目录
- Dispatchers协程调度器
- Dispatchers.Default
- Dispatchers.IO
- Dispatchers.Main
- Dispatchers.Unconfined
- 协程调度器的实现CoroutineScheduler
- 总结
Dispatchers协程调度器
CoroutineDispatcher,具有用于调度任务的底层执行器。ExecutorCoroutineDispatcher的实例应由调度程序的所有者关闭。
此类通常用作基于协程的API和异步API之间的桥梁,异步API需要Executor的实例。
根据各种调度器的继承关系,梳理如下继承结构:
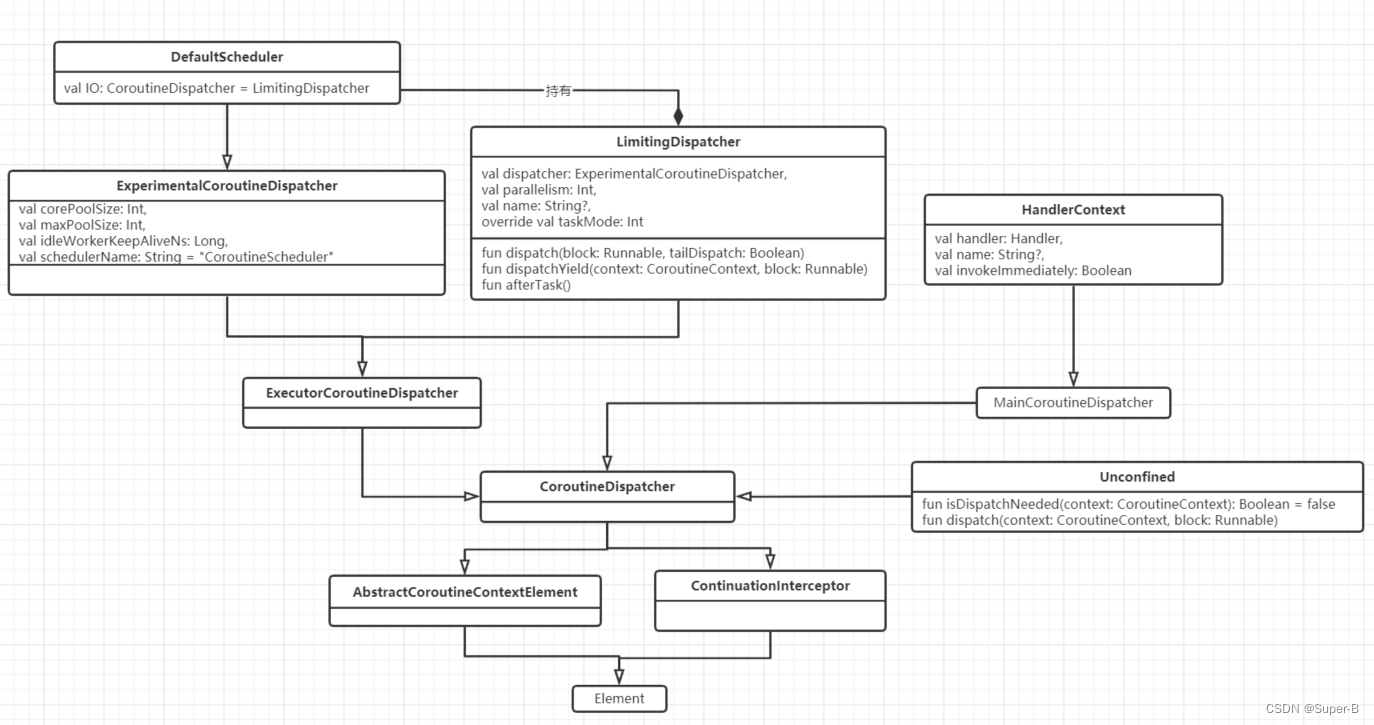
CoroutineDispatcher基类将由所有协程调度器实现扩展,kotlin官方实现了以下四种调度器:
Dispatchers.Default -如果上下文中未指定调度器或任何其他ContinuationInterceptor,则所有标准构建器都使用默认值。它使用共享后台线程的公共池。对于消耗CPU资源的计算密集型协程来说,这是一个合适的选择。
Dispatchers.IO -使用按需创建线程的共享池,用于卸载IO密集型阻塞操作(如文件I/O和阻塞套接字I/O)。
Dispatchers.Unconfined -在当前调用帧中启动协程执行,直到第一次暂停,然后协程生成器函数返回。协程稍后将在相应的挂起函数使用的任何线程中恢复,而不将其限制在任何特定的线程或池中。无约束调度器通常不应在代码中使用。
HandlerContext -在主线程中调度任务,android中主线程也就是ui线程,使用该调度器谨慎ANR异常,不应该使用该调度器调度阻塞或者耗时任务。
可以使用newSingleThreadContext和newFixedThreadPoolContext创建专用线程池。
可以使用asCoroutineDispatcher扩展函数将任意执行器转换为调度器。
Dispatchers.Default
这个调度器的类型是DefaultScheduler,一般是做cpu密集计算型任务,内部包含的成员变量IO,也就是对应的Dispatchers.IO调度器。主要实现在ExecutorCoroutineDispatcher()中,代码如下:
internal object DefaultScheduler : ExperimentalCoroutineDispatcher() {
val IO: CoroutineDispatcher = LimitingDispatcher(
this,
systemProp(IO_PARALLELISM_PROPERTY_NAME, 64.coerceAtLeast(AVAILABLE_PROCESSORS)),
"Dispatchers.IO",
TASK_PROBABLY_BLOCKING
)
//省略。。。
}
public open class ExperimentalCoroutineDispatcher(
private val corePoolSize: Int,
private val maxPoolSize: Int,
private val idleWorkerKeepAliveNs: Long,
private val schedulerName: String = "CoroutineScheduler"
) : ExecutorCoroutineDispatcher() {
public constructor(//省略。。。)
override val executor: Executor
get() = coroutineScheduler
// This is variable for test purposes, so that we can reinitialize from clean state
private var coroutineScheduler = createScheduler()
override fun dispatch(context: CoroutineContext, block: Runnable): Unit =
try {
coroutineScheduler.dispatch(block)
} catch (e: RejectedExecutionException) {
DefaultExecutor.dispatch(context, block)
}
override fun dispatchYield(context: CoroutineContext, block: Runnable): Unit =
try {
coroutineScheduler.dispatch(block, tailDispatch = true)
} catch (e: RejectedExecutionException) {
DefaultExecutor.dispatchYield(context, block)
}
}
//省略。。。
}
Default调度器其实没做什么特别的操作,只是用coroutineScheduler代理实现了协程的调度。
