6. 一阶段
在一阶段的调用流程是
6.1 DataSource
Seata最重要的一个功能就是对 DataSource 进行了代理,在用户执行插入 sql 时会在插入之间根据 sql 构建一个前置镜像出来,如果出现异常了,就可以通过 undolog 日志里面的镜像语句进行回滚;
seata中代理对数据进行代理的方式以及调用联调大致如下,seata对 数据源、连接对象、预编译对象 都进行了代理,最后通过 ExecuteTemplate 对象来执行解析 sql创建镜像等操作
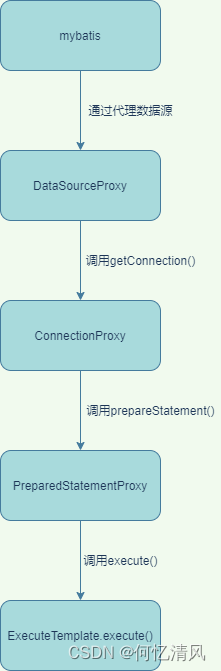
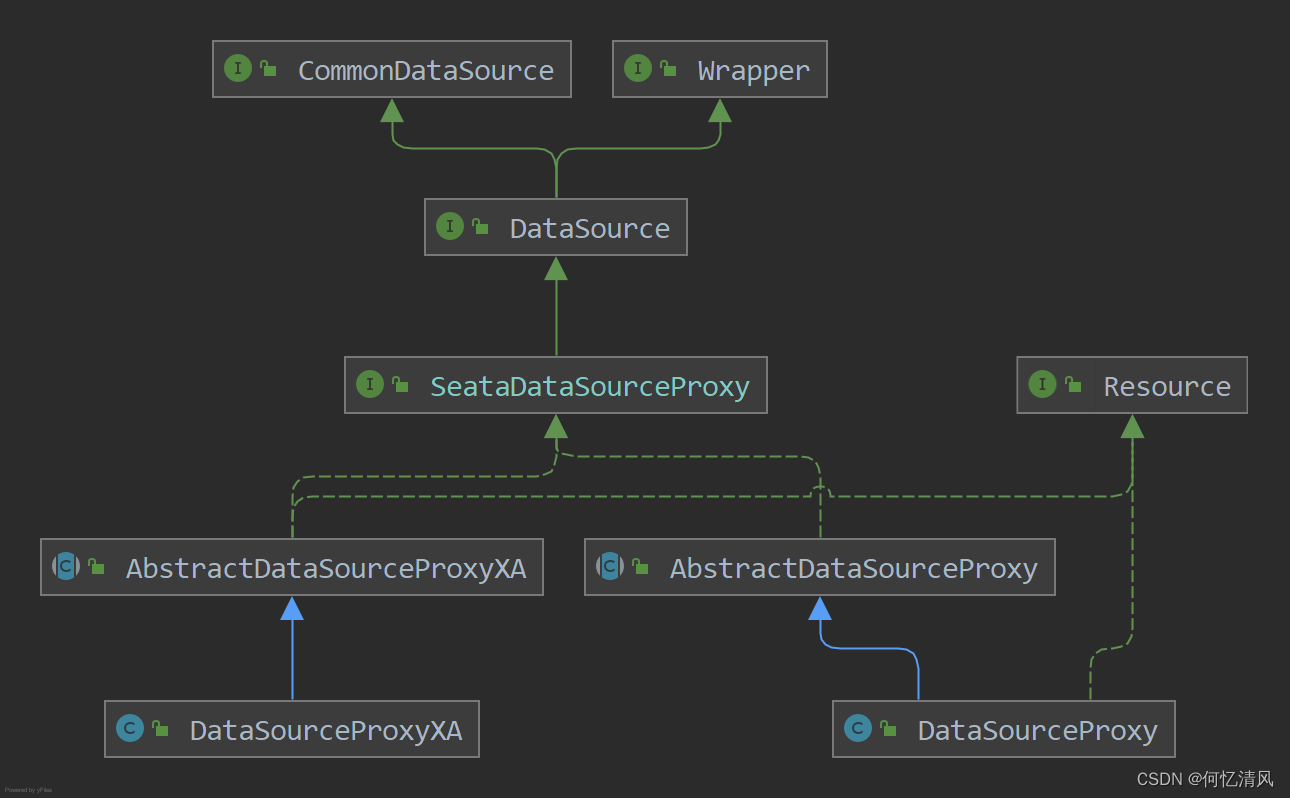
6.2 SeataAutoDataSourceProxyCreator
步骤跟上面扫描 @GloableTransactional 一样对 DataSource 数据源进行代理,代理对象为 SeataDataSourceProxy 类型,根据代理模式创建不同的实现类:
- DataSourceProxy:AT模式
- DataSourceProxyXA:XA模式
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
// 只对 DataSource 进行代理
if (!(bean instanceof DataSource)) {
return bean;
}
if (!(bean instanceof SeataDataSourceProxy)) {
//调用父类对 bean 进行代理
Object enhancer = super.wrapIfNecessary(bean, beanName, cacheKey);
//要么已经被代理了,要么是被排除了
if (bean == enhancer) {
return bean;
}
//否者构建代理对象
DataSource origin = (DataSource) bean;
SeataDataSourceProxy proxy = buildProxy(origin, dataSourceProxyMode);
DataSourceProxyHolder.put(origin, proxy);
return enhancer;
}
SeataDataSourceProxy proxy = (SeataDataSourceProxy) bean;
DataSource origin = proxy.getTargetDataSource();
Object originEnhancer = super.wrapIfNecessary(origin, beanName, cacheKey);
if (origin == originEnhancer) {
return origin;
}
DataSourceProxyHolder.put(origin, proxy);
return originEnhancer;
}
6.3 SeataAutoDataSourceProxyAdvice
数据源通知类,通知类中没有做什么特别的事,就是判断了当前执行的方法在 DataSource 中是否也具有相同的方法,如果存在相同的方法,直接调用 代理类 就可以了
public Object invoke(MethodInvocation invocation) throws Throwable {
// check whether current context is expected
if (!inExpectedContext()) {
return invocation.proceed();
}
//获取需要执行的方法
Method method = invocation.getMethod();
String name = method.getName();
Class<?>[] parameterTypes = method.getParameterTypes();
//获取到DataSource中是否具有当前方法,如果抛出异常那么直接执行本体方法
Method declared;
