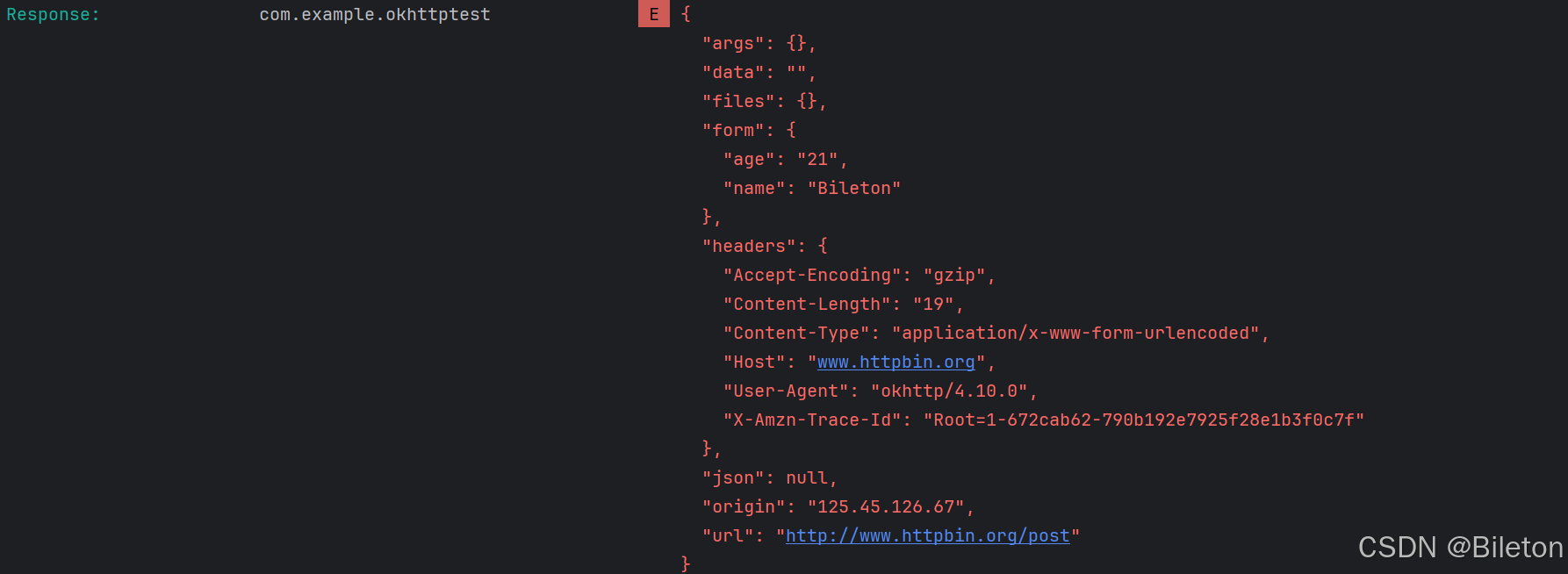
在大数据技术的快速发展中,Apache Spark凭借其高效的内存计算和友好的编程模型,成为了现代数据处理领域中的一颗耀眼明星。Spark的出现填补了批处理和实时处理之间的空白,使得数据分析任务能够以前所未有的速度和效率得以执行。本文将深入剖析Apache Spark的技术原理、架构特点及其在大数据生态中的重要作用。
1. Spark的诞生与发展
Apache Spark起源于加州大学伯克利分校的AMPLab(Algorithms, Machines, and People Laboratory),其主要目标是克服传统MapReduce在交互式查询和流处理上的不足。自2010年发布以来,Spark迅速受到业界的关注,并在2014年成为Apache的顶级项目。由于其高速的数据处理能力,Spark广泛应用于多种数据分析场景和行业。
2. Spark的核心概念
Spark的核心概念包括弹性分布式数据集(Resilient Distributed Dataset, RDD)、数据帧(DataFrame)、以及数据集(Dataset)。这些概念为Spark提供了统一的抽象和API,使得分布式计算更加直观。
-
RDD (Resilient Distributed Dataset):Spark的基本抽象,是一个只读的分区记录集合。RDD具备容错性,即使在节点失败的情况下也能通过血缘关系(Lineage)重新计算缺失的数据。用户可以通过在RDD上应用转换(Transformation)和动作(Action)来进行数据操作。
-
DataFrame:在RDD之上提供的一种更高级的数据抽象,与数据库中的表格类似。DataFrame在Spark SQL模块中具有更优化的执行计划,并支持SQL查询,适合结构化数据处理。
-
Dataset:结合RDD和DataFrame优点的抽象,提供类型安全的编程接口。Dataset API允许开发者轻松执行复杂运算,同时保持编译时类型检查。
3. Spark的架构与组件
Spark的架构高度模块化,主要由以下几大组件组成:
-
Spark Core:Spark的基本计算引擎,负责任务调度、内存管理、容错处理等。Core模块支持对各种数据源的访问,并提供RDD API。
-
Spark SQL:处理结构化数据的模块,提供DataFrame和SQL查询接口,支持与Hive的互操作。
-
Spark Streaming:用于实时数据处理,能够将流数据切分为小批数据块,进行分布式计算。
-
MLlib:Spark的机器学习库,包含常用的机器学习算法(如分类、回归、聚类等)以及数据处理工具。
-
GraphX:图计算引擎,支持构建和操作图结构的数据。
-
SparkR:Spark对R语言的支持,方便数据科学家在Spark上执行R脚本。
4. Spark的执行流程
Spark的执行流程主要分为以下几个步骤:
-
任务提交:用户通过Driver程序向Spark集群提交应用程序。Driver负责分析用户代码,生成DAG(Directed Acyclic Graph)计划。
-
任务划分:DAG Scheduler将DAG划分为多个阶段(Stage),每个阶段包含若干任务(Task),这些任务将在executor上并行执行。
-
任务调度:Task Scheduler根据可用资源,将任务分配到相应的excutor上。
