一、背景
最近在给项目搭建日志平台的时候,采用的方案是 SkyWalking + ELK 日志平台,但发现 ELK 日志平台中的日志没有 Trace ID,导致无法追踪代码报错的整体链路。
空哥提示:
Trace ID是分布式追踪中用来唯一标识一个服务请求或事务的 ID。在微服务架构中,一个请求可能会经过多个服务节点,Trace ID 帮助追踪和关联整个请求链路中的所有日志和性能数据。
既然 SkyWalking 提供了日志的链路追踪,为什么 ELK 没有链路追踪 ID 呢? 带着这个疑问我们继续往下看。
二、SkyWalking 和 ELK 啥关系啊?
-
SkyWalking: 专注于应用性能监控(APM)的系统,主要提供分布式追踪、服务性能分析和多维度监控功能。
它支持自动化代码埋点,能够追踪微服务之间的调用关系和性能指标。
-
ELK:日志数据的集中管理和分析,Elasticsearch + Logstash + Filebeat,作为日志采集和存储,Kibana 作为可视化日志检索平台。
SkyWalking 和 ELK 是如何联系在一起的?我们一步一步往下看。
2.1 SkyWalking
SkyWalking 本来就带有链路追踪,而且通过搭建 SkyWalking-UI 服务就可以以通过界面来查看日志。
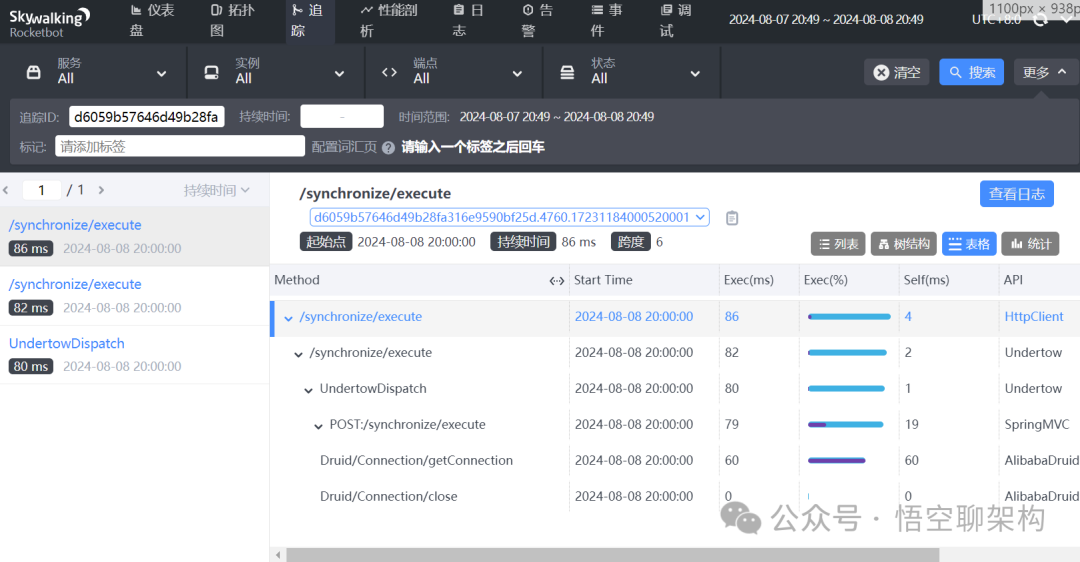
SkyWalking 整体架构如下:
FROM http://skywalking.apache.org/
-
