欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/143749468
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。

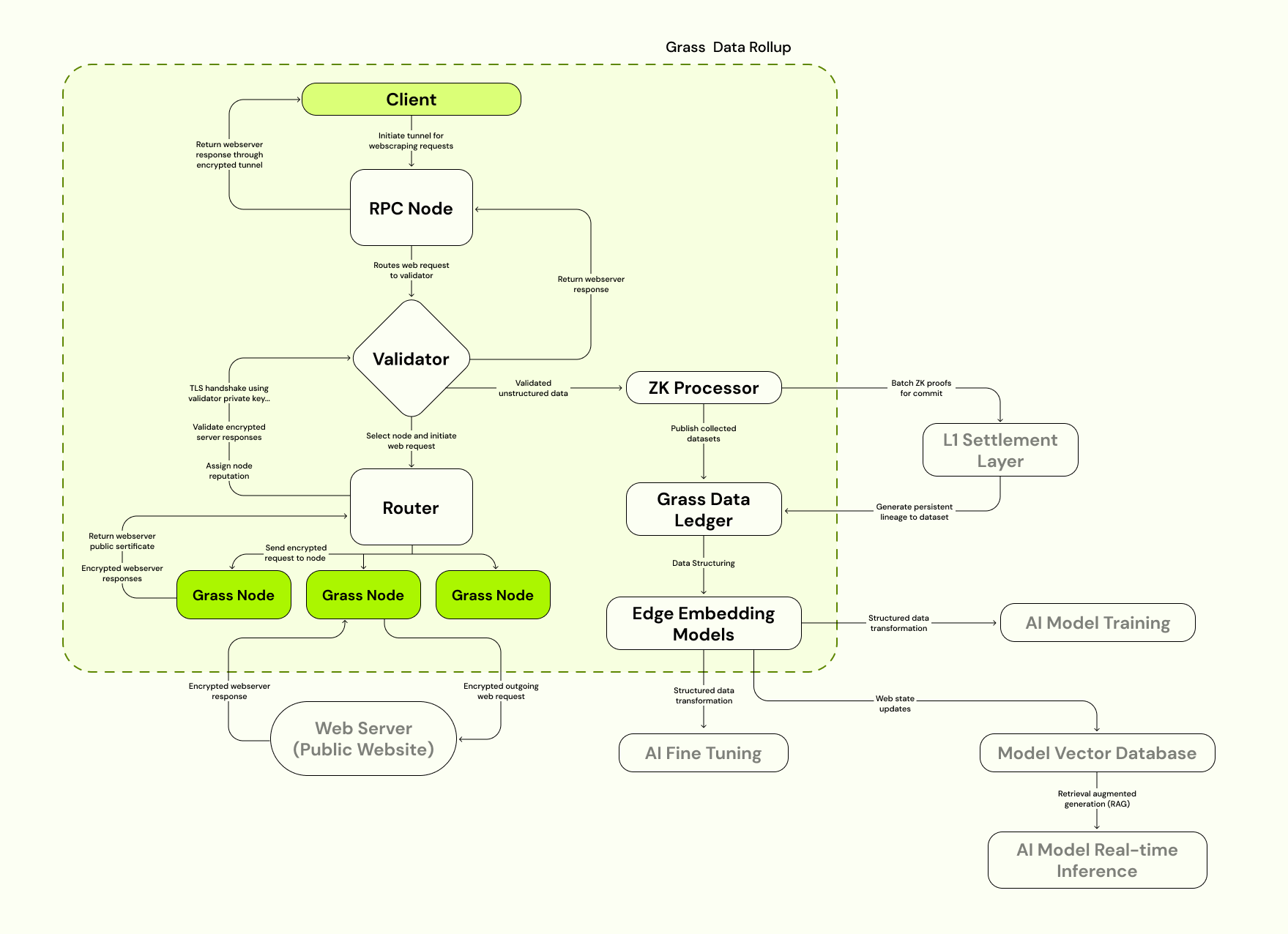
影响 (多模态)大语言模型 参数量的主要网络模块,即 Linear、Embedding、Norm(LayerNorm or RMSNorm) 等 3 个部分,其中,多模态大模型还包括 Conv3D,手动计算参数量,与 PyTorch 直接计算保持一致。
PyTorch 源码:
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
以 Qwen2-VL-7B-Instruct 、Qwen2-7B-Instruct、Llama-3.1-8B-Instruct 为例。
网络结构参数量:
- Linear:参数矩阵,或者加上
bias,Linear(in_features=w, out_features=h, bias=True)参数量是x=w*h+h,当bias=False, 则是x=w*h。 - Embedding:认为是没有 bias 的 Linear。
- Norm:
- LayerNorm 包括 2 个可训练参数
γ
\gamma
γ 和
β
\beta
β,假设
hidden_size的大小为 h,hidden_size每一维都有两个参数,即2*hidden_size - RMSNorm 每 1 维则只有 1 个可训练参数 , 即
hidden_size
- LayerNorm 包括 2 个可训练参数
γ
\gamma
γ 和
β
\beta
β,假设
- Conv3D:即
Conv3d(3, 1280, kernel_size=(2, 14, 14), stride=(2, 14, 14), bias=False),即参数量=输入维度*输出维度*卷积核,3*1280*2*14*14=1505280 - RotaryEmbedding、Activition 和 Dropout:旋转位置编码、激活函数、Dropout 都没有可训练参数
Llama-3.1-8B-Instruct 参数量:
128256 ∗ 4096 + 32 ∗ ( 4096 ∗ 4096 ∗ 2 + 4096 ∗ 1024 ∗ 2 + 4096 ∗ 14336 ∗ 3 + 2 ∗ 4096 ) + 4096 + 4096 ∗ 128256 = 8030261248 = 8 B 128256*4096 + 32*(4096*4096*2 + 4096*1024*2 + 4096*14336*3 + 2*4096) + 4096 + 4096*128256 = 8030261248 = 8B 128256∗4096+32∗(4096∗4096∗2+4096∗1024∗2+4096∗14336∗3+2∗4096)+4096+4096∗128256=8030261248=8B
即:
P a r a m e t e r s = E m b e d d i n g + l a y e r s ∗ ( L i n e a r Q K V O + L i n e a r m l p + R M S N o r m ) + R M S N o r m + L i n e a r Parameters = Embedding + layers*(Linear_{QKVO} + Linear_{mlp}+RMSNorm) + RMSNorm + Linear Parameters=Embedding+layers∗(LinearQKVO+Linearmlp+RMSNorm)+RMSNorm+Linear
计算参数量:[Info] parameters: 8030261248
大语言模型 Llama-3.1-8B-Instruct 的网络结构:
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=128256, bias=False)
)
多模态视觉大模型 Qwen2-VL-7B-Instruct 的网络结构:
Qwen2VLForConditionalGeneration(
(visual): Qwen2VisionTransformerPretrainedModel(
(patch_embed): PatchEmbed(
(proj): Conv3d(3, 1280, kernel_size=(2, 14, 14), stride=(2, 14, 14), bias=False)
)
(rotary_pos_emb): VisionRotaryEmbedding()
(blocks): ModuleList(
(0-31): 32 x Qwen2VLVisionBlock(
(norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(attn): VisionSdpaAttention(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(mlp): VisionMlp(
(fc1): Linear(in_features=1280, out_features=5120, bias=True)
(act): QuickGELUActivation()
(fc2): Linear(in_features=5120, out_features=1280, bias=True)
)
)
)
(merger): PatchMerger(
