小T导读:TDengine 助力广州疆海科技有限公司高效完成储能业务的数据分析任务,轻松应对海量功率、电能及输入输出数据的实时统计与分析,并以接近 1 : 20 的数据文件压缩率大幅降低存储成本。此外,taosX 强大的 transform 功能帮助用户完成原始数据的清洗和结构优化,而其零代码迁移能力更实现了历史数据从 TDengine OSS 与 MySQL 到 TDengine 企业版的平滑迁移,全面提升了企业的数据管理效率。本文将详细解读这一实践案例。
1.背景概述
随着光伏、电池等技术的不断进步,家庭储能、户外储能市场蓬勃发展,广州疆海科技有限公司旗下的 “Zendure(征拓)” 致力于家庭储能和能源管理系统的研发与销售,用户遍布全球。

对储能设备进行能量分析是 Zendure 的关键业务之一。这一动作能够帮助用户实时掌握储能设备的运行状态,通过对功率、电能以及输入输出数据此类典型的时序数据进行精准统计与分析,用户可清晰了解设备的能效表现与能源使用情况,轻松实现精细化管理和优化决策。
最初,我们采用关系型数据库管理储能设备的时序数据,但随着数据规模的迅猛增长,很快遇到了性能瓶颈,不得不寻找更高效的解决方案。在数据库选型过程中,我们了解到时序数据库 TDengine,其独特的“一设备一张表”数据模型、“超级表-子表”架构,以及卓越的性能表现,与我们的储能设备数据管理需求高度契合。
我们最初使用 TDengine OSS 开源版本进行业务数据存储,随着业务规模扩大和功能需求增加,2024 年正式升级至TDengine 企业版。借助 taosX 强大的数据接入与迁移能力,在涛思技术团队的支持下,我们不仅高效迁移了开源版的历史数据,还完成了 MySQL 存储数据的 transform 结构优化,并顺利导入 TDengine 企业版集群,实现了历史数据迁移、业务切换及表结构优化,确保系统平稳过渡,为储能业务的进一步发展奠定了坚实基础。
