6-1 二叉树的遍历
函数接口定义:
void InorderTraversal( BinTree BT ); void PreorderTraversal( BinTree BT ); void PostorderTraversal( BinTree BT ); void LevelorderTraversal( BinTree BT );其中
BinTree结构定义如下:typedef struct TNode *Position; typedef Position BinTree; struct TNode{ ElementType Data; BinTree Left; BinTree Right; };要求4个函数分别按照访问顺序打印出结点的内容,格式为一个空格跟着一个字符。
裁判测试程序样例:
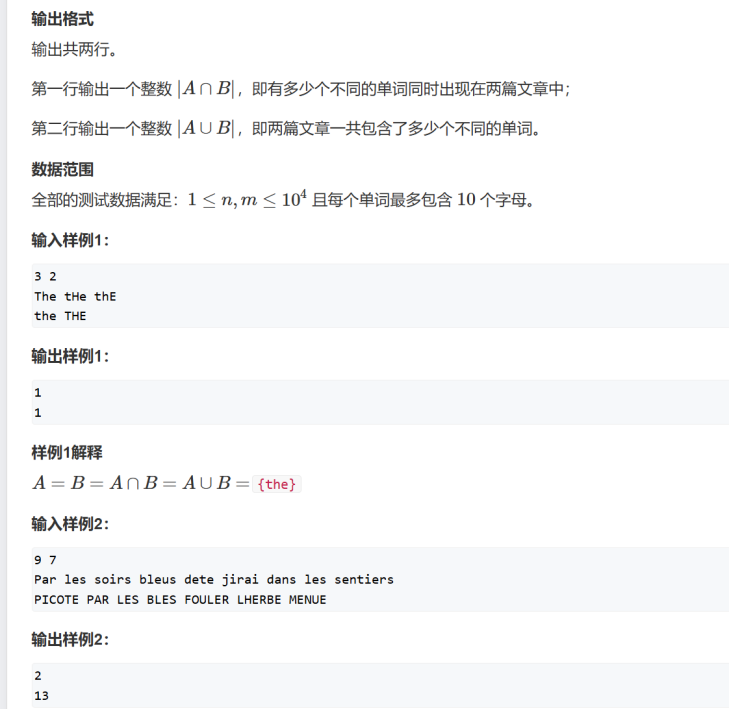
#include <stdio.h> #include <stdlib.h> typedef char ElementType; typedef struct TNode *Position; typedef Position BinTree; struct TNode{ ElementType Data; BinTree Left; BinTree Right; }; BinTree CreatBinTree(); /* 实现细节忽略 */ void InorderTraversal( BinTree BT ); void PreorderTraversal( BinTree BT ); void PostorderTraversal( BinTree BT ); void LevelorderTraversal( BinTree BT ); int main() { BinTree BT = CreatBinTree(); printf("Inorder:"); InorderTraversal(BT); printf("\n"); printf("Preorder:"); PreorderTraversal(BT); printf("\n"); printf("Postorder:"); PostorderTraversal(BT); printf("\n"); printf("Levelorder:"); LevelorderTraversal(BT); printf("\n"); return 0; } /* 你的代码将被嵌在这里 */输出样例(对于图中给出的树):
Inorder: D B E F A G H C I Preorder: A B D F E C G H I Postorder: D E F B H G I C A Levelorder: A B C D F G I E H

解题思路
首先我们要知道前序遍历,中序遍历,后序遍历
前序遍历是从根节点出发,然后到左子树最后再到右子树
中序遍历是从遍历到左子树,然后再飞去根节点,最好到右子树
后序遍历是从遍历到左子树,然后再飞去右子树,最后到根节点
我们有来前序,中序和后序遍历的顺序之后,我就要开始编写代码了
层次遍历就是一层一层的从左边往右边进行遍历这棵树,这个就要用到队列的思想了
前序遍历
我们在进行前序遍历的时候,,是先遍历根然后再遍历左子树
所以我们在写递归的时候,就要先遍历根然后再遍历左子树void PreorderTraversal(BinTree BT){ if(BT == NULL){ return; } printf(" %c",BT -> Data); PreorderTraversal(BT -> Left); PreorderTraversal(BT -> Right); }这里我们进行根的遍历,然后再进入左子树,所以我们的printf是放在前面的
同理可得其他的情况是怎么个情况
中序遍历void InorderTraversal(BinTree BT){ if(BT == NULL){ return; } InorderTraversal(BT -> Left); printf(" %c",BT -> Data); InorderTraversal(BT -> Right); }后序遍历
void PostorderTraversal(BinTree BT){ if(BT ==NULL){ return; } PostorderTraversal(BT -> Left); PostorderTraversal(BT -> Right); printf(" %c",BT -> Data); }层次遍历