try {
declared = DataSource.class.getDeclaredMethod(name, parameterTypes);
} catch (NoSuchMethodException e) {
return invocation.proceed();
}
//调用代理对象的方法
DataSource origin = (DataSource) invocation.getThis();
SeataDataSourceProxy proxy = DataSourceProxyHolder.get(origin);
Object[] args = invocation.getArguments();
return declared.invoke(proxy, args);
}
6.4 SeataDataSourceProxy
public interface SeataDataSourceProxy extends DataSource {
/**
* 获取到代理的源对象
*/
DataSource getTargetDataSource();
/**
* 获取当前分支事务采用的模式
*/
BranchType getBranchType();
}
6.5 DataSourceProxy
AT模式的数据源代理对象,通过 DataSource 的使用方式,一般是,先通过 getConnection() 获取到一个数据库的连接,然后通过 Connection 对象再创建一个 Statement 的对象来操作 sql 语句,所以这里我们可以先看 getConnection() 方法是如何实现的
getConnection()
直接创建了一个 ConnectionProxy 连接代理对象
public ConnectionProxy getConnection() throws SQLException {
Connection targetConnection = targetDataSource.getConnection();
return new ConnectionProxy(this, targetConnection);
}
6.6 ConnectionProxy

createStatement()
又对 Statement 对象创建了一个代理对象
public Statement createStatement() throws SQLException {
Statement targetStatement = getTargetConnection().createStatement();
return new StatementProxy(this, targetStatement);
}
commit()
1)写隔离实现机制
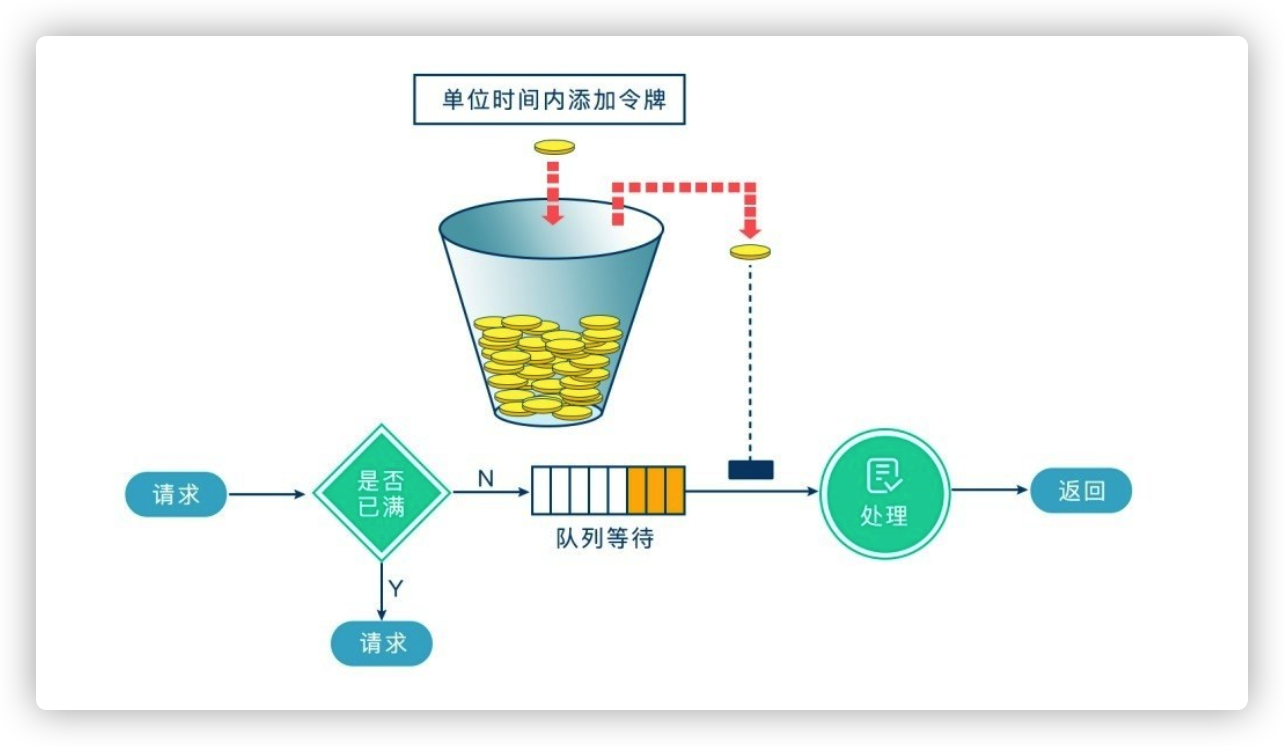
提交事务时,会先向 TC 注册一个全局锁,表名+行记录 构成的锁;Seata 中对于写隔离的实现就是采用全局锁实现,写的过程:
- 一阶段本地事务提交前,申请全局锁,拿不到全局锁不能提交
- 超出了限制将放弃拿锁,回滚本地事务,释放本地锁
例如:t1和t2 两个事务,t1将 1000 修改为 900,t1先拿到全局锁,提交本地事务释放了本地锁,然后t2拿到本地锁将900修改为800,但是t1全局锁还没有释放,t2拿不到全局锁就根据策略进行重试,这时t1收到了 TC 的回滚请求,t1开始根据undolog进行回滚,发现t2还持有本地锁,就会一直进行重试回滚,t2持有本地锁重试次数超过了限制,放弃提交开始回滚数据释放问题锁,t1拿到本地锁开始执行回滚任务;因为整个过程 全局锁 在 t1结束前一直是被 t1 持有,所以不会发生脏写的问题。
2)读隔离实现机制
在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交(Read Uncommitted) 。
如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理。
为什么要默认采用 读未提交?
