上篇文章:
多线程—synchronized原理![]() https://blog.csdn.net/sniper_fandc/article/details/146713129?fromshare=blogdetail&sharetype=blogdetail&sharerId=146713129&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link
https://blog.csdn.net/sniper_fandc/article/details/146713129?fromshare=blogdetail&sharetype=blogdetail&sharerId=146713129&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link
目录
1 Callable接口
2 ReentrantLock
3 原子类
4 线程池
5 信号量Semaphore
6 CountDownLatch
1 Callable接口
在多线程环境下,如果要计算1+...+100的值,没有学习Callable接口前,可能我们写的代码如下:
public class CallThread {
public static Object locker = new Object();
public static int sum = 0;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
int result = 0;
for(int i = 1;i <= 100;i++){
result += i;
}
synchronized (locker){
sum = result;
locker.notify();
}
});
t.start();
synchronized (locker){
while(sum == 0){
locker.wait();
}
System.out.println("1+...+100 = " + sum);
}
}
}由于run方法没有返回值,因此必须使用全局变量sum来接收计算结果,同时要输出计算结果,必须得等线程运行结束,因此使用wait和notify方法来保证线程同步。这样的代码是比较繁琐的,如果使用了Callable接口,就会简化很多:
public class CallThread {
public static void main(String[] args) throws InterruptedException, ExecutionException {
Callable<Integer> callable = new Callable<Integer>() {
public Integer call() throws Exception {
int result = 0;
for(int i = 1;i <= 100;i++){
result += i;
}
return result;
}
};
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread t = new Thread(futureTask);
t.start();
System.out.println("1+...+100 = " + futureTask.get());
}
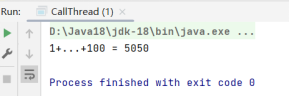
}上述代码的运行结果如下:
Callable接口类似Runnable接口,也是定义线程需要执行的任务,但是不同的是这个任务可以带返回值,返回值类型就是泛型参数类型。定义任务后,需要用FutureTask来包装这个任务,用于接收Callable实例的返回值。创建线程需要把FutureTask的实例作为参数传入,线程执行结束后,会把计算结果放入FutureTask的实例中。获取FutureTask实例中的返回值需要用到get(),如果线程还没有执行结束,代码会阻塞到get()方法的位置,直到线程执行结束接收到返回值。
2 ReentrantLock
ReentrantLock直译可重入锁,和synchronized类似,也是通过加锁实现共享数据的互斥访问。
ReentrantLock类加锁操作的实现方式是通过ReentrantLock的实例.lock()来加锁,通过ReentrantLock的实例.unlock()来解锁:
ReentrantLock lock = new ReentrantLock();
lock.lock();
...
lock.unlock(); 但是这种方式往往给开发人员带来更复杂的代码逻辑,导致如果加锁过程中出现异常,可能程序就执行不到解锁,因此常常搭配try-catch-finally语句使用:
ReentrantLock lock = new ReentrantLock();
lock.lock();
try {
...
} finally {
lock.unlock()
}有了synchronized,为什么还需要ReentrantLock?(它们的区别是什么)
1.synchronized是关键字,是JVM内部的实现。而ReentrantLock是一个类,是标准库的一个类,是基于java的实现。
2.synchronized的加锁解锁基于代码块,进入代码块加锁,退出代码块解锁,不需要显示调用加锁解锁的代码。ReentrantLock的加锁解锁基于lock()和unlock(),需要显示调用方法,更灵活,但是解锁容易遗漏。
3.synchronized是非公平锁。而ReentrantLock默认是非公平锁,但是也提供了公平锁版本,构造方法传参true就会启用公平锁策略。
4.synchronized如果加锁失败,就会进入阻塞状态。而ReentrantLock提供trylock()方法,这个方法会尝试加锁,如果加锁失败,不会进入阻塞状态并返回false,继续向下执行其他代码。trylock()还可以设置一定的等待时间,如果加锁失败,就等待一会,时间一过再放弃。
