在机器学习教学实践中,我们常会遇到这样一个问题:"模型表现非常出色,准确率超过90%!但当将其提交到隐藏数据集进行测试时,效果却大打折扣。问题出在哪里?"这种情况几乎总是与数据泄露有关。
当测试数据在数据准备阶段无意中泄露(渗透)到训练数据时,就会发生数据泄露。这种情况经常出现在常规数据处理任务中,而你可能并未察觉。当泄露发生时,模型会从本不应看到的测试数据中学习,导致测试结果失真。

数据泄露的定义
数据泄露是机器学习中的一个常见问题,发生在不应被模型看到的数据(如测试数据或未来数据)意外地被用于训练模型时。这可能导致模型过拟合,并在新的、未见数据上表现不佳。
我们将聚焦以下数据预处理步骤中的数据泄露问题。并将结合
scikit-learn
中的具体预处理方法,并在文章末尾给出代码示例。
缺失值填充
在处理真实数据时,经常会遇到缺失值。与其删除这些不完整的数据点,不如用合理的估计值填充它们。这有助于我们保留更多的数据用于分析。
填充缺失值的简单方法包括:
- 使用
SimpleImputer(strategy='mean')或SimpleImputer(strategy='median')将缺失值填充为该列的平均值或中位数 - 使用
KNNImputer()查看相似的数据点并使用它们的值 - 使用
SimpleImputer(strategy='ffill')或SimpleImputer(strategy='bfill')将缺失值填充为数据中前一个或后一个值 - 使用
SimpleImputer(strategy='constant', fill_value=value)将所有缺失值替换为相同的数字或文本
这个过程被称为填充,虽然很有用,但我们需要谨慎计算这些替换值,以避免数据泄露。
数据泄露案例:简单填充(平均值)
当你使用所有数据的平均值填充缺失值时,平均值本身包含了训练集和测试集的信息。这个合并的平均值与你仅使用训练数据计算所得不同。由于这个不同的平均值会进入你的训练数据,你的模型实际上从本不应看到的测试数据信息中学习。
🚨 问题所在使用完整数据集计算平均值
❌ 错误做法使用训练集和测试集的统计数据计算填充值
💥 后果训练数据包含受测试数据影响的平均值
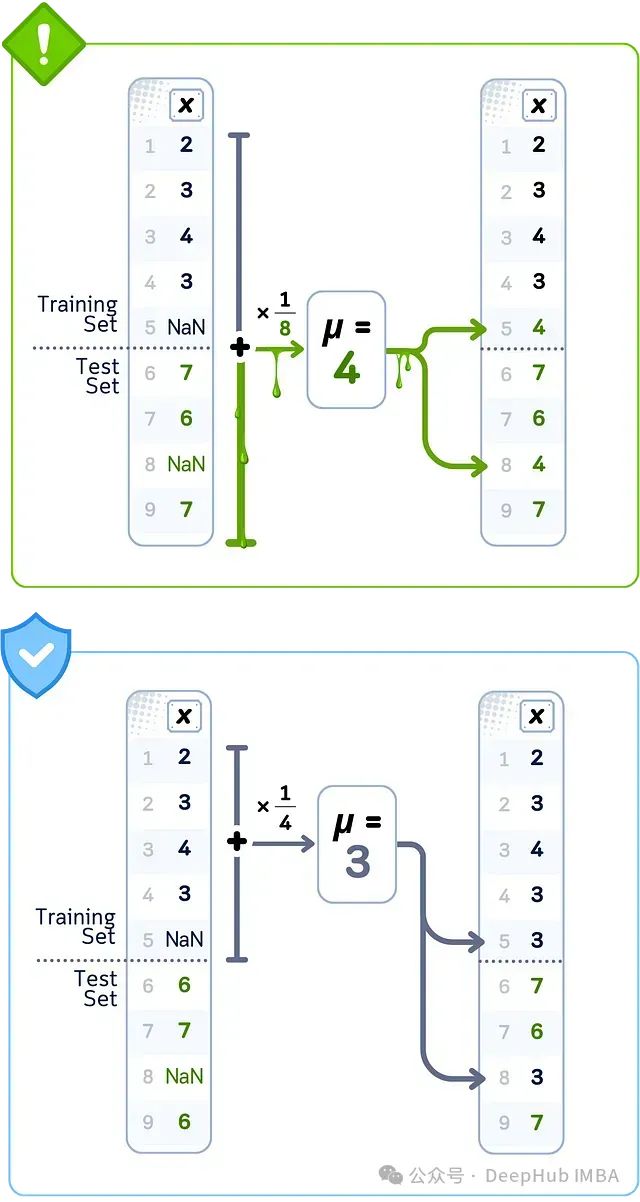
当使用所有数据行计算的平均值(4)填充缺失值,而非正确地仅使用训练数据的平均值(3)时,就会发生平均值填充泄露,导致错误的填充值。
数据泄露案例:KNN填充