这种遍历一般是要用到队列的,但是在这个题目中,数据量没有这么大,所以博主就模拟了一个数组大小为100的队列进行操作void LevelorderTraversal(BinTree BT){ BinTree array[100]; int front = 0; int rear = 0; array[rear++] = BT; while(front < rear){ BinTree current = array[front++]; printf(" %c", current -> Data); if(current -> Left != NULL){ array[rear++] = current -> Left; } if(current -> Right != NULL){ array[rear++] = current -> Right; } } }这里我们可以运用这个数组再加两个变量作为队列的头指针和尾指针方便演示出队和进队的操作,然后就是我们放进来一个节点之后,就要去放入他的左孩子和右孩子,这样就可以做到层次遍历,因为是可以通过入队的顺序找到对应的孩子节点
我们数组的属性是要为树的节点的属性的,然后我们放入之后,不段的取出,然后取出之后判断这个有没有左孩子和右孩子,我们下一次取出的就是这个节点的左孩子和右孩子节点,然后按照顺序依次放入就好了
注意:我们是要从头取出,从对尾巴进入,很重要
当然博主也写出了队列的操作typedef struct Que{ struct aNode* head; struct aNode* tail; }Que; typedef struct aNode{ BinTree data; struct aNode* Next; }aNode; Que* creatQueue(){ Que* temp = (Que*) malloc (sizeof(Que)); temp -> head = NULL; temp -> tail = NULL; return temp; } void push(Que* q, BinTree root){ if(q == NULL) return; aNode* temp = (aNode*) malloc (sizeof(aNode)); temp -> data = root; temp -> Next = NULL; if(q -> head == NULL){ q -> head = temp; q -> tail = temp; } else{ q -> tail -> Next= temp; q -> tail = temp; } } BinTree pop(Que* q){ if(q == NULL ||q -> head == NULL) return NULL; aNode* temp = q -> head; BinTree temp1 = temp -> data; q -> head = q -> head -> Next; if(q -> head == NULL) q -> tail = NULL; free(temp); return temp1; } void LevelorderTraversal(BinTree BT){ if(BT == NULL) return; Que* q = creatQueue(); push(q, BT); while(q->head != NULL){ BinTree current = pop(q); printf(" %c", current -> Data); if(current -> Left != NULL){ push(q, current -> Left); } if(current -> Right != NULL){ push(q, current -> Right); } } }
7-1 是否同一棵二叉搜索树
给定一个插入序列就可以唯一确定一棵二叉搜索树。然而,一棵给定的二叉搜索树却可以由多种不同的插入序列得到。例如分别按照序列{2, 1, 3}和{2, 3, 1}插入初始为空的二叉搜索树,都得到一样的结果。于是对于输入的各种插入序列,你需要判断它们是否能生成一样的二叉搜索树。
输入格式:
输入包含若干组测试数据。每组数据的第1行给出两个正整数N (≤10)和L,分别是每个序列插入元素的个数和需要检查的序列个数。第2行给出N个以空格分隔的正整数,作为初始插入序列。随后L行,每行给出N个插入的元素,属于L个需要检查的序列。
简单起见,我们保证每个插入序列都是1到N的一个排列。当读到N为0时,标志输入结束,这组数据不要处理。
输出格式:
对每一组需要检查的序列,如果其生成的二叉搜索树跟对应的初始序列生成的一样,输出“Yes”,否则输出“No”。
输入样例:
4 2 3 1 4 2 3 4 1 2 3 2 4 1 2 1 2 1 1 2 0输出样例:
Yes No No
解题思路
这个题目的解题思路,我们不断地比较根节点,就是树的根节点,我们知道一棵树的有左子树和右子树,然后左子树和右子树也有对应的根节点,不断判断就好了bool dfs(int a[], int b[], int n){ if(n == 0) return true; if(a[1] != b[1]) return false; int right1[20]; int left1[20]; int right2[20]; int left2[20]; int r1 = 0; int l1 = 0; int r2 = 0; int l2 = 0; for(int i = 2; i<=n; i++){ if(a[i] > a[1]) right1[++r1] = a[i]; else left1[++l1] = a[i]; if(b[i] > b[1]) right2[++r2] = b[i]; else left2[++l2] = b[i]; } if(r1 != r2||l1!