大家好,我是飘渺。
今天咱们继续更新Kubernetes云原生实战系列,如何基于上篇文章中提到的部署架构进行磁盘分区、格式化、挂载目录。
看到这里估计很多人要直接就关掉了:磁盘分区格式化不是运维的事吗,跟我开发有什么关系?
理论上确实没什么关系,但是面试的时候面试官不也经常问你如何保证redis高可用,消息队列高可用吗?那时候可不敢说跟开发没关系~
所以作为一名光(KU)荣(BI)的开发,咱要有这样一个觉悟:运维会的我们要会,运维不会的我们也要会!
磁盘挂载分析
首先我们来分析一下需要对哪些目录进行挂载
- 首先,master和worker节点都需要一个容器运行时环境,目前还是建议直接使用docker。使用docker的时候我们都知道,容器数据是存储在
/var/lib/docker这个目录的,在使用和操作过程中数据量会逐渐增加,所以建议为/var/lib/docker单独挂载一个硬盘。 - master节点需要安装etcd,etcd数据会存放在
/var/lib/etcd这个目录下,生产环境也建议直接给它挂载一个硬盘。 - worker节点会安装ceph存储,ceph存储需要有一块未格式化的磁盘。
所以结论如下:
- master 节点需要分两个区,分别需要挂载
/var/lib/docker和/var/lib/etcd目录 - worker 节点需要分两个区,一个用于挂载
/var/lib/docker目录,一块不要格式化并将其预留给ceph。 - 对于负载均衡器这个没要求,直接使用系统盘即可
磁盘分区挂载实战
master节点
master节点我们预备了160G,其中docker使用100G,etcd使用60G(其实etcd只需要10G左右就够了)
- 查看磁盘挂载情况
df -h
[root@k8s-master1 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 16G 0 16G 0% /dev
tmpfs 16G 0 16G 0% /dev/shm
tmpfs 16G 33M 16G 1% /run
tmpfs 16G 0 16G 0% /sys/fs/cgroup
/dev/vda2 49G 2.4G 47G 5% /
/dev/vda1 1014M 142M 873M 14% /boot
tmpfs 3.2G 0 3.2G 0% /run/user/0
可以发现并未有磁盘挂载。
- 查看磁盘分区情况
[root@k8s-master1 ~]# fdisk -l
磁盘 /dev/vda:53.7 GB, 53687091200 字节,104857600 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x000cdd7e
设备 Boot Start End Blocks Id System
/dev/vda1 * 2048 2099199 1048576 83 Linux
/dev/vda2 2099200 104857566 51379183+ 83 Linux
磁盘 /dev/vdb:107.4 GB, 107374182400 字节,209715200 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0xfe180011
设备 Boot Start End Blocks Id System
磁盘 /dev/vdc:64.4 GB, 64424509440 字节,125829120 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0xa9b4219c
设备 Boot Start End Blocks Id System
可以发现有两块空磁盘,/dev/vdb100G 和 /dev/vdc 60G,接下来需要对其进行分区格式化
- 对2块磁盘分别进行分区,以
/dev/vdb为例
使用fdisk命令进行分区
fdisk /dev/vdb
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pHpGEwUA-1668998479804)(https://img.javadaily.cn/uPic/image-20220331202902797.png)]
说明:
-
输入n进行分区,d删除分区
-
选择分区类型
这里有两个选项(推荐选择P):
p: 主分区 linux上主分区最多能有4个,如果要分多个区那就依次选1、2、3、4
e:扩展分区 linux上扩展分区只能有1个,扩展分区创建后不能直接使用,还要在扩展分区上创建逻辑分区。
-
选择分区个数,可以选择4个分区,这里只需要分成1个区
-
设置柱面,这里选择默认值就可以,这里所有空间就会被分到一个区
-
输入w,写入分区表,进行分区
对/dev/vdb分完区后按照同样的步骤对/dev/vdc进行分区。
分区完成后再次查看磁盘分区情况
fdisk -l
可以看到磁盘/dev/vdb下已经有了一个分区/dev/vdb1,而/dev/vdc磁盘下也已经有了分区/dev/vdc1
- 使用
mkfs.ext4对分区后的磁盘进行格式化
[root@k8s-master1 ~]# mkfs.ext4 /dev/vdb1
mke2fs 1.42.9 (28-Dec-2013)
/dev/vdb1 已经挂载;will not make a 文件系统 here!