当在所有数据上使用KNN填充缺失值时,该算法会从训练集和测试集中找到相似的数据点。它创建的替换值基于这些邻近点,这意味着测试集值直接影响了训练数据。由于KNN查看实际的邻近值,相比简单的平均值填充,这种训练和测试信息的混合更加直接。
🚨 问题所在在完整数据集中寻找邻居
❌ 错误做法 使用测试集样本作为填充的潜在邻居
💥 后果使用直接的测试集信息填充缺失值
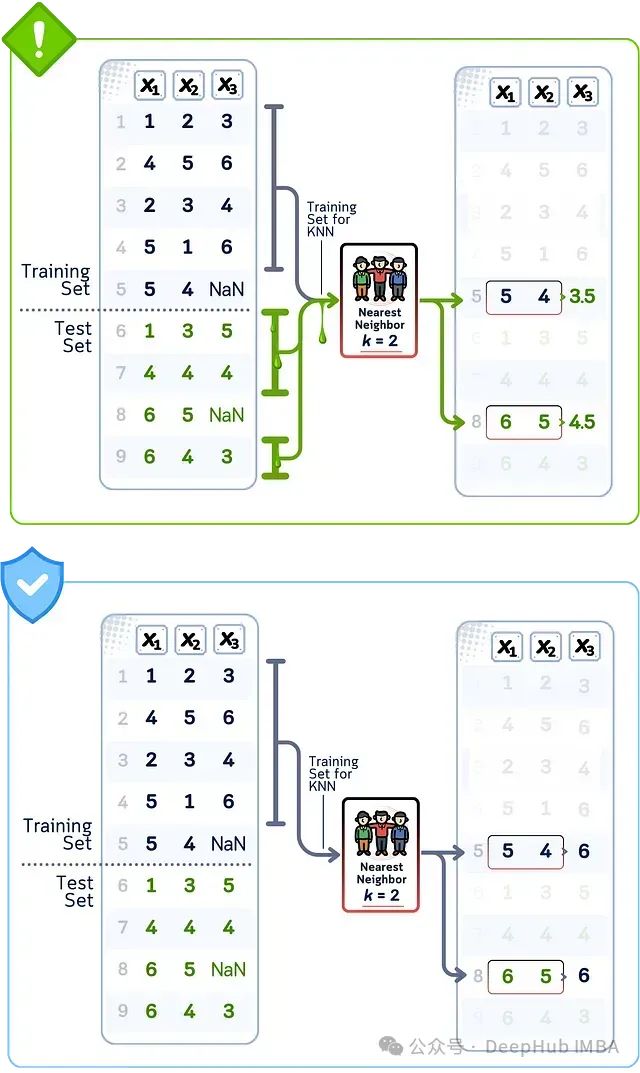
当使用训练数据和测试数据找到最近邻(得到值3.5和4.5)时,就会发生KNN填充泄露;而正确的做法是仅使用训练数据模式填充缺失值(得到值6和6)。
分类编码
有些数据以类别而非数字的形式呈现,如颜色、名称或类型。由于模型只能处理数字,我们需要将这些类别转换为数值。
常见的类别转换方法包括:
- 使用
OneHotEncoder()为每个类别创建单独的由1和0组成的列(也称为虚拟变量) - 使用
OrdinalEncoder()或LabelEncoder()为每个类别分配一个数字(如1、2、3) - 使用
OrdinalEncoder(categories=[ordered_list])自定义类别顺序,以反映自然层次结构(如small=1, medium=2, large=3) - 使用
TargetEncoder()根据类别与我们试图预测的目标变量之间的关系将类别转换为数字
转换类别的方式会影响模型的学习效果,在此过程中需要注意不要使用来自测试数据的信息。
数据泄露案例:目标编码
当使用所有数据的目标编码转换分类值时,编码值是使用来自训练集和测试集的目标信息计算的。替换每个类别的数字是目标值的平均值,其中包括测试数据。这意味着训练数据被分配的值已经包含了本不应知道的测试集目标值信息。
🚨 问题所在使用完整数据集计算类别平均值
❌ 错误做法使用所有目标值计算类别替换
💥 后果训练特征包含未来目标信息
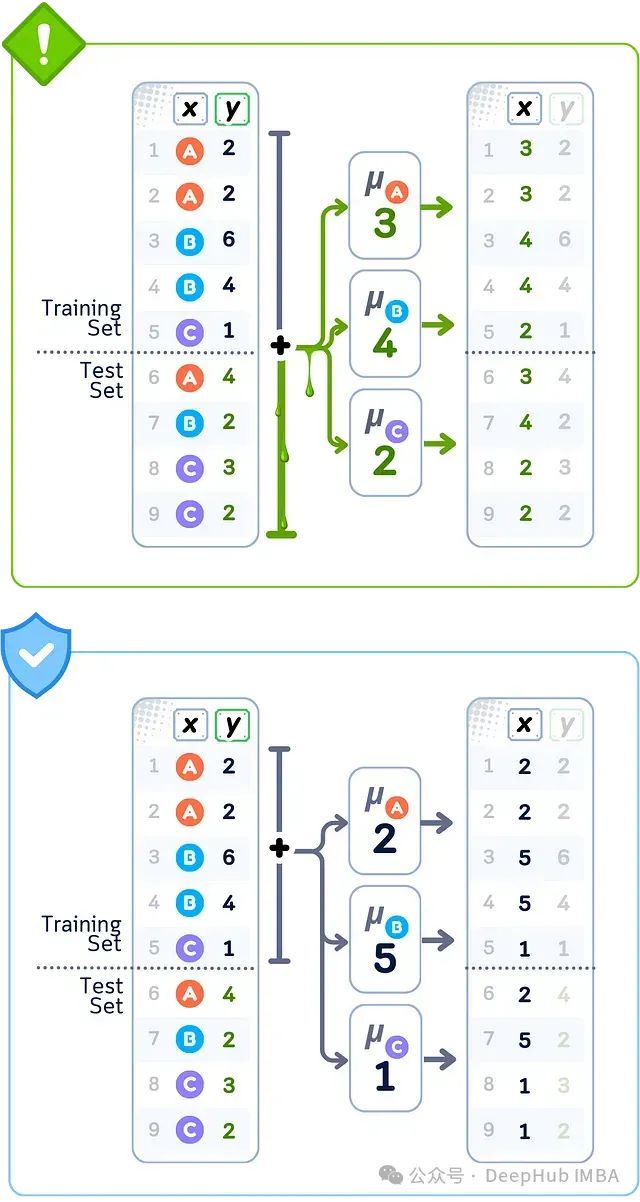
当使用所有数据替换类别的平均目标值(A=3, B=4, C=2)时,就会发生目标编码泄露;而正确的做法是仅使用训练数据的平均值(A=2, B=5, C=1),否则会导致错误的类别值。
数据泄露案例:One-Hot编码
当使用所有数据将类别转换为二进制列,然后选择要保留的列时,选择是基于在训练集和测试集中发现的模式。保留或删除某些二进制列的决定受到它们在测试数据中预测目标效果的影响,而不仅仅是训练数据。这意味着选择的列部分取决于本不应使用的测试集关系。