= l2) return false; return dfs(right1, right2, r1) && dfs(left1, left2, l1); } int main(){ int n, m; int num1[20]; int num2[20]; while(1){ scanf("%d",&n); if(n == 0) break; scanf("%d",&m); for(int i = 1; i<=n; i++){ scanf("%d",&num1[i]); } for(int i = 1; i<=m; i++){ bool key; for(int j = 1; j<=n; j++){ scanf("%d",&num2[j]); key = dfs(num1,num2,n); } if(key== false){ printf("No\n"); } else{ printf("Yes\n"); } } } }我们再判断的时候加上四个数组和四个变量作为左子树和右子树的大小,这个比较大小的操作是可以没有的,但是为了计算量减少,我们就用了减枝
我们这个先把这个树分割为左子树和右子树,左子树和右子树的顺序很重要,我们要理解,如果子树得顺序不一样得话,那么节点得顺序就不一样
所以我们判断他们的顺序就好了,但是怎么判断顺序呢?就是不断地判断根节点就好了

7-2 堆中的路径
将一系列给定数字插入一个初始为空的最小堆 h。随后对任意给定的下标 i,打印从第 i 个结点到根结点的路径。
输入格式:
每组测试第 1 行包含 2 个正整数 n 和 m (≤103),分别是插入元素的个数、以及需要打印的路径条数。下一行给出区间 [−104,104] 内的 n 个要被插入一个初始为空的小顶堆的整数。最后一行给出 m 个下标。
输出格式:
对输入中给出的每个下标 i,在一行中输出从第 i 个结点到根结点的路径上的数据。数字间以 1 个空格分隔,行末不得有多余空格。
输入样例:
5 3 46 23 26 24 10 5 4 3输出样例:
24 23 10 46 23 10 26 10
我们要把这序列变成一个有序的一个顺序,这个也就是数组表示的一个二叉搜索树反制
#include<stdio.h> #include<string.h> long ans[10000]; void adjust(int x) { while (x > 1) { int parent = x / 2; if (ans[x] < ans[parent]) { long temp = ans[x]; ans[x] = ans[parent]; ans[parent] = temp; x = parent; } else { break; } } } void mysort(int a[], int n, int x) { if (x == n + 1) return; ans[x] = a[x]; adjust(x); mysort(a, n, x + 1); } int main() { int h, n; for (int i = 0; i < 10000; i++) { ans[i] = -10001; } scanf("%d %d", &h, &n); int num1[10000]; for (int i = 1; i <= h; i++) { scanf("%d", &num1[i]); } mysort(num1, h, 1); // for (int i = 1; i <= h; i++) { // printf("%d ", ans[i]); // } for(int i = 1;i <= n; i++){ int w; scanf("%d",&w); int first = 0; while(1){ if(w == 0) break; if(first == 0){ printf("%d",ans[w]); first = 1; } else printf(" %d",ans[w]); w = w/2; } printf("\n"); } return 0; }解题思路
我们用递归的方法不断地排序我们的顺序,然后排序的方法我们单独写一个,递归出口就是n+1
最关键的void adjust(int x) { while (x > 1) { int parent = x / 2; if (ans[x] < ans[parent]) { long temp = ans[x]; ans[x] = ans[parent]; ans[parent] = temp; x = parent; } else { break; } } }这里是用到不断地对x/2来进行表示parent,然后再判断是否小于,如果小于就交换
总结
1 遍历的方法,这个后面很常用
2 判断是否是同一个二叉树,就是不断对树的根节点进行判断,而且顺序是一样的,因为插入的方法
3 堆的就是路径就是用一个while循环来往前面不断地比较