[root@k8s-master1 ~]# mkfs.ext4 /dev/vdc1
mke2fs 1.42.9 (28-Dec-2013)
/dev/vdc1 已经挂载;will not make a 文件系统 here!
- 挂载磁盘
# 查看格式化后的UUID,用于挂载使用
[root@k8s-master1 ~]# blkid
/dev/vda2: UUID="5a00d5df-880e-4f76-b61d-d712d353e8d9" TYPE="xfs"
/dev/vda1: UUID="2d10a1a9-0917-4162-a4ed-589a26127875" TYPE="xfs"
/dev/vdb1: UUID="b3351cfa-5623-4633-b4a6-9baab1d8e2d4" TYPE="ext4"
/dev/vdc1: UUID="3543f03e-0b16-4271-8601-f7f0b2222a92" TYPE="ext4"
/dev/sr0: UUID="2022-03-30-15-13-58-00" LABEL="config-2" TYPE="iso9660"
可以看到格式化后的vdb1的uuid为b3351cfa-5623-4633-b4a6-9baab1d8e2d4,vdc1的UUID为3543f03e-0b16-4271-8601-f7f0b2222a92
编辑/etc/fstab文件,在最后一行加上需要挂载的磁盘UUID,并设置磁盘格式为ext4
#
# /etc/fstab
# Created by anaconda on Thu May 14 10:38:44 2020
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
UUID=5a00d5df-880e-4f76-b61d-d712d353e8d9 / xfs defaults 0 0
UUID=2d10a1a9-0917-4162-a4ed-589a26127875 /boot xfs defaults 0 0
UUID=b3351cfa-5623-4633-b4a6-9baab1d8e2d4 /var/lib/docker ext4 defaults 0 0
UUID=3543f03e-0b16-4271-8601-f7f0b2222a92 /var/lib/etcd ext4 defaults 0 0
分区挂载完成后手动挂载确认配置是否正常
mount -a
- 验证分区挂载情况,可以看到已经给
/var/lib/docker和/var/lib/etcd挂载了分区
[root@dev-k8s-master3 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 16G 0 16G 0% /dev
tmpfs 16G 0 16G 0% /dev/shm
tmpfs 16G 8.6M 16G 1% /run
tmpfs 16G 0 16G 0% /sys/fs/cgroup
/dev/vda2 49G 2.4G 47G 5% /