🚨 问题所在从完整数据集确定类别
❌ 错误做法基于所有唯一值创建二进制列
💥 后果特征选择受测试集模式影响
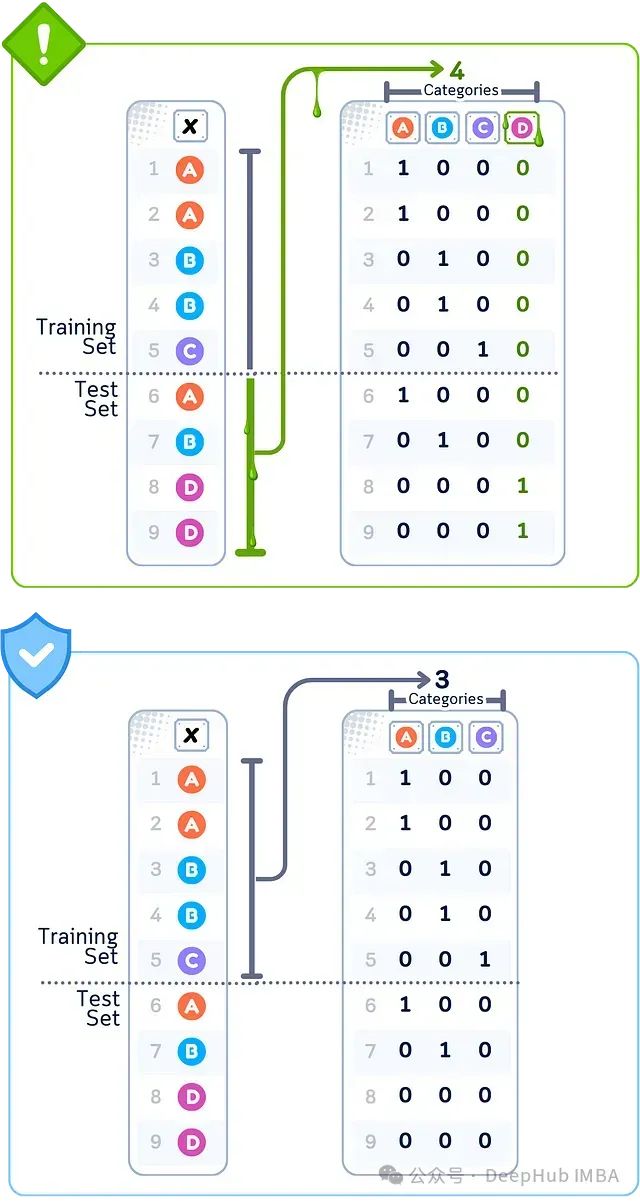
当使用完整数据集的所有唯一值(A,B,C,D)创建类别列时,就会发生One-Hot编码泄露;而正确的做法是仅使用训练数据中存在的类别(A,B,C),否则会导致错误的编码模式。
数据缩放
数据中不同特征的取值范围差异通常很大,有些可能是几千,有些则是微小的小数。调整这些范围,使所有特征具有相似的尺度,以帮助模型更好地工作。
常见的尺度调整方法包括:
- 使用
StandardScaler()使值以0为中心,大多数值落在-1和1之间(均值=0,方差=1) - 使用
MinMaxScaler()将所有值压缩在0和1之间,或使用MinMaxScaler(feature_range=(min, max))自定义范围 - 使用
FunctionTransformer(np.log1p)或PowerTransformer(method='box-cox')处理非常大的数字,使分布更正态 - 使用
RobustScaler()采用不受异常值影响的统计数据调整尺度(使用四分位数而非均值/方差)
虽然缩放有助于模型公平地比较不同特征,但我们需要仅使用训练数据计算这些调整,以避免泄露。
数据泄露案例:标准缩放
当使用所有数据对特征进行标准化时,计算中使用的平均值和分布值来自训练集和测试集。这些值与仅使用训练数据所得不同。这意味着训练数据中的每个标准化值都使用了测试集中值的分布信息进行了调整。
🚨 问题所在 使用完整数据集计算统计数据
❌ 错误做法使用所有值计算均值和标准差
💥 后果使用测试集分布缩放训练特征
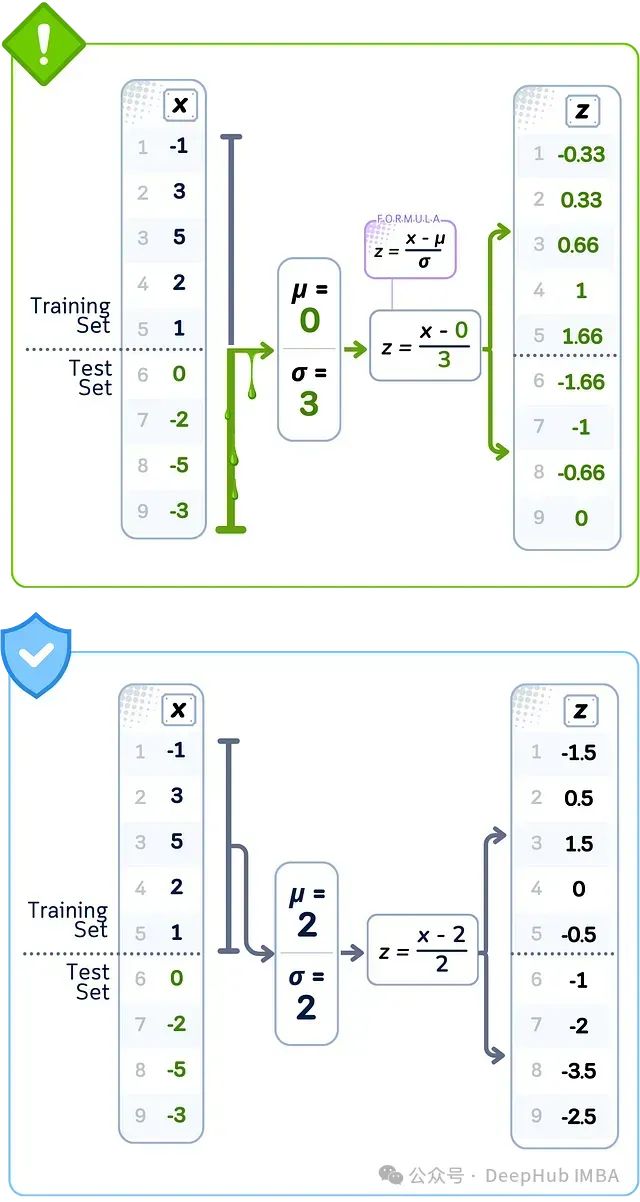
当使用完整数据集的平均值(μ=0)和分布(σ=3)对数据进行归一化时,就会发生标准缩放泄露;而正确的做法是仅使用训练数据的统计数据(μ=2,σ=2),否则会导致错误的标准化值。
数据泄露案例:最小-最大缩放
当使用所有数据的最小值和最大值缩放特征时,这些边界值可能来自测试集。训练数据中的缩放值是使用这些边界计算的,这可能与仅使用训练数据所得结果不同。这意味着你训练数据中的每个缩放值都使用了测试集中值的完整范围进行了调整。
🚨 问题所在使用完整数据集找到边界
❌ 错误做法从所有数据点确定最小/最大值
💥 后果使用测试集范围归一化训练特征
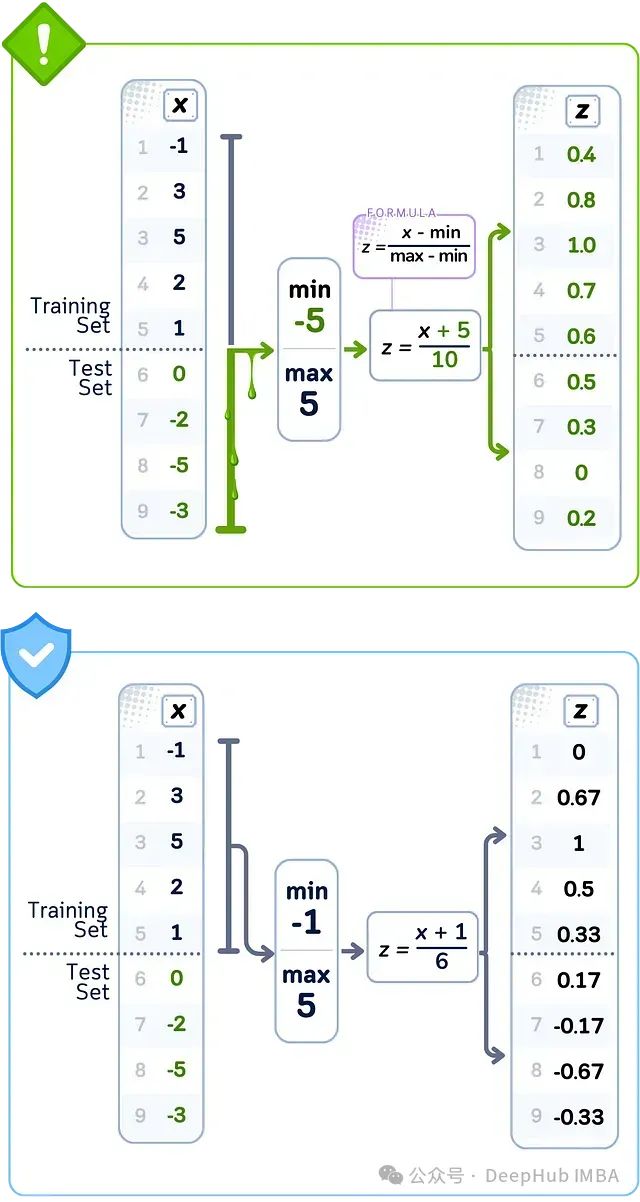
当使用完整数据集的最小值(-5)和最大值(5)缩放数据时,就会发生最小-最大缩放泄露;而正确的做法是仅使用训练数据的范围(最小值=-1,最大值=5),否则会导致值的错误缩放。
离散化
有时将数字分组为类别比使用精确值更有利。这有助于机器学习模型更轻松地处理和分析数据。
创建这些组的常见方法包括:
- 使用
KBinsDiscretizer(strategy='uniform')使每个组覆盖相同大小范围的值 - 使用
KBinsDiscretizer(strategy='quantile')使每个组包含相同数量的数据点 - 使用
KBinsDiscretizer(strategy='kmeans')通过聚类找到数据中的自然分组 - 使用
QuantileTransformer(n_quantiles=n, output_distribution='uniform')根据数据中的百分位数创建组
虽然对值进行分组可以帮助模型更好地找到模式,但我们决定组边界的方式需要仅使用训练数据,以避免泄露。
数据泄露案例:等频分箱
当使用所有数据创建具有相等数量数据点的箱时,箱之间的切割点是使用训练集和测试集确定的。这些切割值与仅使用训练数据所得结果不同。这意味着当你将训练数据中的数据点分配到箱中时,使用的分割点受到了测试集值的影响。
🚨 问题所在使用完整数据集设置阈值
❌ 错误做法使用所有数据点确定箱边界
💥 后果使用测试集分布对训练数据分箱
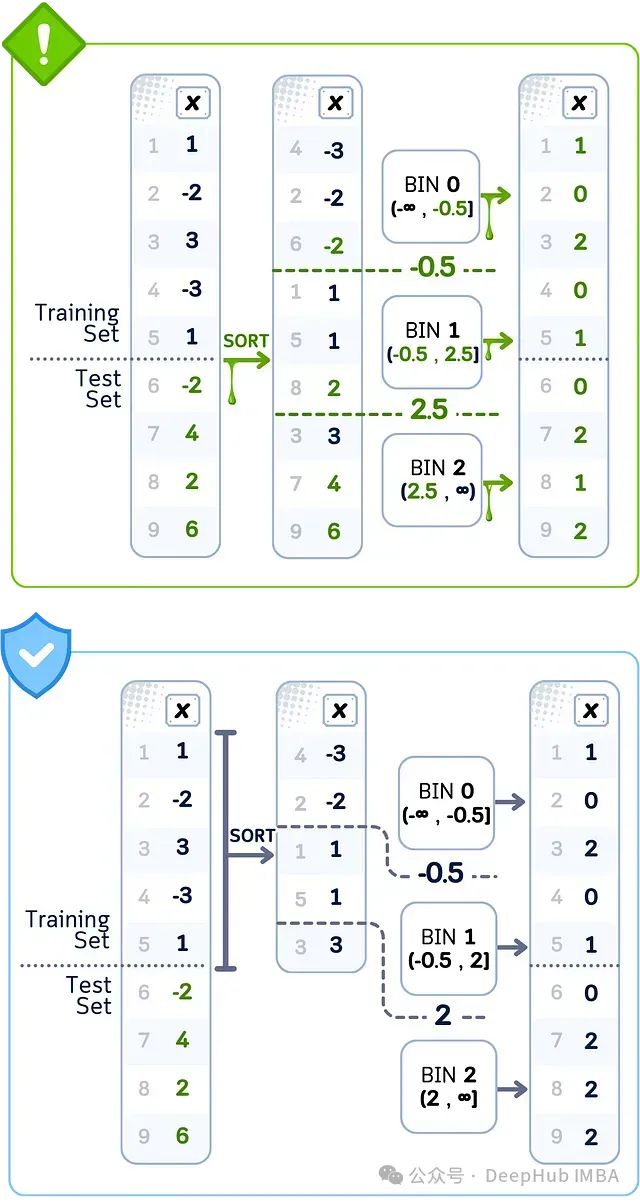
当使用所有数据设置箱切割点(-0.5,2.5)时,就会发生等频分箱泄露;而正确的做法是仅使用训练数据设置边界(-0.5,2.0),否则会导致值的错误分组。
数据泄露案例:等宽分箱
当使用所有数据创建相等大小的箱时,用于确定箱宽度的范围来自训练集和测试集。这个总范围可能比仅使用训练数据所得范围更宽或更窄。这意味着当你将训练数据中的数据点分配到箱中时,你使用的是基于测试集值的完整分布计算得到的箱边界。
🚨 问题所在使用完整数据集计算范围
❌ 错误做法基于完整数据分布设置箱宽度
💥 后果使用测试集边界对训练数据分箱
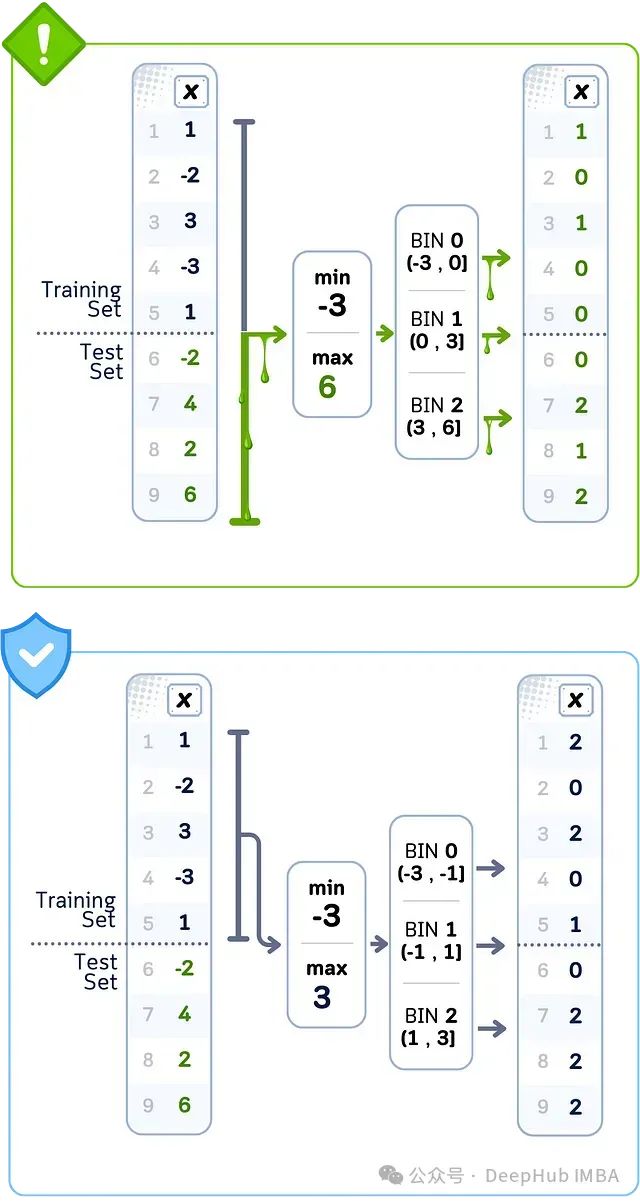
当使用完整数据集的范围(-3到6)将数据拆分为大小相等的组时,就会发生等宽分箱泄露;而正确的做法是仅使用训练数据的范围(-3到3),否则会导致错误的分组。
