前文:https://www.cnblogs.com/odesey/p/16902836.html
如果图不能加载,请查看原文:https://www.cnblogs.com/odesey/p/16907351.html
介绍了混淆矩阵。本文旨在说明其他机器学习模型的评价指标。
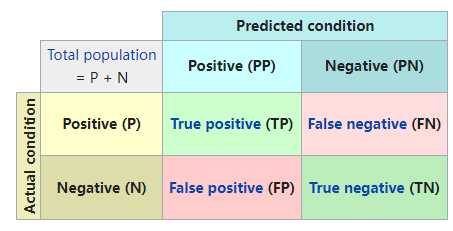
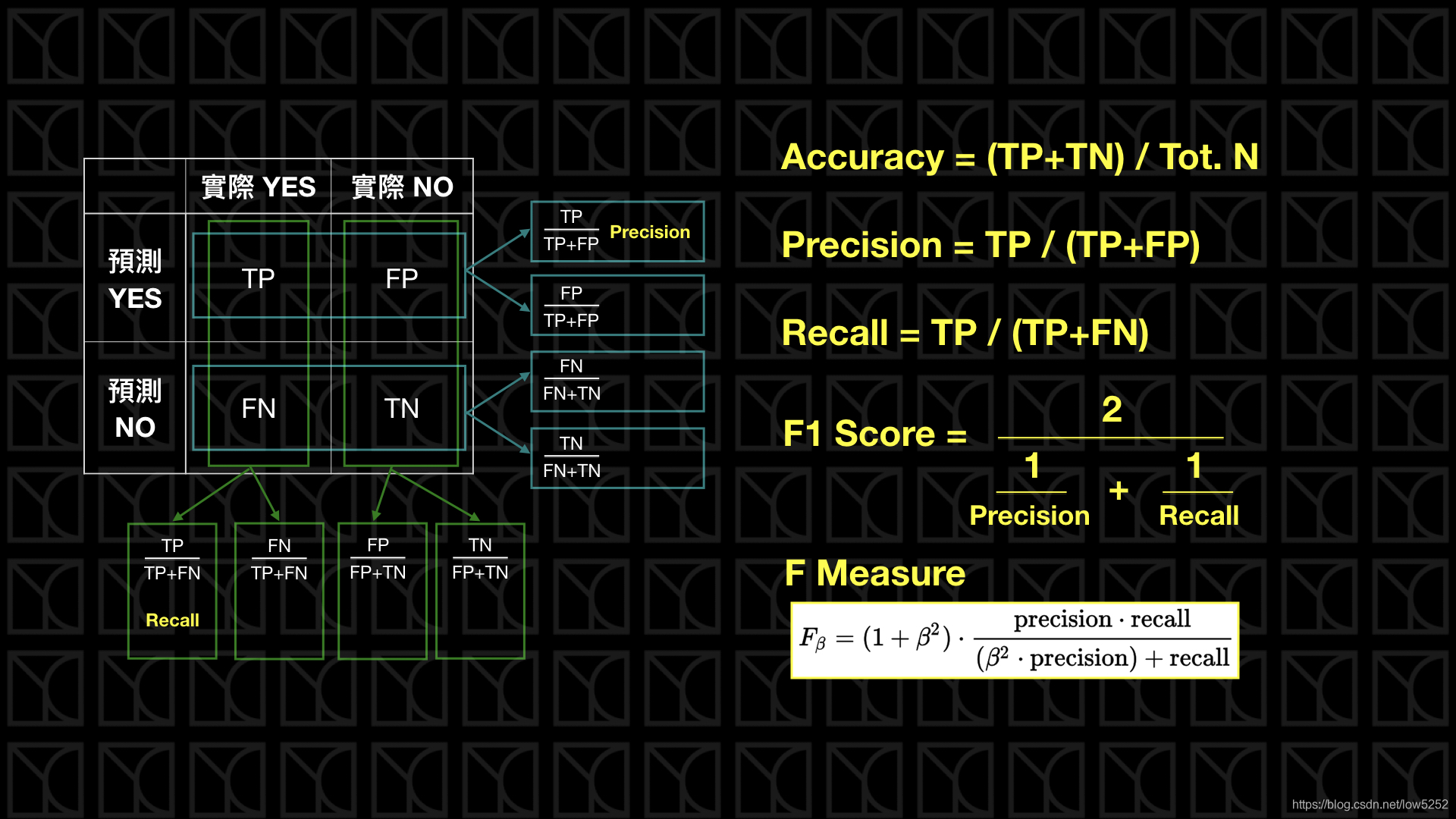
1. 准确率(Accuracy-Acc)
A c c = T P + T N T P + T N + F P + F N Acc = \frac{TP+TN}{TP+TN+FP+FN} Acc=TP+TN+FP+FNTP+TN
显然,Acc 表示模型预测正确(混淆矩阵的对角线)与全部样本(所有加一起)的比值。
Acc 评价指标对平等对待每个类别,即每一个样本判对 (0) 和判错 (1) 的代价都是一样的。
问题 : 精度有什么缺陷?什么时候精度指标会失效?
