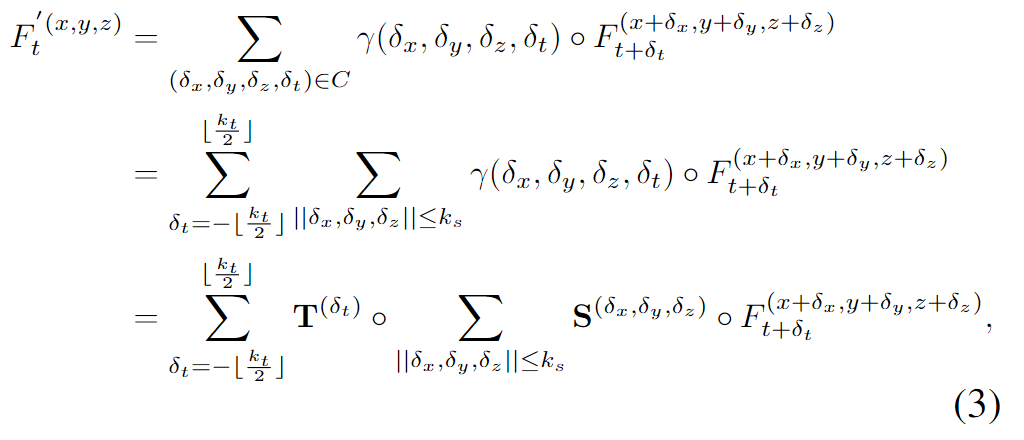
Inter-frame Temporal Mamba
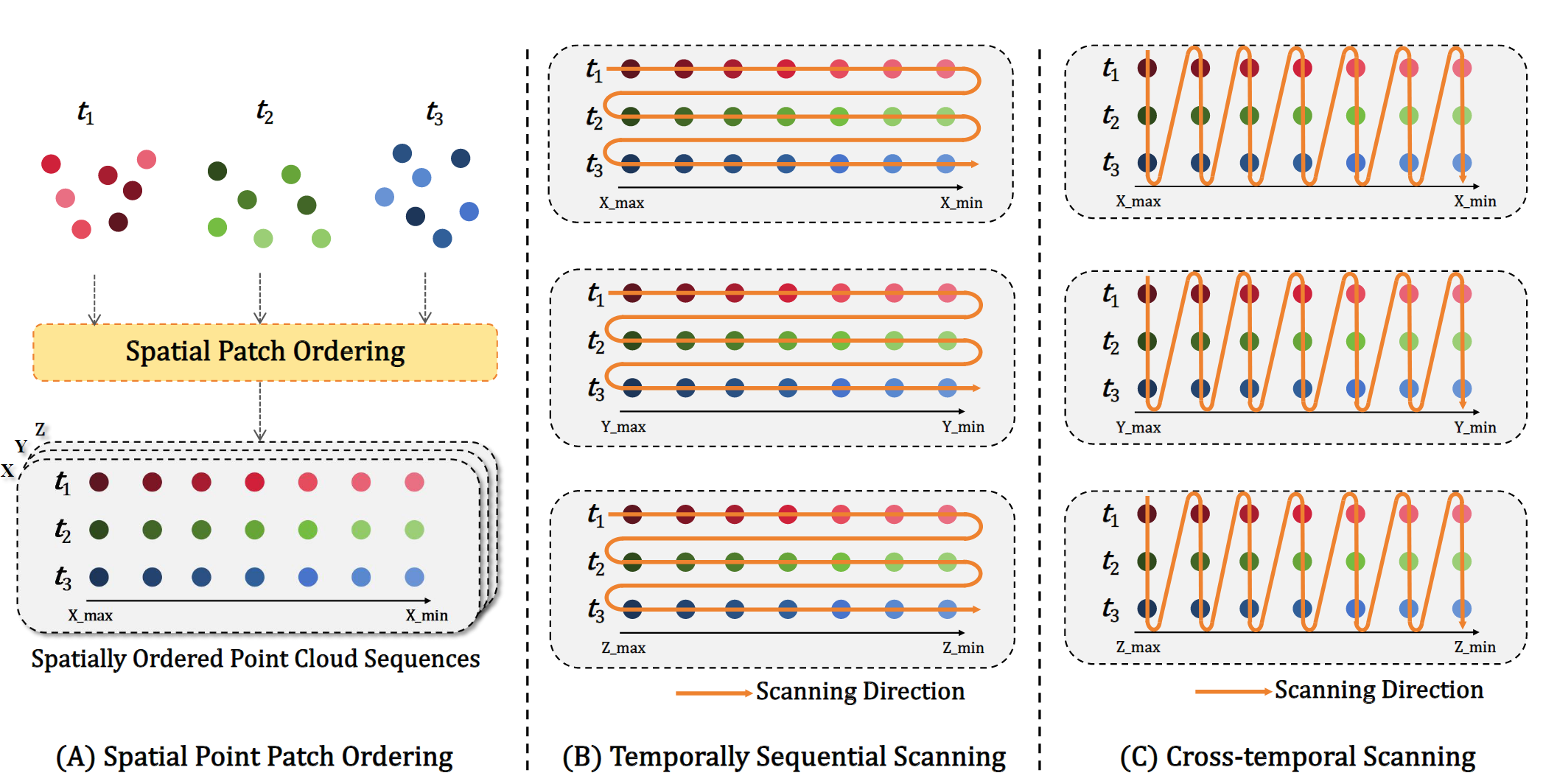
利用多种序列扫描方式,并在后续的实验中进行对比。
实验
3D Action Recognition
MSR Action数据集
