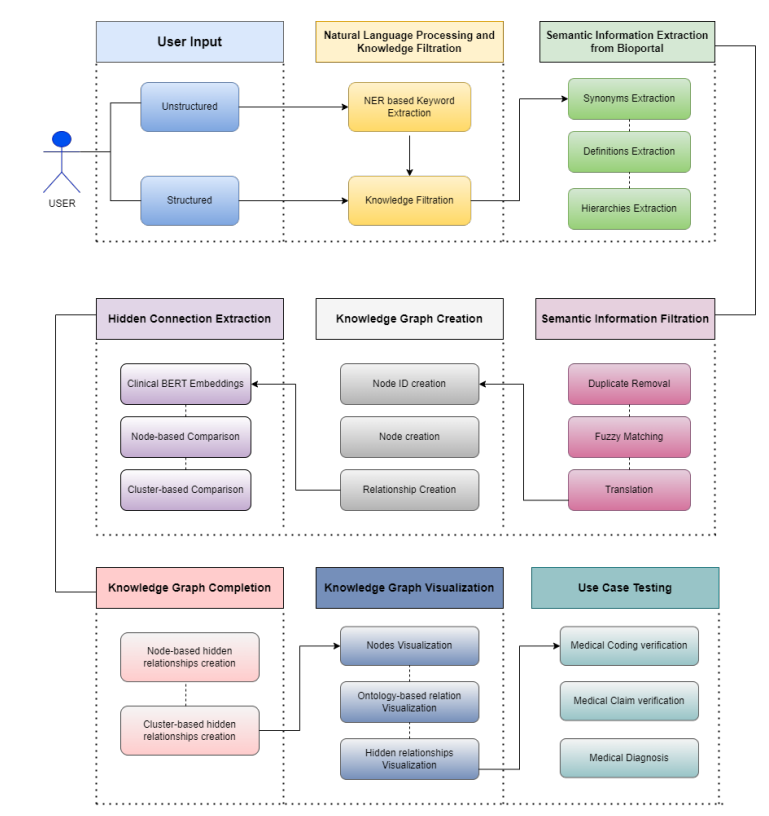
机器学习的三大类型——监督学习、无监督学习和强化学习,虽然可以应用于许多问题,但并非所有问题都能通过这些方法有效解决。每种类型的机器学习都有其局限性,具体如下:
1. 监督学习 (Supervised Learning)
监督学习是通过训练数据中的标签来学习映射关系,常用于分类和回归任务。尽管监督学习在许多领域取得了成功,但它也有一些无法解决的问题:
- 标签缺失问题:监督学习依赖于标记数据(即每个训练样本都需要一个明确的标签)。对于很多任务,标记数据的获取成本很高,或者根本无法获得足够的标记数据(如医学影像的人工标注)。
- 过拟合:如果训练数据的样本过少或不具代表性,模型可能会过度拟合训练数据,导致在新数据上的表现很差。
- 高维稀疏数据:在某些情况下(例如文本处理中的词袋模型),数据维度非常高,而每个数据点中只有少数特征非零,这使得监督学习模型很难提取有效信息,导致模型性能较差。
2. 无监督学习 (Unsupervised Learning)
无监督学习不依赖于标签数据,而是从无标签数据中提取结构或模式。它常用于聚类、降维等任务。然而,无监督学习也有其局限性:
- 缺乏明确目标:无监督学习无法提供一个明确的目标或标准来评估模型的好坏,尤其是在需要明确分类或回归结果的情况下。这使得某些任务(例如预测问题)无法有效应用无监督学习。
- 难以评估模型效果:无监督学习的输出通常是聚类或数据的低维表示,而这些输出可能很难解释或评估,尤其是在没有明确标注数据的情况下。
- 对数据的先验假设依赖性强:许多无监督学习算法(如K-means聚类)依赖于特定的数据结构或假设,如果数据不符合这些假设,算法的效果可能会大打折扣。
3. 强化学习 (Reinforcement Learning)
强化学习是一种通过与环境交互并根据奖励信号学习的方式,常用于控制、游戏、机器人等领域。尽管强化学习有强大的应用潜力,但它也有一些无法有效解决的问题:
- 样本效率低:强化学习通常需要大量的交互和试错过程才能获得有效的策略。对于一些需要在短时间内做出决策的任务,强化学习可能非常低效。
- 需要大量计算资源:尤其是在复杂的环境中,训练强化学习模型通常需要大量的计算资源和时间,这对于某些实际应用(如实时决策)可能不适用。
- 现实世界中难以定义奖励:在某些问题中,定义合适的奖励函数可能非常困难,尤其是当任务没有明确的衡量标准时。错误的奖励设计可能导致模型学习到不期望的行为。
- 多任务或复杂环境:强化学习往往在相对单一和简化的环境中表现较好,但在多任务或动态变化的复杂环境中,模型的学习效果可能较差,且难以适应不断变化的条件。
总结
尽管监督学习、无监督学习和强化学习在很多应用场景中表现优秀,但它们并非万能的。具体的局限性包括:
- 监督学习依赖大量标注数据,且容易过拟合;
- 无监督学习缺乏明确的评估标准,难以解决有明确目标的任务;
- 强化学习需要大量的样本和计算资源,且难以应对奖励定义不明确的任务。
在这些局限性下,机器学习有时需要与其他技术(如领域知识、人工智能的其他方法)结合使用,才能解决复杂问题。