猜想:如果使用默认数据库的 可重复读,会出现的问题就是 t1开启事务修改1000 - 100 = 900但是本地事务还没有提交,t2查询的数据出来还是1000 - 100 = 900,t1拿到锁开始提交事务并且释放本地锁以及全局锁,而t2也开始提交事务,这时候 t1和t2 都将数据改成了900,就导致了数据异常
public void commit() throws SQLException {
try {
//采用重试机制,反复的获取锁
lockRetryPolicy.execute(() -> {
//执行提交任务
doCommit();
return null;
});
} catch (SQLException e) {
//判断是否是自动提交 并且并没有被改变过
if (targetConnection != null && !getAutoCommit() && !getContext().isAutoCommitChanged()) {
rollback();
}
throw e;
} catch (Exception e) {
throw new SQLException(e);
}
}
doCommit()
private void doCommit() throws SQLException {
//查看是否存在全局事务的配置,如果存在全局事务需要注册当前分支
if (context.inGlobalTransaction()) {
//如果分支注册成功了,直接提交事务
processGlobalTransactionCommit();
} else if (context.isGlobalLockRequire()) {
//如果不存在 XID 先去判断是否存在全局锁
processLocalCommitWithGlobalLocks();
} else {
//提交事务
targetConnection.commit();
}
}
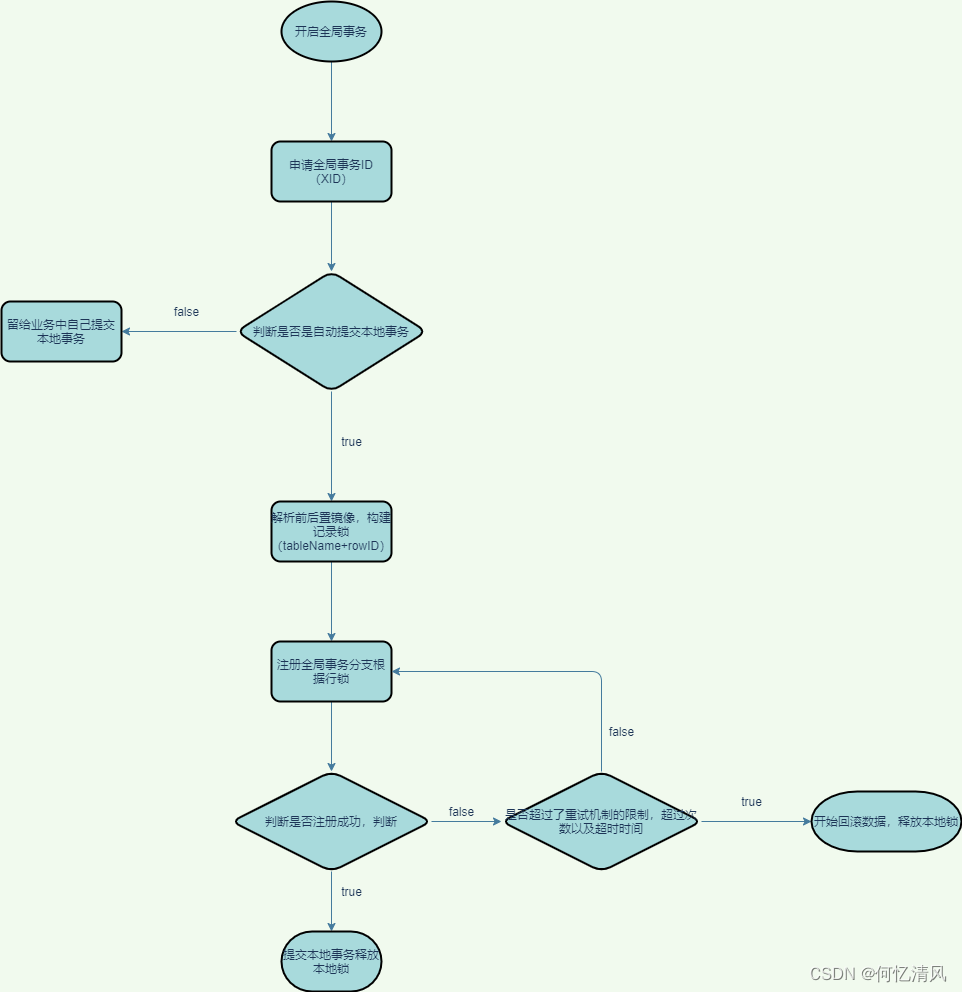
processGlobalTransactionCommit()
private void processGlobalTransactionCommit() throws SQLException {
try {
//向 TC 设置一个由 表名:id 组成的全局锁,返回一个 branchId
register();
} catch (TransactionException e) {
//如果锁已经存在,那么构建一个锁冲突的异常 LockConflictException
recognizeLockKeyConflictException(e, context.buildLockKeys());
}
try {
//刷新undolog日志,提交事务
UndoLogManagerFactory.getUndoLogManager(this.getDbType()).flushUndoLogs(this);
targetConnection.commit();
} catch (Throwable ex) {
LOGGER.error("process connectionProxy commit error: {}", ex.getMessage(), ex);
//上报异常事务状态
report(false);
throw new SQLException(ex);
}
if (IS_REPORT_SUCCESS_ENABLE) {
report(true);
}
context.reset();
}
6.7 PreparedStatementProxy
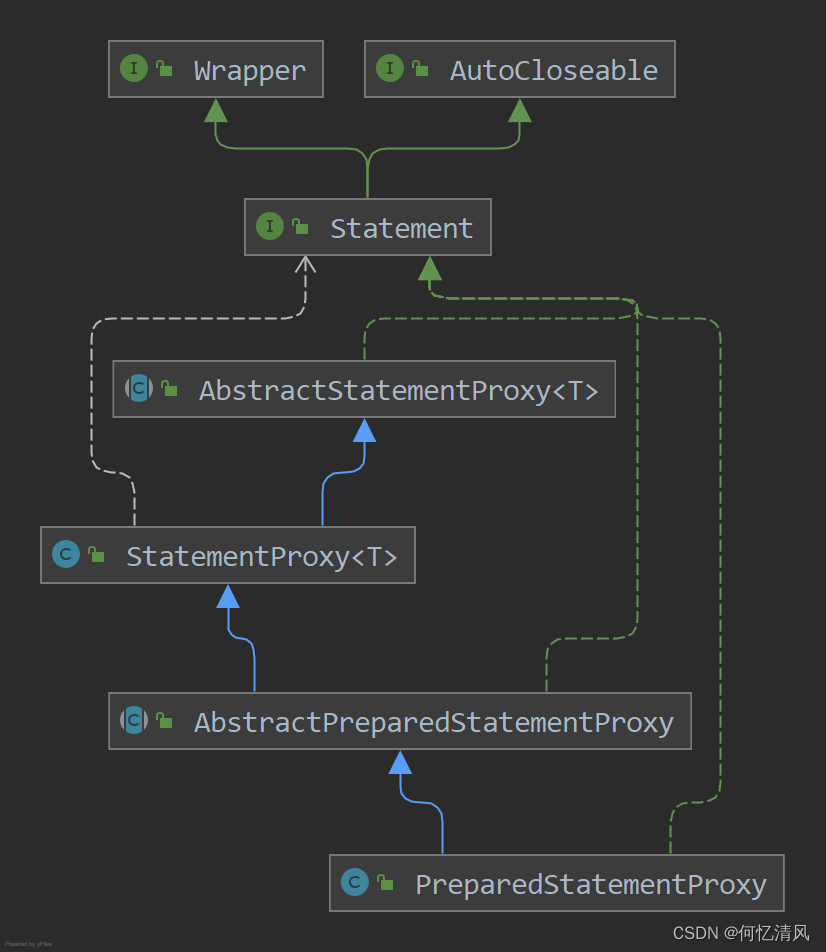
PreparedStatementProxy 覆写的 execute() 方法并没有做什么事,直接通过 ExecuteTemplate 来执行的
@Override
public boolean execute() throws SQLException {
//执行完之后,直接调用回调函数执行源sql
return ExecuteTemplate.execute(this, (statement, args) -> statement.execute());
}
6.8 ExecuteTemplate
- SQLRecognizerFactory : sql识别工厂,引的哪个包就使用哪个识别器,这里使用的是 druid的识别器
- DruidSQLRecognizerFactoryImpl
- AntlrMySQLRecognizerFactory
- SQLRecognizer:sql识别器将对应的sql语句解析成不同的类型,下面是实现类,数据库不同实现的类型也不同

public static <T, S extends Statement> T execute(List<SQLRecognizer> sqlRecognizers,
StatementProxy<S> statementProxy,
StatementCallback<T, S> statementCallback,
Object... args) throws SQLException {
//对其进行全局锁的检查
if (!RootContext.requireGlobalLock() && BranchType.AT != RootContext.getBranchType()) {
//如果没有全局锁的标识并且也不是AT模式,直接执行源sql
return statementCallback.execute(statementProxy.getTargetStatement(), args);