Dispatchers.IO
这个是LimitingDispatcher类型的,是DefaultScheduler类型的成员变量,而LimitingDispatcher类型又是继承自ExecutorCoroutineDispatcher的,LimitingDispatcher在它基础上做了有调度个数限制的排队机制,IO这个名字代表的IO操作,IO操作又是阻塞线程的操作,线程不能及时释放,所以加入了队列机制,防止IO线程爆炸式增长。如下:
internal object DefaultScheduler : ExperimentalCoroutineDispatcher() {
val IO: CoroutineDispatcher = LimitingDispatcher(
this,
systemProp(IO_PARALLELISM_PROPERTY_NAME, 64.coerceAtLeast(AVAILABLE_PROCESSORS)),
"Dispatchers.IO",
TASK_PROBABLY_BLOCKING
)
//省略。。。
}
private class LimitingDispatcher(
private val dispatcher: ExperimentalCoroutineDispatcher,
private val parallelism: Int,
private val name: String?,
override val taskMode: Int
) : ExecutorCoroutineDispatcher(), TaskContext, Executor {
private val queue = ConcurrentLinkedQueue<Runnable>()
private val inFlightTasks = atomic(0)
private fun dispatch(block: Runnable, tailDispatch: Boolean) {
var taskToSchedule = block
while (true) {
// Commit in-flight tasks slot
val inFlight = inFlightTasks.incrementAndGet()
// Fast path, if parallelism limit is not reached, dispatch task and return
if (inFlight <= parallelism) {
dispatcher.dispatchWithContext(taskToSchedule, this, tailDispatch)
return
}
queue.add(taskToSchedule)
if (inFlightTasks.decrementAndGet() >= parallelism) {
return
}
taskToSchedule = queue.poll() ?: return
}
}
override fun dispatchYield(context: CoroutineContext, block: Runnable) {
dispatch(block, tailDispatch = true)
}
}
构造函数 传入了parallelism参数 ,这个是并发数。
dispatchYield方法 实现是直接调用的dispatch方法。
dispatch方法:一个while循环,循环内,
- 给inFlightTasks变量加一(这个变量代表正在调度中的个数),如果inFlightTasks <= parallelism,代表当前调度任务数小于最大并发数,说明可以继续向调度器中调度任务,
- 否则将任务加入到队列中,接着尝试将inFlightTasks减一,如果大于并发数,那么直接结束;
- 如果小于并发数,说明刚刚已经有任务结束了,让出了并发数,这个时候可以再次尝试从队列中取出任务,从1开始。
override fun afterTask() {
var next = queue.poll()
// If we have pending tasks in current blocking context, dispatch first
if (next != null) {
dispatcher.dispatchWithContext(next, this, true)
return
}
inFlightTasks.decrementAndGet()
next = queue.poll() ?: return
dispatch(next, true)
}
afterTask方法
这个方法是任务调度结束后的回调,这里面首先从队列中取出一个任务,
任务不为空,让调度器调度这个任务,结束;
为空,给调度任务数加一,然后尝试取出任务,为空返回,不为空,继续调用dispatch方法,整个流程就串起来了。
整个流程如下图所示:
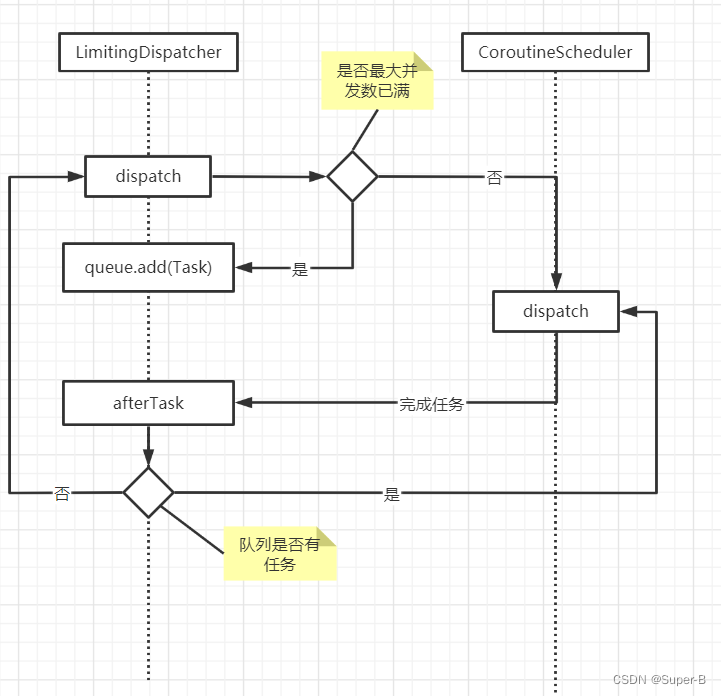
综上:IO调度器侧重于调度任务数量的限制,防止IO操作阻塞线程,让线程数量爆炸式增长。
Dispatchers.Main
