本文详细介绍SDXL在SD系列的基础上做了什么优化,包括模型架构优化和训练过程数据的相关优化策略。

目录
Stable Diffusion XL核心基础内容
SDXL整体架构初识
Base模型
Refiner模型
Base——VAE
Base——U-Net
Base——Text Encoder
Refiner
GPT补充【TODO】
SDXL官方训练技巧&细节
图像尺寸条件化
图像裁剪条件化
多尺度训练
使用Offset Noise
SDXL的条件注入与训练细节
总结
补充
1. 图像尺寸条件化嵌入位置
2. 图像裁剪条件化嵌入位置
傅里叶编码的优点
嵌入位置总结
历史文章
Stable Diffusion XL核心基础内容
摘录于:https://zhuanlan.zhihu.com/p/643420260
与Stable Diffusion 1.x-2.x相比,Stable Diffusion XL主要进行如下的优化:
- 基于Stable Diffusion 1.x-2.x的U-Net,VAE,CLIP Text Encoder改进。
- 增加一个独立的基于Latent的Refiner模型,也是一个扩散模型,用来提升生成图像的精细化程度。
- 设计了很多训练Tricks,包括图像尺寸条件化策略、图像裁剪参数条件化策略以及多尺度训练策略等。
- 先发布Stable Diffusion XL 0.9测试版本,基于用户反馈,针对性增加数据集和使用RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)技术优化训练后,推出了Stable Diffusion XL 1.0正式版。
SDXL整体架构初识
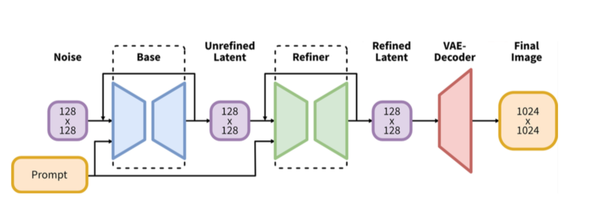
Stable Diffusion XL是一个二阶段的级联扩散模型(Latent Diffusion Model),包括Base模型和Refiner模型。
Base模型
其中Base模型的主要工作和Stable Diffusion 1.x-2.x一致,具备文生图(txt2img)、图生图(img2img)、图像inpainting等能力。
SDXL Base模型由U-Net、VAE以及CLIP Text Encoder(两个)三个模块组成。
在FP16精度下Base模型大小6.94G(FP32:13.88G),其中U-Net占5.14G、VAE模型占167M以及两个CLIP Text Encoder一大一小(OpenCLIP ViT-bigG和OpenAI CLIP ViT-L)分别是1.39G和246M。
Refiner模型
在Base模型之后,级联了Refiner模型,对Base模型生成的图像Latent特征进行精细化提升,其本质上是在做图生图的工作。
SDXL Refiner模型同样由U-Net、VAE和CLIP Text Encoder(一个)三个模块组成(与Base模型共用,CLIP用大的)。
在FP16精度下Refiner模型大小6.08G,其中U-Net占4.52G、VAE模型占167M(与Base模型共用)以及CLIP Text Encoder模型(OpenCLIP ViT-bigG)大小1.39G(与Base模型共用)。
Stable Diffusion XL的参数量增加到了66亿(Base模型35亿+Refiner模型31亿),Stable Diffusion XL 1.0在0.9版本上使用更多训练集+RLHF来优化生成图像的色彩、对比度、光线以及阴影方面。
Base——VAE
回顾VAE流程【推理阶段】:
1. 当输入是图片时,首先会使用VAE的Encoder结构将输入图像转换为Latent特征,然后U-Net不断对Latent特征进行优化,最后使用VAE的Decoder结构将Latent特征重建出像素级图像。VAE还可以改进生成图像中的高频细节,小物体特征和整体图像色彩【当滤镜使用·】。
2. 当输入是文字时,这时我们不需要VAE的Encoder结构,只需要Decoder进行图像重建。VAE的灵活运用,让Stable Diffusion系列增添了几分优雅。
SDXL的VAE结构(KL-f8)和损失函数没有变,但在训练中做了以下两点优化:
- 选择了更大的Batch-Size(256 vs 9),
- 对模型进行指数滑动平均操作(EMA,exponential moving average),EMA对模型的参数做平均,从而提高性能并增加模型鲁棒性。
SD 1.x和SD 2.x的VAE模型是互相兼容的。而SDXL VAE是重新从头开始训练的,所以其Latent特征分布与之前的两者不同,不兼容。
VAE在将Latent特征送入U-Net之前,需要对Latent特征进行缩放让其标准差尽量为1:
- Stable Diffusion1.x和2.x系列采用的缩放系数为0.18215;
- Stable Diffusion XL的缩放系数重新设置为0.13025。
注意:由于缩放系数的改变,使用不匹配的VAE,会生成充满噪声的图片。
Base——U-Net
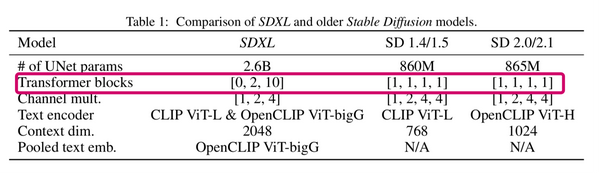
上表是Stable Diffusion XL与之前的Stable Diffusion系列的对比,参数量增加幅度达到了3倍左右。

1. SDXL_Spatial Transformer_X模块数量占新增参数量的主要部分,结构,由Conv改为Liner,且使用X个BasicTransformer Block


2. U-Net的Encoder和Decoder结构也从之前系列的4stage改成3stage([1,1,1,1] -> [0,2,10]),如上表红框。
3. SDXL只使用两次下采样和上采样,而之前的SD系列模型都是三次下采样和上采样。
- 在的Encoder结构中,包含了两个CrossAttnDownBlock结构和一个SDXL_DownBlock结构;
- 在Decoder结构中,包含了两个CrossAttnUpBlock结构和一个SDXL_UpBlock结构;
- 与此同时,Encoder和Decoder中间存在Skip Connection,进行信息的传递与融合。


在第一个stage中不再使用Spatial Transformer Blocks,而在第二和第三个stage中大量增加了Spatial Transformer Blocks(分别是2和10)。这样设计有什么好处呢?
首先,在第一个stage中不使用SDXL_Spatial Transformer_X模块,可以明显减少显存占用和计算量。
然后,在第二和第三个stage这两个维度较小的feature map上使用数量较多的SDXL_Spatial Transformer_X模块,能在大幅提升模型整体性能(学习能力和表达能力)的同时,优化了计算成本。
整个新的SDXL Base U-Net设计思想也让SDXL的Base出图分辨率提升至1024x1024。在出图参数保持一致的情况下,耗时只比Stable Diffusion多了20%-30%之间。
Base——Text Encoder
回顾SD模型:CLIP模型主要包含Text Encoder和Image Encoder两个模块。
- Stable Diffusion 1.x系列使用的是OpenAI CLIP ViT-L/14(123.65M)中的Text Encoder模型;
- Stable Diffusion 2.x系列则使用OpenCLIP ViT-H/14(354.03M)中的Text Encoder模型。
同样是一个只由Transformer模块组成的模型,一共有12个CLIPEncoder模块。
不同的是,Stable Diffusion XL与之前的系列相比使用了两个CLIP Text Encoder从文本信息中提取Text Embeddings,分别是
- OpenCLIP ViT-bigG(694M)
- OpenAI CLIP ViT-L/14(123.65M)
从而大大增强了Stable Diffusion XL对文本的提取和理解能力,同时提高了输入文本和生成图片的一致性。
OpenCLIP ViT-bigG的优势在于模型结构更深,特征维度更大,特征提取能力更强,但是其两者的基本CLIPEncoder模块是一样的。

Stable Diffusion XL分别提取两个Text Encoder的倒数第二层特征,并进行concat操作作为文本条件(Text Conditioning),总的特征维度是77x2048。在ImageNet上zero-shot性能有所提高。
其中OpenCLIP ViT-bigG的特征维度为77x1280,而OpenAI CLIP ViT-L/14的特征维度是77x768,所以输入总的特征维度是77x2048。
77是最大的token数,2048是SDXL的context dim——1280+768=2048,再通过Cross Attention模块将文本信息传入Stable Diffusion XL的训练过程与推理过程中。
其他相同点
- SDXL和SD 1.x-2.x系列一样,只使用Text Encoder模块从文本信息中提取Text Embeddings。
- SD XL输入的最大Token数依旧是77,当输入文本的Token数量超过77后,将通过Clip操作拉回77x2048;如果Token数不足77则会通过padding操作得到77x2048。
- 和之前的系列一样,SDXL Text Encoder在官方训练时是冻结的,我们在对SDXL模型进行微调训练时,可以同步开启Text Encoder的微调训练,能够使得Text Encoder对生成图片的控制力增强,使其生成内容更加贴近训练集的分布。
U-Net(Base)结构+Refiner结构
Refiner
SD XL在U-Net(Base)之后,级联Refiner模型,进一步提升生成图像的细节特征与整体质量。通过级联的方式进行模型融合(ensemble),提升生成图片的质量
由于已经有U-Net(Base)模型生成了图像的Latent特征,所以Refiner模型的主要工作是在Latent特征进行小噪声去除和细节质量提升。

Refiner模型和Base模型一样是基于Latent的扩散模型,也采用了Encoder-Decoder结构,和U-Net兼容同一个VAE模型。不过在Text Encoder部分,Refiner模型只使用了OpenCLIP ViT-bigG的Text Encoder,同样提取了倒数第二层特征以及进行了pooled text embedding的嵌入。

SDXL Refiner模型和SDXL Base模型在结构上的异同:
1. SDXL Base的Encoder和Decoder结构都采用3个stage,而SDXL Base【应该是Refiner】设计的是4个stage。
【Refiner与 Base 模型相比多了一个 stage,因为 Refiner 的主要任务是对初步生成的图像进行细化,而不需要像 Base 模型一样的深度生成过程。】
2. SDXL Refiner和SDXL Base一样,在第一个stage中没有使用Attention模块。
【在 SDXL Base 和 SDXL Refiner 的结构中, 第一个 stage 不使用 Attention 模块。这样做是因为第一个 stage 主要用于低级别的特征提取,而不是关注高层次的语义信息。】
3. 在经过第一个卷积后,SDXL Refiner设置初始网络特征维度为384,而SDXL Base 采用的是320。
4. SDXL Refiner的Attention模块中SDXL_Spatial Transformer结构数量均设置为4。
【在 SDXL Refiner 的 Attention 模块中,每个 Attention stage 中的 SDXL_Spatial Transformer 数量均设置为 4,以增强图像的细节处理能力。这种配置确保了 Refiner 在对图像细化时具有足够的计算能力。】
5. SDXL Refiner的参数量为2.3B,比起SDXL Base的2.6B参数量略小一些。
【因为 Refiner 模型的深度比 Base 模型稍浅(3 个 stage),并且主要关注局部细节增强,因此不需要完全相同的计算量。】
6. SDXL Refiner模型的训练逻辑与SDXL Base一样,不过Refiner模型只在前200个Timesteps上训练(设置的noise level较低)。
在Stable Diffusion XL推理阶段,输入一个prompt,通过VAE和U-Net(Base)模型生成Latent特征,接着给这个Latent特征进行扩散过程加上一定的噪音。在此基础上,再使用Refiner模型进行去噪,以提升图像的整体质量与局部细节。
- Base 模型:更深、去噪步数更多,专注于从噪声生成图像,侧重整体生成过程。
- Refiner 模型:更浅、去噪步数较少,主要关注局部细节的增强,侧重图像细节的微调和增强。
GPT补充【TODO】
SDXL官方训练技巧&细节
图像尺寸条件化
之前在Stable Diffusion的训练过程中,需要用两个阶段的训练过程都要对最小图像尺寸进行约束。
- 第一阶段中,会将尺寸小于256x256的图像舍弃;之后在256x256的图像尺寸上进行预训练。
- 在第二阶段,会将尺寸小于512x512的图像筛除;然后在512x512的图像尺寸上继续训练。
这样的约束会导致训练数据中的大量数据被丢弃,从而很可能导致模型性能和泛化性的降低。
针对上述问题,常规思路可以借助超分模型将尺寸过小的图像放大。但是可能会在对图像超分的同时会引入一些噪声伪影,影响模型的训练,导致生成一些模糊的图像。
SD XL的核心思想是height和width都使用傅里叶特征编码进行独立嵌入,将图像尺寸作为条件引入训练过程。
SD XL为了在解决数据集利用率问题的同时不引入噪声伪影,将U-Net(Base)模型与原始图像分辨率相关联,核心思想是将输入图像的原始高度和宽度作为额外的条件嵌入U-Net模型中,表示为
=(height,width) 。height和width都使用傅里叶特征编码进行独立嵌入,然后将特征concat后加在Time Embedding上,将图像尺寸作为条件引入训练过程。这样以来,模型在训练过程中能够学习到图像的原始分辨率信息,从而在推理生成阶段更好地适应不同尺寸的图像生成,而不会产生噪声伪影的问题。
使用了图像尺寸条件化后,Base模型已经对不同图像分辨率有了“自己的判断”。当输入低分辨率条件时,生成的图像较模糊;在不断增大分辨率条件时,生成的图像质量不断提升。
图像裁剪条件化
之前的SD系列模型,由于需要输入固定的图像尺寸用作训练,很多数据在预处理阶段会被裁剪。训练中对图像裁剪可能导致的图像特征丢失。进而造成在图像生成过程中出现不符合训练数据分布的特征。
图像裁剪条件化主要思想是在加载数据时,将左上角的裁剪坐标通过傅里叶编码后加在Time Embedding上,并嵌入U-Net(Base)模型中,并与原始图像尺寸一起作为额外的条件嵌入U-Net模型,从而在训练过程中让模型学习到对“图像裁剪”的认识。
之前的Stable Diffusion系列模型,由于需要输入固定的图像尺寸用作训练,很多数据在预处理阶段会被裁剪。生成式模型中典型的预处理方式是先调整图像尺寸,使得最短边与目标尺寸匹配,然后再沿较长边对图像进行随机裁剪或者中心裁剪。虽然裁剪是一种数据增强方法,但是训练中对图像裁剪导致的图像特征丢失,可能会导致AI绘画模型在图像生成过程中出现不符合训练数据分布的特征。
如下图所示,对一个骑士的图片做了裁剪操作后,丢失了头部和脚部特征,再将裁剪后的数据放入模型中训练,就会影响模型对骑士这个概念的学习和认识。
“骑士”概念特征被破坏的数据 下图中展示了SD 1.4和SD 1.5的经典失败案例,生成图像中的猫出现了头部缺失的问题,龙也出现了体征不完整的情况:
SD1.4和SD1.5的经典失败案例 其实之前NovelAI就发现了这个问题,并提出了基于分桶(Ratio Bucketing)的多尺度训练策略,其主要思想是先将训练数据集按照不同的长宽比(aspect ratio)进行分组(groups)或者分桶(buckets)。在训练过程中,每次在buckets中随机选择一个bucket并从中采样Batch个数据进行训练。将数据集进行分桶可以大量较少裁剪图像的操作,并且能让模型学习多尺度的生成能力;但相对应的,预处理成本大大增加,特别是数据量级较大的情况下。
并且尽管数据分桶成功解决了数据裁剪导致的负面影响,但如果能确保数据裁剪不把负面影响引入生成过程中,裁剪这种数据增强方法依旧能给模型增强泛化性能。所以Stable Diffusion XL使用了一种简单而有效的条件化方法,即图像裁剪参数条件化策略。其主要思想是在加载数据时,将左上角的裁剪坐标通过傅里叶编码后加在Time Embedding上,并嵌入U-Net(Base)模型中,并与原始图像尺寸一起作为额外的条件嵌入U-Net模型,从而在训练过程中让模型学习到对“图像裁剪”的认识。
从下图中可以看到,将不同的 ccrop 坐标条件的生成图像进行了对比,当我们设置 ccrop=(0,0) 时可以生成主要物体居中并且无特征缺失的图像,而采用其它的坐标条件则会出现有裁剪效应的图像:
SDXL使用不同裁剪坐标获取具有裁剪效应的图像
图像尺寸条件化策略和图像裁剪参数条件化策略都能在SDXL训练过程中使用(在线方式应用),同时也可以很好的迁移到其他AIGC生成式模型的训练中。下图详细给出了两种策略的通用使用流程:

图像尺寸条件化策略和图像裁剪参数条件化策略在SDXL训练时的使用流程可以看到,SDXL在训练过程中的数据处理流程和之前的系列是一样的,只是需要再将图像原始长宽(width和height)以及图像进行crop操作时的左上角的裁剪坐标top和left作为条件输入。
多尺度训练
Stable Diffusion XL在多尺度训练的基础上,增加了分桶策略。
SDXL的论文中说训练时采用的是内部数据集作为训练。Stable Diffusion XL首先采用图像尺寸条件化和图像裁剪参数条件化这两种策略在256x256和512x512的图像尺寸上分别预训练600000步和200000步(batch size = 2048),总的数据量约等于 (600000 + 200000) x 2048 = 16.384亿。
接着Stable Diffusion XL在1024x1024的图像尺寸上采用多尺度方案来进行微调,并将数据分成不同纵横比的桶(bucket),并且尽可能保持每个桶的像素数接近1024×1024,同时相邻的bucket之间height或者width一般相差64像素左右。
Stable Diffusion XL的具体分桶情况如下图所示:
Stable Diffusion XL训练中使用的多尺度分桶训练策略 其中Aspect Ratio = Height / Width,表示高宽比。
在训练过程中,一个Batch从一个桶里的图像采样,并且我们在每个训练步骤(step)中可以在不同的桶之间交替切换。除此之外,Aspect Ratio也会作为条件嵌入到U-Net(Base)模型中,嵌入方式和上面提到的其他条件嵌入方式一致,让模型能够更好地学习到“多尺度特征”。
与此同时,SDXL在多尺度微调阶段依然使用图像裁剪参数条件化策略,进一步增强SDXL对图像裁剪的敏感性。
在完成了多尺度微调后,SDXL就可以进行不同Aspect Ratio的图像生成了,不过官方推荐生成尺寸默认为1024x1024。
使用Offset Noise
在SDXL进行微调时,使用了Offset Noise操作,能够让SDXL生成的图像有更高的色彩自由度(纯黑或者纯白背景的图像)。
SD 1.x和SD 2.x一般只能生成中等亮度的图片,即生成平均值相对接近 0.5 的图像(全黑图像为 0,全白图像为 1),之所以会出现这个问题,是因为SD系列模型训练和推理过程的不一致造成的。
SD模型在训练中进行noise scheduler流程并不能将图像完全变成随机高斯噪声,但是推理过程中,SD模型是从一个随机高斯噪声开始生成的,因此就会存在训练与推理的噪声处理过程不一致。
Offset Noise操作是解决这个问题的一种直观并且有效的方法,我们只需要在SD模型的微调训练时,把额外从高斯分布中采样的偏置噪声引入图片添加噪声的过程中,这样就对图像的色彩均值造成了破坏,从而提高了SDXL生成图像的“泛化性能”。
上述代码中的noise_offset默认是采用0.1,SDXL在官方的训练中采用的是0.05。
SDXL的条件注入与训练细节
上面三个图像条件可以像Timestep一样采用傅立叶编码得到Embedding特征,然后再和pooled text embedding特征concat,得到维度为2816的embeddings特征。
接着再将这个embeddings特征通过两个Linear层映射到和Time Embedding一样的维度空间,然后加(add)到Time Embedding上即可作为SDXL U-Net的条件输入。
可以看到,上面的流程已经清晰的展示了SDXL进行额外条件注入的全部流程。
总结
在 SDXL 的训练中,图像尺寸条件化、图像裁剪条件化、多尺度训练和 Offset Noise 操作共同提升了模型的生成质量:
- 图像尺寸条件化:利用傅里叶特征编码将图像尺寸作为条件嵌入,避免数据丢失和放大噪声问题,提升模型的泛化能力。
- 图像裁剪条件化:通过编码裁剪坐标,让模型学习图像裁剪的特征影响,确保生成图像符合训练数据分布。【通过傅里叶编码裁剪坐标(左上角的裁剪坐标top和left)后加在Time Embedding上】
- 多尺度训练:【先经过1和2的图像与训练后,再】引入分桶策略,保证不同纵横比的图像质量一致性,增强生成图像的细节和比例适应性。
- Offset Noise:通过【训练时额外从高斯分布中采样的】偏置噪声提升色彩自由度和泛化性,使模型在色彩复杂的场景下生成更自然的图像。
SDXL在训练中的配置。和SD 1.x系列一样,SDXL在训练时采用了1000步的DDPM和相同的noise scheduler,同时依旧采用基于预测noise的损失函数,和SD 1.x系列一致:

这里的c为Text Embeddings。
补充
在 SDXL 中,图像尺寸条件化和图像裁剪条件化分别通过傅里叶编码增强模型对尺寸和裁剪特征的理解。这些条件的嵌入位置(都可以嵌入时间步条件向量)和傅里叶编码的细节如下:
1. 图像尺寸条件化嵌入位置
嵌入目标:
图像尺寸(如宽度W和高度H)被编码后作为模型的条件输入,用于指导生成不同尺寸的图像。
嵌入具体操作:
-
傅里叶编码:
- 输入:图像的尺寸
(W, H),通常是归一化后的值,例如缩放到[0, 1]范围。 - 编码:通过傅里叶特征,将低维连续变量
(W, H)转换成高维表示:,其中
是一组频率基。
- 编码后的维度增加,捕捉了尺寸变化的高频和低频信息。
- 输入:图像的尺寸
-
与模型嵌入融合:
- 编码结果通过线性层映射到特定维度,与时间步嵌入(Time Embedding)或模型的中间层(U-Net)条件向量结合。时间步嵌入如下:
- 在生成过程中,图像尺寸的特征影响扩散过程的每一阶段,确保尺寸变化的全局一致性。
- 编码结果通过线性层映射到特定维度,与时间步嵌入(Time Embedding)或模型的中间层(U-Net)条件向量结合。时间步嵌入如下:
2. 图像裁剪条件化嵌入位置
嵌入目标:
将图像裁剪操作(即左上角裁剪坐标 (top, left))编码后嵌入模型,指导模型生成与裁剪操作一致的图像。
嵌入具体操作:
-
傅里叶编码:
- 输入:裁剪坐标
(top, left),通常归一化为[0, 1]。 - 编码:同样使用傅里叶特征:
。其中
- 编码后生成高维表示,捕捉坐标变化的细微差异。
- 输入:裁剪坐标
-
与模型嵌入融合:
- 编码结果通过线性映射,直接与时间步嵌入(Time Embedding)相加,形成额外的条件嵌入:
- 这种方式确保裁剪信息能够影响扩散过程中的每个时间步,指导模型生成裁剪特征一致的图像。
- 编码结果通过线性映射,直接与时间步嵌入(Time Embedding)相加,形成额外的条件嵌入:
傅里叶编码的优点
-
捕捉连续变化:
- 原始坐标和尺寸是低维的连续变量,傅里叶编码将它们映射到高维空间,允许模型捕捉更多的细节和变化模式。
- 高频分量能反映小幅度变化,低频分量反映全局趋势。
-
避免信息丢失:
- 简单使用低维坐标可能导致模型难以学习不同尺寸或裁剪操作间的细微差别。
- 傅里叶编码通过周期性函数丰富了特征表示,降低了信息压缩带来的偏差。
频率基是一组离散的频率值,通常表示为
(如
),用来控制傅里叶编码的正弦和余弦函数的周期。
嵌入位置总结
-
图像尺寸条件化:
- 将傅里叶编码后的尺寸信息作为全局条件,与时间步嵌入或扩散过程中的特定层嵌入相加。
- 目标:增强模型对全图尺寸变化的适应性。
-
图像裁剪条件化:
- 将傅里叶编码后的裁剪坐标嵌入时间步条件向量,指导模型在扩散的每一步中考虑裁剪操作的影响。
- 目标:学习裁剪对局部和全局特征分布的影响,提升生成一致性。
历史文章
Stable Diffusion概要讲解-CSDN博客
Stable diffusion详细讲解-CSDN博客
Stable Diffusion的加噪和去噪详解-CSDN博客
Diffusion Model 原理-CSDN博客
Stable Diffusion核心网络结构——VAE-CSDN博客
Stable Diffusion核心网络结构——CLIP Text Encoder-CSDN博客
Stable Diffusion核心网络结构——U-Net-CSDN博客
Stable Diffusion中U-Net的前世今生与核心知识-CSDN博客



