(ln_q): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
(mlp): Sequential(
(0): Linear(in_features=5120, out_features=5120, bias=True)
(1): GELU(approximate='none')
(2): Linear(in_features=5120, out_features=3584, bias=True)
)
)
)
(model): Qwen2VLModel(
(embed_tokens): Embedding(152064, 3584)
(layers): ModuleList(
(0-27): 28 x Qwen2VLDecoderLayer(
(self_attn): Qwen2VLSdpaAttention(
(q_proj): Linear(in_features=3584, out_features=3584, bias=True)
(k_proj): Linear(in_features=3584, out_features=512, bias=True)
(v_proj): Linear(in_features=3584, out_features=512, bias=True)
(o_proj): Linear(in_features=3584, out_features=3584, bias=False)
(rotary_emb): Qwen2VLRotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=3584, out_features=18944, bias=False)
(up_proj): Linear(in_features=3584, out_features=18944, bias=False)
(down_proj): Linear(in_features=18944, out_features=3584, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((3584,), eps=1e-06)
(rotary_emb): Qwen2VLRotaryEmbedding()
)
(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)
总参数量:[Info] parameters: 8291375616
- 视觉模型的参数量:
[Info] parameters model.visual: 675759104 - 语言模型的参数量:
[Info] parameters model.model: 7070619136+[Info] parameters model.lm_head: 544997376
即:675759104(8.15%) + 7070619136(85.28%) + 544997376(6.57%) = 8291375616 = 8B
Qwen2-VL-7B-Instruct 的 Qwen2VisionTransformerPretrainedModel 参数量:
patch_embed参数量:3*1280*2*14*14=1505280blocks参数量:[Info] parameters model.visual.blocks: 629678080- 详细计算公式:
32*(1280*2*2 + (1280+1)*3840 + (1280+1)*1280 + 1280*5121 + 5120*1281)=629678080
- 详细计算公式:
merger参数量:
合并计算公式:
3 ∗ 1280 ∗ 2 ∗ 14 ∗ 14 + 32 ∗ ( 1280 ∗ 2 ∗ 2 + ( 1280 + 1 ) ∗ 3840 + ( 1280 + 1 ) ∗ 1280 + 1280 ∗ 5121 + 5120 ∗ 1281 ) + 1280 ∗ 2 + 5120 ∗ 5121 + ( 5120 + 1 ) ∗ 3584 = 675759104 3*1280*2*14*14 + 32*(1280*2*2 + (1280+1)*3840 + (1280+1)*1280 + 1280*5121 + 5120*1281) + 1280*2 + 5120*5121 + (5120+1)*3584 \\ = 675759104 3∗1280∗2∗14∗14+32∗(1280∗2∗2+(1280+1)∗3840+(1280+1)∗1280+1280∗5121+5120∗1281)+1280∗2+5120∗5121+(5120+1)∗3584=675759104
Qwen2-VL-7B-Instruct 的 Qwen2VLModel 参数量:
152064 ∗ 3584 + 28 ∗ ( ( 3584 + 1 ) ∗ 3584 + ( 3584 + 1 ) ∗ 512 ∗ 2 + 3584 ∗ 3584 + 3584 ∗ 18944 ∗ 3 + 2 ∗ 3584 ) + 3584 = 7070619136 3584 ∗ 152064 = 544997376 152064*3584 + 28*((3584+1)*3584 + (3584+1)*512*2 + 3584*3584 + 3584*18944*3 + 2*3584) + 3584 \\ = 7070619136 \\ 3584 * 152064 = 544997376 152064∗3584+28∗((3584+1)∗3584+(3584+1)∗512∗2+3584∗3584+3584∗18944∗3+2∗3584)+3584=70706191363584∗152064=544997376
