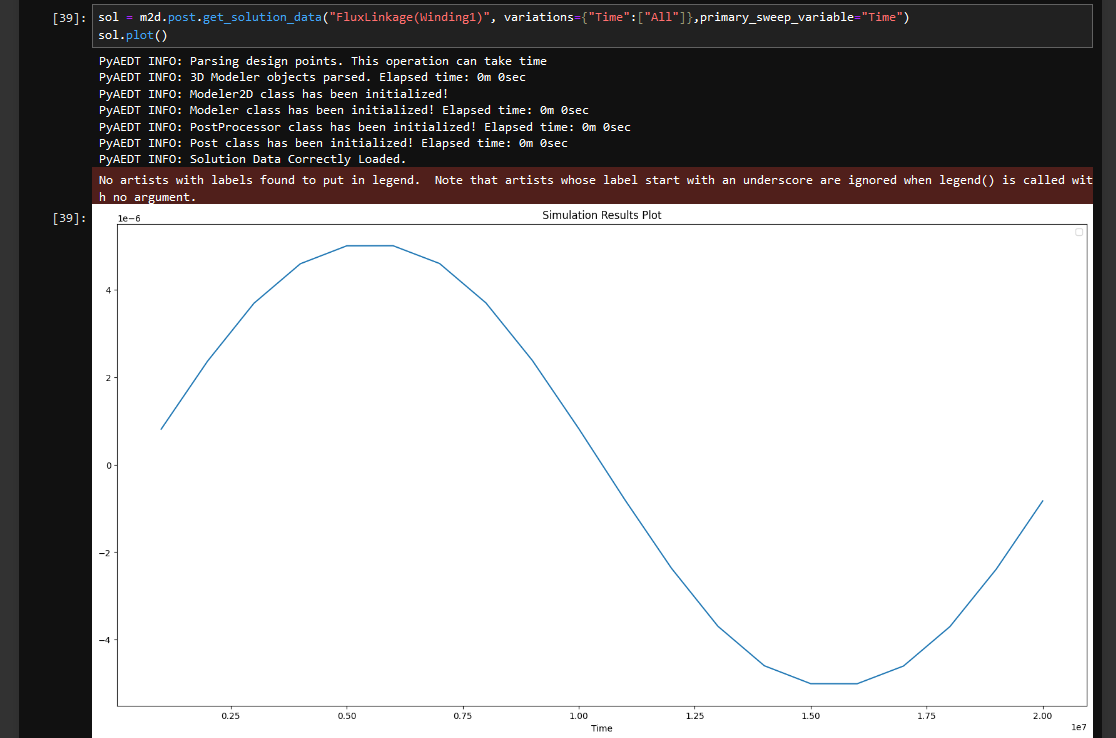
文件地址
https://github.com/yanx27/Pointnet_Pointnet2_pytorch?spm=5176.28103460.0.0.21a95d27ollfze
Pointnet_Pointnet2_pytorch\log\classification\pointnet2_ssg_wo_normals文件夹改名为Pointnet_Pointnet2_pytorch\log\classification\pointnet2_cls_ssg
"E:\Pointnet_Pointnet2_pytorch\provider.py" 在provider.py文件头添加
def pc_normalize(pc):
l = pc.shape[0]
centroid = np.mean(pc, axis=0)
pc = pc - centroid
m = np.max(np.sqrt(np.sum(pc**2, axis=1)))
pc = pc / m
return pc详细介绍了如何从视频帧中生成点云数据并使用PointNet++模型提取特征,最后将特征保存下来。
从视频帧中生成点云数据并提取特征
1. 引言
在计算机视觉领域,点云数据是一种重要的三维数据形式,广泛应用于自动驾驶、机器人导航、物体识别等场景。本文将详细介绍如何从视频帧中生成点云数据,并使用PointNet++模型提取特征,最后将特征保存下来以供后续分析或使用。
2. 环境准备
在开始之前,确保你的环境中安装了以下依赖项:
Python 3.6+
PyTorch 1.7+
Open3D
OpenCV
NumPy
你可以使用以下命令安装这些依赖项:
pip install torch torchvision
pip install open3d opencv-python numpy
3. 代码实现
import os
import sys
# 获取当前脚本所在的目录
current_dir = os.path.dirname(os.path.abspath(__file__))
# 将 models 目录添加到 sys.path
sys.path.insert(0, os.path.join(current_dir, 'models'))
import numpy as np
import torch
import cv2
import open3d as o3d
from models.pointnet2_cls_ssg import get_model
from provider import pc_normalize
import time
import hashlib
# 打印 sys.path 以确认路径是否正确
print(sys.path)
# 设置设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"设备设置为: {device}")
# 加载预训练模型
#"E:\Pointnet_Pointnet2_pytorch\log\classification\pointnet2_cls_ssg\checkpoints\best_model.pth"
model_path = os.path.join('log', 'classification', 'pointnet2_cls_ssg', 'checkpoints', 'best_model.pth') # 替换为实际路径
print(f"加载预训练模型: {model_path}")
model = get_model(num_class=40, normal_channel=False).to(device)
# 只加载模型参数
checkpoint = torch.load(model_path, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
model.eval()
print("模型加载完成")
# 从视频帧生成点云数据
def frame_to_point_cloud(frame, depth_frame=None):
if depth_frame is None:
# 如果没有深度图,使用随机生成的点云数据作为示例
points = np.random.rand(1024, 3) # 生成 1024 个点,每个点有 3 个坐标
else:
# 使用深度图生成点云
h, w = depth_frame.shape
y, x = np.indices((h, w))
z = depth_frame
points = np.stack([x, y, z], axis=-1).reshape(-1, 3)