}
//创建sql识别器
String dbType = statementProxy.getConnectionProxy().getDbType();
if (CollectionUtils.isEmpty(sqlRecognizers)) {
/**
* 根据sql识别器工厂创建对应的识别器来创建 SQLRecognizer 对象,目前提供了两个实现类
* DruidSQLRecognizerFactoryImpl 和 AntlrMySQLRecognizerFactory 两个子类进行识别,两个子类通过两个包进行引用
*/
sqlRecognizers = SQLVisitorFactory.get(
statementProxy.getTargetSQL(),
dbType);
}
Executor<T> executor;
/**
* 根据对应的sql类型创建出对应的执行器
* 默认:PlainExecutor
* 插入:InsertExecutor (会根据数据库的类型进行创建,这里只是指定接口名称)
* 修改:UpdateExecutor
* 删除:DeleteExecutor
* select for update:SelectForUpdateExecutor
* insert_on_duplicate_update:MySQLInsertOrUpdateExecutor
* 多个sql执行:MultiExecutor
*/
if (CollectionUtils.isEmpty(sqlRecognizers)) {
executor = new PlainExecutor<>(statementProxy, statementCallback);
} else {
if (sqlRecognizers.size() == 1) {
SQLRecognizer sqlRecognizer = sqlRecognizers.get(0);
switch (sqlRecognizer.getSQLType()) {
case INSERT:
executor = EnhancedServiceLoader.load(InsertExecutor.class, dbType,
new Class[]{StatementProxy.class, StatementCallback.class, SQLRecognizer.class},
new Object[]{statementProxy, statementCallback, sqlRecognizer});
break;
case UPDATE:
executor = new UpdateExecutor<>(statementProxy, statementCallback, sqlRecognizer);
break;
case DELETE:
executor = new DeleteExecutor<>(statementProxy, statementCallback, sqlRecognizer);
break;
case SELECT_FOR_UPDATE:
executor = new SelectForUpdateExecutor<>(statementProxy, statementCallback, sqlRecognizer);
break;
case INSERT_ON_DUPLICATE_UPDATE:
switch (dbType) {
case JdbcConstants.MYSQL:
case JdbcConstants.MARIADB:
executor =
new MySQLInsertOrUpdateExecutor(statementProxy, statementCallback, sqlRecognizer);
break;
default:
throw new NotSupportYetException(dbType + " not support to INSERT_ON_DUPLICATE_UPDATE");
}
break;
default:
executor = new PlainExecutor<>(statementProxy, statementCallback);
break;
}
} else {
executor = new MultiExecutor<>(statementProxy, statementCallback, sqlRecognizers);
}
}
T rs;
try {
/**
* 执行时默认时执行 PlainExecutor中的方法
* 其他类型执行 BaseTransactionalExecutor 中的方法
*/
rs = executor.execute(args);
} catch (Throwable ex) {
if (!(ex instanceof SQLException)) {
// Turn other exception into SQLException
ex = new SQLException(ex);
}
throw (SQLException) ex;
}
return rs;
}
6.9 Executor
根据sql识别器,识别出sql的类型是 insert、update还是delete等类型,根据不同的类型创建不同的sql执行器
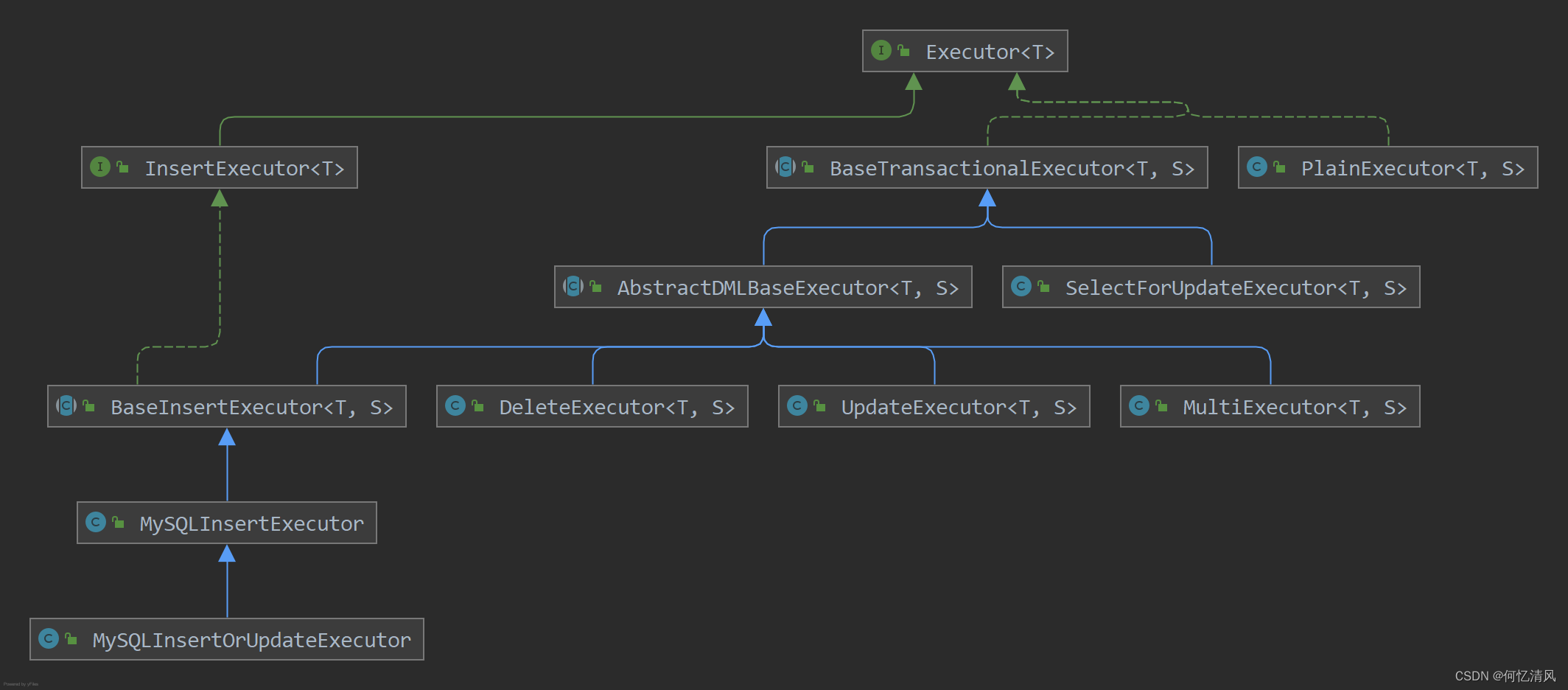
ExecuteTemplate 中对sql进行解析之后创建出不同类型的 Eexcutor 实现类,以 Insert sql为例子,解析出的类型是 MysqlInsertOrUpdateExecutor 该类型并没有实现 execute(args) 方法,往上找调用的方法在 BaseTrasactionalExecutor 类中