- 对于有倾向性的问题,往往不能用 ACC 指标来衡量。比如,判断空中的飞行物是导弹还是其他飞行物,很显然为了减少损失,我们更倾向于相信是导弹而采用相应的防护措施。此时判断为导弹实际上是其他飞行物与判断为其他飞行物实际上是导弹这两种情况的重要性是不一样的;
- 对于样本类别数量严重不平衡的情况,也不能用 ACC 指标来衡量。比如银行客户样本中好客户990个,坏客户10个。如果一个模型直接把所有客户都判断为好客户,得到精度为99%,但这显然是没有意义的。
样本类别数不平衡指的是:所有样本中的大部分都是正样本,或负样本。如入职体检中,未患癌症的样本是占优的;所有投保客户中的非欺诈客户是占优的。
2. 查准率(Precision)
Precision 统计 “预测为 Positive 且预测正确(TP) 的样本”中,有多少预测是正确的。
P = T P T P + F P P = \frac{TP}{TP+FP} P=TP+FPTP
从公式可以看出,Precision 从 预测为 Positive 结果 出发,计算 模型预测为 Positive且预测正确(TP) 占 模型预测的所有 Positive 样本(TP+FP) 的比例。
Precision 越高意味着模型对 “预测为 Positive ” 的判断越可信。
3. 查全率/召回率(Recall)
R = T P T P + F N R = \frac{TP}{TP+FN} R=TP+FNTP
从公式可以看出,Recall 从 真实标签为 Positive 出发,计算 模型预测为 Positive 且预测正确(TP) 占 真实的所有 Positive 样本(TP+FN) 的比例。
Recall 越高越好,越高意味着模型对 “实际为正” 的样本误判越少,漏判的概率越低。
在 混淆矩阵的 列是预测值的前提下,Precision 和 Recall 的简记为 “竖准横全”。
4. Precision 和 Recall 之间的关系
业务场景下,对模型对查准率和查准率的侧重,可能有所不同。
例子:
-
地震的预测 对于地震的预测,我们希望的是 Recall 非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲 Precision。情愿发出 1000 次警报,把 10 次地震都预测正确了;也不要预测 100 次对了 8次 漏了两次。
-
在 量化投资 的场景下,错标的成本很高,所以 Precision 要高。即使,模型会错失很多的投资机会,但如果因为误标记,做了一笔错误的交易,公司就会产生重大资损。
“宁错拿一万,不放过一个”,分类阈值较低
-
嫌疑人定罪 基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。即使有时候放过了一些罪犯,但也 是值得的。因此我们希望有较高的 Precision 值,可以合理地牺牲 Recall。
-
在恶意骗保识别的场景下,漏标的代价很大,所以查全率要高。即使,把一些正常的客户标记为了高风险的客户,也可以在后续的人工复核中做二次审核,继续理赔流程。但如果漏标了恶意骗保客户,公司就会产生重大资损。
“宁放过一万,不错拿一个”,“疑罪从无”,分类阈值较高
● 所以在建模实操当中,我们不可避免的要对查全率和查准率两者进行权衡。权衡的方式之一,就是对两者进行调和平均,即F值。
问题 :
某一家互联网金融公司风控部门的主要工作是利用机器模型抓取坏客户。互联网金融公司要扩大业务量,尽量多的吸引好客户,此时风控部门该怎样调整Recall和Precision?如果公司坏账扩大,公司缩紧业务,尽可能抓住更多的坏客户,此时风控部门该怎样调整Recall和Precision?