2.能量分析业务
2.1 问题描述
能量分析业务既需要从业务维度将数据分为功率、电能、输入输出这 3 类,分类别进行统计查询,又需要从设备维度,按每个设备的 device 信息进行统计查询。过去使用关系型数据库,无论是按照业务建表还是按照设备建表均无法很好地满足业务需求。
2.2 TDengine 解决方案
2.2.1 超级表设计
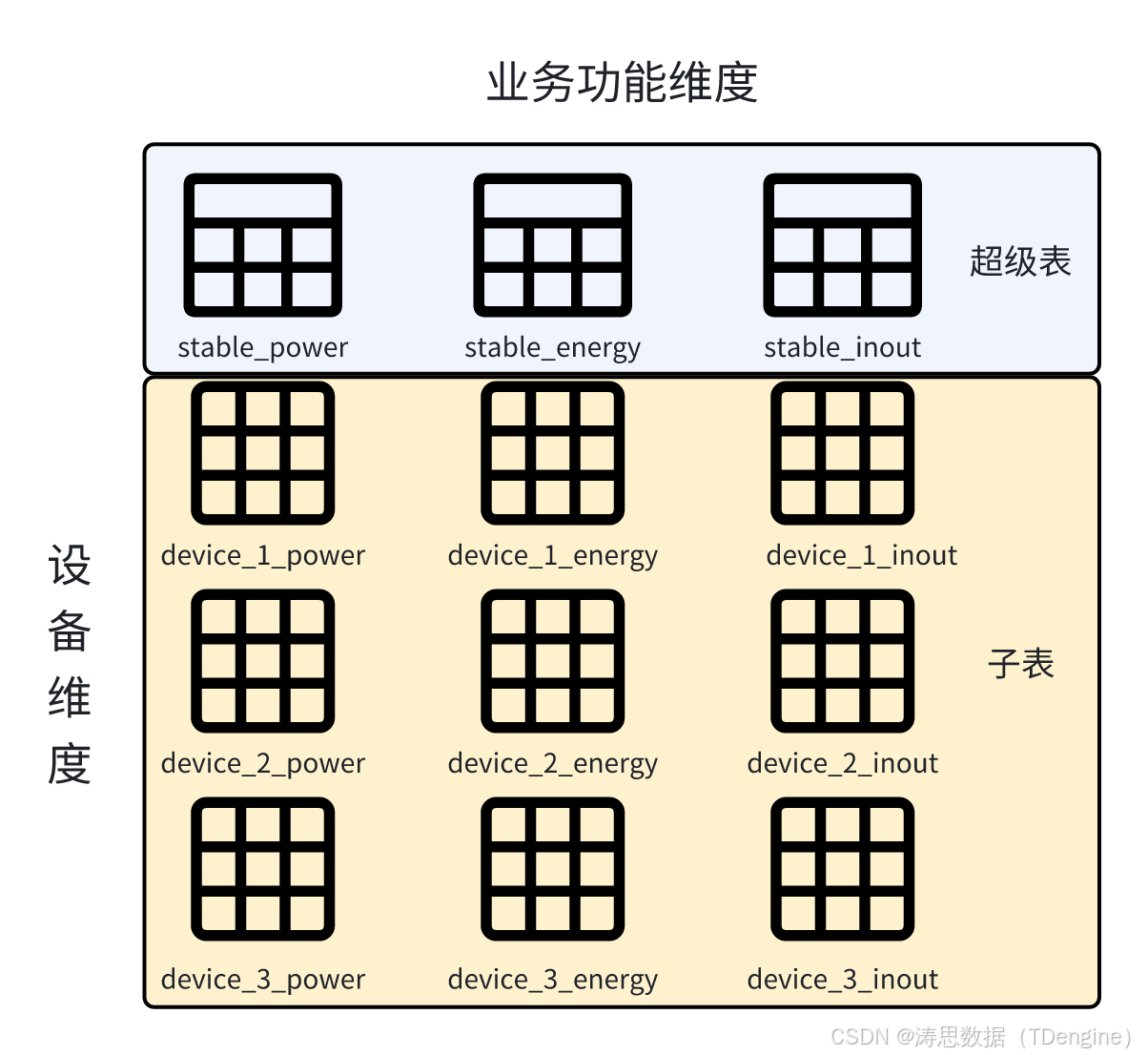
结合业务需求以及 TDengine “一个设备一张表” 数据模型,“超级表-子表” 组织结构,我们对设备储能数据的组织方式如下:
创建了 3 张超级表,分别对应设备的功率数据、电能数据以及输入输出数据。而每个设备的数据分别记录在超级表下的对应子表中,同时兼顾了业务维度与设备维度对数据组织的需求,如下图所示。
经过测试验证以及实际业务检验,TDengine 能够很好地支持储能设备能量分析业务,查询速度和数据压缩率表现都很优异。
2.2.2 高速查询
查询案例 1 :
统计 2024 年 9 月以来,每个设备每天的 energy 总和,查询语句和耗时记录如下,我们可以看到返回 100 余万笔统计结果,仅耗时 1 秒多。


查询案例 2:
查询设备 id 为 100048,在 2024-11-09 当天,全天的电力输入输出数据,返回 258 条数据耗时 0.513 秒。

2.2.3 高效压缩
使用 TDengine 的另一个优势,在于数据压缩率高。我们的数据服务部署在亚马逊云上,高压缩率给我们节省了很多成本。
对于功率、电能、输入输这 3 张超级表,数据压缩率分别达到了 5.34 %、5.95 %、8.63 % 。(数据压缩率指 data 文件中 实际占用的空间 / 无压缩状态下数据占用的空间 * 100%)。