具体的实现类是HandlerContext,代码如下:
HandlerContext(Looper.getMainLooper().asHandler(async = true))
internal class HandlerContext private constructor(
private val handler: Handler,
private val name: String?,
private val invokeImmediately: Boolean
) : HandlerDispatcher(), Delay {
//省略。。。
}
主线程中调度任务,android中主线程也就是ui线程。实现原理是内部持有一个val handler : Handler = Looper.getMainLooper().asHandler(async = true),这个handler正是主线程的handler。
在调用dispatch调度方法的时候,是使用handler发送一个Runnable任务,
override fun dispatch(context: CoroutineContext, block: Runnable) {
handler.post(block)
}
在delay的时候,如果当前的dispatcher正是HandlerContext,那么实现是handler发送一个延迟了timeMillis毫秒时长的Runnable。invokeOnCancellation的扩展方法是在协程被取消的时候,移除掉该runnable消息。
override fun scheduleResumeAfterDelay(timeMillis: Long, continuation: CancellableContinuation<Unit>) {
val block = Runnable {
with(continuation) { resumeUndispatched(Unit) }
}
handler.postDelayed(block, timeMillis.coerceAtMost(MAX_DELAY))
continuation.invokeOnCancellation { handler.removeCallbacks(block) }
}
下面这个方法也比较常看到,就是协程在调度continuation的时候,会去判断是不是需要去调度,不需要的话,直接在当前线程执行,需要调度的,需要由dispatcher来重新调度任务,这样可能执行的线程会被切换,如果不是主线程的话,、就需要调度了, 如果是主线程的话立刻执行。
override fun isDispatchNeeded(context: CoroutineContext): Boolean {
return !invokeImmediately || Looper.myLooper() != handler.looper
}
Dispatchers.Unconfined
具体的实现如下:
internal object Unconfined : CoroutineDispatcher() {
//省略。。。
}
isDispatchNeeded直接返回false,代表不需要重新调度。
override fun isDispatchNeeded(context: CoroutineContext): Boolean = false
dispatchYield没有被覆写,直接调用dispatch方法,用的还是CoroutineDispatcher的实现。
dispatch的报错信息显示,Unconfined调度器只能在存在YieldContext的时候调度,否则就会报异常。
//CoroutineDispatcher
public open fun dispatchYield(context: CoroutineContext, block: Runnable): Unit = dispatch(context, block)
//Unconfined
override fun dispatch(context: CoroutineContext, block: Runnable) {
// It can only be called by the "yield" function. See also code of "yield" function.
val yieldContext = context[YieldContext]
if (yieldContext != null) {
// report to "yield" that it is an unconfined dispatcher and don't call "block.run()"
yieldContext.dispatcherWasUnconfined = true
return
}
throw UnsupportedOperationException("Dispatchers.Unconfined.dispatch function can only be used by the yield function. " +
