本文讨论一波,kubernetes集群部署的高可用postgresql集群在滚动更新场景下,如何实现减少failover次数?
这个原理我觉得适用于任何主从架构的中间件,是一个通用的设计技巧。
那就是: 在进行滚动升级过程中,先重启从节点,再重启主节点。
所以为什么?接下来做不区分主从重启 和 区分主从重启 的对比:
不区分主从重启
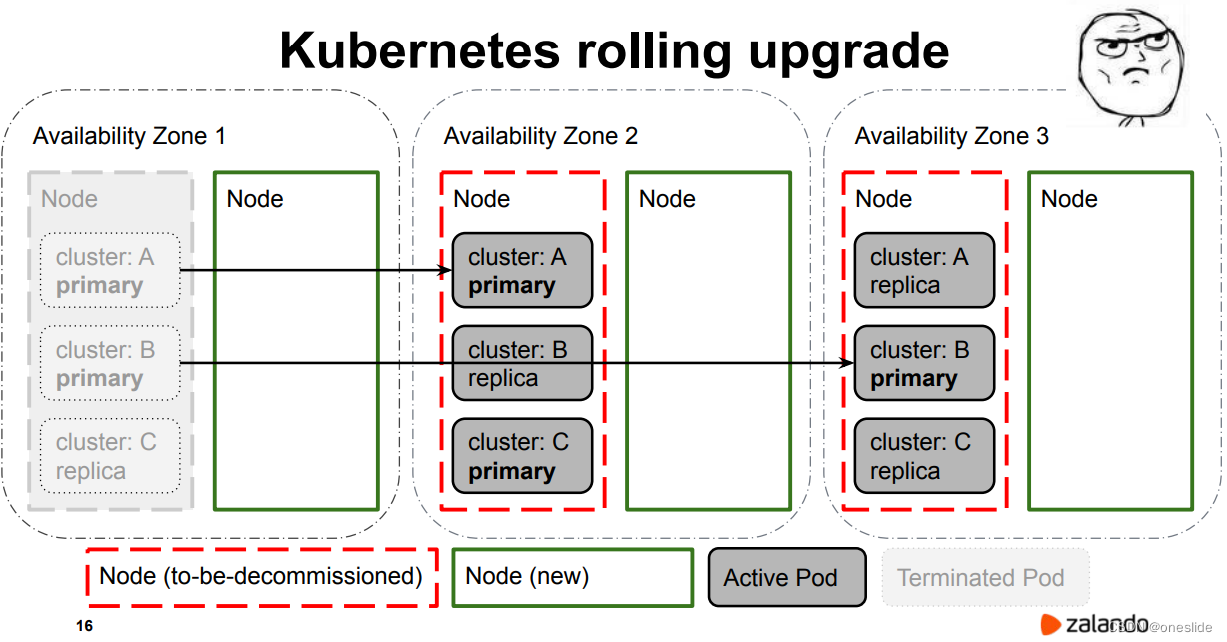
红色框代表将要退役的节点,绿色框代表新节点。
- 在迁移场景下,退役节点 不等于 新节点