2.2.4 应用界面展示
目前该项目运行中的储能设备数量已经超过 3 万台/套,系统运行稳定高效。部分数据查询页面如下图所示:


3. TDengine - TDengine 历史数据迁移
3.1 问题描述
采购企业版后,在涛思技术团队的协助下,我们在亚马逊云上成功部署了 3 节点集群。随之而来的挑战是如何在不中断原有业务的情况下,将开源版集群中一年的历史数据平稳迁移至新集群,并在大部分数据同步完成后再执行业务切换。
历史数据的大规模迁移一向是数据运维的难题,但幸运的是,TDengine 企业版内置了 taosX 组件,提供零代码数据接入能力,使得迁移过程更加高效便捷。
3.2 TDengine 解决方案
为尽快同步历史数据,同时保留对基础性能参数的调整灵活性,涛思技术团队采用 taosX 命令行模式,通过原生连接方式进行数据迁移操作。
taosx run -f "taos://root:XXXX@node1:6030/zendure_db?schema=none&unit=2d&start=2024-08-01T00:00:00Z&end=2024-09-01T00:00:00Z&libraryPath=/data/taos/soft/libtaos.so.3.0.7.1" -t 'taos://root:XXXX@tdengine-enterprise-eu-1:6030/zendure_db?fails-to=/data/error_db_sync_M08.log' -j 10上述命令行(密码用 XXXX 替换),能够从源端(-t),TDengine版本号为 3.0.7.1,hostsname 为 tdengine-enterprise-eu-1 的节点,以原生连接(6030)的方式将 dbname 为 zendure_db ,时间段为 2024-08-01 到 2024-09-01 的历史数据迁移到目标端(-f)。通过控制 -j 参数限制并发线程数,避免数据迁移操作对源端产生过大的影响。
在业务低谷期,按时间段倒叙迁移,每天迁移 3-4 个月的历史数据,最终我们成功在国庆假期之前完成了历史数据的迁移。
4. 超级表 schema 变更
4.1 问题描述
在最初使用 TDengine OSS 管理数据时,由于对其特性尚不熟悉,业务模式未完全梳理清晰,导致部分超级表的设计不够合理。例如,一些原本适合作为 tag 列的字段被误设为数据列,造成了不必要的磁盘空间浪费;部分超级表则需要新增 tag 列,以优化数据管理和查询效率。
由于这些表结构变更较为复杂,无法直接通过简单的增删数据列或 tag 列完成调整。为此,涛思技术团队协助设计了一套基于 CSV 文件的数据中转方案,并结合 taosX 与 taosExplorer 高效完成数据迁移,确保数据结构优化的同时,平稳过渡至新的存储架构。
4.2 TDengine 解决方案
实施思路
-
以 csv 文件作为数据中转形态
-
通过 taos shell 执行 SQL 语句,将原超级表数据批量导出到 csv 文件中
-
利用 TDengine 自带工具 taosX、taosExplore所具备的批量 csv 文件解析写入功能,将导出到 csv 文件中的原始数据按照新的表结构写入到新超级表中。
操作步骤
-
创建新数据库与新表
-
将原表数据分批次导出到 csv 文件中
-
创建 csv 写入任务
-
字段映射
-
执行数据写入并监测任务运行情况
-
数据正确性检验
-
业务迁移
-
遗留数据迁移
-
tag 赋值
关键步骤介绍
数据导出到 csv 文件与数据重新映射并写入 TDengine 是两个关键步骤。
首先,通过 taos shell 执行 SQL 语句,即可按指定时间范围导出历史数据至 CSV 文件。例如,使用以下 SQL 语句即可导出特定时间段的数据:
select tbname, * from test.meters where ts >='2017-07-14 10:00:00' and ts <'2017-07-14 11:00:00'>> /root/test/1.csv;
select tbname, * from test.meters where ts >='2017-07-14 11:00:00' and ts <'2017-07-14 11:30:00'>> /root/test/2.csv;
select tbname, * from test.meters where ts >='2017-07-14 11:30:00' and ts <'2017-07-14 12:00:00'>> /root/test/3.csv; 在 taosExplorer 中配置数据源,以及数据在新建超级表中的映射关系,即可实现变更表结构的需求。
我们可按照如下步骤配置数据源:

解析成功后,在“映射”选项卡中,配置新旧超级表之间的映射关系,在这一步将原始数据映射到新的表结构中。

在涛思技术团队的协助下,最终我们成功实现了表结构的变更与数据的迁移。
5.从 MySQL 迁移数据到 TDengine
5.1 问题描述
过去,一些历史数据存储在 MySQL 中,随着企业版 TDengine 的部署,我们希望将这些数据迁移至 TDengine集群进行统一管理。然而,由于 MySQL 与TDengine 的建表方式存在较大差异,我们需要对字段进行映射,并筛选出符合需求的部分数据进行导入。在涛思技术团队的支持下,我们借助 taosX 高效完成了数据筛选、结构映射及迁移,实现了 MySQL 历史数据的顺利接入。
5.2 TDengine 解决方案
taosX 可通过配置 SQL 语句从 MySQL 数据源查询所需数据,并将其映射至 TDengine 已创建的超级表或子表,实现数据的高效接入与迁移。SQL 配置界面如下图所示:

在迁移过程中,我们遇到了 taosX 无法识别 MySQL 时间戳字段的问题。通过使用 UNIX_TIMESTAMP 函数将 MySQL 的时间戳转换为 UNIX 时间戳,成功解决了该问题。
此外,MySQL 可存储所有时间戳相同的数据,而 TDengine 仅保留相同时间戳的最后一条记录。为满足业务需求,我们将 type 数据列的信息叠加到毫秒级时间戳中,在不使用复合主键的情况下,实现了类似的效果。
最终采用的 SQL 语句如下:
SELECT t.consumer_id,device_id,UNIX_TIMESTAMP(t.create_time)*1000+type as ts,power,type
FROM
t_device_inout_power_record t,t_device d,t_product pt
where
t.device_id=d.id and
d.product_id=pt.id and
pt.product_type_id in (3,4) and
create_zone_time>'2023-1-1';对从 MySQL 查询出来的数据进行映射处理:

任务执行完成后的指标如下,可以看到总计导入了四千多万行数据,完成了数据从 MySQL 向 TDengine的迁移。

6.结语
时序数据的迅猛增长曾给我们带来查询效率和存储成本的挑战,而 TDengine 的引入成功解决了这些问题。尤其值得一提的是 taosX 组件,其零代码数据迁移能力大幅降低了开发时间和成本,让数据管理更加高效便捷。
家庭储能与户外储能市场仍在快速发展,对时序数据的高效管理需求也将持续增长。未来,我们期待与 TDengine 携手,共同助力中国企业扬帆出海,为全球能源管理贡献更多力量。
本文作者:疆海科技 马老师
关于疆海科技
广州疆海科技有限公司创立于 2017 年,是一家设计与技术驱动的国家高新技术企业,致力于家庭储能和能源管理系统的研发与销售。公司目前累计申请专利 70 多项,已有专利 60 多项;产品多次获得德国红点、德国 iF 和日本 G-Mark 设计大奖。公司旗下的“Zendure(征拓)”品牌在欧美有较高知名度,在全球各地有大量忠实用户。目前公司的分销渠道覆盖欧美中东日本等全球 63 个国家,上千家线下门店,并且通过亚马逊等电商平台直接面向消费者销售,是中国出海品牌中少有的拥有完善的线上线下渠道的品牌之一。







![【数据结构】[特殊字符] 并查集优化全解:从链式退化到近O(1)的性能飞跃 | 路径压缩与合并策略深度实战](https://i-blog.csdnimg.cn/direct/81f95b97a06c4f66be7895afedcb590d.jpeg#pic_center)