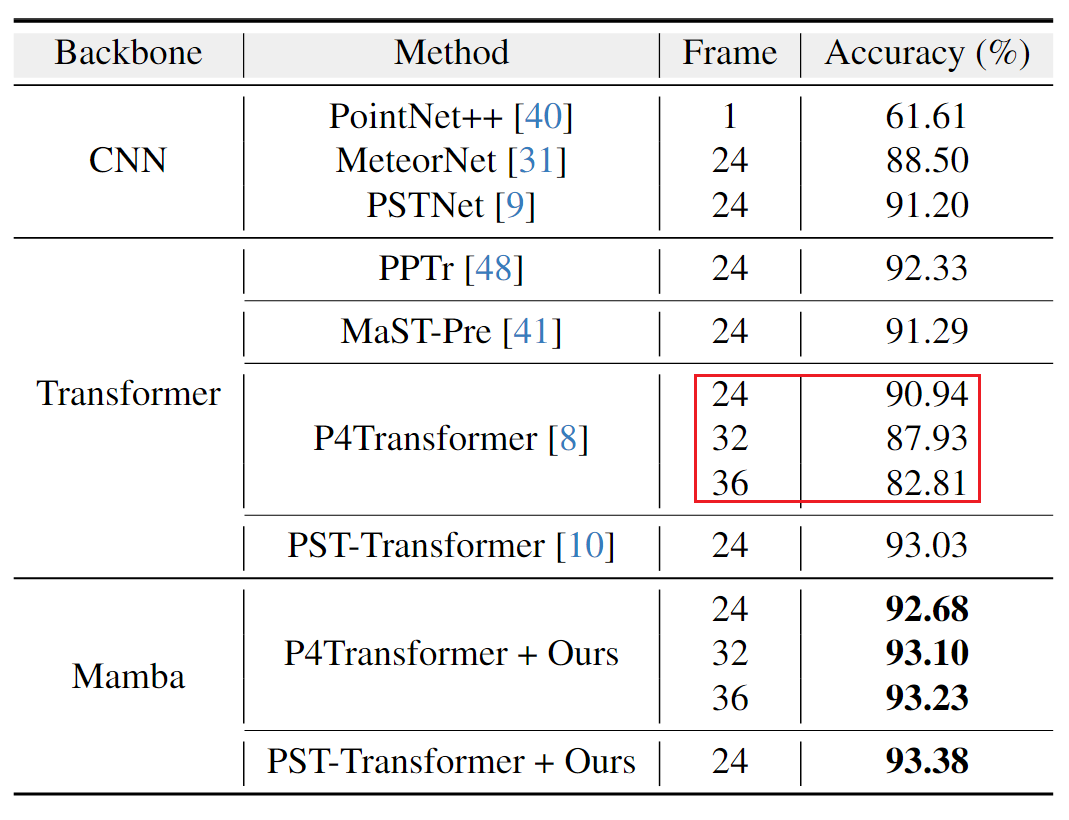
4D Action Segmentation
HOI4D数据集
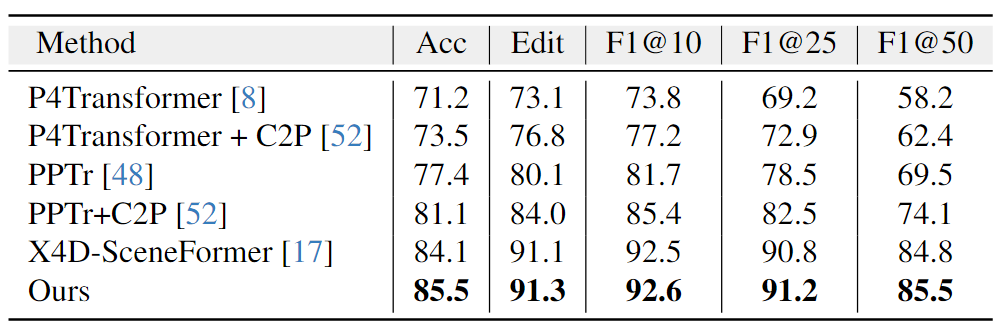
4D Semantic Segmentation
Synthia 4D数据集中mIoU对比。