答: 如果互联网公司要扩大业务量,为了减少好客户的误抓率,保证吸引更多的好客户,风控部门就会提高阈值,从而提高模型的查准率Precision,同时,导致查全率Recall下降。如果公司要缩紧业务,尽可能抓住更多的坏客户,风控部门就会降低阈值,从而提高模型的查全率Recall,但是这样会导致一部分好客户误抓,从而降低模型的查准率 Precision。
当然 Precision 越高越好,Recall 也是越高越好。但根据以上几个案例,我们知道随着阈值的变化 Recall 和 Precision 变化的方向是往往是相悖的,因为:
- 提高 Precision ,意味着模型要更加精准的、更加确定性的标记“正值”,这就意味着标记更少的正样本;
- 而提高 Recall ,意味着要圈选更多的正样本,以避免漏判,这就意味着标记更多的正样本。
建模实操当中,我们不可避免的要对查全率和查准率两者进行权衡。权衡的方式之一,就是对两者进行调和平均,即 F-Score 。
5. F-Score
F β = ( 1 + β 2 ) × P × R β 2 × P + R F_\beta =(1+\beta ^2)\times \frac{P\times R}{\beta ^2 \times P + R} Fβ=(1+β2)×β2×P+RP×R
β 表示权重。β 越大,Recall 的权重越大; 越小,Precision 的权重越大。
特别的,β = 1,称为 F1-Score。
F β F_\beta Fβ 的物理意义就是将 Precision 和 Recall 这两个分值合并为一个分值,在合并的过程中,Recall 的权重是 Precision 的 β 倍 。 F1 分数认为 Recall 和 Precision 同等重要,F2 分数认为 Recall 的重要程度是 Precision 的 2 倍,而 F0.5 分数认为 Recall 的重要程度是 Precision 的一半。
应用领域
F 分数被广泛应用在信息检索领域,用来衡量检索分类和文档分类的性能。早期人们只关注 F1 分数,但是随着谷歌等大型搜索引擎的兴起,Precision 和 Recall 对性能影响的权重开始变得不同,人们开始更关注其中的一种,所以 F β F_\beta Fβ 分数得到越来越广泛的应用。
F 分数也被广泛应用在自然语言处理领域,比如命名实体识别、分词等,用来衡量算法或系统的性能。
几张不错的图:



大多情况算数平均都可以使用,因为我们都假设有线性关系存在,譬如说平均距离;几何平均常用于人口计算,因为人口增加是成比例增加的;调和平均常用于计算平均速率,在固定距离下,所花时间就是平均速率,这数据成倒数关系,而F1 Measure也同样是这样的数据特性,在固定TP的情况下,有不同的分母,所以这里使用调和平均较为适当。
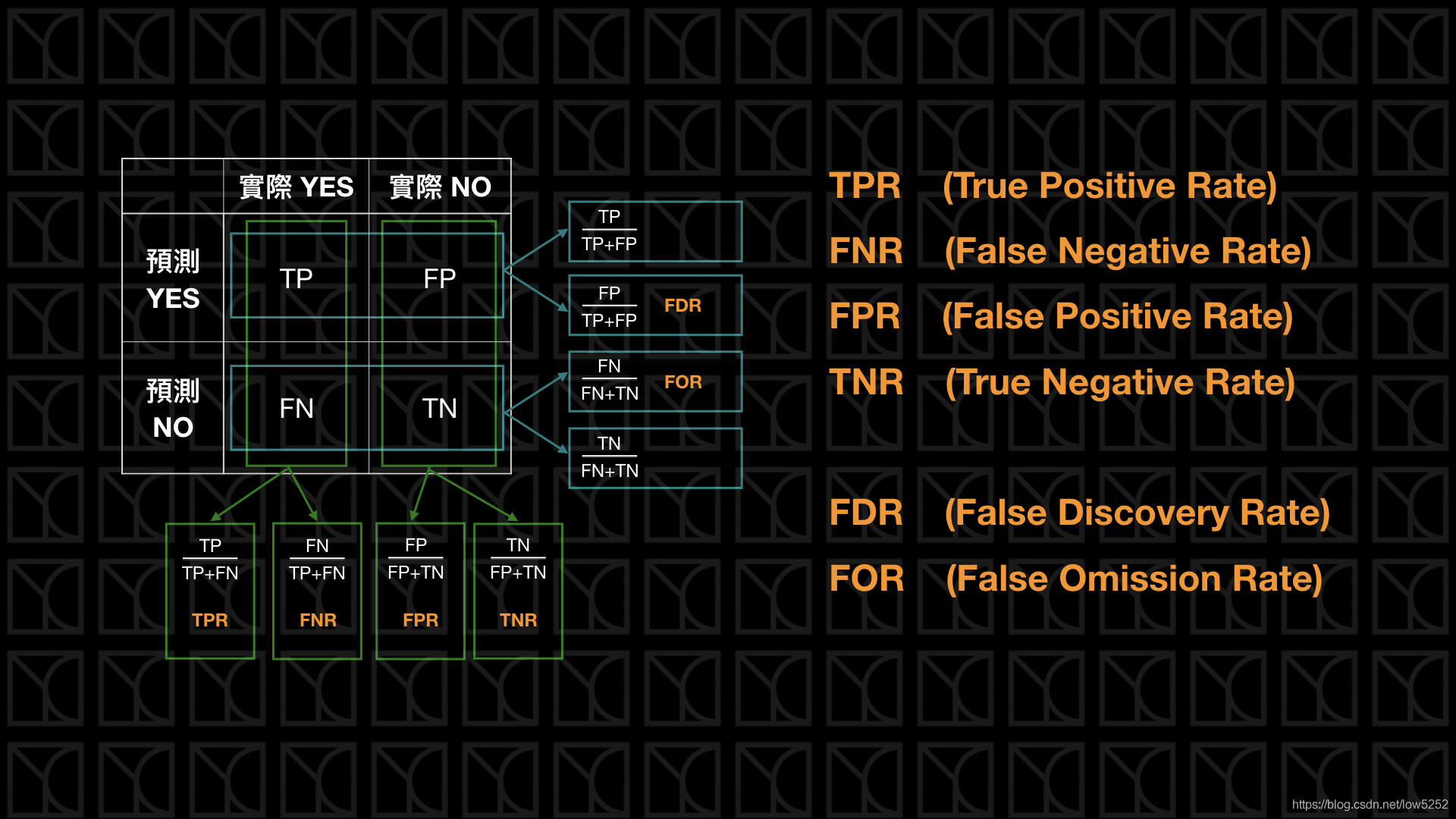
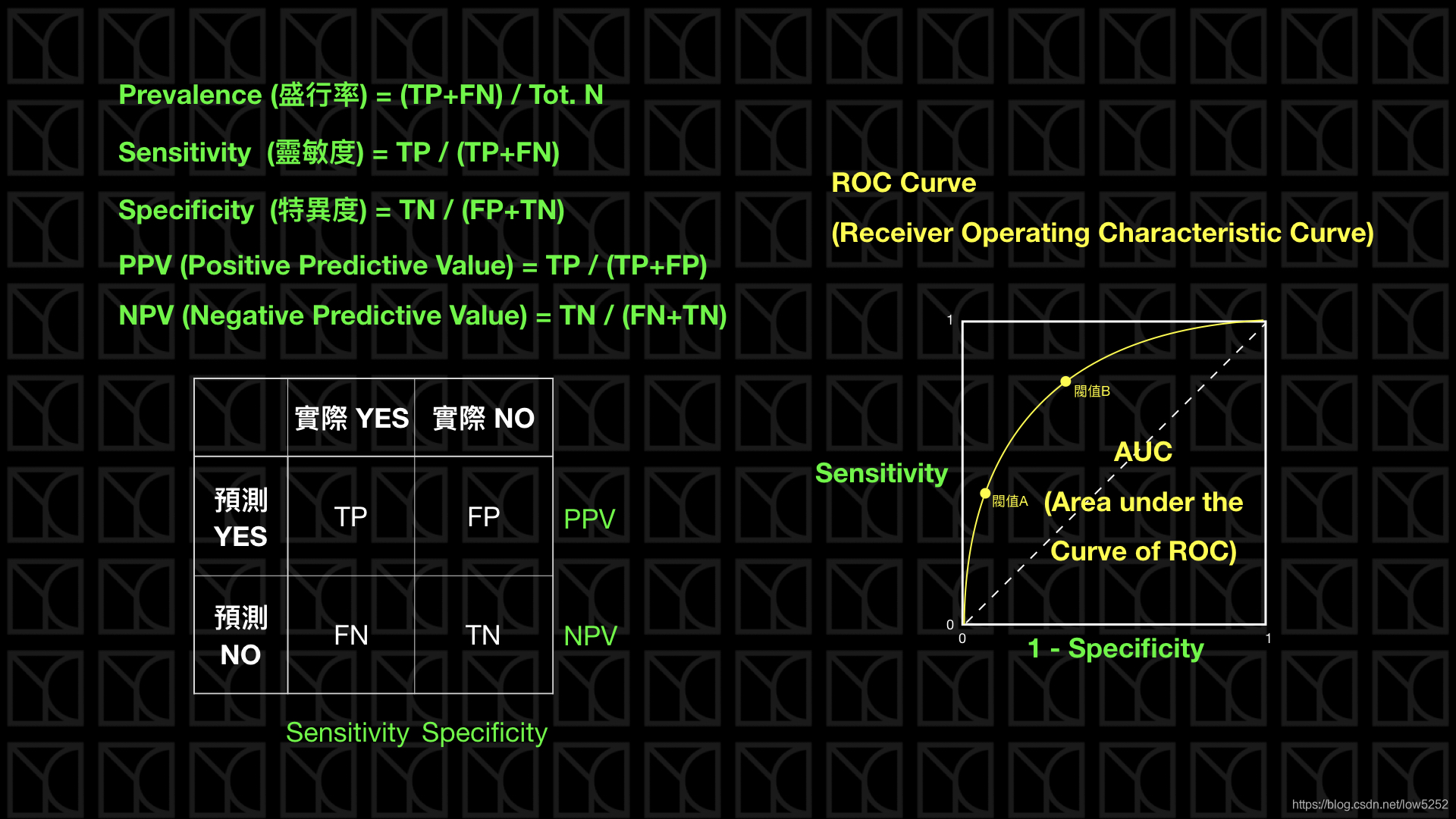
不过上述图,列是 真实值,而我们的列是 预测值。图来自:https://blog.csdn.net/low5252/article/details/104429898
6. P-R Curve(P-R 曲线)
因为大部分机器学习模型都是概率模型,即输出都是概率,比如逻辑回归模型。因此选择不同的 阈值 就可以得到不同的混淆矩阵,也就得到了不同的 P, R。每一对 P,R 对应 P-R Curve 图中的一个点,连接点就得到了 P-R 曲线。
注意:横坐标是 R, 纵坐标是 R。
问题:如何生成 P-R 曲线?