"If you wrap Unconfined dispatcher in your code, make sure you properly delegate " +
"isDispatchNeeded and dispatch calls.")
}
yied方法:是暂时让出工作线程,等待下一次线程调取恢复协程。
yield代码如下:
public suspend fun yield(): Unit = suspendCoroutineUninterceptedOrReturn sc@ { uCont ->
val context = uCont.context
context.checkCompletion()
val cont = uCont.intercepted() as? DispatchedContinuation<Unit> ?: return@sc Unit
if (cont.dispatcher.isDispatchNeeded(context)) {
cont.dispatchYield(context, Unit)
} else {
val yieldContext = YieldContext()
cont.dispatchYield(context + yieldContext, Unit)
if (yieldContext.dispatcherWasUnconfined) {
return@sc if (cont.yieldUndispatched()) COROUTINE_SUSPENDED else Unit
}
}
COROUTINE_SUSPENDED
}
- 如果isDispatchNeeded == true,那么就需要重新将协程被调度器调度一次,线程有可能切换掉;
- 如果isDispatchNeeded == false,上下文集合需要添加val yieldContext = YieldContext()这个元素(在上面的Dispatchers.Unconfined
的dispatche方法中,如果有YieldContext元素,将dispatcherWasUnconfined设置为true,代表yield操作什么都没有做,需要协程调度器用其他方法调度一次)。
判断dispatcherWasUnconfined,true:说明Dispatchers.Unconfined什么都没有做,需要在调度一次,调用了yieldUndispatched方法,这个方法大概就是让协程直接恢复一次,或者线程调度一次恢复;
false:说明正在被调度器调度,是个挂起点,返回COROUTINE_SUSPENDED值。
不太清楚Dispatchers.Unconfined这个调度器有啥用,有知道的留言下,学习学习。
协程调度器的实现CoroutineScheduler
调度过程正真的实现是CoroutineScheduler这个类,上面说的四种调度器是包装类,调度逻辑在CoroutineScheduler中,代码如下:
internal class CoroutineScheduler(
@JvmField val corePoolSize: Int,
@JvmField val maxPoolSize: Int,
@JvmField val idleWorkerKeepAliveNs: Long = IDLE_WORKER_KEEP_ALIVE_NS,
@JvmField val schedulerName: String = DEFAULT_SCHEDULER_NAME
) : Executor, Closeable {
//省略。。。
}
构造函数入参 corePoolSize: Int定义核心线程数,maxPoolSize: Int定义最大线程数量
fun dispatch(block: Runnable, taskContext: TaskContext = NonBlockingContext, tailDispatch: Boolean = false) {
val task = createTask(block, taskContext)
// try to submit the task to the local queue and act depending on the result
val currentWorker = currentWorker()
val notAdded = currentWorker.submitToLocalQueue(task, tailDispatch)
if (notAdded != null) {
if (!addToGlobalQueue(notAdded)) {
// Global queue is closed in the last step of close/shutdown -- no more tasks should be accepted
throw RejectedExecutionException("$schedulerName was terminated")
}
}
val skipUnpark = tailDispatch && currentWorker != null
// Checking 'task' instead of 'notAdded' is completely okay