因此,Qwen2-VL-7B 的数据量完全对齐。
测试:
# 预训练模型, 查看其词表大小
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
print(f"[Info] transformers version: {transformers.__version__}")
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
# ------------ Qwen2-VL-7B ----------- #
model_path = "[your path]/llm/Qwen/Qwen2-VL-7B-Instruct"
print(f"[Info] model_path: {model_path}")
# Load the model in half-precision on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_path, torch_dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained(model_path)
configuration = model.config
print(f"[Info] Qwen2-VL-7B vocab_size: {configuration.vocab_size}")
print(model)
print(f"[Info] parameters: {count_parameters(model)}")
print(f"[Info] parameters model.visual: {count_parameters(model.visual)}")
print(f"[Info] parameters model.model: {count_parameters(model.model)}")
print(f"[Info] parameters model.lm_head: {count_parameters(model.lm_head)}")
print(f"[Info] parameters model.visual.patch_embed: {count_parameters(model.visual.patch_embed)}")
print(f"[Info] parameters model.visual.blocks: {count_parameters(model.visual.blocks)}")
print(f"[Info] parameters model.visual.blocks[0].norm1: {count_parameters(model.visual.blocks[0].norm1)}")
print(f"[Info] parameters model.visual.blocks[0].norm2: {count_parameters(model.visual.blocks[0].norm2)}")
print(f"[Info] parameters model.visual.blocks[0].attn: {count_parameters(model.visual.blocks[0].attn)}")
print(f"[Info] parameters model.visual.blocks[0].mlp: {count_parameters(model.visual.blocks[0].mlp)}")
# ------------ Qwen2-VL-7B ----------- #
# ------------ Qwen2-7B ----------- #
model_path = "[your path]/llm/Qwen/Qwen2-7B-Instruct"
print(f"[Info] model_path: {model_path}")
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
print(f"[Info] Qwen2-7B vocab_size: {tokenizer.vocab_size}")
print(model)
print(f"[Info] parameters: {count_parameters(model)}")
# ------------ Qwen2-7B ----------- #
# ------------ Llama-3.1-8B ----------- #
model_path = "[your path]/llm/Meta-Llama-3.1-8B-Instruct"
print(f"[Info] model_path: {model_path}")
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
print(f"[Info] Llama-3.1-8B vocab_size: {tokenizer.vocab_size}")
print(model)
print(f"[Info] parameters: {count_parameters(model)}")
# ------------ Llama-3.1-8B ----------- #
Qwen2-7B 的参数量是 7615616512,即 7070619136 + 544997376 = 7615616512
参考:
- 大模型的参数量是如何计算的
- 大模型参数量如何计算
- 如何根据模型结构,计算大模型的参数量?