execute()
从上下文中获取了 XID 进行绑定
public T execute(Object... args) throws Throwable {
//获取到 XID
String xid = RootContext.getXID();
if (xid != null) {
//如果XID不为空的话绑定到当前获取的连接代理对象中,证明当前连接已经绑定了全局事务,如果后续连接来绑定新全局事务抛出异常
statementProxy.getConnectionProxy().bind(xid);
}
//判断是否需要全局锁,这里根据方法是否打了 @GlobalLock注解,GlobalTransactionalInterceptor中会根据 @GlobalLock 和 @GlobalTransactional注解进行不同的处理,如果是事务这里应该是false
statementProxy.getConnectionProxy().setGlobalLockRequire(RootContext.requireGlobalLock());
//AbstractDMLBaseExecutor
return doExecute(args);
}
doExecute()
public T doExecute(Object... args) throws Throwable {
AbstractConnectionProxy connectionProxy = statementProxy.getConnectionProxy();
//根据是否自动提交事务来进行区分执行的代码,如果是自动提交,那么需要把自动提交关闭,改成手动提交
if (connectionProxy.getAutoCommit()) {
return executeAutoCommitTrue(args);
} else {
//不需要提交留给二阶段通知提交时开始提交
return executeAutoCommitFalse(args);
}
}
executeAutoCommitFalse()
先根据sql语句构建出前置镜像 TableRecords ,然后执行sql语句,根据前置镜像的主键id构建出执行sql之后的查询sql语句,根据修改之后记录构建后置镜像
public class TableRecords implements java.io.Serializable {
private static final long serialVersionUID = 4441667803166771721L;
//表的元数据信息
private transient TableMeta tableMeta;
//表名称
private String tableName;
//每一行数据对应的记录,里面又包括了每个字段的key和value
private List<Row> rows = new ArrayList<Row>();
}
在后续提交时会根据构建的 tableName:{主键值1},{主键值2}…{主键值N} 记录锁对行加上锁,防止其他事务进行修改
protected T executeAutoCommitFalse(Object[] args) throws Exception {
if (!JdbcConstants.MYSQL.equalsIgnoreCase(getDbType()) && isMultiPk()) {
throw new NotSupportYetException("multi pk only support mysql!");
}
//构建前置镜像
TableRecords beforeImage = beforeImage();
//执行sql语句
T result = statementCallback.execute(statementProxy.getTargetStatement(), args);
//获取到影响的行数
int updateCount = statementProxy.getUpdateCount();
if (updateCount > 0) {
//构建后置镜像根据前置镜像的id查询出执行之后的sql记录
TableRecords afterImage = afterImage(beforeImage);
//构建undolog日志:构建锁,锁的结构是 表名:主键值1....{值键值n},并且将锁添加到 lockKeysBuffer 在执行提交事务时会根据前面的锁对表数据上锁
prepareUndoLog(beforeImage, afterImage);
}
return result;
}
executeAutoCommitTrue()
这里需要注意一点的是 LockRetryPolicy 对象,这里用到的是 AbstractDMLBaseExecutor.LockRetryPolicy
- AbstractDMLBaseExecutor.LockRetryPolicy:继承至 ConnectionProxy.LockRetryPolicy,覆写了 onException(),抛出了异常会进行回滚
- ConnectionProxy.LockRetryPolicy :onException() 方法什么事都没有做
protected T executeAutoCommitTrue(Object[] args) throws Throwable {
ConnectionProxy connectionProxy = statementProxy.getConnectionProxy();