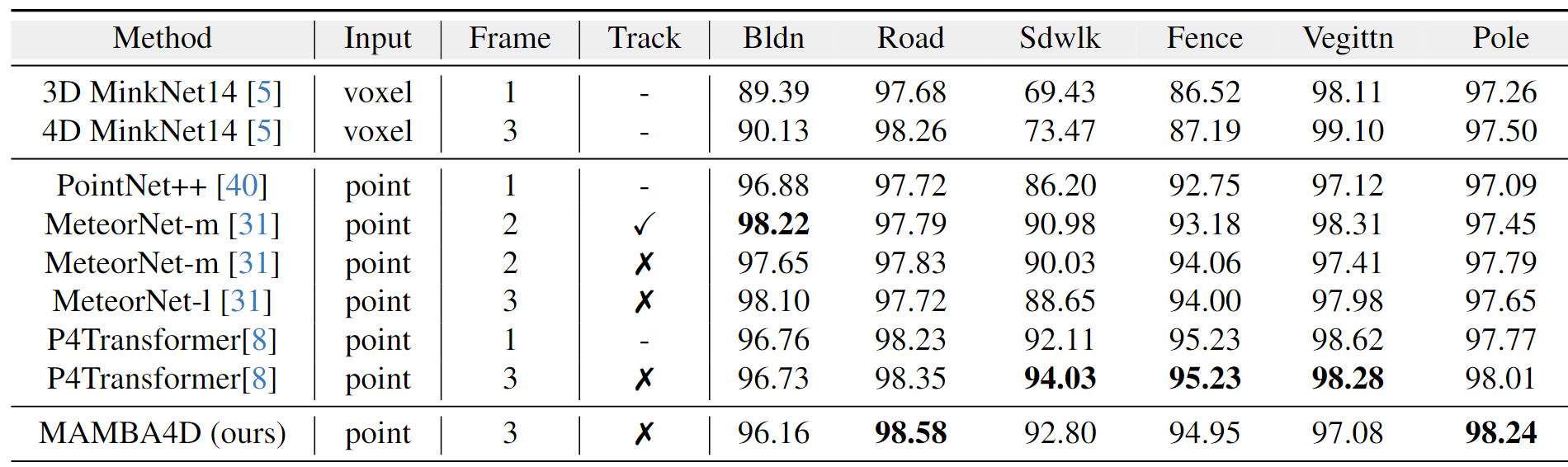
track:是否使用了点追踪。
Ablation Studies
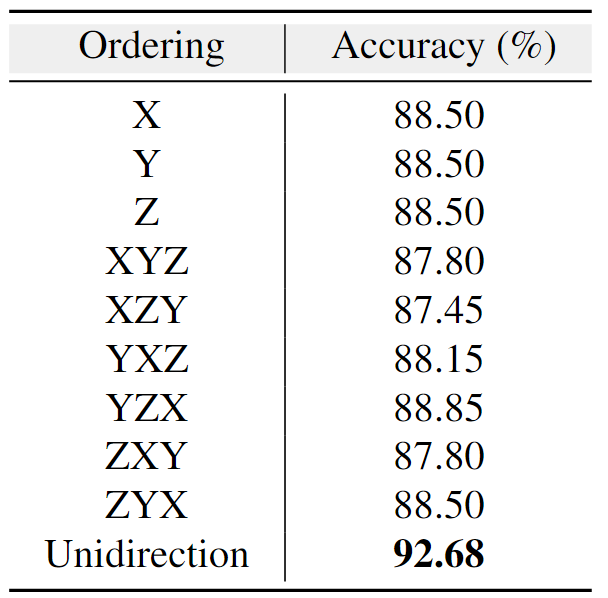
帧内mamba块排序方式。
纯x,y,z的顺序不确定,不可复现。
Unidirection:使用默认构造出来的序列顺序,不打乱,但也不手动优化排序顺序。