- 在滚动升级场景下,退役节点 可以等于 新节点
有三个Postgresql高可用集群,每个集群的结构为一主两从。
初始态

迁移AZ1
主从切换次数:
| Cluster | failover times |
|---|---|
| A | 1 |
| B | 1 |
| C | 0 |
迁移AZ2
AZ1 协调副本数量状态,在新节点上启动了几个replica。

迁移AZ2 , 又发生两次主从切换:
主从切换次数:
| Cluster | failover times |
|---|---|
| A | 2 |
| B | 1 |
| C | 1 |
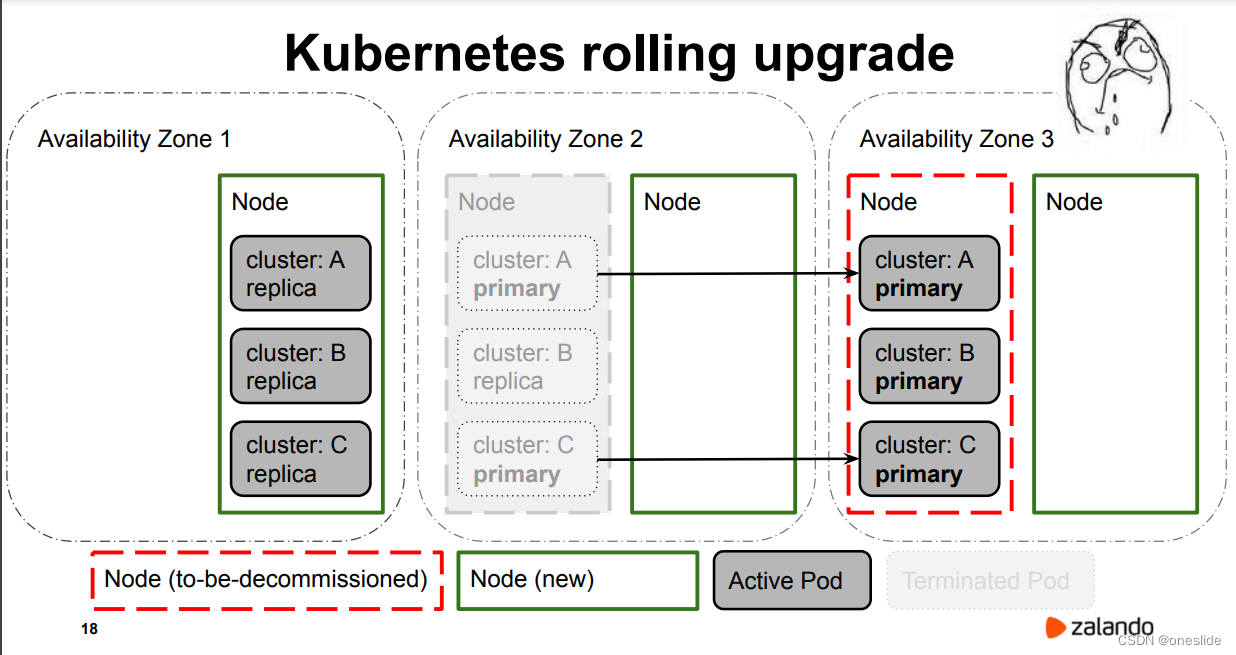
迁移AZ3
AZ2 协调副本数量状态,在新节点上启动了几个replica。
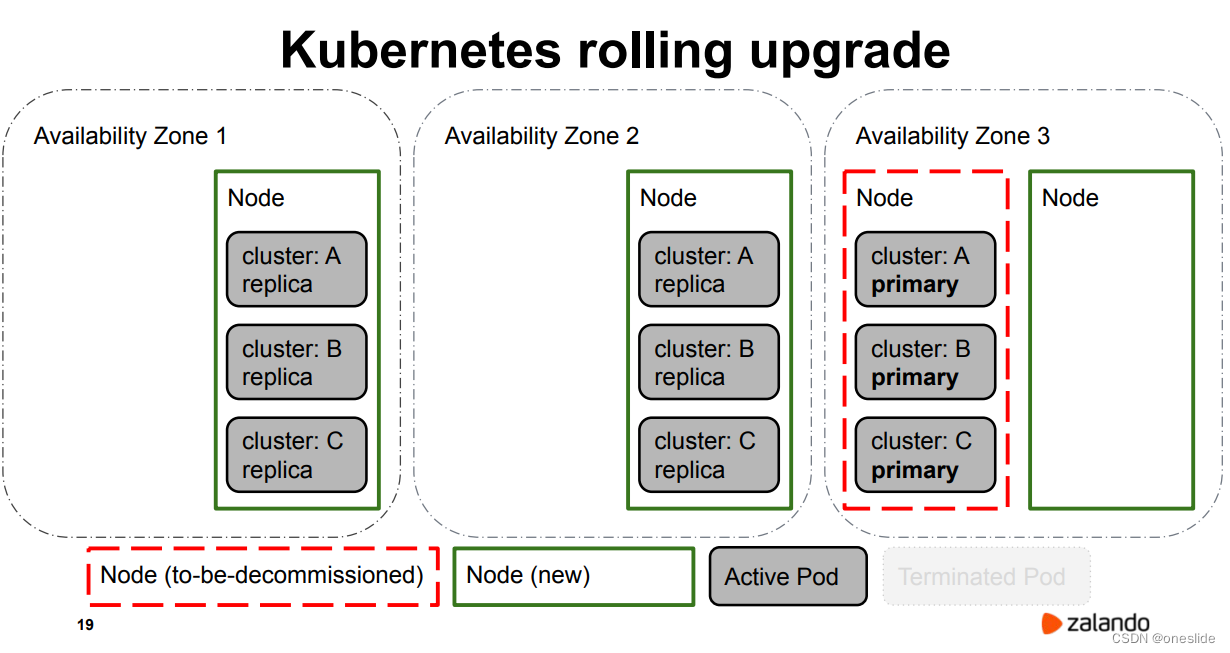
迁移AZ2 , 又发生3次主从切换:

终态
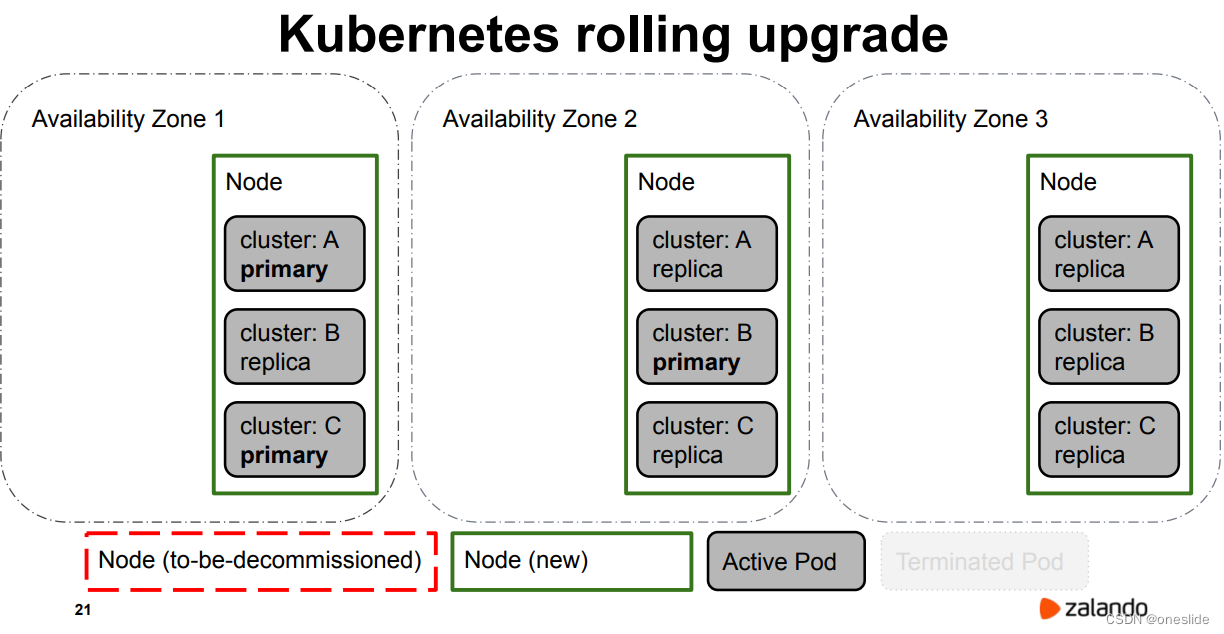
从初始态滚动更新到终态,主从切换的次数过于频繁。
主从切换次数:
| Cluster | failover times |
|---|---|
| A | 3 |
| B | 2 |
| C | 2 |
区分主从重启
从上面的滚动更新场景,可以认识到一个核心问题。
当滚动更新轮到某个主节点时,主从切换之后新主节点因为是老版本,将来还需要重启更新的,因此它的重启将会导致另一次主从切换。
如果先重启从节点,重启后,主从切换假如被提升为主节点。因为它已经更新重启过了。所以它不用重启升级导致后面的主从切换了。
按照这个策略执行一下,对比与 不区分主从重启 策略的failover数据。
初始态
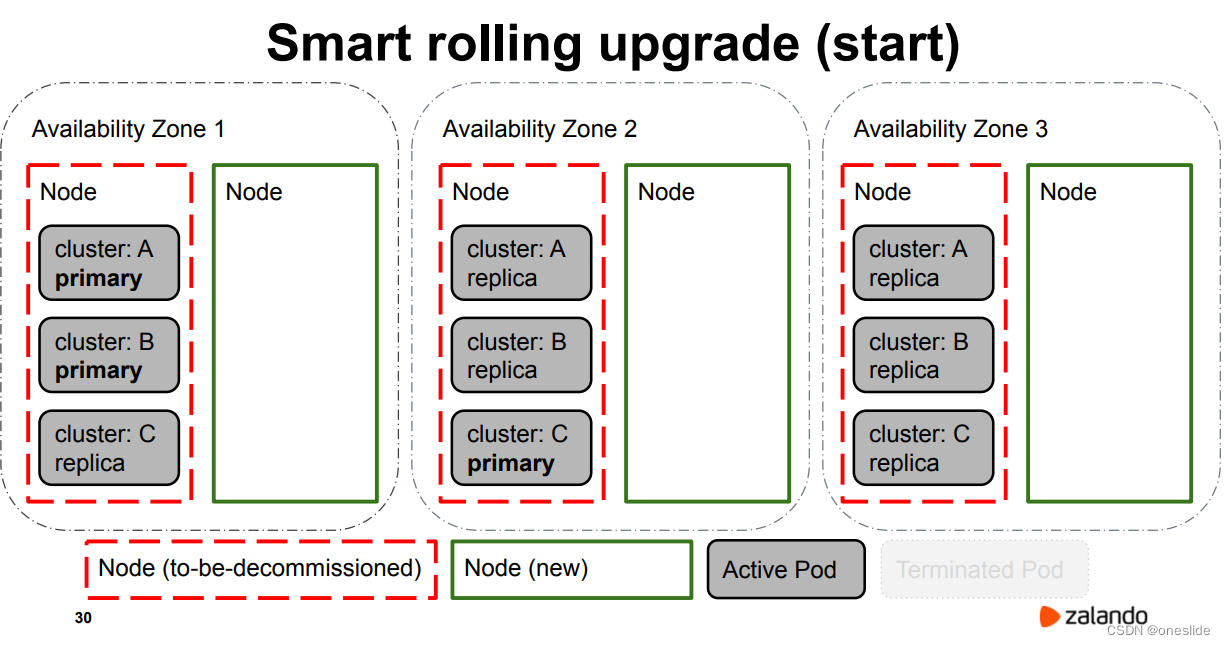
重启所有从节点
重启所有从节点不发生主从切换。
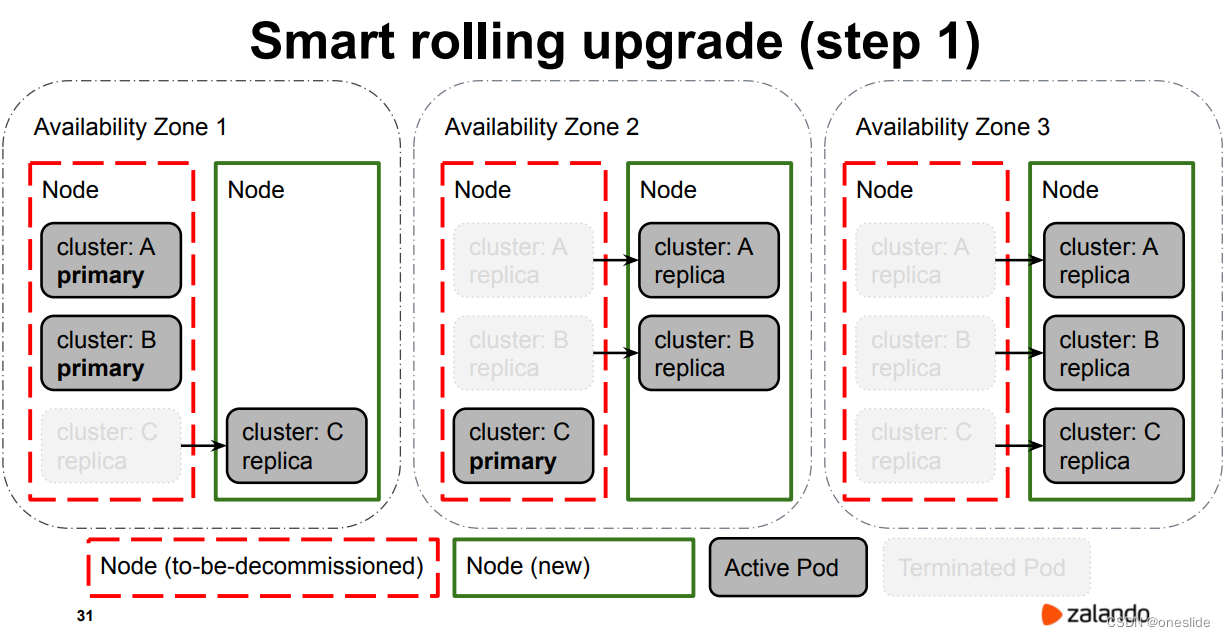
停止旧的从实例(灰色):
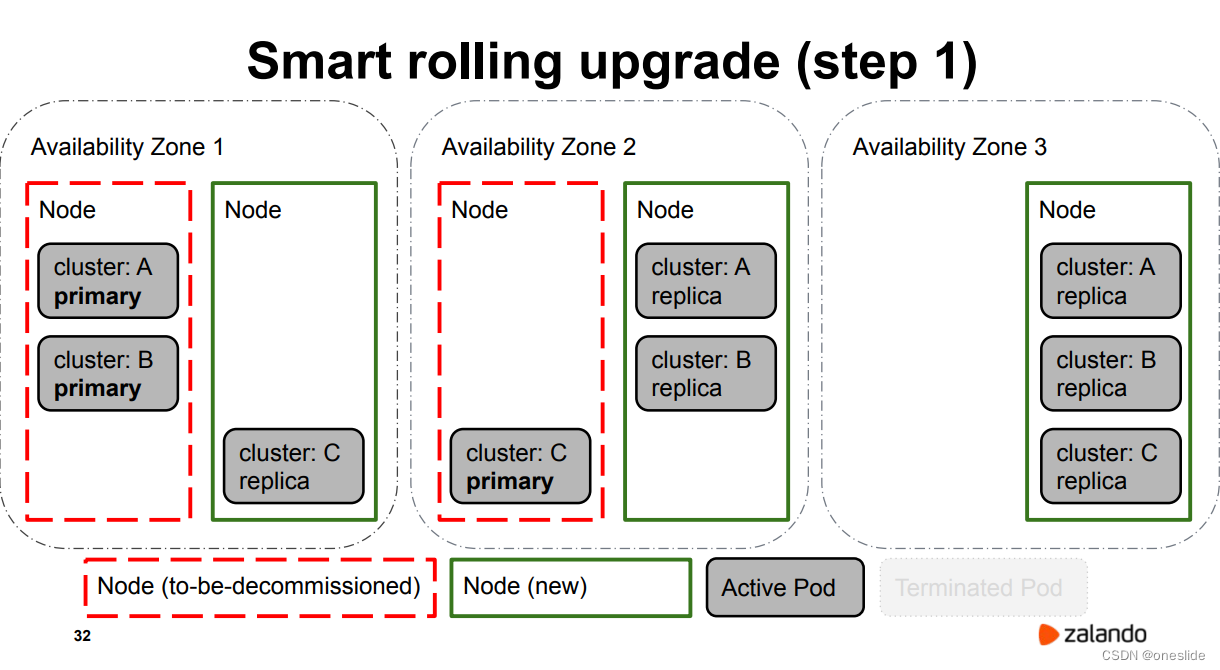
重启主节点
重启主节点导致所有集群A,B,C都发生一次主从切换:
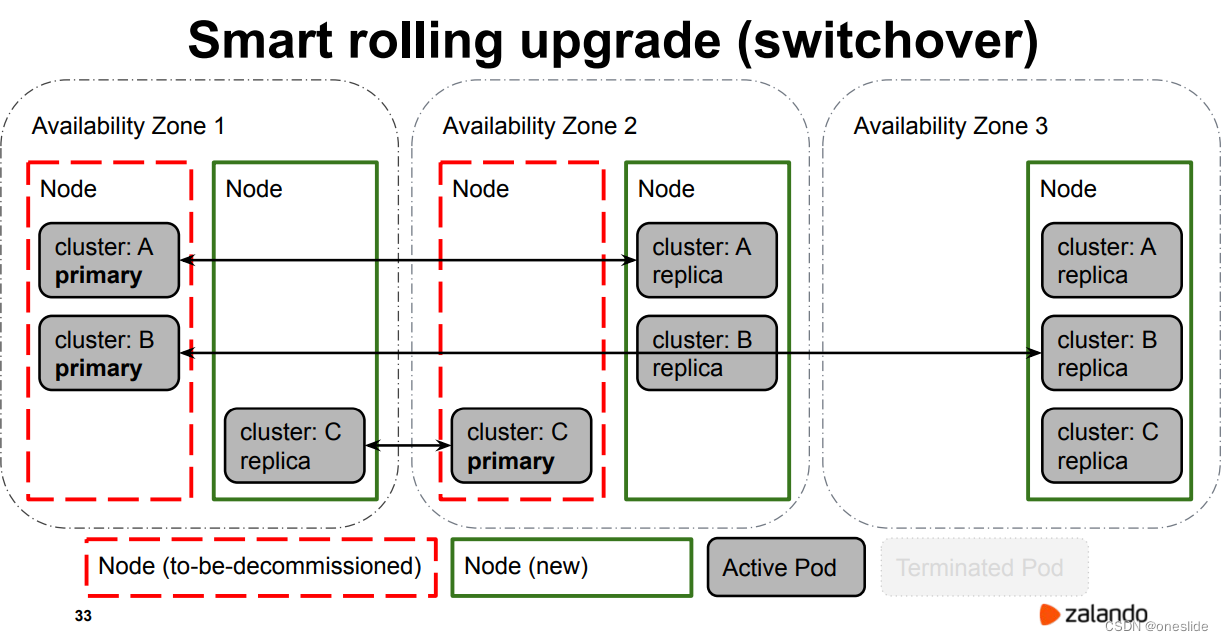