try {
//改变是否自动提交
connectionProxy.changeAutoCommit();
//锁重试的机制,如果一直拿不到锁就执行回滚的任务
return new LockRetryPolicy(connectionProxy).execute(() -> {
//构建前后镜像undolog日志
T result = executeAutoCommitFalse(args);
//执行事务的提交,看上面 ConnectionProxy.commit()
connectionProxy.commit();
return result;
});
} catch (Exception e) {
// when exception occur in finally,this exception will lost, so just print it here
LOGGER.error("execute executeAutoCommitTrue error:{}", e.getMessage(), e);
//根据配置中 在锁冲突时的重试回滚机制,默认是true
if (!LockRetryPolicy.isLockRetryPolicyBranchRollbackOnConflict()) {
connectionProxy.getTargetConnection().rollback();
}
throw e;
} finally {
//清除事务相关的属性
connectionProxy.getContext().reset();
//自动提交打开
connectionProxy.setAutoCommit(true);
}
}
7. 网络请求
http://t.csdn.cn/jZSs2
8. 二阶段
8.1 分支提交
在二阶段 TC 向 TM 发起分支提交的请求时,通过 BranchCommitRequest 构建请求体,前面在网络请求里面提到了 seata 中是如何对请求体进行处理的,下面代码是 处理器 调用到 AbstractRMHandler 的代码;对应的处理器是 RmBranchCommitProcessor
public AbstractResultMessage onRequest(AbstractMessage request, RpcContext context) {
if (!(request instanceof AbstractTransactionRequestToRM)) {
throw new IllegalArgumentException();
}
//设置当前类为handler处理器
AbstractTransactionRequestToRM transactionRequest = (AbstractTransactionRequestToRM)request;
transactionRequest.setRMInboundMessageHandler(this);
//这里通过调用,会调用到 DefaultRMHandler.handle(BranchCommitRequest) 的方法中,然后再通过对应的模式来获取处理器执行
return transactionRequest.handle(context);
}
AbstractCallback 一个抽象的回调函数,实现了自定义的 Callback:
- onSuccess:成功之后回调
- onTransactionException:出现事务异常的回调
- onException:出现执行异常的回调
public BranchCommitResponse handle(BranchCommitRequest request) {
//处理分支提交的请求
BranchCommitResponse response = new BranchCommitResponse();
//自定义的回调抽象类 AbstractCallback,其中实现了异常捕获的方法
exceptionHandleTemplate(new AbstractCallback<BranchCommitRequest, BranchCommitResponse>() {
@Override
public void execute(BranchCommitRequest request, BranchCommitResponse response)
throws TransactionException {
//执行分支提交
doBranchCommit(request, response);
}
}, request, response);
return response;
}
执行分支提交的代码比较简单,获取到对应模式的资源管理器,然后调用对应的方法,默认是AT模式,这里就获取的是 DataSourceManager 类
protected void doBranchCommit(BranchCommitRequest request, BranchCommitResponse response)
throws TransactionException {
//获取到对应的RM管理器,AT模式的执行器是 io.seata.rm.datasource.DataSourceManager.branchCommit() 开启一个异步的worker线程
BranchStatus status = getResourceManager().branchCommit(request.getBranchType(), xid, branchId, resourceId,
applicationData);
.........