使用手动的排序方式效果反而可能不如Unidirection,Unidirection包含一些原始的采样结构信息,而手工排序打乱了这一结构。
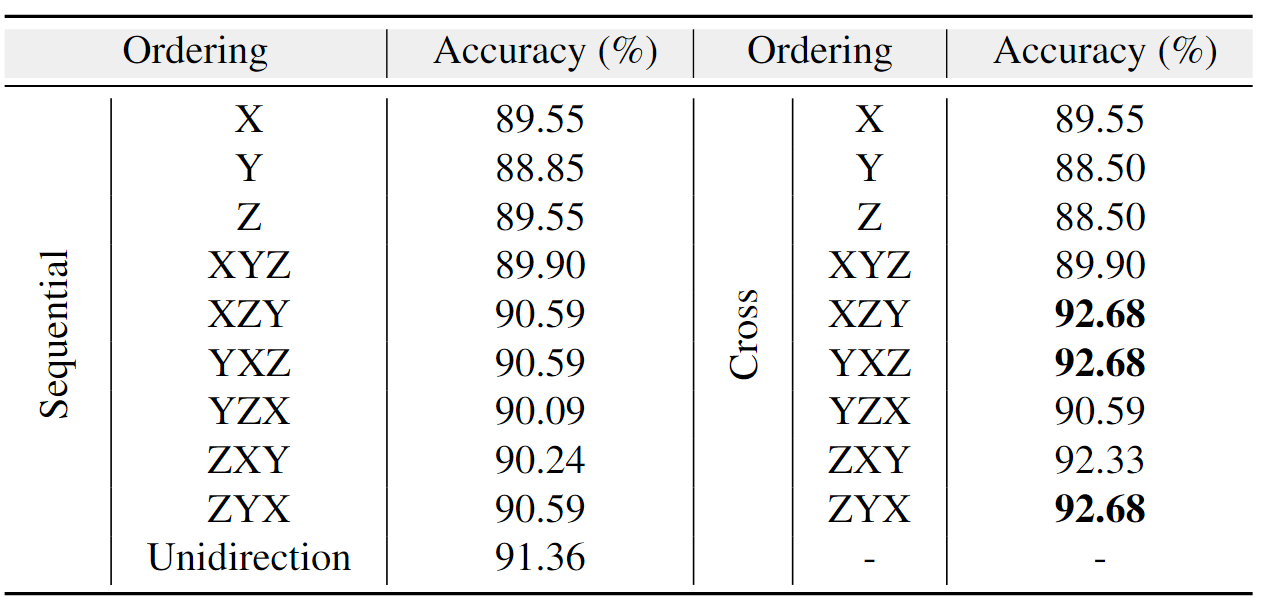
帧间mamba块排序方式。
跨帧的排序方式让Mamba更好建模时序动态变化,特别适合点云这种“空间+时间融合”的数据。