points = points[~np.isnan(points).any(axis=1)] # 去除无效点
if points.shape[0] > 1024:
points = points[np.random.choice(points.shape[0], 1024, replace=False)]
elif points.shape[0] < 1024:
points = np.pad(points, ((0, 1024 - points.shape[0]), (0, 0)), mode='constant')
print(f"生成点云数据: {points.shape}")
return points
# 提取特征
def extract_features(model, point_cloud):
point_cloud = pc_normalize(point_cloud) # 归一化点云
point_cloud = torch.from_numpy(point_cloud).float().unsqueeze(0).transpose(2, 1).to(device)
with torch.no_grad():
pred, trans_feat = model(point_cloud) # 只接收两个返回值
print(f"提取特征完成: {pred.shape}")
return pred.cpu().numpy()
# 处理单个视频文件
def process_video(video_path, output_folder):
cap = cv2.VideoCapture(video_path)
frame_count = 0
video_name = os.path.basename(video_path).split('.')[0]
print(f"开始处理视频: {video_path}")
all_features = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 生成点云数据
point_cloud = frame_to_point_cloud(frame)
if point_cloud.shape[0] < 1024: # 确保至少有 1024 个点
print(f"帧 {frame_count} 点云数据不足,跳过")
continue # 如果点不够,跳过此帧
# 提取特征
features = extract_features(model, point_cloud)
print(f"处理帧 {frame_count} 特征: {features}")
# 保存特征到 all_features 列表中
all_features.append(features)
frame_count += 1
cap.release()
print(f"视频处理完成: {video_path}")
# 生成唯一的文件名
output_file = os.path.join(output_folder, f'{video_name}_features.npy')
# 将所有特征保存到一个文件中
np.save(output_file, np.vstack(all_features))
print(f"特征已保存到: {output_file}")
# 检查视频文件是否已处理
def is_video_processed(video_path, processed_videos):
video_hash = hashlib.md5(video_path.encode()).hexdigest()
return video_hash in processed_videos
# 获取已处理的视频文件列表
def get_processed_videos(output_file):
if not os.path.exists(output_file):
return set()
processed_videos = set()
with open(output_file, 'r') as f:
for line in f:
processed_videos.add(line.strip())
return processed_videos
# 记录已处理的视频文件
def record_processed_video(video_path, output_file):
video_hash = hashlib.md5(video_path.encode()).hexdigest()
with open(output_file, 'a') as f:
f.write(video_hash + '\n')