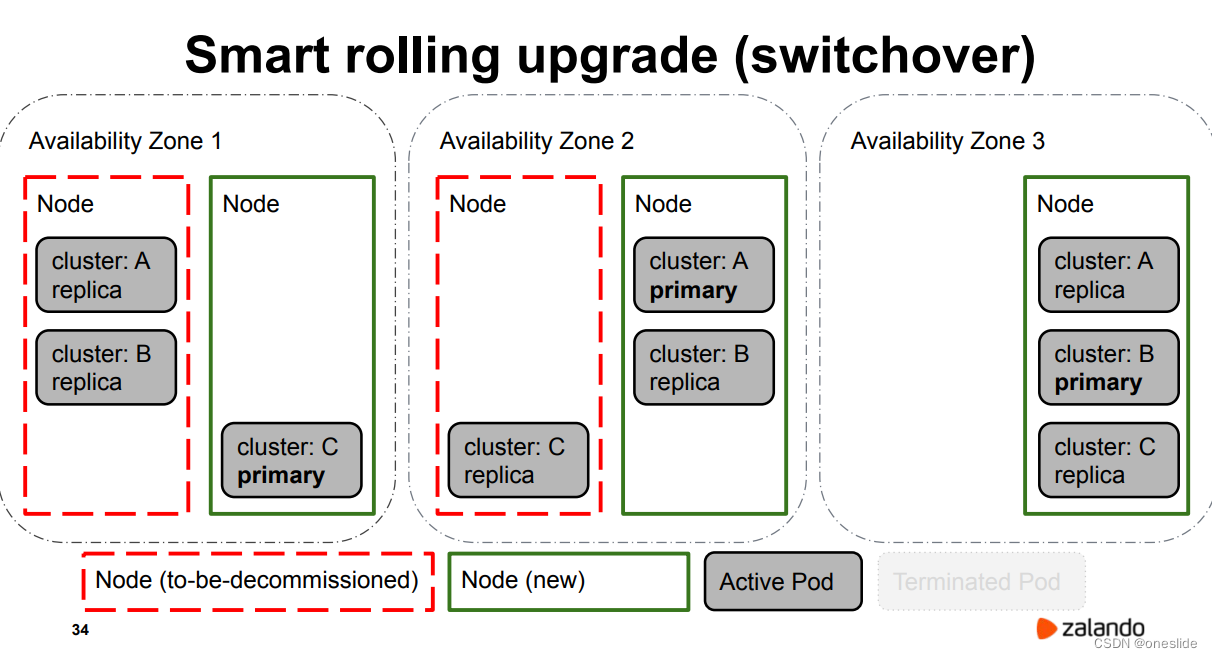
主从切换次数:
| Cluster | failover times |
|---|---|
| A | 1 |
| B | 1 |
| C | 1 |
将主节点重启成功后,变成从节点:
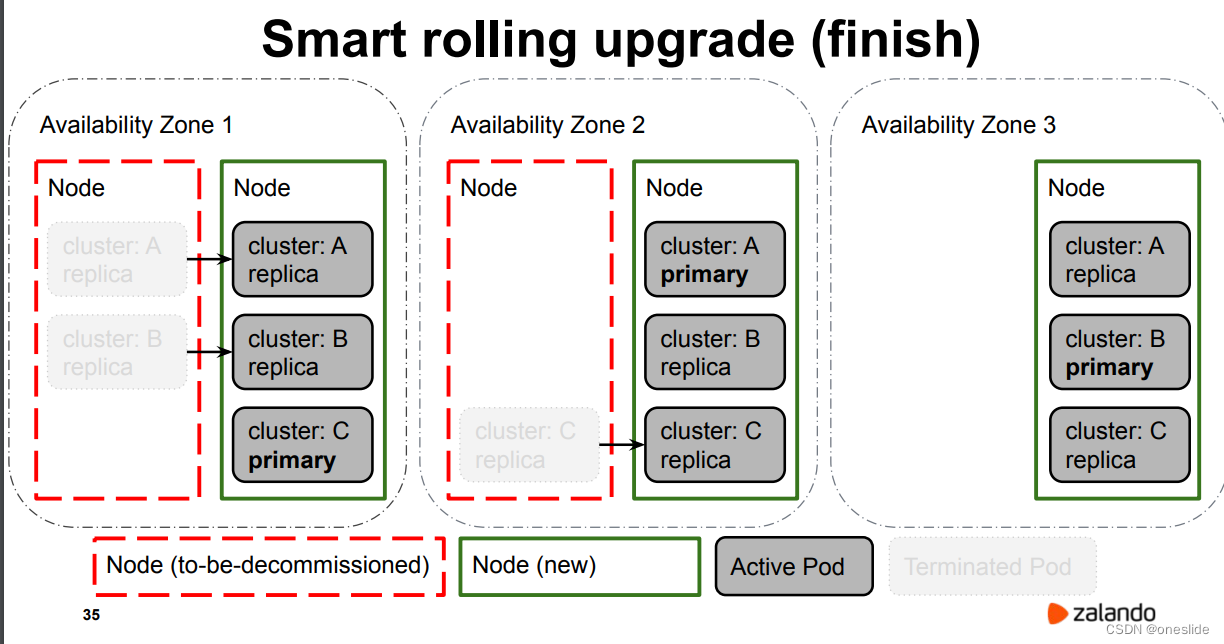
可以发现,每个集群只发生了一次failover,这是相对理想的结果。
总结
主从切换能够实现高可用,但是主从切换可能导致数据丢失,增加额外风险。因此即使是高可用集群下,应该尽可能避免主从切换。
通过主从切换的次数数据对比,可以发现区分主从节点的滚动更新策略要优于不区分主从。


![图书管理系统(Java实现)[附完整代码]](https://img-blog.csdnimg.cn/de47c8fe281d40b2acb0bfe054ca268e.png)






![[附源码]java毕业设计物理中考复习在线考试系统](https://img-blog.csdnimg.cn/baccf72d81e643938e123886630aadff.png)