重采样
当数据中某些类别的样本数量远多于其他类别时,我们可以使用
imblearn
中的重采样技术通过创建新样本或移除现有样本来平衡它们。这有助于模型公平地学习所有类别。
添加样本的常见方法(过采样):
- 使用
RandomOverSampler()复制较小类别中的现有样本 - 使用
SMOTE()使用插值为较小类别创建新的合成样本 - 使用
ADASYN()在模型最难处理的区域创建更多样本,重点关注决策边界 移除样本的常见方法(欠采样): - 使用
RandomUnderSampler()从较大类别中随机移除样本 - 使用
NearMiss(version=1)或NearMiss(version=2)根据它们与较小类别的距离从较大类别中移除样本 - 使用
TomekLinks()或EditedNearestNeighbours()根据它们与其他类别的相似性仔细选择要移除的样本
虽然平衡数据有助于模型学习,但创建或移除样本的过程应仅使用训练数据的信息,以避免泄露。
数据泄露案例:过采样(SMOTE)
当使用所有数据上的SMOTE创建合成数据点时,该算法会从训练集和测试集中选取附近的点来创建新样本。这些新点是通过将测试集样本的值与训练数据混合创建的。这意味着你的训练数据获得了直接使用测试集值信息创建的新样本。
🚨 问题所在使用完整数据集生成样本
❌ 错误做法使用测试集邻居创建合成点
💥 后果训练数据被测试集影响的样本增强
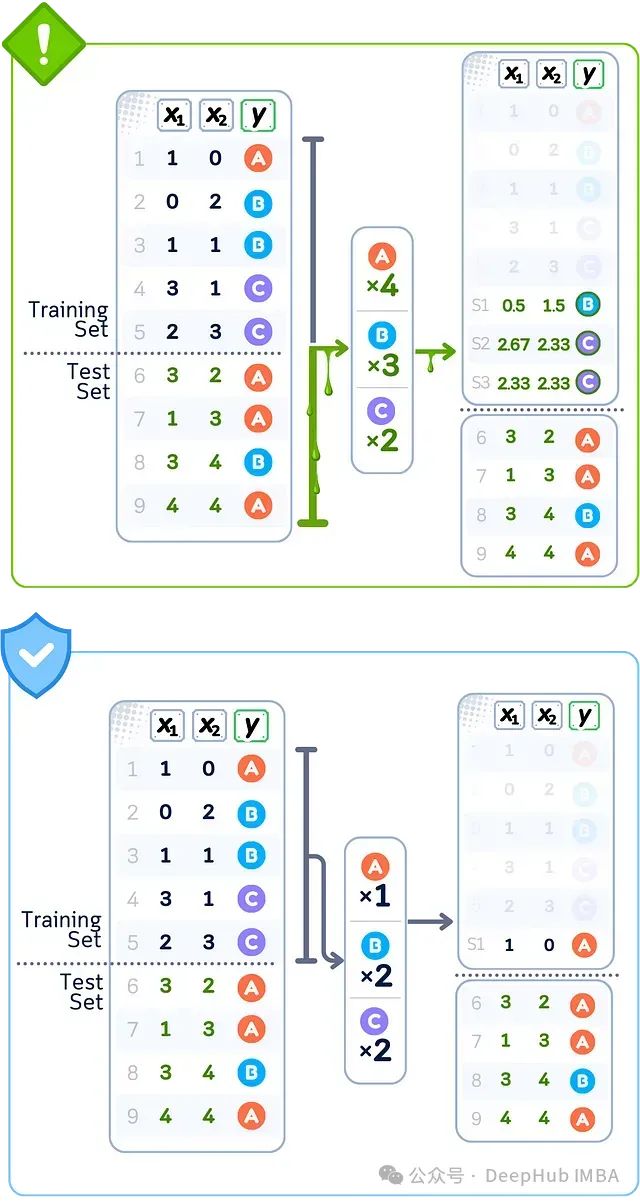
当根据整个数据集的类别计数复制数据点(A×4, B×3, C×2)时,就会发生过采样泄露;而正确的做法是仅使用训练数据(A×1, B×2, C×2)来决定每个类别要复制的次数。
数据泄露案例:欠采样(TomekLinks)
当使用所有数据上的Tomek Links移除数据点时,该算法会从训练集和测试集中找到最接近但标签不同的点对。从训练数据中移除点的决定基于它们与测试集点的接近程度。这意味着你的最终训练数据是由其与测试集值的关系塑造的。
🚨 问题所在使用完整数据集移除样本
❌ 错误做法使用测试集关系识别点对
💥 后果基于测试集模式减少训练数据
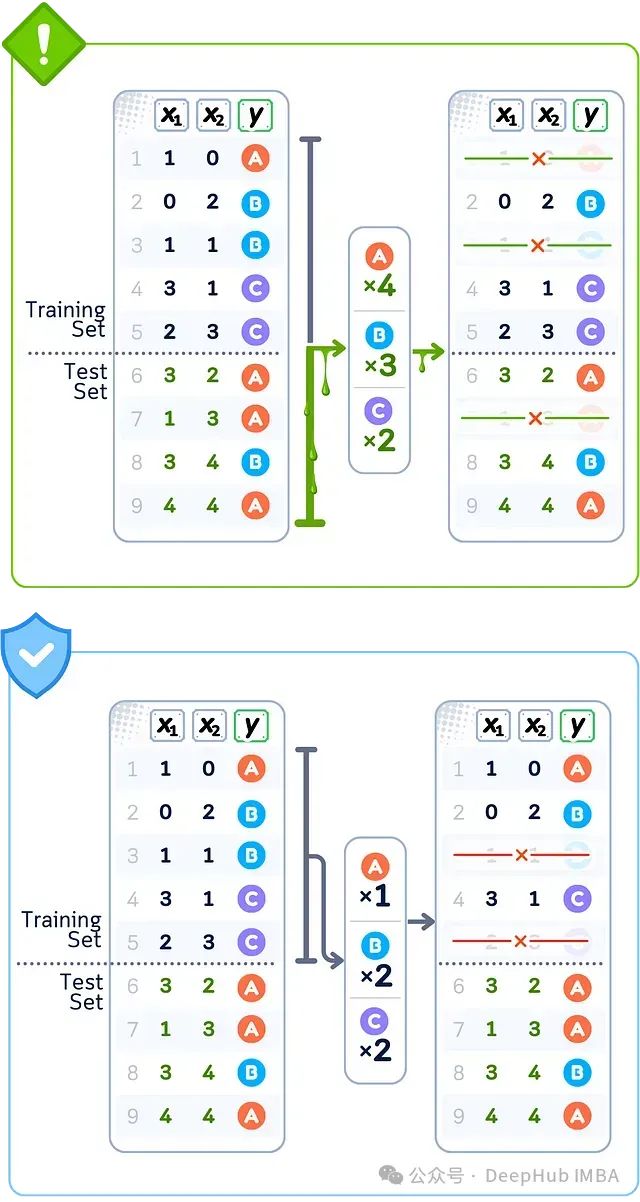
当根据整个数据集的类别比例移除数据点(A×4, B×3, C×2)时,就会发生欠采样泄露;而正确的做法是仅使用训练数据(A×1, B×2, C×2)来决定每个类别要保留的样本数量。
最后总结
在预处理数据时,需要将训练数据和测试数据完全分开。任何时候使用来自所有数据的信息来转换值-无论是填充缺失值,将类别转换为数字,缩放特征,分箱还是平衡类-都有可能将测试数据信息混合到训练数据中。这使得模型的测试结果不可靠,因为模型已经从它不应该看到的模式中学习了。
解决方案很简单:始终首先转换训练数据,保存这些计算,然后将其应用于测试数据。
数据预处理+分类(带泄漏)代码
让我们看看在预测一个简单的高尔夫比赛数据集时,泄漏是如何发生的。
importpandasaspd
importnumpyasnp
fromsklearn.composeimportColumnTransformer
fromsklearn.preprocessingimportStandardScaler, OrdinalEncoder, KBinsDiscretizer
fromsklearn.imputeimportSimpleImputer
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.treeimportDecisionTreeClassifier
fromsklearn.metricsimportaccuracy_score
fromimblearn.pipelineimportPipeline
fromimblearn.over_samplingimportSMOTE
# Create dataset
dataset_dict= {
'Outlook': ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast', 'sunny', 'sunny', 'rain', 'sunny', 'overcast', 'overcast', 'rain', 'sunny', 'overcast', 'rain', 'sunny', 'sunny', 'rain', 'overcast', 'rain', 'sunny', 'overcast', 'sunny', 'overcast', 'rain', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0, 72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0, 88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0, 90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0, 65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True, True, False, True, True, False, False, True, False, True, True, False, True, False, False, True, False, False],
'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes']
}
df=pd.DataFrame(dataset_dict)
X, y=df.drop('Play', axis=1), df['Play']
# Preprocess AND apply SMOTE to ALL data first (causing leakage)
preprocessor=ColumnTransformer(transformers=[
('temp_transform', Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('discretizer', KBinsDiscretizer(n_bins=4, encode='ordinal'))
]), ['Temperature']),
('humid_transform', Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('discretizer', KBinsDiscretizer(n_bins=4, encode='ordinal'))
]), ['Humidity']),
('outlook_transform', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1),
['Outlook']),
('wind_transform', Pipeline([
('imputer', SimpleImputer(strategy='constant', fill_value=False)),
('scaler', StandardScaler())
]), ['Wind'])
])
# Transform all data and apply SMOTE before splitting (leakage!)
X_transformed=preprocessor.fit_transform(X)
smote=SMOTE(random_state=42)
X_resampled, y_resampled=smote.fit_resample(X_transformed, y)
# Split the already transformed and resampled data
X_train, X_test, y_train, y_test=train_test_split(X_resampled, y_resampled, test_size=0.5, shuffle=False)
# Train a classifier
clf=DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
print(f"Testing Accuracy (with leakage): {accuracy_score(y_test, clf.predict(X_test)):.2%}")
上面的代码使用了ColumnTransformer,这是scikit-learn中的一个很好用的功能,允许我们对数据集中的不同列应用不同的预处理步骤。
代码演示了数据泄漏,因为所有转换在拟合期间都会看到整个数据集,这在真实的机器学习场景中是不合适的,因为我们需要将测试数据与训练过程完全分开。
这种方法也可能显示出人为的更高的测试精度,因为测试数据特征是在预处理步骤中使用的!
数据预处理+分类(无泄漏)代码
以下是没有数据泄露的版本:
importpandasaspd
importnumpyasnp
fromsklearn.composeimportColumnTransformer
fromsklearn.preprocessingimportStandardScaler, OrdinalEncoder, KBinsDiscretizer
fromsklearn.imputeimportSimpleImputer
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.treeimportDecisionTreeClassifier
fromsklearn.metricsimportaccuracy_score
fromimblearn.pipelineimportPipeline
fromimblearn.over_samplingimportSMOTE
# Create dataset
dataset_dict= {
'Outlook': ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast', 'sunny', 'sunny', 'rain', 'sunny', 'overcast', 'overcast', 'rain', 'sunny', 'overcast', 'rain', 'sunny', 'sunny', 'rain', 'overcast', 'rain', 'sunny', 'overcast', 'sunny', 'overcast', 'rain', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0, 72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0, 88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0, 90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0, 65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True, True, False, True, True, False, False, True, False, True, True, False, True, False, False, True, False, False],
'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'No', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No', 'Yes']
}
df=pd.DataFrame(dataset_dict)
X, y=df.drop('Play', axis=1), df['Play']
# Split first (before any processing)
X_train, X_test, y_train, y_test=train_test_split(X, y, test_size=0.5, shuffle=False)
# Create pipeline with preprocessing, SMOTE, and classifier
pipeline=Pipeline([
('preprocessor', ColumnTransformer(transformers=[
('temp_transform', Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('discretizer', KBinsDiscretizer(n_bins=4, encode='ordinal'))
]), ['Temperature']),
('humid_transform', Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('discretizer', KBinsDiscretizer(n_bins=4, encode='ordinal'))
]), ['Humidity']),
('outlook_transform', OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1),
['Outlook']),
('wind_transform', Pipeline([
('imputer', SimpleImputer(strategy='constant', fill_value=False)),
('scaler', StandardScaler())
]), ['Wind'])
])),
('smote', SMOTE(random_state=42)),
('classifier', DecisionTreeClassifier(random_state=42))
])
# Fit pipeline on training data only
pipeline.fit(X_train, y_train)
print(f"Training Accuracy: {accuracy_score(y_train, pipeline.predict(X_train)):.2%}")
print(f"Testing Accuracy: {accuracy_score(y_test, pipeline.predict(X_test)):.2%}")
与泄漏版本的关键区别在于:
在进行任何处理之前,先拆分数据所有转换(预处理、SMOTE),预处理仅从训练数据中学习的参数,SMOTE仅适用于训练数据。在预测之前,测试数据完全不可见
这种方法提供了更现实的性能估计,因为它在训练和测试数据之间保持了适当的分离。
https://avoid.overfit.cn/post/b33fb13c677243ada1a713ad7e0e3d17
作者:Samy Baladram



