}
可以看到下面源码中 DataSourceManager.brancheCommit() 方法就调用了一个异步工作线程,执行分支提交 ,里面将任务添加到一个队列中等待执行,执行的任务就是删除对应的的 undolog 逻辑比较简单,就不贴详细的源码了
public BranchStatus branchCommit(BranchType branchType, String xid, long branchId, String resourceId,
String applicationData) throws TransactionException {
return asyncWorker.branchCommit(xid, branchId, resourceId);
}
8.2 分支回滚
对应处理器 RmBranchRollbackProcessor,前面的处理逻辑都一样,之后调用的分支回滚方法不一样,上面分支提交是 branchCommit(),而这里是调用 branchRollback()
public BranchStatus branchRollback(BranchType branchType, String xid, long branchId, String resourceId,
String applicationData) throws TransactionException {
//根据资源id,获取到对应的数据源代理
DataSourceProxy dataSourceProxy = get(resourceId);
if (dataSourceProxy == null) {
throw new ShouldNeverHappenException(String.format("resource: %s not found",resourceId));
}
try {
//根据db类型获取到undolog的管理器,这里的undo方法,调用的 io.seata.rm.datasource.undo.AbstractUndoLogManager.undo
UndoLogManagerFactory.getUndoLogManager(dataSourceProxy.getDbType()).undo(dataSourceProxy, xid, branchId);
} catch (TransactionException te) {
//对应对应的异常码,设置对应的分支回滚状态
new Object[]{branchType, xid, branchId, resourceId, applicationData, te.getMessage()});
if (te.getCode() == TransactionExceptionCode.BranchRollbackFailed_Unretriable) {
return BranchStatus.PhaseTwo_RollbackFailed_Unretryable;
} else {
return BranchStatus.PhaseTwo_RollbackFailed_Retryable;
}
}
return BranchStatus.PhaseTwo_Rollbacked;
}
io.seata.rm.datasource.undo.AbstractUndoLogManager#undo:
public void undo(DataSourceProxy dataSourceProxy, String xid, long branchId) throws TransactionException {
Connection conn = null;
ResultSet rs = null;
PreparedStatement selectPST = null;
boolean originalAutoCommit = true;
for (; ; ) {
try {
//获取到真实的连接对象
conn = dataSourceProxy.getPlainConnection();
// The entire undo process should run in a local transaction.
if (originalAutoCommit = conn.getAutoCommit()) {
//修改自动提交为手动提交
conn.setAutoCommit(false);
}
// 查询undo log日志出来
selectPST = conn.prepareStatement(SELECT_UNDO_LOG_SQL);
//设置分支id
selectPST.setLong(1, branchId);
//xid
selectPST.setString(2, xid);
//执行查询语句
rs = selectPST.executeQuery();
boolean exists = false;
//遍历查询出来的数据
while (rs.next()) {
exists = true;
//如果服务端发送了多次回滚请求,这里只需要确保回滚了正确状态的日志
int state = rs.getInt(ClientTableColumnsName.UNDO_LOG_LOG_STATUS);
if (!canUndo(state)) {
if (LOGGER.isInfoEnabled()) {
LOGGER.info("xid {} branch {}, ignore {} undo_log", xid, branchId, state);
}
return;
}
//解析出context字段
String contextString = rs.getString(ClientTableColumnsName.UNDO_LOG_CONTEXT);
//解析出context为map
Map<String, String> context = parseContext(contextString);
//回去到rollback_info信息
byte[] rollbackInfo = getRollbackInfo(rs);
//获取到解析器名称,按照解析器进行序列化,默认使用jackson
String serializer = context == null ? null : context.get(UndoLogConstants.SERIALIZER_KEY);
UndoLogParser parser = serializer == null ? UndoLogParserFactory.getInstance()
: UndoLogParserFactory.getInstance(serializer);
//解析出回滚日志对象
BranchUndoLog branchUndoLog = parser.decode(rollbackInfo);
try {
// 设置当前线程采用的解析器的名称
setCurrentSerializer(parser.getName());
//获取到undolog 前后镜像数据信息
List<SQLUndoLog> sqlUndoLogs = branchUndoLog.getSqlUndoLogs();
if (sqlUndoLogs.size() > 1) {
Collections.reverse(sqlUndoLogs);
}
//遍历sql
for (SQLUndoLog sqlUndoLog : sqlUndoLogs) {
//获取到表的元数据信息
TableMeta tableMeta = TableMetaCacheFactory.getTableMetaCache(dataSourceProxy.getDbType()).getTableMeta(