当然,你可以选择直接调用 sklearn 包的函数。那内部怎么做呢?sklearn.metrics.precision_recall_curve 中的关键源码如下:
# 按预测概率(score)降序排列
desc_score_indices = np.argsort(y_score, kind="mergesort")[::-1]
y_score = y_score[desc_score_indices]
y_true = y_true[desc_score_indices]
# 概率(score)阈值, 取所有概率中不相同的
distinct_value_indices = np.where(np.diff(y_score))[0]
threshold_idxs = np.r_[distinct_value_indices, y_true.size-1]
thresholds = y_score[threshold_idxs]
# 累计求和, 得到不同阈值下的 tps, fps
tps = np.cumsum(y_true)[threshold_idxs]
fps = 1 + threshold_idxs - tps
# PR
precision = tps / (tps + fps)
precision[np.isnan(precision)] = 0 # 将nan替换为0
recall = tps / tps[-1]
last_ind = tps.searchsorted(tps[-1]) # 最后一个tps的index
sl = slice(last_ind, None, -1) # 倒序
precision = np.r_[precision[sl], 1] # 添加 precision=1, recall=0, 可以让数据从0开始
recall = np.r_[recall[sl], 0]
从代码中总结了计算PR的几个关键步骤:
- 对于预测概率(score)排序, 从高到低
- 以预测概率(score)作为阈值统计 tps 和 fps
- 计算 precision 和 recall , 并倒序
参考:https://zhuanlan.zhihu.com/p/404798546
tps 和 fps 指的是混淆矩阵中的 TP 和 FP 个数。

举例说明:
在一个识别图片是否是车,这样一个二分类任务中,我们训练好了一个模型。假设测试样例有20 个,用训练好模型测试可以得到如下测试结果: 其中 id (序号),confidence score (置信度、得分) 和 ground truth label (类别标签)。
例子来自:https://smilelingyong.github.io/2019/03/21/Precision-Recall-R-Pcurve-ROC-AUC-mAP/
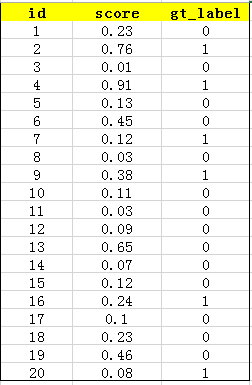
接下来对 confidence score 排序,得到:
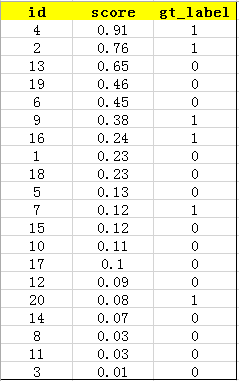
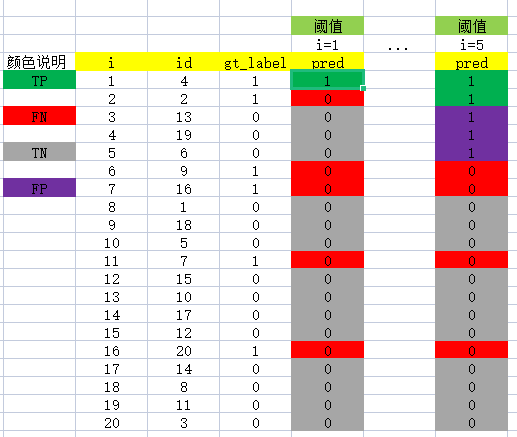
然后我们开始计算 P-R曲线 值,将排序后的样例,从 (i = 1) 到 (i = 20) 遍历,每次将第 (i) 个样例的 confidence scores 做为阈值,前 (i) 个预测为正例时,计算对应的 Precision 和 Recall。
例如,当 (i = 1) 时,预测了一个作为 正例,其余的都预测为反例,此时的阈值为 0.91。 此时的 TP=1 就是指 第4张(id=4),FP=0,FN=5 为第 2、9、16、7、20 的图片, TN=15 为 13,19,6,1,18,5,15,10,17,12,14,8,11,3。Precision = TP/(TP+FP) = 1/(1+0) = 0 ;Recall = TP/(TP+FN) = 1/(1+5)=1/6 。接着计算当 (i = 2) 时,以此类推…
为了便于理解,我们再讲一个例子当 (i = 5) 时,表示我们选了前5个预测结果认为是正例,此时阈值为0.45。
两种情况如下图:
调用 sklearn 验证上述计算过程是否正确:
import seaborn as sns
from matplotlib import pyplot as plt
from scipy.special import softmax
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score
from sklearn.metrics import precision_recall_curve
sns.set_theme(color_codes=True)
y_true = [1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0]
## i = 1
y_pred = [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# ## i = 5
# y_pred = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# 准确率acc,精准precision,召回recall,F1
acc = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f'[Info] acc: {acc:.3f}, precision: {precision:.3f}, recall: {recall:.3f}, f1: {f1:.3f}')
# 横坐标是真实类别数,纵坐标是预测类别数
cf_matrix = confusion_matrix(y_true, y_pred)
# 横坐标是真实类别数,纵坐标是预测类别数
cf_matrix = confusion_matrix(y_true, y_pred)
# figure, axes = plt.subplots(2, 2, figsize=(16*1.25, 16))
# 混淆矩阵
# ax = sns.heatmap(cf_matrix, annot=True, fmt='g', ax=axes[0][0], cmap='Blues')
ax = sns.heatmap(cf_matrix, annot=True, fmt='g', cmap='Blues')
ax.title.set_text("Confusion Matrix")
ax.set_xlabel("y_pred")
ax.set_ylabel("y_true")
# plt.savefig(csv_path.replace(".csv", "_cf_matrix.png"))
plt.show()
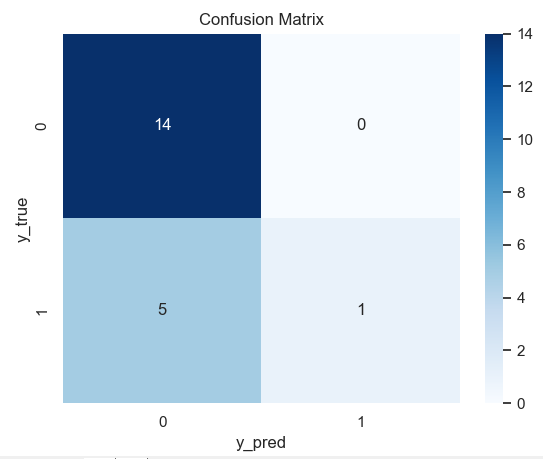
输出:
[Info] acc: 0.750, precision: 1.000, recall: 0.167, f1: 0.286
i=1 时的混淆矩阵:
参考:
- 注意 average 参数含义:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html#sklearn.metrics.precision_score
- P-R 曲线 是从右往左画的:https://zhuanlan.zhihu.com/p/404798546
如何理解 P-R 曲线?
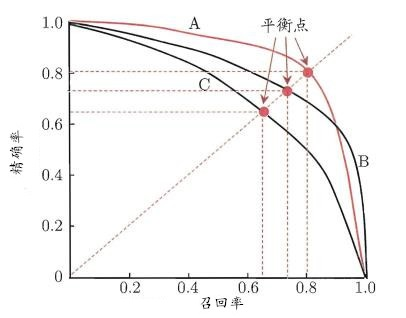
注意:为绘图方便和美观,示意图显示出单调平滑曲线,但现实任务中的P-R曲线常是非单调、不平滑的,在很多局部有上下波动。
P-R 曲线直观地显示出模型在样本总体上的 Precision、Recall。在进行比较的时候,若一个模型的 P-R 曲线 被另外一个模型的 P-R 曲线 完全“包住”,则可断言后者的性能优于前者。如上图中 模型A 的性能就优于 模型C ;如果两个模型的 P-R曲线 出现了交叉,如上图汇总的 A 和 B,则难以一般性地断言两者孰优孰劣,我们可以根据曲线下方的面积大小(不容易估算)来进行比较,但更常用的是 “平衡点”(Break-Event Point,简称BEP) 或者是 F1 分数。平衡点(BEP)是P=R时的取值,如果这个值较大,则说明模型的性能较好。同样,F1值越大,我们可以认为该模型的性能较好。
注意:P-R 曲线 的平衡点 和 F1 分数的区别。 F1 分数是通过每对 P-R 算出来的。而 平衡点 是 P-R 曲线中的 P = R 时的值。
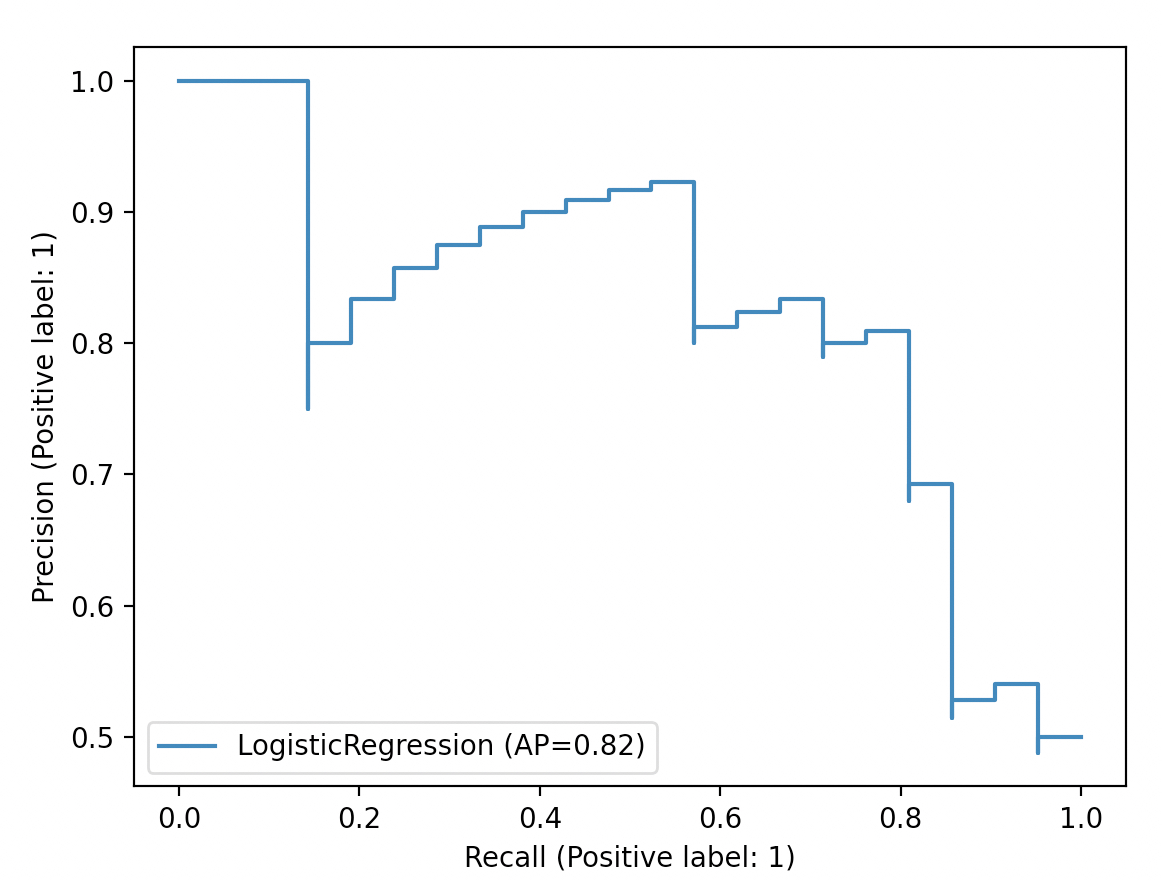
对于 Recall 来说,根据其公式可知,TP + FN 是一个定值(即所有真实正样本的数量),改变阈值并不会使得发生改变。这意味着如果降低阈值,那么 Recall 便会提高或保持不变,因为变得更大(或保持不变)了。因此,如果阈值由大变小,那么便会使得 TP 变大,Recall 便会由小变大。
对于 Precision 来说,根据其公式可知,阈值越小那么 TP + FP 就会越大(因为更多的样本会被预测为正类别),整体上(不是绝对,因为 分子 TP 也会变大,可能导致 Precision 增加)Precision 便会降低;同理,如果阈值越大那么 TP + FP 就会越小,某些情况下预测出的结果可能都是正样本,则 Precision 总体上便会提高。因此,如果阈值由大变小,那么 Precision 整体也会由大变小。
阈值由大变小:P-R 曲线 从左到右。 Recall 随着 阈值由大变小,是单调非减的;但是 Precision 却不一定。
P-R 曲线 的缺点
P-R 曲线会受到正负样本比例的影响。比如当负样本增加 10倍 后,在 racall 不变的情况下,必然召回了更多的负样本,所以 Precision 就会大幅下降,所以 P-R 曲线对正负样本分布比较敏感。对于不同正负样本比例的测试集,P-R 曲线的变化就会非常大。
从 P-R 曲线 中寻找最佳阈值
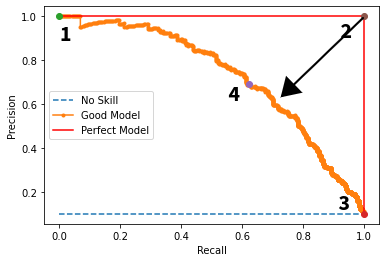
由于我们现在知道一个好的模型的 P-R 曲线接近完美模型点(即点 2);非常直观的是,我们模型的最佳阈值将对应于曲线上最接近点 2 的点。
以下是找到最佳阈值的 2 种方法:
-
从 (1,1) 求出曲线上每个点的欧式距离,对于相应的阈值,用 (recall, precision) 表示。
- 选择距离最小的点和相应的阈值。
-
找到每个点的 F1 分数(召回率、精度),具有最大 F1 分数的点是所需的最佳点。
参考:https://analyticsindiamag.com/complete-guide-to-understanding-precision-and-recall-curves/
7. Area Under the Curve(AUC)
AUC 是一个概念,表示曲线下面的面积。至于什么曲线,那就看你要计算什么曲线。
8. Average Precision(AP)
平均查准率,是对不同召回率点上的查准率进行平均,在 P-R曲线 图上表现为 P-R 曲线下面的面积(AUC)。AP 的值越大,则说明模型的平均查准率越高。
如何计算 P-R 曲线的 AUC 得到 AP?
由于并不知道PR曲线对应的函数不能用积分进行求解,因此只能采用近似的方法来求得曲线与轴所围成的面积。对于 P-R AUC值的计算一般来说有两种方式:矩形规则和梯形规则。
矩形规则
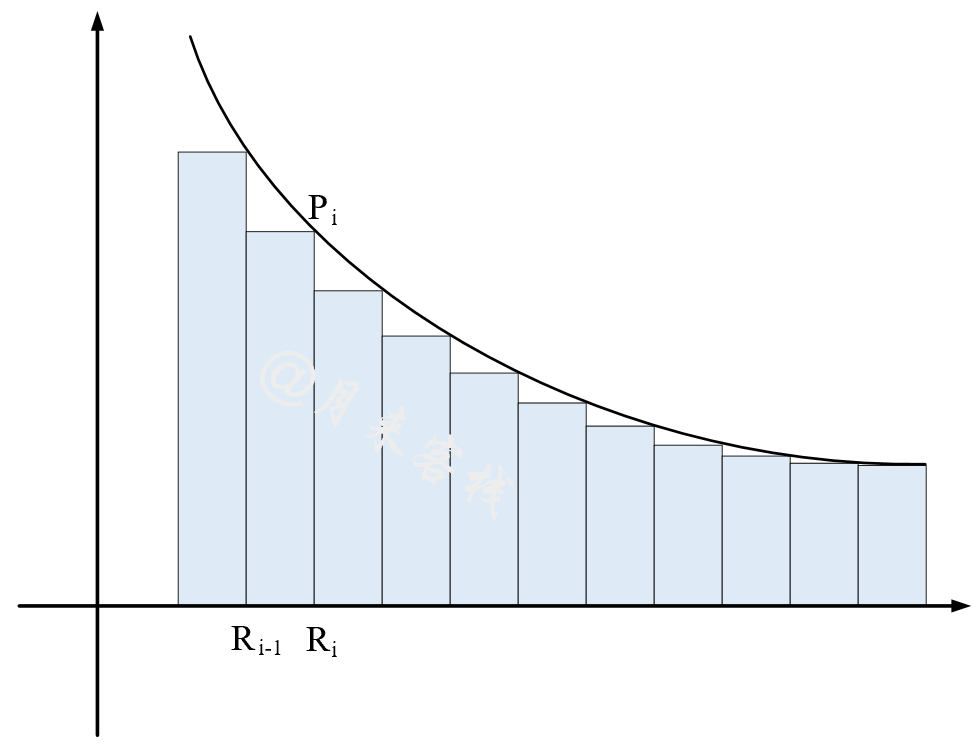
主要思想是将轴上连续两个值之间与曲线围成的区域看成是一个矩形,然后依次累加所有矩形的面积得到PR AUC,如图所示。
计算公式为:
A P = ∑ i n ( R i − R i − 1 ) P i AP = \sum_{i}^{n} (R_i - R_{i-1})P_i AP=∑in(Ri−Ri−1)Pi
其中 R i R_i Ri 和 P i P_i Pi 分别表示第 i 个阈值对应的 racall 和 Precision。
从计算过程可以看出,通过这种方法来计算 AUC 值形式上就相当于是对不同阈值下的 Precision 进行了加权求和(权重是 R i − R i − 1 R_i - R_{i-1} Ri−Ri−1。因此在 scikit-learn 中这一计算结果也称为 Average Precision。
梯形规则
主要思想则是将轴上连续两个值之间与曲线围成的区域看成是一个梯形,然后依次累加所有梯形的面积得到 P-R AUC,如图所示:
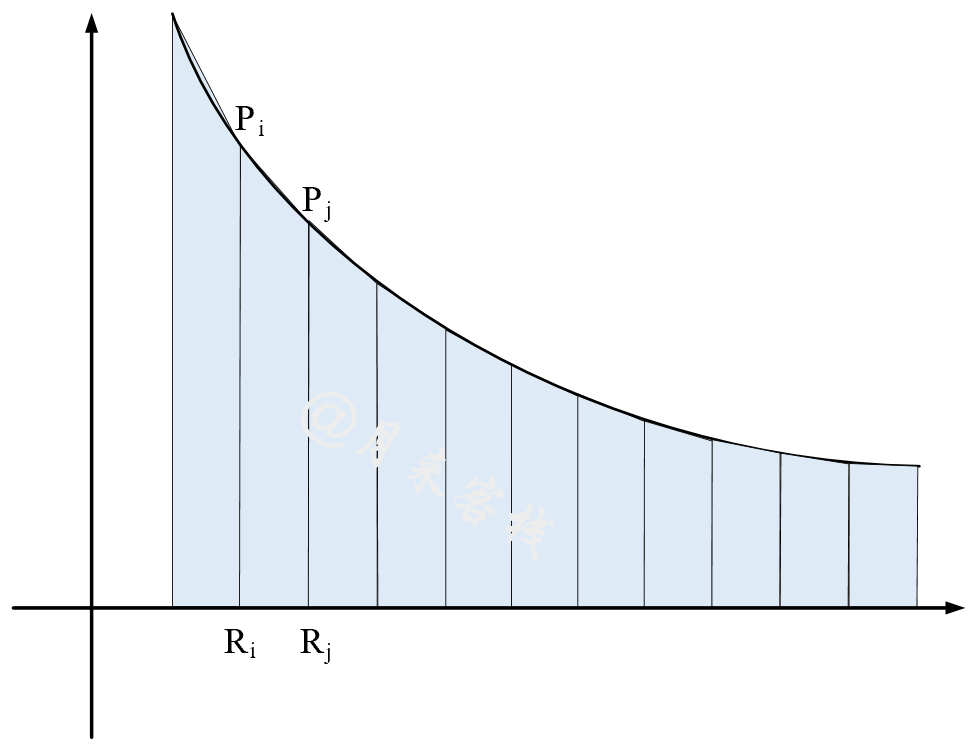
A P = ∑ i , j n 1 2 ( R j − R i ) ( P i + P j ) , i < j AP = \sum_{i,j}^{n} \frac{1}{2} (R_j - R_{i})(P_i + P_j), i<j AP=∑i,jn21(Rj−Ri)(Pi+Pj),i<j
其中 R i , R j R_{i}, R_{j} Ri,Rj 分别为 Recall 轴上两个连续的点, P i , P j P_i, P_j Pi,Pj 为分别为与 R i , R j R_{i}, R_{j} Ri,Rj 对应的Precision。
这里需要注意的是,由于上述两种计算 AUC 的方法采用了不同的策略,因此最终两者计算得到的结果并不相等。
近似计算
在目标检测中的近似计算主要分为三种:11 点插值(VOC 2007), 所有点插值(VOC 2010) 和 COCO。
目标检测中,模型一般会检测多个类别,比如 VOC 数据集是 20 个类别,像 YOLO 模型会输出 20D 的是前景条件下类别概率向量,前景概率,二者相乘会得到 置信度。而通过 IOU(预测框,真实框) 我们来区分 预测的是 TP 还是 FP。假设大于 0.5 , 那就是 TP,否则是 FP。根据置信度从大到小排序,我们可以计算出该类别的 P-R 曲线。
