文章目录
- 1. 根据训练照片训练数据模型
- 2. 根据训练的数据文件,进行人脸识别
1. 根据训练照片训练数据模型
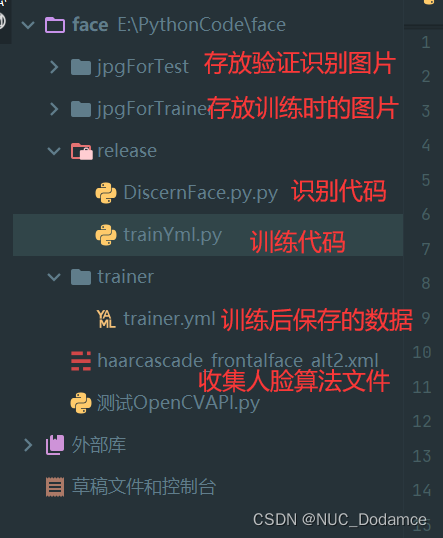
训练流程:
- 读取文件夹下的所有文件,使用PIL 库中的Image方法打开图片,并将其转化为灰度图片。
- 加载人脸数据分类器,这里直接使用OpenCV库自带的(cv.CascadeClassifier(…))
- 使用numpy.array方法,让照片向量化。使用分类器detectMultiScale方法,提取图片脸部特征值。
- 将一个人的信息和脸部特征值写入到文件中,达到训练的目的
照片命名格式:学号-1/学号-2+.jpg
import cv2 as cv
import os
from PIL import Image
import numpy as np
# 根据jpgForTrainer文件夹中的图片进行训练,随后的训练数据保存到trainer/trainer.yml
def getImageAndLabel(url):
# 储存人脸数据
faces_msg = []
name = []
# 保存图片信息
imagePaths = [os.path.join(url, f) for f in os.listdir(url)]
# 加载分类器
detector = cv.CascadeClassifier('../haarcascade_frontalface_alt2.xml')
# 遍历图片
for pict in imagePaths:
fileImg = Image.open(pict).convert('L') # 打开灰度图像
# 图片向量化
imgNumpy = np.array(fileImg, 'uint8')
face = detector.detectMultiScale(imgNumpy, 1.1, 5) # 提取图片脸部特征值
# 提取图片的学号
ids = int(os.path.split(pict)[1].split('-')[0])
flag = False
for x, y, w, h in face:
# 保存脸部数据
flag = True
name.append(ids)
faces_msg.append(imgNumpy[y:y + h, x:x + w]) # 保存脸部数据
if flag:
print(f'DEBUG:捕捉到学号为{ids}的人脸,')
print('DEBUG')
print('id', name)
print('face', faces_msg)
return faces_msg, name
if __name__ == '__main__':
path = "../jpgForTrainer/"
# 获取人脸特征和姓名
faces, id = getImageAndLabel(path)
# 加载识别器
recognize = cv.face.LBPHFaceRecognizer_create()
recognize.train(faces, np.array(id))
# 保存文件
recognize.write('../trainer/trainer.yml')
2. 根据训练的数据文件,进行人脸识别
步骤:
- 将要识别的图片使用os模块,读取进来
- 使用cv2库(检测cv)cv.imread函数打开图片,调用人脸识别函数(自定义)进行识别,函数返回从训练数据里面查找的复合条件的学号,根据图片名称来判断识别是否准确
- 人脸识别函数中,使用data = cv.face.LBPHFaceRecognizer_create(),data.read(‘…/trainer/trainer.yml’)来加载训练好的数据。
- 使用data.predict函数来预测准确性,准确性在25以内的就可以认为识别成功,将学号写到图片上调用cv.imshow函数进行输出。可以使用cv.resize函数对图片进行缩放后再将识别信息写到图片上。
- 最后统计识别学号和照片名称学号对应的比例来计算识别成功率即可。
# 测试人脸识别
import cv2 as cv
import os
# 加载训练数据文件
data = cv.face.LBPHFaceRecognizer_create()
data.read('../trainer/trainer.yml')
# 错误数目
fault = 0
path = '../jpgForTest'
# 根据jpgForTest里面的文件来进行识别测试
# 识别模块
def discern(_img):
ret = []
gray = cv.cvtColor(_img, cv.COLOR_BGR2GRAY)