5.synchronized必须使用wait()和notify()来等待和唤醒,唤醒时随机唤醒一个线程。ReentrantLock搭配Condition类实现等待和唤醒,可以随机唤醒一个,也可以唤醒指定线程。
当锁竞争不激烈时,使用synchronized更好(偏向锁和轻量级锁)。当锁竞争激烈时,使用ReentrantLock更灵活,不让线程死等。如果想要使用公平锁,也要用ReentrantLock。
3 原子类
原子类基于CAS实现,因此比加锁实现的代码性能更高,主要有以下几个类:AtomicBoolean、AtomicInteger、AtomicIntegerArray、AtomicLong、AtomicReference、AtomicStampedReference。
常见的方法有:addAndGet(int delta)<=>i += delta、decrementAndGet()<=>--i、getAndDecrement()<=>i--、incrementAndGet()<=>++i、getAndIncrement()<=>i++,这些方法都是AtomicInteger类中的方法。
4 线程池
线程池的创建最核心的类是ThreadPoolExecutor类,这个类有多种参数,帮助我们创建多种类型的线程池:
corePoolSize:核心线程的数量。(核心线程一旦创建就一直存在)
maximumPoolSize:最大线程的数量=核心线程+临时线程的数目。(临时线程:一段时间不干活,就被销毁)
keepAliveTime:临时线程允许的空闲时间。
unit:keepaliveTime的时间单位,是秒,分钟等等。
workQueue:传递任务的阻塞队列。线程池内部有默认的阻塞队列,我们也可以传入自定义的队列。(线程池的可扩展性)
threadFactory:创建线程的工厂,参与具体的创建线程工作。
RejectedExecutionHandler:拒绝策略,如果任务量超出线程池的任务队列的负荷了接下来怎么处理。策略有如下四种:
AbortPolicy():超过负荷,直接抛出异常。
CallerRunsPolicy():调用者负责处理。
DiscardOldestPolicy():丢弃队列中最老的任务。
DiscardPolicy():丢弃新来的任务。
而前面使用线程池创建线程方法中使用的Executors本质上是ThreadPoolExecutor类的封装。
注意:创建线程池时线程数量如何设置?但凡回答具体的数字都是错的,正确的做法是根据不同的程序设置不同数量,可以通过压测(性能测试)来控制不同线程数量,观察CPU占用率、内存占用率等等来确定合适的线程数量。
5 信号量Semaphore
信号量Semaphore表示可用资源的数量,本质上是一个计数器,在信号量机制中有操作P和V(都是原子性的操作),P操作表示申请资源,因此P操作后资源数量-1;V操作表示释放资源,V操作后资源数量+1。当可用资源数量为0时,P操作阻塞,因此通过信号量机制也可以实现线程同步。
P操作对应的方法是acquire(),V操作对应的方法是release()。具体使用如下:
public class MySemaphore {
public static void main(String[] args) throws InterruptedException {
Semaphore semaphore = new Semaphore(3);
semaphore.acquire();
System.out.println("获取资源");
semaphore.acquire();
System.out.println("获取资源");
semaphore.acquire();
System.out.println("获取资源");
// semaphore.release();
// System.out.println("释放资源");
semaphore.acquire();
System.out.println("获取资源");
}
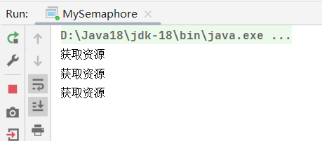
}创建包含3个资源的计数器,但是main尝试连续获取4个资源,结果是被阻塞到第4次acquire()处。
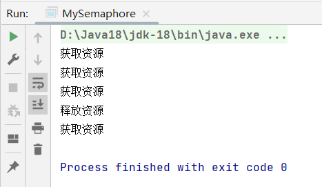
如果把代码中的注释取消,即连续3次获取资源,此时可用资源的数量为0,再释放一次资源,此时可用资源的数量为1,再获取1次资源即可顺利执行。
6 CountDownLatch
CountDownLatch这个类会等待所有的任务都执行结束后再执行后续的代码,具体使用如下:
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(10);
for(int i = 0;i < 10;i++){
Thread t = new Thread(() ->{
try {
//Math.random()返回0-1之间的随机数
Thread.sleep((long)(Math.random() * 5000));
System.out.println(Thread.currentThread().getName() + "执行完毕了");
countDownLatch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
},"线程"+ i);
t.start();
}
countDownLatch.await();
System.out.println("所有任务都执行完了,工作结束");
}
}CountDownLatch的构造方法传入的参数表示任务的个数,对应内部有个计数器,每当一个任务调用countDownLatch.countDown(),计数器-1。await()会进行阻塞,直到计数器为0。只有所有任务都调用countDown(),计数器为0,所有任务都执行完毕,此时await()方法才结束阻塞。代码运行结果如下:

下篇文章: