图论理论基础
https://www.programmercarl.com/kamacoder/%E5%9B%BE%E8%AE%BA%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html
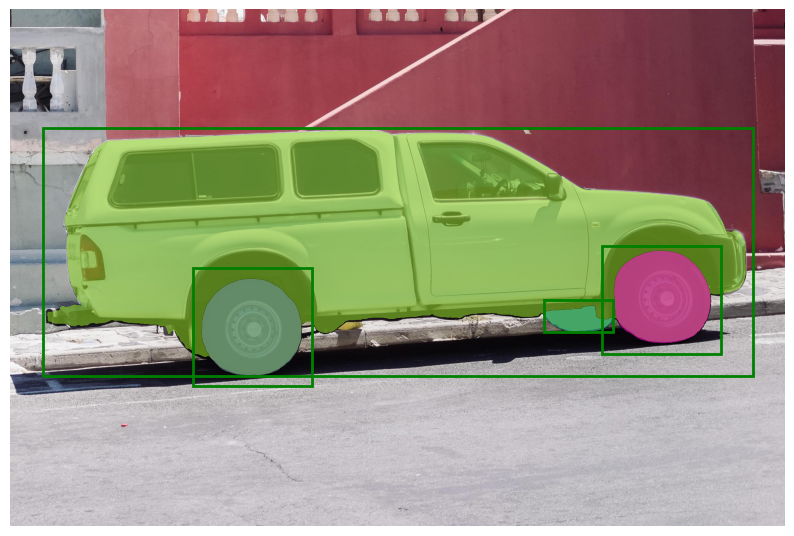
图的基本概念
二维坐标中,两点可以连成线,多个点连成的线就构成了图。
当然图也可以就一个节点,甚至没有节点(空图)
图的种类
整体上一般分为 有向图 和 无向图。
有向图是指 图中边是有方向的
无向图是指 图中边没有方向
加权有向图,就是图中边是有权值的,例如:
加权无向图也是同理。
度
无向图中有几条边连接该节点,该节点就有几度。
在有向图中,每个节点有出度和入度。
出度:从该节点出发的边的个数。
入度:指向该节点边的个数。
连通性
在图中表示节点的连通情况,我们称之为连通性。
连通图
在无向图中,任何两个节点都是可以到达的,我们称之为连通图
如果有节点不能到达其他节点,则为非连通图.
强连通图
在有向图中,任何两个节点是可以相互到达的,我们称之为 强连通图。
无向图中的连通图有什么区别,不是一样的吗?
强连通图是在有向图中任何两个节点是可以相互到达
下面这个有向图才是强连通图:
连通分量
在无向图中的极大连通子图称之为该图的一个连通分量。
强连通分量
在有向图中极大强连通子图称之为该图的强连通分量。
图的构造
我们如何用代码来表示一个图呢?
一般使用邻接表、邻接矩阵 或者用类来表示。
主要是 朴素存储、邻接表和邻接矩阵。
邻接矩阵
邻接矩阵 使用 二维数组来表示图结构。 邻接矩阵是从节点的角度来表示图,有多少节点就申请多大的二维数组。
在一个 n (节点数)为8 的图中,就需要申请 8 * 8 这么大的空间。、
这种表达方式(邻接矩阵) 在 边少,节点多的情况下,会导致申请过大的二维数组,造成空间浪费。
而且在寻找节点连接情况的时候,需要遍历整个矩阵,即 n * n 的时间复杂度,同样造成时间浪费。
邻接矩阵的优点:
- 表达方式简单,易于理解
- 检查任意两个顶点间是否存在边的操作非常快
- 适合稠密图,在边数接近顶点数平方的图中,邻接矩阵是一种空间效率较高的表示方法。
缺点:
- 遇到稀疏图,会导致申请过大的二维数组造成空间浪费 且遍历 边 的时候需要遍历整个n * n矩阵,造成时间浪费
邻接表
邻接表 使用 数组 + 链表的方式来表示。 邻接表是从边的数量来表示图,有多少边 才会申请对应大小的链表。
邻接表的优点:
- 对于稀疏图的存储,只需要存储边,空间利用率高
- 遍历节点连接情况相对容易
缺点:
- 检查任意两个节点间是否存在边,效率相对低,需要 O(V)时间,V表示某节点连接其他节点的数量。
- 实现相对复杂,不易理解
图的遍历方式
图的遍历方式基本是两大类:
- 深度优先搜索(dfs)
- 广度优先搜索(bfs)
在讲解二叉树章节的时候,其实就已经讲过这两种遍历方式。
二叉树的递归遍历,是dfs 在二叉树上的遍历方式。
二叉树的层序遍历,是bfs 在二叉树上的遍历方式。
dfs 和 bfs 一种搜索算法,可以在不同的数据结构上进行搜索,在二叉树章节里是在二叉树这样的数据结构上搜索。
而在图论章节,则是在图(邻接表或邻接矩阵)上进行搜索。
深搜理论基础
https://www.programmercarl.com/kamacoder/%E5%9B%BE%E8%AE%BA%E6%B7%B1%E6%90%9C%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html
dfs 与 bfs 区别
提到深度优先搜索(dfs),就不得不说和广度优先搜索(bfs)有什么区别
先来了解dfs的过程
先说一下dfs和bfs大概的区别:
- dfs是可一个方向去搜,不到黄河不回头,直到遇到绝境了,搜不下去了,再换方向(换方向的过程就涉及到了回溯)。
- bfs是先把本节点所连接的所有节点遍历一遍,走到下一个节点的时候,再把连接节点的所有节点遍历一遍,搜索方向更像是广度,四面八方的搜索过程。
当然以上讲的是,大体可以这么理解,接下来 我们详细讲解dfs
dfs 搜索过程
- 搜索方向,是认准一个方向搜,直到碰壁之后再换方向
- 换方向是撤销原路径,改为节点链接的下一个路径,回溯的过程。
代码框架
正是因为dfs搜索可一个方向,并需要回溯,所以用递归的方式来实现是最方便的。
有递归的地方就有回溯,那么回溯在哪里呢?
就递归函数的下面,例如如下代码:
void dfs(参数) {
处理节点
dfs(图,选择的节点); // 递归
回溯,撤销处理结果
}
可以看到回溯操作就在递归函数的下面,递归和回溯是相辅相成的。
在讲解二叉树章节的时候,二叉树的递归法其实就是dfs,而二叉树的迭代法,就是bfs(广度优先搜索)
所以dfs,bfs其实是基础搜索算法,也广泛应用与其他数据结构与算法中。
我们在回顾一下回溯法的代码框架:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
回溯算法,其实就是dfs的过程,这里给出dfs的代码框架:
void dfs(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本节点所连接的其他节点) {
处理节点;
dfs(图,选择的节点); // 递归
回溯,撤销处理结果
}
}
可以发现dfs的代码框架和回溯算法的代码框架是差不多的。
深搜三部曲
在 二叉树递归讲解中,给出了递归三部曲。
回溯算法讲解中,给出了 回溯三部曲。
其实深搜也是一样的,深搜三部曲如下:
- 确认递归函数,参数
void dfs(参数)
通常我们递归的时候,我们递归搜索需要了解哪些参数,其实也可以在写递归函数的时候,发现需要什么参数,再去补充就可以。
一般情况,深搜需要 二维数组数组结构保存所有路径,需要一维数组保存单一路径,这种保存结果的数组,我们可以定义一个全局变量,避免让我们的函数参数过多。
例如这样:
vector<vector<int>> result; // 保存符合条件的所有路径
vector<int> path; // 起点到终点的路径
void dfs (图,目前搜索的节点)
但这种写法看个人习惯,不强求。
- 确认终止条件
终止条件很重要,很多同学写dfs的时候,之所以容易死循环,栈溢出等等这些问题,都是因为终止条件没有想清楚。
if (终止条件) {
存放结果;
return;
}
终止添加不仅是结束本层递归,同时也是我们收获结果的时候。
另外,其实很多dfs写法,没有写终止条件,其实终止条件写在了, 下面dfs递归的逻辑里了,也就是不符合条件,直接不会向下递归。这里如果大家不理解的话,没关系,后面会有具体题目来讲解。
- 处理目前搜索节点出发的路径
一般这里就是一个for循环的操作,去遍历 目前搜索节点 所能到的所有节点。
for (选择:本节点所连接的其他节点) {
处理节点;
dfs(图,选择的节点); // 递归
回溯,撤销处理结果
}
98. 所有可达路径
https://www.programmercarl.com/kamacoder/0098.%E6%89%80%E6%9C%89%E5%8F%AF%E8%BE%BE%E8%B7%AF%E5%BE%84.html
思路
#include <stdio.h>
#include <stdlib.h>
#define MAX_NODES 100
// 图的结构体
typedef struct Graph {
int edges[MAX_NODES][MAX_NODES]; // 邻接矩阵
int indegree[MAX_NODES]; // 入度数组
int vertexCount; // 节点数量
} Graph;
// 深度优先搜索递归函数
void DFS(Graph *G, int node, int destination, int *path, int pathLen) {
path[pathLen] = node; // 将当前节点添加到路径中
pathLen++; // 增加路径长度
if (node == destination) { // 找到一条路径
// 输出路径
for (int i = 0; i < pathLen; i++) {
printf("%d", path[i]);
if (i < pathLen - 1) printf(" "); // 添加空格
}
printf("\n");
} else {
// 继续深度搜索
for (int next = 1; next <= G->vertexCount; next++) {
if (G->edges[node][next]) { // 如果存在边
DFS(G, next, destination, path, pathLen);
}
}
}
pathLen--; // 回溯
}
int main() {
Graph G;
int N, M;
scanf("%d %d", &N, &M);
// 初始化图
G.vertexCount = N;
for (int i = 1; i <= N; i++) {
G.indegree[i] = 0; // 初始化入度
for (int j = 1; j <= N; j++) {
G.edges[i][j] = 0; // 初始化邻接矩阵
}
}
// 读入每条边
for (int i = 0; i < M; i++) {
int s, t;
scanf("%d %d", &s, &t);
G.edges[s][t] = 1; // 建立有向边
}
int path[MAX_NODES]; // 存储路径
DFS(&G, 1, N, path, 0); // 从1到N进行DFS
return 0;
}学习反思
这段代码实现了一个基于深度优先搜索的图遍历算法。下面对代码进行一些学习反思:Graph结构体表示了一个图,包含了图的边和顶点的入度信息以及顶点数量。DFS函数实现了深度优先搜索算法,它通过递归的方式遍历图中的所有路径,并找到到达目标节点的路径。参数node表示当前节点,destination表示目标节点,path和pathLen表示当前路径和路径长度。在递归过程中,先将当前节点加入到路径中,然后判断是否达到目标节点,如果是则打印路径,否则继续向下一个节点递归。main函数中首先读取图的顶点数量和边的数量,并根据输入初始化图的数据结构。然后调用DFS函数进行图遍历。在DFS函数中,需要传入一个存储路径的数组path和路径长度pathLen,这样可以在递归过程中记录路径。最后,将起始节点设置为1,目标节点设置为N,路径长度为0进行递归调用。