if (task.mode == TASK_NON_BLOCKING) {
if (skipUnpark) return
signalCpuWork()
} else {
// Increment blocking tasks anyway
signalBlockingWork(skipUnpark = skipUnpark)
}
}
dispatch函数的实现:
- 创建task,block如果是Task类型的话,设置submissionTime变量,submissionTime变量用于延迟执行的时间判断,以及队列排序的时间顺序;设置taskContext,该变量是task执行的协程上下文。不是Task类型的话,会创建TaskImp类型的任务返回,关键是finally中的
taskContext.afterTask(),就是task执行完成后需要回调afterTask通知协程上下文执行完毕了,上面的Dispatchers.IO里面的LimitingDispatcher调度器就是需要afterTask回调通知,才能将队列中下一个任务抛给CoroutineScheduler去执行。
internal fun createTask(block: Runnable, taskContext: TaskContext): Task {
val nanoTime = schedulerTimeSource.nanoTime()
if (block is Task) {
block.submissionTime = nanoTime
block.taskContext = taskContext
return block
}
return TaskImpl(block, nanoTime, taskContext)
}
internal class TaskImpl(
@JvmField val block: Runnable,
submissionTime: Long,
taskContext: TaskContext
) : Task(submissionTime, taskContext) {
override fun run() {
try {
block.run()
} finally {
taskContext.afterTask()
}
}
}
- 获取当前的工作线程,如果当前是工作线程直接返回,不是的话返回空
private fun currentWorker(): Worker? = (Thread.currentThread() as? Worker)?.takeIf { it.scheduler == this }
- 将任务提交到工作线程的本地队列中
private fun Worker?.submitToLocalQueue(task: Task, tailDispatch: Boolean): Task? {
if (this == null) return task
if (state === WorkerState.TERMINATED) return task
if (task.mode == TASK_NON_BLOCKING && state === WorkerState.BLOCKING) {
return task
}
mayHaveLocalTasks = true
return localQueue.add(task, fair = tailDispatch)
}
返回是空的,说明添加成功了,返回task说明没有添加成功。
如果线程是中断状态,那么直接返回task。
如果任务是非阻塞的也就是cpu密集型任务,而线程是阻塞的(正在执行任务中),那么不添加任务,直接返回task。
其他情况,添加任务到队列中,mayHaveLocalTasks标志位true,代表当前线程中有任务。
- 没有添加的话,需要添加到全局队列中,globalCpuQueue全局cpu密集型队列,globalBlockingQueue全局IO队列,根据任务类型添加到对应的队列中。如果全局队列都添加失败的话,直接抛出异常。
if (notAdded != null) {
if (!addToGlobalQueue(notAdded)) {
// Global queue is closed in the last step of close/shutdown -- no more tasks should be accepted
throw RejectedExecutionException("$schedulerName was terminated")
}
}
val globalCpuQueue = GlobalQueue()
val globalBlockingQueue = GlobalQueue()
private fun addToGlobalQueue(task: Task): Boolean {
return if (task.isBlocking) {
globalBlockingQueue.addLast(task)
} else {
globalCpuQueue.addLast(task)
}
}
- 根据是否是尾部添加和当前线程是否是空,决定是否跳过唤醒工作线程的步骤。
val skipUnpark = tailDispatch && currentWorker != null
- 非阻塞任务:skipUnpark为true,跳过唤醒步骤,否则唤醒cpu密集型线程;阻塞任务:skipUnpark为true,跳过唤醒步骤,唤醒IO线程。
// Checking 'task' instead of 'notAdded' is completely okay
if (task.mode == TASK_NON_BLOCKING) {
if (skipUnpark) return
signalCpuWork()
} else {
// Increment blocking tasks anyway
signalBlockingWork(skipUnpark = skipUnpark)
}
看下唤醒步骤的具体实现,大概都是先tryUnpark,唤醒线程,如果没有唤醒成功,创建一个新的线程,再次尝试唤醒。
private fun signalBlockingWork(skipUnpark: Boolean) {
// Use state snapshot to avoid thread overprovision
val stateSnapshot = incrementBlockingTasks()
if (skipUnpark) return
if (tryUnpark()) return
if (tryCreateWorker(stateSnapshot)) return
tryUnpark() // Try unpark again in case there was race between permit release and parking
}
internal fun signalCpuWork() {
if (tryUnpark()) return
if (tryCreateWorker()) return
tryUnpark()
}
看下工作线程的具体实现吧:
worker继承自Thread,实现了run方法,具体是由runWorker()方法实现的,每个工作线程都有一个本地队列用于存储任务,这样本地有任务就不用去全局队列中去抢资源了,减少锁竞争。
internal inner class Worker private constructor() : Thread() {
//省略。。。
@JvmField
val localQueue: WorkQueue = WorkQueue()
@JvmField
var mayHaveLocalTasks = false
override fun run() = runWorker()
//省略。。。
}
runWorker() 的实现:
private fun runWorker() {
var rescanned = false
while (!isTerminated && state != WorkerState.TERMINATED) {
val task = findTask(mayHaveLocalTasks)
// Task found. Execute and repeat
if (task != null) {
rescanned = false
minDelayUntilStealableTaskNs = 0L
executeTask(task)
continue
} else {
mayHaveLocalTasks = false
}
if (minDelayUntilStealableTaskNs != 0L) {
if (!rescanned) {
rescanned = true
} else {
rescanned = false
tryReleaseCpu(WorkerState.PARKING)
interrupted()
LockSupport.parkNanos(minDelayUntilStealableTaskNs)
minDelayUntilStealableTaskNs = 0L
}
continue
}
tryPark()
}
tryReleaseCpu(WorkerState.TERMINATED)
}
工作线程是用while循环一直运行的,循环内:
val task = findTask(mayHaveLocalTasks),前面这个变量mayHaveLocalTasks出现过,在添加task到本地队列的时候,会置为true,本地队列有任务,从本地获取,没有就从全局队列中获取,如果还是没有,从其他线程队列中偷取任务到自己队列中:
fun findTask(scanLocalQueue: Boolean): Task? {
if (tryAcquireCpuPermit()) return findAnyTask(scanLocalQueue)
// If we can't acquire a CPU permit -- attempt to find blocking task
val task = if (scanLocalQueue) {
localQueue.poll() ?: globalBlockingQueue.removeFirstOrNull()
} else {
