持续调度参数在高负载大集群中的影响
- 背景介绍
- 2种调度通信方式
- 对集群的影响
- 社区相关的讨论
- 结论
背景介绍
这几年经历了我们大数据的Yarn集群的几次扩容,集群从原先的800多台增加到1300多台到现在的1600多台,在集群规模不断增加的过程中,有遇到一次扩容后调度性能不增反降的情况,经过排查确认到是和持续调度有关。
本文记录了该问题的详细排查过程和解决手段。
2种调度通信方式
该问题出现在我们的最近一次扩容,集群规模扩大到1600多台(当然可能之前也已经出现了这个问题,只是没有特别恶化),扩容后不久,集群的调度性能出现整体下降的情况,具体表现为:资源使用率始终上不去,并且出现了大量的处于SUBMITTED的任务;集群在扩容后整体的性能不增反降,每天的离线任务反而没法在计划时间内跑完。
分析这个问题前,要了解Yarn的心跳机制,默认有这样的一个心跳机制:
- 每个 NodeManager(NM)会定期向 ResourceManager(RM)发送心跳。这些心跳基于配置项
yarn.resourcemanager.nodemanagers.heartbeat-interval-ms; - 在这个心跳过程中,每个 NM 会告诉 RM 有多少未使用的容量,FairScheduler 将为该 NM 分配一个或多个容器以在该 NM 上运行。默认的心跳间隔为 1 秒(即每秒 1 次心跳)。
上面说的是常规的基于心跳的容器分配,但是我们的集群启用了一个参数yarn.scheduler.fair.continuous-scheduling-enabled,这个是持续调度参数,该参数启用的情况下,调度情况表现为:
- FairScheduler 开启连续调度。在连续调度模式下,有一个独立的线程执行容器分配,然后根据属性
yarn.scheduler.fair.continuous-scheduling-sleep-ms暂停一段时间(毫秒) - 持续调度不依赖与NM的心跳通信,是连续发生的,当心跳到来,会将调度结果直接返回给NM
两者的区别:
- 心跳调度机制下,当收到某个节点的心跳,就对这个节点且仅仅对这个节点进行一次调度,即谁的心跳到来就触发对谁的调度,
- 持续调度的每一轮,是会遍历当前集群的所有节点,每个节点依次进行一次调度,保证一轮下来每一个节点都被公平地调度一次
对集群的影响
说完了心跳调度和持续调度,我们再说下为什么我们出现大部分任务SUBMITTED不运行。
上面已经说了,在持续调度的时候,会遍历当前集群的所有节点,而连续调度会在这个过程中获取锁,在集群规模小的时候,影响不大,节点数量很多的情况下,拿到锁到释放会持续大量时间,说白了,就是遍历太久了。
社区相关的讨论
在YARN-3091下,社区对这个问题是有过多种尝试的,比如把对象锁换成读写锁,但是目前看,社区还是决定启用持续调度,具体可以看YARN-6486
对于这个事实,可以通过SLS工具进行进一步的模拟证明:
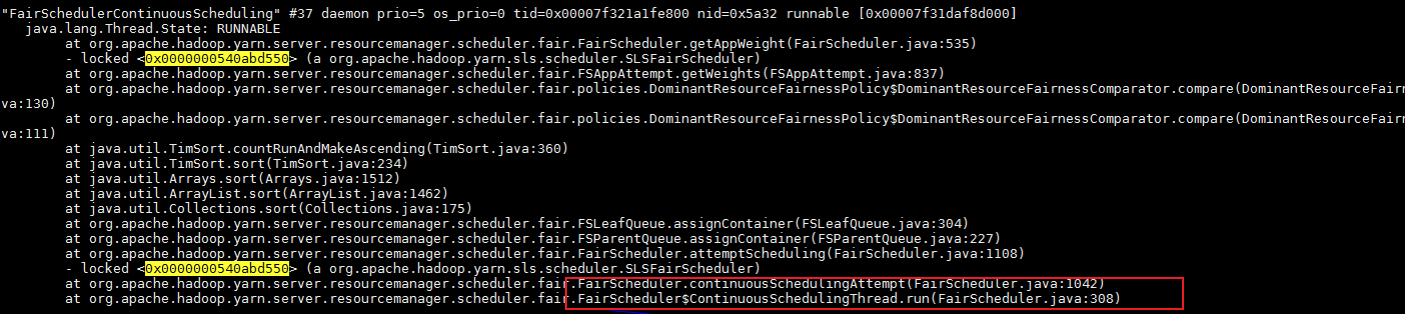
在2000节点下开启了持续调度,复现生产问题,30分钟完成0个作业,SUBMITTED(积压)状态作业高达28000个。调度操作延时到达700ms:
在H3当前的版本中,已经有了相关的推荐配置:

结论
最终,对于持续工作负载的大集群,推荐使用以下设置:
yarn.scheduler.fair.continuous-scheduling-enabled = false
yarn.scheduler.fair.assignmultiple = true
这样一方面关闭了持续调度,另一方面开启了一次心跳中分配多个containers,调度不会再出现大面积SUBMITTED任务,同时性能也能保障。


















