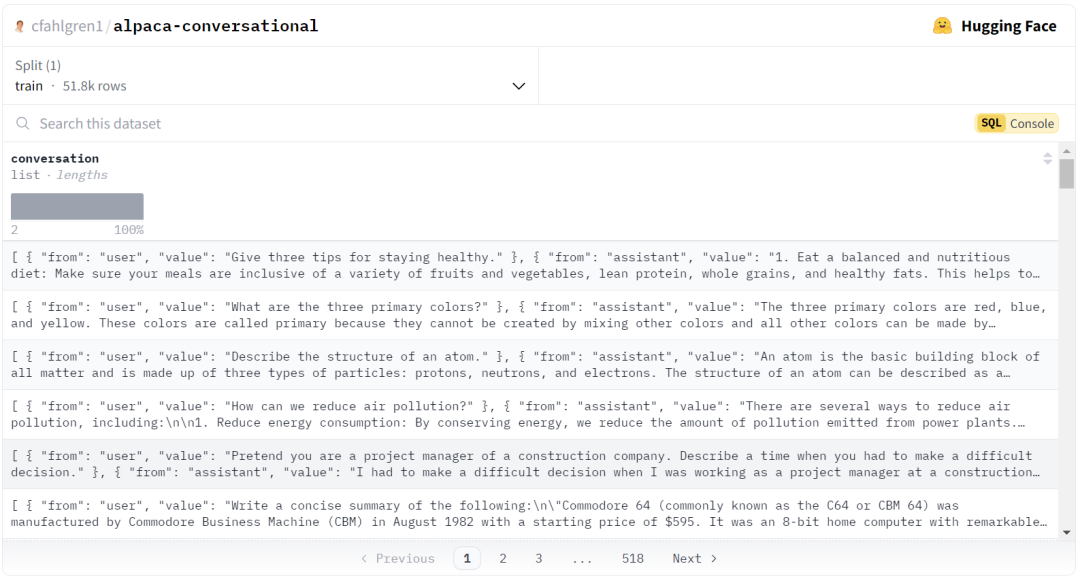
目录
一、合并两个有序链表
二、链表分割
三、链表的回文结构
u解题的总体思路:
合并两个有序链表:首先创建新链表的头节点(哨兵位:本质上是占位子),为了减少一些判断情况,简化操作。然后我们再创建俩个指针分别指针两个单链表的头,然后遍历比较,将两个指针指向节点的最小值接在新链表的后面。
链表分割:创建两个新链表lessHead和greatHead,一个存储原链表中小于x的节点,一个存储其他的节点,我们按顺序遍历原链表:当循环结束后,我们将存储小于x的节点的新链表lessHead接在另一个新链表greatHead的前面。
链表的回文结构:我们利用前面OJ题中的方法,找中间节点(快慢指针),反转链表(三指针法)解这道题,我们找到中间节点后,将中间节点后面的节点的指向反转,然后我们遍历这个反转后的链表与原链表比较,看是否满足条件。
一、合并两个有序链表

步骤1:
我们新建一个链表,初始化NewHead,NewTail三个指针都指向头节点NewList,然后,我们创建指针l1,l2分别指向list1和list2.

步骤2:当l1和l2指向的节点都不为NULL,循环遍历节点,将最小值的节点接在新链表的后面,然后NewTail指向新链表的最后的节点位置上。

步骤3:
我们将l1和l2指向链表节点不为NULL的接在NewTail的next域上,就完成了合并操作。

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
ListNode *l1 = list1,*l2 = list2;
ListNode *NewList = (ListNode*)malloc(sizeof(ListNode)); //创建头节点
ListNode * NewHead, *NewTail;
NewHead = NewTail = NewList; //初始化俩个指针都指向新链表
//l1 和 l2 当前节点都不为NULL,遍历
while(l1 && l2){
if(l1->val < l2->val){
NewTail->next = l1;
l1 = l1->next; //l1往后走
}else{
NewTail->next = l2;
l2 = l2->next; //l2往后走
}
NewTail = NewTail->next; //更新NewTail 指向当前新插入的节点
}
//两者有一个为NULL(不可能同时为NULL)
if(l1!=NULL){
NewTail->next=l1;
}else{
NewTail->next=l2;
}
return NewList->next;
}二、链表分割
 步骤1:
步骤1:
我们首先创建两个新的链表,lessHead存储节点值< x的节点,greatHead存储节点值>= x的节点。

步骤2:
我们循环原链表,将每个节点按照判断接在各自的新链表中。

步骤3:
我们将lessHead的lessTail的next域接在greatHead的next前面,这样我们就实现了两个新链表的拼接.(注意:最后要将greatTail的next域置为NULL,防止死循环)

/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
#include <functional>
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
ListNode *pcur = pHead;
//创建俩个头节点,分别存储小节点,和大节点
ListNode *lessHead = (ListNode*)malloc(sizeof(ListNode));
ListNode *lessTail = lessHead;
ListNode *greatHead = (ListNode*)malloc(sizeof(ListNode));
ListNode *greatTail = greatHead;
//循环遍历原链表中的每个节点
while(pcur){
if(pcur->val < x){
lessTail->next = pcur;
lessTail = lessTail->next; //尾指针后移当新插入的节点
}else{
greatTail->next = pcur;
greatTail = greatTail->next; //尾节点后移到新插入的节点
}
pcur = pcur->next;
}
//拼接两个新链表,将lessHead接入到greatHead后面
lessTail->next = greatHead->next;
greatTail->next = NULL; //将最后的节点next域置为NULL
return lessHead->next;
}
};三、链表的回文结构

步骤1:
我们首先写出找中间节点的函数middleNode,和反转链表的函数reverseList,找到中间节点,然后,将中间节点后面的链表反转。(这两个函数在上个文章中详细讲解过,这里不再重点讲述)
 步骤2:
步骤2:
反转以mid为头节点的链表。

从这里可以看出我们的链表变成了俩个部分,然后我们遍历这两个链表,比较各自节点的值是否相等,相等说明我们原链表就是回文链表。

/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class PalindromeList {
public:
//反转链表
ListNode* reverseList(ListNode* head){
ListNode*n1,*n2,*n3;
n1 = NULL;
n2 = head;
if(n2==NULL){
return NULL;
}
n3 = n2->next;
while(n2){
n2->next = n1;
n1 = n2;
n2 = n3;
if(n3)
n3 = n3->next;
}
return n1;
}
//找中间节点
ListNode* middleNode(ListNode* head){
if(head==NULL){
return NULL;
}
ListNode *slow,*fast;
slow = fast = head;
while(fast && fast->next){
slow = slow->next; //slow走一步
fast = fast->next->next; //fast走两步
}
return slow;
}
bool chkPalindrome(ListNode* A) {
ListNode*phead = A;
ListNode*mid = middleNode(A); //找中间节点
ListNode*pcur = reverseList(mid); //反转以中间节点为头的后面的节点
while(pcur){
if(pcur->val != phead->val){
return false;
}
pcur = pcur->next;
phead = phead->next;
}
//循环正常结束,返回true
return true;
}
};