# 处理视频文件夹
def process_video_folder(folder_path, output_folder):
processed_videos_file = os.path.join(output_folder, 'processed_videos.txt')
processed_videos = get_processed_videos(processed_videos_file)
print(f"开始处理视频文件夹: {folder_path}")
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.endswith('.mp4') or file.endswith('.avi'):
video_path = os.path.join(root, file)
if is_video_processed(video_path, processed_videos):
print(f"视频已处理,跳过: {video_path}")
continue
process_video(video_path, output_folder)
record_processed_video(video_path, processed_videos_file)
print("所有视频处理完成")
# 主程序
if __name__ == "__main__":
# 视频文件夹路径
input_folder = r'E:\Pointnet_Pointnet2_pytorch\data\voide'
output_folder = r'E:\Pointnet_Pointnet2_pytorch\data\voide_features' # 特征保存路径
# 确保输出文件夹存在
os.makedirs(output_folder, exist_ok=True)
# 处理视频文件夹
process_video_folder(input_folder, output_folder)
3.1 导入必要的库
首先,我们需要导入一些必要的库,包括文件操作、数值计算、深度学习框架、图像处理和点云处理相关的库。
3.2 设置设备
检查是否有可用的GPU,并设置设备。如果存在GPU,将使用GPU进行计算;否则,使用CPU。
3.3 加载预训练模型
我们使用PointNet++模型来提取点云特征。首先,加载预训练模型。这通常涉及以下几个步骤:
指定模型路径:提供预训练模型的路径。
加载模型:使用 get_model 函数创建模型实例,并将其移动到指定的设备(CPU或GPU)。
加载模型参数:从预训练模型文件中加载模型参数,并设置模型为评估模式。
3.4 从视频帧生成点云数据
定义一个函数 frame_to_point_cloud,该函数从视频帧中生成点云数据。如果没有深度图,可以生成随机点云数据作为示例。具体步骤如下:
生成随机点云:如果没有深度图,生成1024个随机点,每个点有3个坐标。
使用深度图生成点云:如果有深度图,从深度图中提取点云数据。具体做法是将深度图的每个像素位置(x, y)和对应的深度值z组合成一个三维点(x, y, z)。然后,去除无效点,并确保点云数据的形状为 (1024, 3)。
3.5 提取特征
定义一个函数 extract_features,该函数使用预训练模型提取点云数据的特征。具体步骤如下:
归一化点云:对点云数据进行归一化处理,使其适合输入到模型中。
转换为张量:将点云数据转换为PyTorch张量,并移动到指定的设备。
提取特征:使用预训练模型提取特征,并返回特征向量。
3.6 处理单个视频文件
定义一个函数 process_video,该函数处理单个视频文件,逐帧生成点云数据并提取特征。具体步骤如下:
打开视频文件:使用OpenCV的 cv2.VideoCapture 打开视频文件。
读取帧:逐帧读取视频。
生成点云数据:调用 frame_to_point_cloud 函数生成点云数据。
提取特征:调用 extract_features 函数提取特征。
保存特征:将提取的特征保存为 .npy 文件。
3.7 处理视频文件夹
定义一个函数 process_video_folder,该函数处理指定文件夹中的所有视频文件。具体步骤如下:
遍历文件夹:使用 os.walk 遍历指定文件夹中的所有视频文件。
处理每个视频:调用 process_video 函数处理每个视频文件。
3.8 主程序
在主程序中,指定输入视频文件夹和输出特征文件夹的路径,并调用 process_video_folder 函数处理所有视频文件。
4. 总结
本文详细介绍了如何从视频帧中生成点云数据,并使用PointNet++模型提取特征,最后将特征保存下来。通过这些步骤,你可以将视频数据转换为点云数据,并提取有用的特征,为后续的分析和应用提供支持。