globalBlockingQueue.removeFirstOrNull()
}
return task ?: trySteal(blockingOnly = true)
}
trySteal方法,循环workers队列,遍历线程本地队列,去偷取任务,偷到的话返回任务,没偷到的话,返回null:
private fun trySteal(blockingOnly: Boolean): Task? {
//省略。。。
var currentIndex = nextInt(created)
var minDelay = Long.MAX_VALUE
repeat(created) {
//省略。。。
val worker = workers[currentIndex]
if (worker !== null && worker !== this) {
val stealResult = if (blockingOnly) {
localQueue.tryStealBlockingFrom(victim = worker.localQueue)
} else {
localQueue.tryStealFrom(victim = worker.localQueue)
}
if (stealResult == TASK_STOLEN) {
return localQueue.poll()
} else if (stealResult > 0) {
minDelay = min(minDelay, stealResult)
}
}
}
minDelayUntilStealableTaskNs = if (minDelay != Long.MAX_VALUE) minDelay else 0
return null
}
在偷不到任务的时候会设置一个变量,stealResult等于-2,最后minDelayUntilStealableTaskNs 等于0;
internal const val TASK_STOLEN = -1L
internal const val NOTHING_TO_STEAL = -2L
在偷取任务的时候,如果上个任务时间和这次时间间隔太短的话,返回下次执行的间隔时间差,minDelayUntilStealableTaskNs设置为这个时间值,大于0。
- 找到task了,直接执行任务
executeTask(task),执行完成,continue循环,从1开始; - 没找到任务,设置
mayHaveLocalTasks = false - 如果minDelayUntilStealableTaskNs不等于0,就是上面的间隔时间太短的条件触发,那么让线程释放锁(防止线程执行任务太过密集,等待下次循环再去调度任务),continue循环,从1开始;
- 上面条件不成立,调用tryPark(),这个是和unPark相反的操作,让线程闲置,放入到线程队列中:
private fun tryPark() {
if (!inStack()) {
parkedWorkersStackPush(this)
return
}
assert { localQueue.size == 0 }
workerCtl.value = PARKED // Update value once
while (inStack()) { // Prevent spurious wakeups
if (isTerminated || state == WorkerState.TERMINATED) break
tryReleaseCpu(WorkerState.PARKING)
interrupted() // Cleanup interruptions
park()
}
}
首先判断是否在队列中,不在的话,放入线程队列中;在队列中,将状态设置为PARKED,不断循环将释放线程的cpu占用锁,尝试放到队列中,park函数中有可能销毁工作线程,看线程是否到达死亡时间点。
worker工作流程如下图所示:
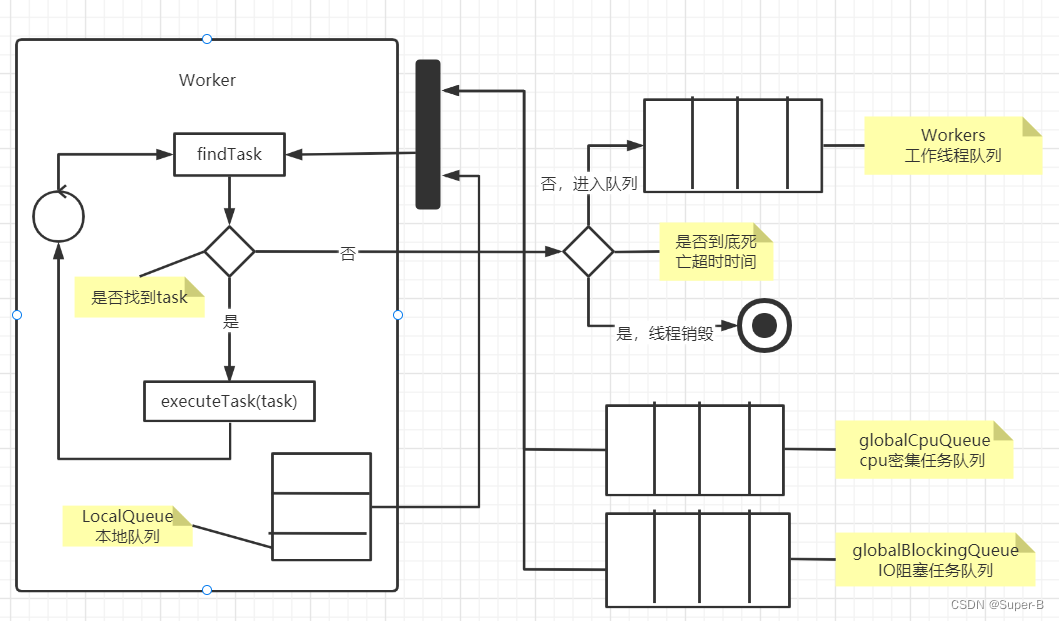
总结
1. Dispatchers的四种调度器是饿汉式单例对象,所以一个进程只存在一个实例对象。
2. Dispatchers的四种调度器中,IO和default是共用的一个线程池,它的实现是CoroutineScheduler。
3. CoroutineScheduler线程池,有一个保存线程的队列,有两种全局任务队列:一个是IO阻塞型队列,一个是cpu密集型任务队列;Worker线程拥有一个本地任务队列。
4. Worker线程会根据任务类型,去对应的全局队列或者从本地队列找任务,找不到会从其他worker队列中偷任务,然后执行;worker会根据自己的状态回到线程队列或者销毁自己。

![图书管理系统(Java实现)[附完整代码]](https://img-blog.csdnimg.cn/de47c8fe281d40b2acb0bfe054ca268e.png)






![[附源码]java毕业设计物理中考复习在线考试系统](https://img-blog.csdnimg.cn/baccf72d81e643938e123886630aadff.png)