VOC 2007 的 AP 和 mAP 计算:11 点插值

给定一个 IOU=0.5 定值,逐步计算 每个类别的 11 点插值 的AP,最后的 mAP 就是这些类别的 AP 平均。
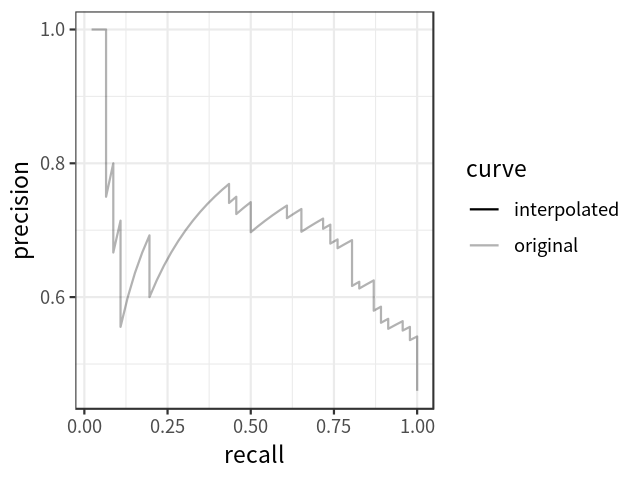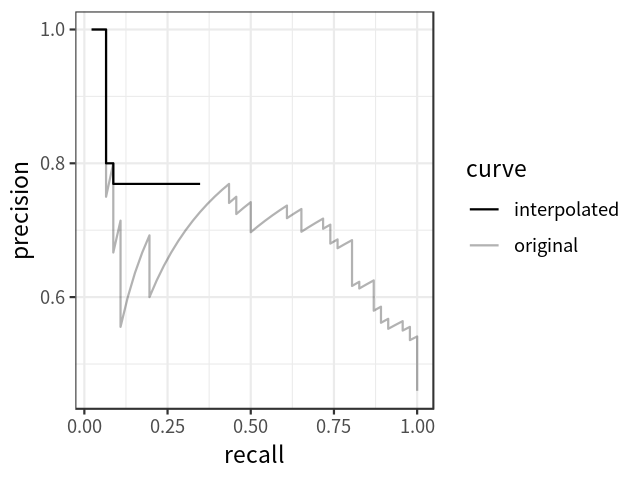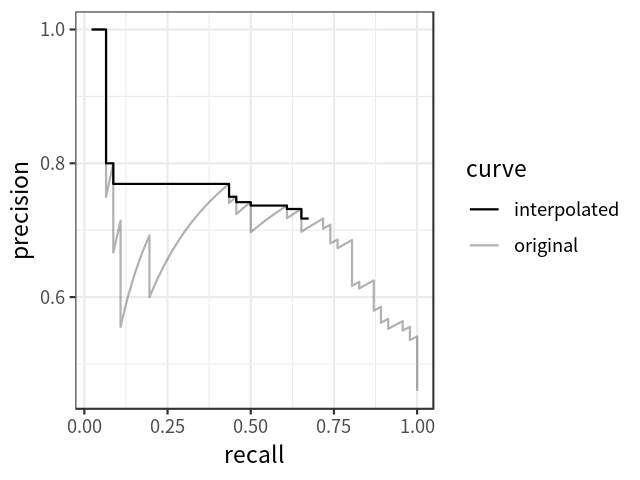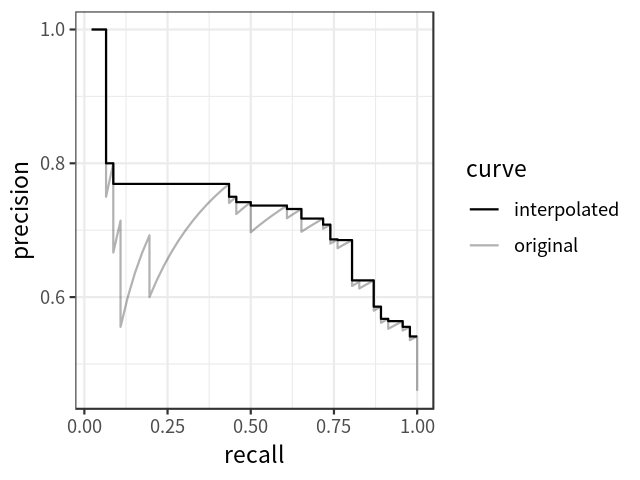
VOC 2010 的 AP 和 mAP 计算: 所有点插值
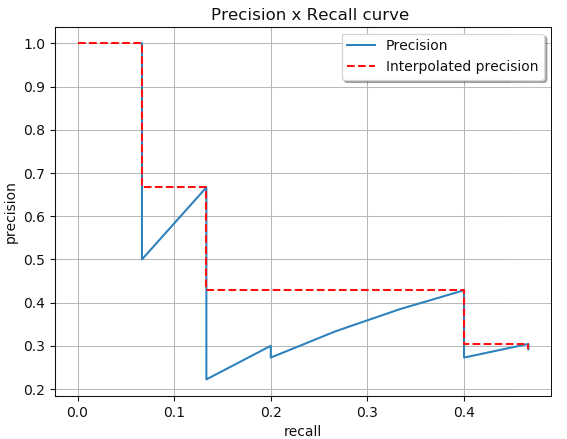
显然,对于 P-R 曲线的每个转折点,都取它右边最大的值。
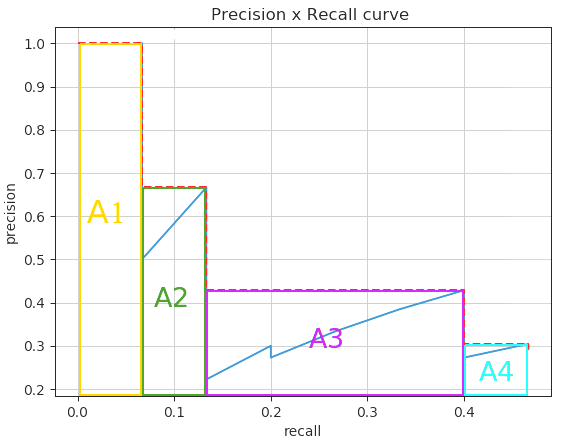
同样,每个类别会计算出一个 AP, 最后的 mAP 就是这些类别的 AP 平均。
COCO AP 和 mAP 的计算
固定 IoUs 下的 AP , 如 IoU=0.5 和 IoU=0.75 分别被写作 AP50 和 AP75。
在 COCO 评估中,IoU threshold 范围从 0.5 到 0.95,步长 0.05 表示为 AP@[ . 5: . 05: . 95]。
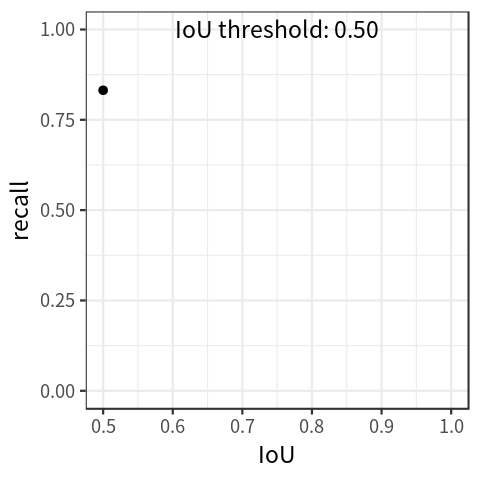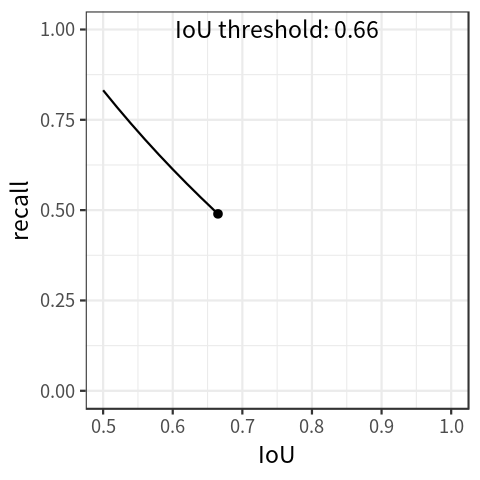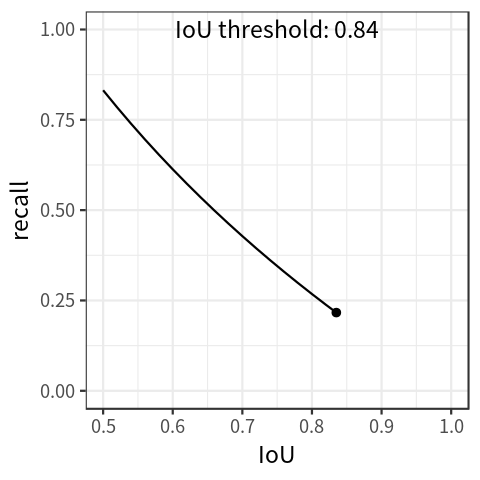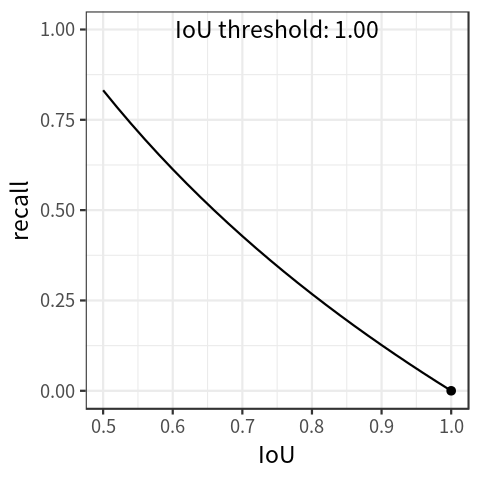
注意:COCO 使用 [0: .01:1] R = 101 recall thresholds 得到 P-R 曲线,其实就是 VOC 2007 的 11点插值的加强版 : 101 点插值。
A P C O C O = 1 101 ( P 0 + P 0.01 + P 0.02 + ⋯ + P 1 ) \mathrm{AP_{COCO}}=\frac{1}{101}\left(P_{0}+P_{0.01}+P_{0.02}+\cdots+P_{1}\right) APCOCO=1011(P0+P0.01+P0.02+⋯+P1)