最上面的 Tracing:负责从应用中,收集链路信息,发送给 SkyWalking OAP 服务器,目前支持 SkyWalking、Zikpin、Jaeger 等提供的 Tracing 数据信息。我们采用的是 SkyWalking Agent 收集 SkyWalking Tracing 数据,传递给 SkyWalking OAP 服务器。
-
中间的 SkyWalking OAP 服务器 :负责接收 Agent 发送的 Tracing 数据信息,然后进行分析(Analysis Core) ,存储到外部存储器( Storage ),最终提供查询( Query )功能。
-
最右边的 Storage :负责存储 Tracing 数据。目前支持 ES、MySQL、Sharding Sphere、TiDB、H2 多种存储器。
-
最左边的 SkyWalking UI :一个网页版的界面,提供查看数据的功能。
2.2 ELK 集中日志平台
整体的架构图如下所示,
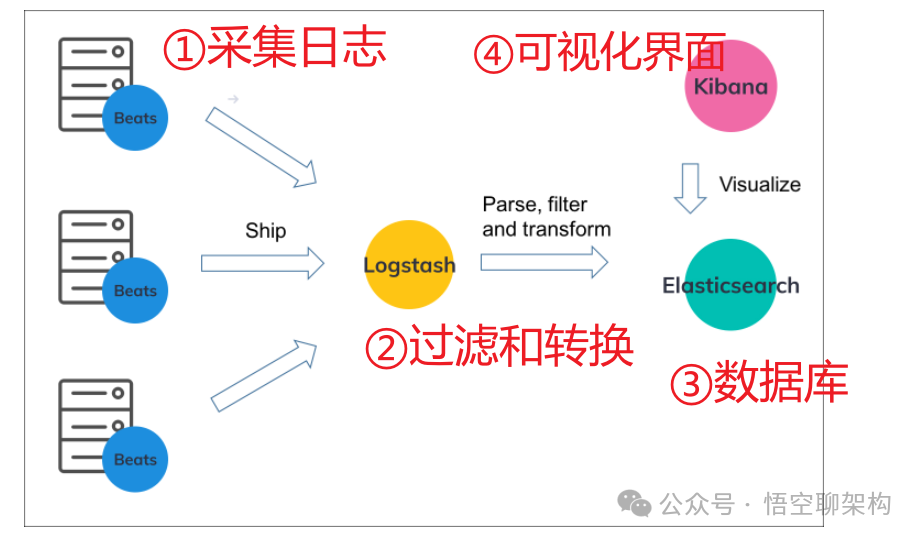
流程如下:
-
Beats:
Filebeat 服务属于 Beats,部署在应用侧,它把日志收集起来,然后再把数据传给 Logstash 服务。
-
Logstash:
负责日志数据的过滤、匹配、格式转换,然后将日志数据发送给 Elasticsearch 存储。
-
Elasticsearch:
负责存储日志数据和建立日志数据索引,便于 Kibana 查询日志。
-
Kibana:
负责可视化查询日志数据。
2.3 SkyWalking 和 ELK 有什么相同之处?
-
都能采集日志
-
都有可视化界面来查询日志
那么这两款日志平台有很多类似之处,直接用其中一种不行吗?
三、只用 SkyWalking 可以吗?
SkyWalking 优点是服务性能分析和链路追踪,但也有不足之处。
3.1 采集方式上不足
Skywalking 监控 Java、Golang、Node、.NET 语言的链路都是采用了 SDK 或者 Agent 的方式将数据上报到 Skyalking 后端,不过都是采用 gRPC 的方式和后端交互,比如我们项目是 Java 项目,SkyWalking Agent 采集到后端的 Java 日志后进行上报。而对于 Nginx 则需要写 Lua 脚本来和 SkyWalking AOP 服务通信,对于 MySQL 日志也需要单独写脚本来上报日志。
3.2 数据可视化的不足
-
SkyWalking 对于链路的展示非常直观,但是对于日志的数据的展示探索能力很弱,而 Kibana 提供了丰富的可视化选型,如折线图、饼图等。
-
SkyWalking 对于日志的搜索和展示能力较弱,而 Kibana 对于搜索的方式非常丰富,而且支持高亮。
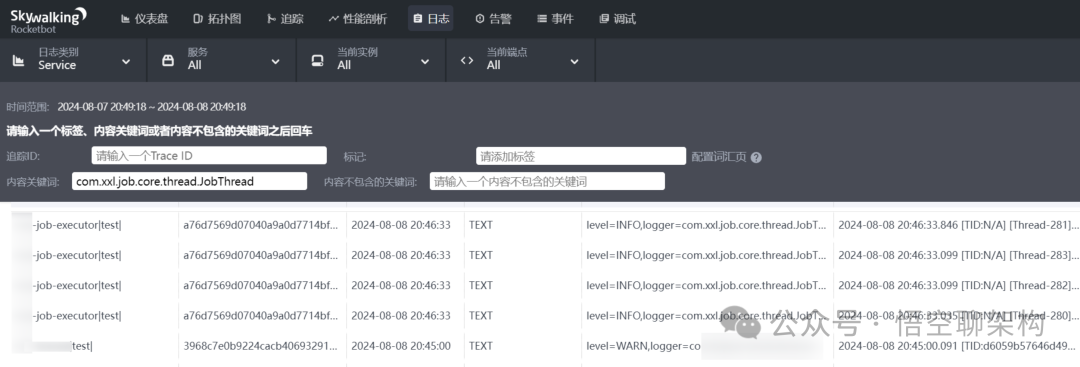
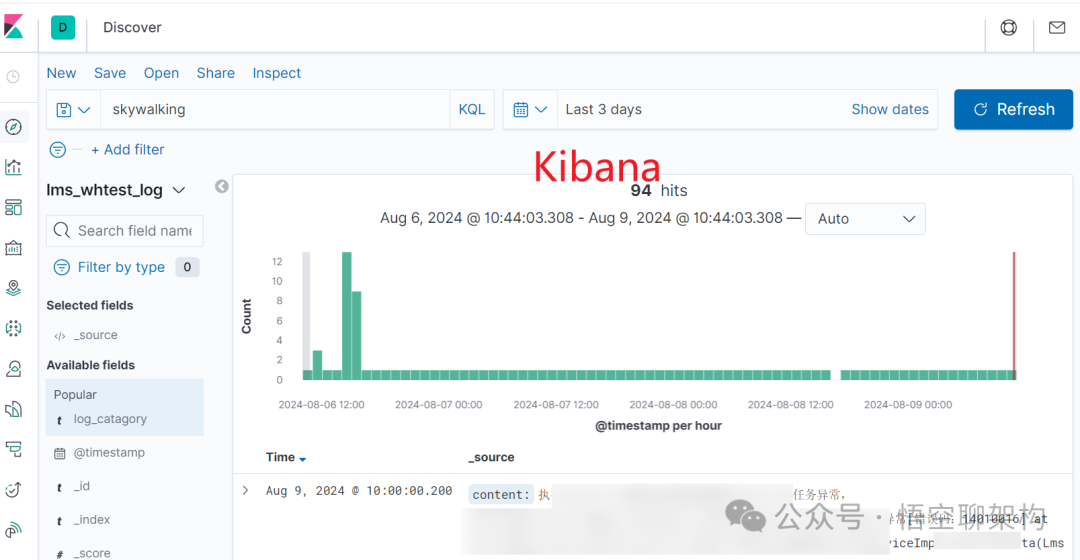
下图分别为 SkyWalking 和 Kibana 的可视化界面
四、只用 ELK 可以实现链路追踪吗?
当然是可以,但是 ELK 并没有日志追踪的能力,需要借助其他工具来实现,以下是常见的做法。
-
SkyWalking 嵌入 Trace ID,依赖 SkyWalking Agent。
-
MDC 中加入 Trace ID,简便,需要在拦截器中加入 Trace ID。
-
Kibana 最近日志,不准确。
4.1 SkyWalking 嵌入 Trace ID 到日志
通过 SkyWalking 的自定义日志布局类 TraceIdPatternLogbackLayout,将分布式追踪系统中的追踪 ID(Trace ID)嵌入到日志中。
4.1.1 使用方式
在 logback-spring.xml 日志配置文件中配置控制台打印的时候使用带有 SkyWalking 的 TraceId 的日志布局。如下代码所示,使用了 TraceIdPatternLogbackLayout 日志布局,然后在日志格式中加入了 [%tid],就能将 trace id 打印出来。
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!-- 定义一个带有TraceId的日志布局 -->
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>${CONSOLE_LOG_PATTERN:-%clr(%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) [%tid] %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}</pattern>
</layout>
<root level="debug">
<appender-ref ref="STDOUT" />
</root>
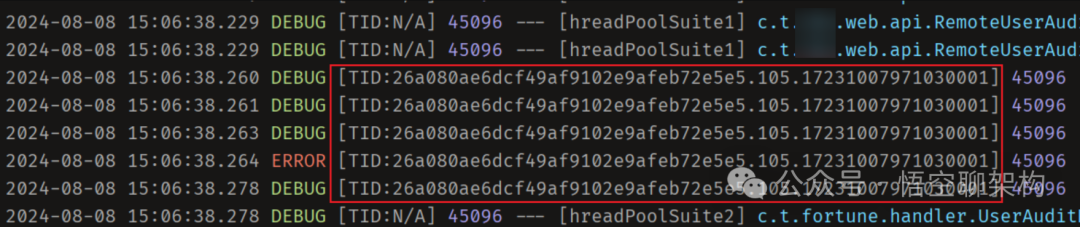
</configuration>程序运行期间就会在控制台窗口打印出 trace id,如下所示:
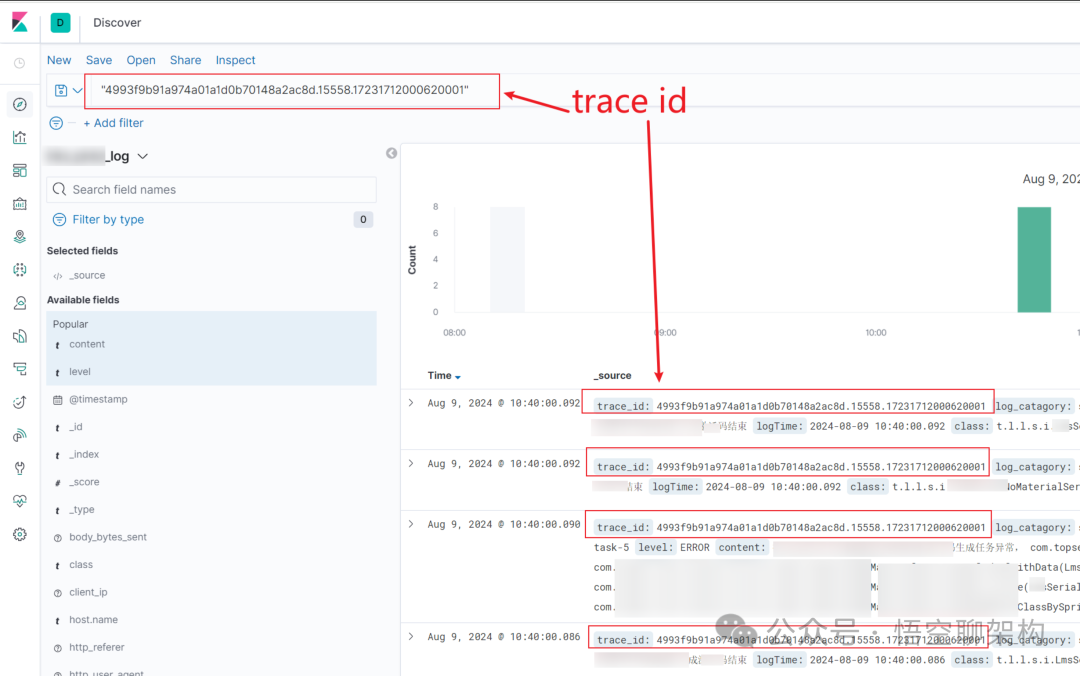
然后通过 Filebeat 和 Logstash 将日志采集并上传到 Elasticsearch。如下图索索,Kibana 根据 trace id 来查看链路日志。
4.1.2 原理
-
上下文传递:
在分布式系统中,服务之间通过 HTTP 调用或其他通信机制相互交互。
Trace ID 需要在服务之间传递,以便追踪整个请求链路。
-
日志集成:
SkyWalking 通过字节码增强或自动代理等技术,自动在应用的运行时上下文中生成和管理 Trace ID。
-
配置灵活性:
SkyWalking 允许开发者通过配置文件(如 logback.xml)自定义日志格式,包括是否在日志中包含 Trace ID。
4.2 MDC 方案
MDC 的方案就是自己生成一个随机 ID 作为 traceId,然后 put 到 MDC 里面。如下代码所示:
-
1
MDC.put("traceId", UUID.randomUUID().toString());
MDC(Mapped Diagnostic Context)用于存储运行上下文的特定线程的上下文数据。MDC 主要依赖于线程局部存储(Thread-Local Storage),这意味着每个线程都有自己独立的 MDC 数据。属于该线程的任何代码都可以轻松访问线程的 MDC 中存在的值。
使用方式和原理可以看空哥之前写的一篇文章:
从 1.5 开始搭建一个微服务框架——链路追踪 traceId
先贴个原理图给大家看看:

4.3 Kibana 的最近日志
Kibana 可查看某一条日志相近的多条日志,如下图所示,点击 View surrounding documents 按钮即可。
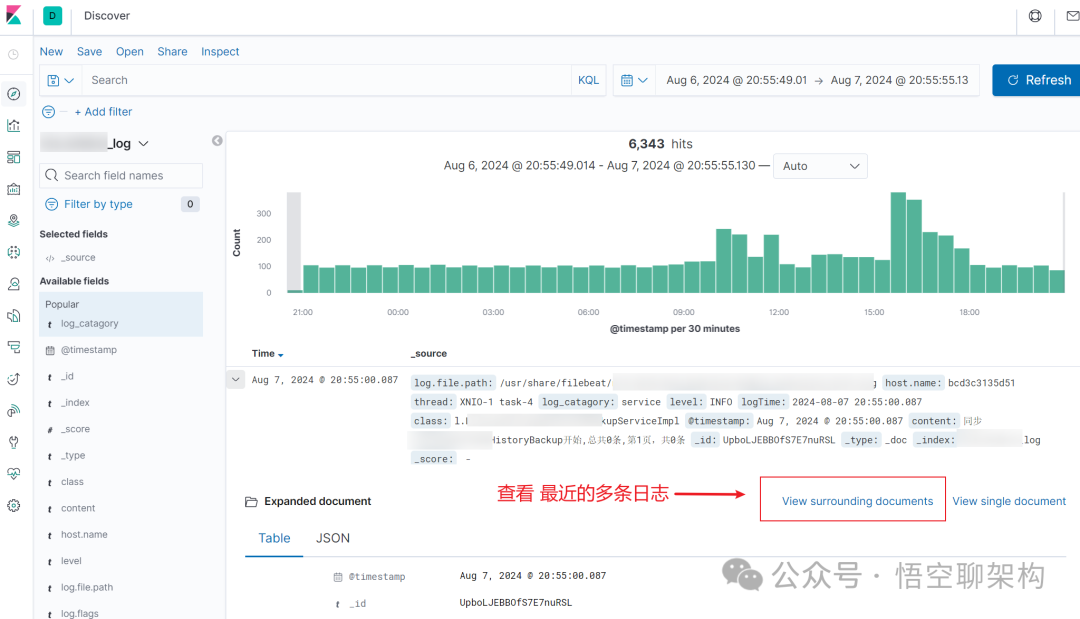
然后就能看到与之时间相近的多条日志

但是这种方式不易准确辨别出相关联的上下文的日志。不易辨别的原因如下:
-
相近时间段内有很多类似日志。
-
相近时间段内有大量的其他日志穿插在这个上下文中,不易刷选可用的日志。
五、总结
SkyWalking和 ELK 各自在 APM 与日志管理领域发挥着重要作用,尽管原生 ELK 不直接支持链路追踪,但通过与 SkyWalking 的集成,可以互补优势,共同提升微服务架构下的可观测性。








![19,[极客大挑战 2019]PHP1](https://i-blog.csdnimg.cn/direct/4b90de505c2044d18a1b9cc257f0e0be.png)