-
任务执行:各executor执行具体任务,并将结果返回给Driver。
-
结果收集:Driver汇集各个任务的结果,最终生成应用的输出。
5. Spark的内存管理与性能优化
Spark的高效性部分得益于其对内存的利用。内存管理是Spark性能优化的关键:
-
缓存(Cache)机制:Spark能够将数据集的中间结果缓存至内存中,以便快速进行后续计算,减少I/O操作。
-
持久化(Persist)机制:用户可以选择不同的持久化级别(如MEMORY_ONLY,MEMORY_AND_DISK等)来控制RDD的存储方式,以优化性能和资源利用。
-
Tungsten计划:Spark采用的内存及CPU利用优化方案,通过避免Java对象的高开销操作,进一步提高执行效率。
6. Spark Streaming:实时数据处理的利器
与传统的批处理不同,Spark Streaming通过将实时数据流分成小批次,以近乎实时的方式处理数据。尽管流计算与批处理相似,但其基于DStream(Discretized Stream)抽象,支持时间窗口操作、状态管理等。
Spark Streaming能够无缝集成Kafka、Flume、HDFS等流数据源,为实时数据分析提供强大支持。
7. MLlib:面向机器学习的强大工具
MLlib是Spark的机器学习库,也是Spark生态中迅速发展的组成部分。它提供了丰富的机器学习算法和实用工具:
- 分类与回归:如逻辑回归、支持向量机、线性回归等。
- 聚类:如K-Means、Gaussian混合模型等。
- 协同过滤:如隐语义模型(ALS)用于推荐系统。
- 特征转换:提供标准化、归一化、主成分分析等功能。
- 模型评估:如交叉验证、网格搜索等。
MLlib的高性能和简洁API使得在大规模数据集上实现机器学习任务变得快速而简单。
8. Spark的生态与应用场景
Spark不仅是一个高效的计算引擎,它还构建了一个庞大的数据处理生态。通过与Amazon AWS、Google Cloud Platform、Microsoft Azure等云服务集成,Spark能够在云环境中轻松部署和扩展。
Spark擅长处理各种应用场景:
- 交互式数据分析:结合Spark SQL,支持使用SQL进行数据挖掘与探索。
- 实时情报获取:使用Spark Streaming进行实时数据的监测与分析。
- 大规模机器学习:通过MLlib快速构建和训练模型。
- 批量数据处理:善于处理来自HDFS、S3等大规模数据集的批处理任务。
- 图分析:使用GraphX进行社交网络、链接分析等。
9. Spark面临的挑战与前景
尽管Spark具备多方面的优势,但在实际应用中也面临一些挑战:
- 资源管理与调度:特别在大型集群中,如何更灵活地调度资源是个难题。
- 深度学习支持:尽管MLlib支持许多机器学习算法,但在深度学习领域仍需更紧密的集成。
- 跨平台兼容:支持与更多数据源和工具集成,提高兼容性与易用性。
然而,随着技术的不断进步,特别是对深度学习流行度的上升以及对实时性需求的增加,Spark在未来将继续扮演关键角色,推动大数据分析的演进。
在总结中,Apache Spark以其卓越的性能和灵活性为用户提供了高效的分布式数据处理能力。无论是在大规模数据分析、实时数据处理还是机器学习应用中,Spark都展现了巨大的潜力与价值。在技术潮流的推动下,Spark将继续引领创新潮头,推进数据驱动的革命。