conn, sqlUndoLog.getTableName(), dataSourceProxy.getResourceId());
sqlUndoLog.setTableMeta(tableMeta);
//根据数据库类型以及sql类型获取到对应的 undo执行器
AbstractUndoExecutor undoExecutor = UndoExecutorFactory.getUndoExecutor(
dataSourceProxy.getDbType(), sqlUndoLog);
undoExecutor.executeOn(conn);
}
} finally {
// 移除当前线程的序列化器
removeCurrentSerializer();
}
}
//如果存在undolog日志,需要删除undolog日志,跟业务代码一起提交事务,需要保证 undolog和日志回滚sql的一致性
if (exists) {
//删除undolog日志
deleteUndoLog(xid, branchId, conn);
//执行事务提交
conn.commit();
} else {
//如果不存在undolog日志,说明视图提交出现了异常导致undolog日志没有被存储上,这里插入了一个 GlobalFinished 状态的日志防止视图被正确的提交了
insertUndoLogWithGlobalFinished(xid, branchId, UndoLogParserFactory.getInstance(), conn);
//执行事务提交
conn.commit();
}
return;
} catch (SQLIntegrityConstraintViolationException e) {
} catch (Throwable e) {
//抛出了异常就执行undolog日志回滚
} finally {
//关闭各个流和管道
}
}
}
方法中真正执行日志回滚的是 AbstractUndoExecutor 类型,这是一个抽象类,通过工厂方法进行创建,根据数据库类型以及 sql的类型 获取到对应的执行器
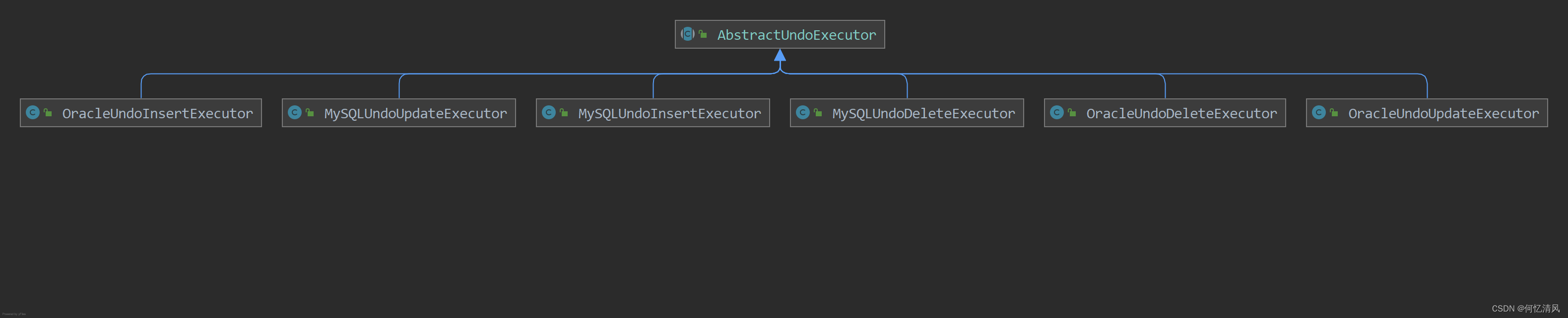
io.seata.rm.datasource.undo.AbstractUndoExecutor#executeOn:
executeOn 作为一个抽象类的公关方法,其中一些比较有特点的函数方法都交给子类实现,例如:buildUndoSQL(构建回滚的sql,如果是插入构建的回滚sql就是删除)、getUndoRows(获取到后置镜像的数据信息)
public void executeOn(Connection conn) throws SQLException {
/**
* 是否开启镜像数据的验证,如果开启了需要对后置镜像和当前数据进行数据的对比,如果不相同说明被其他事务改变需要根据对应的策略进行处理
* 对比策略:
* 前后镜像相比较是否一样,一样的就不需要执行后续了
* 后镜与当前数据进行比较是否一样
* 如果一样直接后续回滚
* 如果不一样再判断前镜与当前数据是否一样,如果不一样说明出现了脏数据,如果一样就不需要执行后续了
*/
if (IS_UNDO_DATA_VALIDATION_ENABLE && !dataValidationAndGoOn(conn)) {
return;
}
PreparedStatement undoPST = null;
try {
//buildUndoSQL() 抽象方法用于子类进行实现,sql不同子类实现方法也不同;例如:insert,构建回滚函数就是delete函数删除对应的语句
String undoSQL = buildUndoSQL();
//根据前置镜像的sql构建出sql语句
undoPST = conn.prepareStatement(undoSQL);
//根据后置镜像的记录获取到对应需要的数据
TableRecords undoRows = getUndoRows();
for (Row undoRow : undoRows.getRows()) {
ArrayList<Field> undoValues = new ArrayList<>();
//获取到记录的主键值
List<Field> pkValueList = getOrderedPkList(undoRows, undoRow, getDbType(conn));
for (Field field : undoRow.getFields()) {
if (field.getKeyType() != KeyType.PRIMARY_KEY) {
undoValues.add(field);
}
}
//设置value
undoPrepare(undoPST, undoValues, pkValueList);
//执行sql语句
undoPST.executeUpdate();
}
}
}
8.3 undolog删除
undolog日志的删除就比较简单了,调用处理 io.seata.rm.RMHandlerAT#handle 方法,通过undolog管理器删除执行,由 TC 指定删除对应的期限的 undolog日志,默认是删除过去 7 天的 3000条数据
io.seata.rm.RMHandlerAT#handle
public void handle(UndoLogDeleteRequest request) {
String resourceId = request.getResourceId();
DataSourceManager dataSourceManager = (DataSourceManager)getResourceManager();
DataSourceProxy dataSourceProxy = dataSourceManager.get(resourceId);
boolean hasUndoLogTable = undoLogTableExistRecord.computeIfAbsent(resourceId, id -> checkUndoLogTableExist(dataSourceProxy));
//根据存储天数进行数据的删除
Date division = getLogCreated(request.getSaveDays());
//获取到undolog日志管理器
UndoLogManager manager = getUndoLogManager(dataSourceProxy);
try (Connection conn = getConnection(dataSourceProxy)) {
if (conn == null) {
LOGGER.warn("Failed to get connection to delete expired undo_log for {}", resourceId);
return;
}
int deleteRows;
do {
//根据日期进行删除,默认 7 天之内的 3000条数据
deleteRows = deleteUndoLog(manager, conn, division);
} while (deleteRows == LIMIT_ROWS);
} catch (Exception e) {
// should never happen, deleteUndoLog method had catch all Exception
}
}
![[附源码]java毕业设计乡村振兴惠农推介系统](https://img-blog.csdnimg.cn/d098fb745292450f9a8854ab844c607f.png)







![[附源码]java毕业设计文档管理系统](https://img-blog.csdnimg.cn/544f3540300343dd803ccb1519bf2cba.png)