# 加载分类器
detector = cv.CascadeClassifier('../haarcascade_frontalface_alt2.xml')
face_data = detector.detectMultiScale(gray, 1.1, 5)
resize = _img
flag = False
for x, y, w, h in face_data:
flag = True
cv.rectangle(_img, (x, y,), (x + w, y + h), color=(0, 0, 255), thickness=1)
# 人脸识别
s_id, confidence = data.predict(gray[y:y + h, x:x + w])
resize = cv.resize(_img, dsize=(700, 600))
if confidence > 25:
cv.putText(resize, 'UnKnow', (5, 50), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
print('标签id:', s_id, '置信评分:', confidence)
cv.putText(resize, str(s_id), (5, 50), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
ret.append(s_id)
if not flag:
# 没检测到人脸
resize = cv.resize(_img, dsize=(700, 600))
cv.putText(resize, 'Not Find Face', (5, 50), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
# 压缩图片输出
cv.imshow('result', resize)
while True:
get = cv.waitKey(1000)
if ord(' ') == get or get == -1:
break
return ret
# # 获取训练人的学号,以此来判断陌生人脸是否识别成功
# def getMessage():
# target = os.listdir('../jpgForTrainer')
# msg = []
# for Str in target:
# tmp = Str.split('-')[0]
# if tmp not in msg:
# msg.append(tmp)
# return msg
if __name__ == '__main__':
files = os.listdir(path) # 得到文件夹下的所有文件名称
size = len(files)
for file in files: # 遍历文件夹
stu_id = file.split('.')[0]
size += 1
print(path + "/" + file + "正在识别")
img = cv.imread(path + '/' + file)
ret = discern(img)
if len(ret) == 0:
fault += 1
print(f'识别错误应该学号为{stu_id},识别学号为{ret}')
else:
for item in ret:
if str(item) not in str(stu_id):
fault += 1
print(f'识别错误应该学号为{stu_id},识别学号为{ret}')
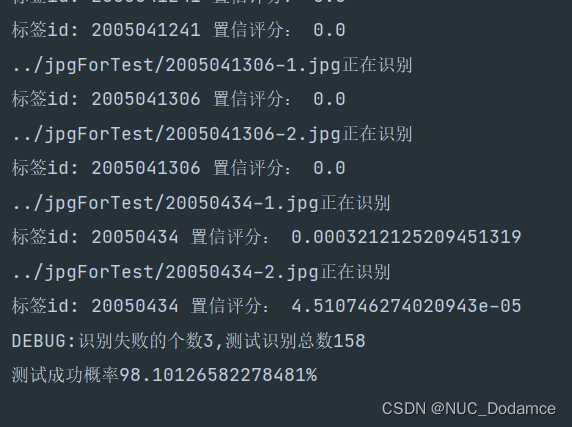
print(f'DEBUG:识别失败的个数{fault},测试识别总数{size}')
print(f'测试成功概率{((size - fault) / size) * 100}%')
cv.destroyAllWindows()
需要注意的是:这个实验使用的haarcascade_frontalface_alt2.xml文件,是OpenCV自带的人脸图像提取算法,需根据实际路径选取
代码中的置信评分越小,越可靠。
参考资料:
一天搞定人脸识别项目!
运行结果:

![[附源码]java毕业设计吾家具线上销售管理系统](https://img-blog.csdnimg.cn/7d956faa08004f5e92a4632353b1cfce.png)
![[附源码]java毕业设计乡村振兴惠农推介系统](https://img-blog.csdnimg.cn/d098fb745292450f9a8854ab844c607f.png)