m A P COCO = m A P 0.50 + m A P 0.55 + . . . + m A P 0.95 10 mAP_{\text{COCO}} = \frac{mAP_{0.50}\ +\ mAP_{0.55}\ +\ ...\ +\ mAP_{0.95}}{10} mAPCOCO=10mAP0.50 + mAP0.55 + ... + mAP0.95
COCO mAP 的计算与 VOC 2007 相比,有两点区别:
- 11点插值变成了 101 点插值
- 不再是固定的一个 IOU, 而是可以选择一个范围,再求平均。
注意: mAP值计算在NMS之后进行的。
AP 衡量的是学出来的模型在某个类别上的好坏,mAP 衡量的是学出的模型在所有类别上的好坏。
参考文献:
- https://learnopencv.com/mean-average-precision-map-object-detection-model-evaluation-metric/
- https://cocodataset.org/#detection-eval
- https://pyimagesearch.com/2022/05/02/mean-average-precision-map-using-the-coco-evaluator/
- https://kharshit.github.io/blog/2019/09/20/evaluation-metrics-for-object-detection-and-segmentation
- https://blog.zenggyu.com/en/post/2018-12-16/an-introduction-to-evaluation-metrics-for-object-detection/
- https://github.com/rafaelpadilla/Object-Detection-Metrics
- https://www.ylkz.life/machinelearning/mlwm/p10975749/
- https://scikit-learn.org/stable/auto_examples/model_selection/plot_precision_recall.html
- https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics
- https://lonepatient.top/2018/03/03/evaluate-your-machine-learning-algorithm