/dev/vdc1 59G 53M 56G 1% /var/lib/etcd
/dev/vdb1 99G 61M 94G 1% /var/lib/docker
/dev/vda1 1014M 142M 873M 14% /boot
tmpfs 3.2G 0 3.2G 0% /run/user/0
- 挂载完成后建议重启机器
[root@k8s-slb ~]# reboot
挂载worker节点
worker节点挂载操作同master节点,不过需要注意的是,worker节点总共500G,我们需要将其中的100G独立分区并挂载到/var/lib/docker,剩下的400G用作ceph存储使用,切记ceph的分区不需要格式化。
主体操作就不再演示,只需要关注将其分成2个区即可。
第一次分区:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QAnhv6UC-1668998479804)(https://img.javadaily.cn/uPic/image-20220629220435490.png)]
分区完成后查看分区情况
[root@k8s-worker1 ~]# fdisk -l
磁盘 /dev/vda:53.7 GB, 53687091200 字节,104857600 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x000cdd7e
设备 Boot Start End Blocks Id System
/dev/vda1 * 2048 2099199 1048576 83 Linux
/dev/vda2 2099200 104857566 51379183+ 83 Linux
磁盘 /dev/vdb:536.9 GB, 536870912000 字节,1048576000 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0xb098e2fd
设备 Boot Start End Blocks Id System
/dev/vdb1 2048 209717247 104857600 83 Linux
可以看到vdb总共536.9G,一个分区/dev/vdb1占用了100G空间,接着再对vdb进行第二次分区。
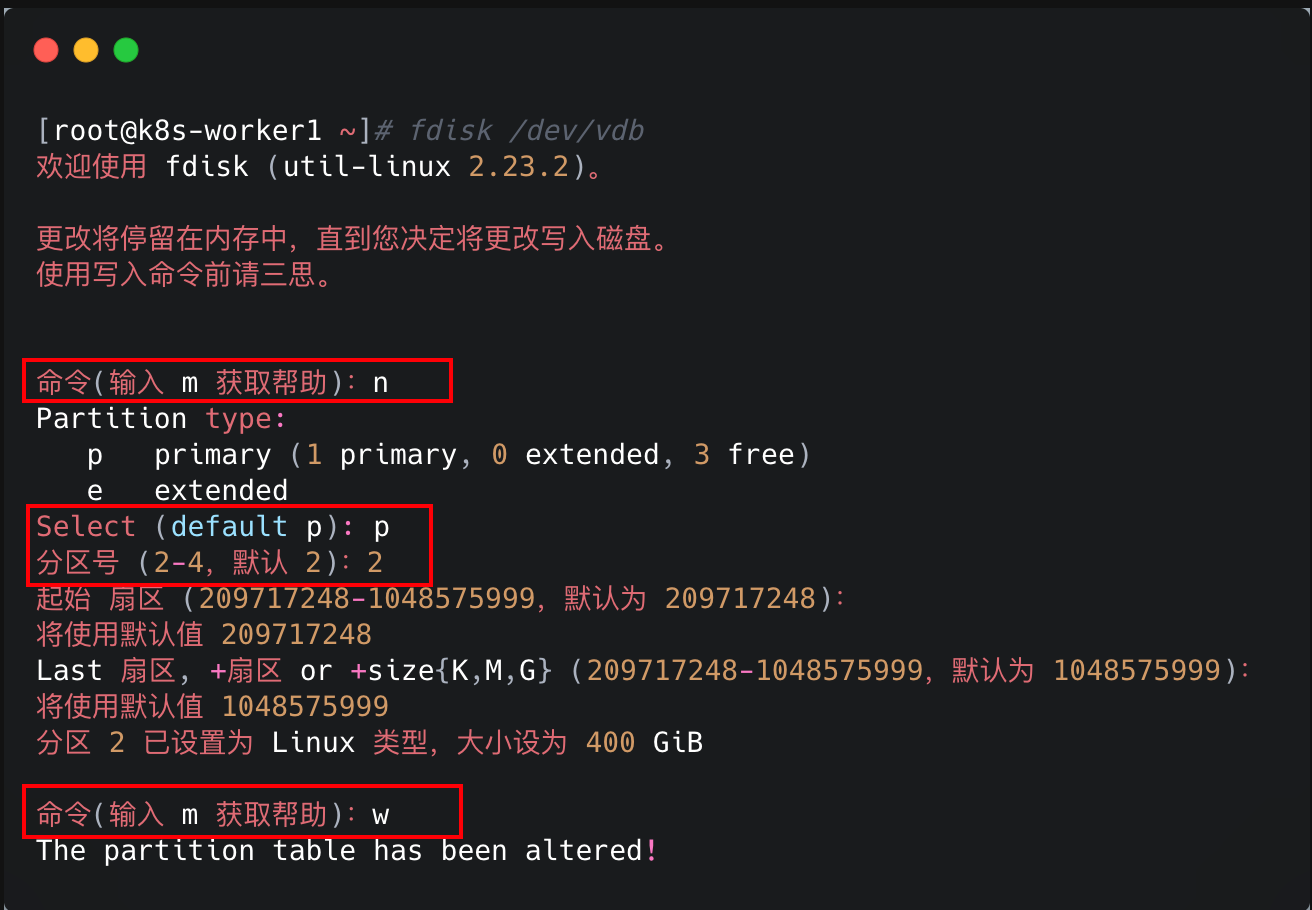
剩下的步骤如格式化、挂载、验证可以参考master节点。
切记,只需要挂载第一个100G的分区给/var/lib/docker,剩下的分区预留给ceph,不需要格式化挂载。
小结
正常情况下磁盘分区是运维工程师的事,不过有句话叫 “技多不压身”,多会点总不是坏事。
各位在生产环境使用docker的时候一定不要忘记分区挂载,或者提醒运维给你挂载好目录。还记得很早之前我们使用docker部署应用,由于未给其单独挂载磁盘,/var/lib/docker默认使用系统盘空间,用了一段时间后就收到磁盘空间报警(系统盘只分配了50G),现在想起来还是觉得好笑。
好了,今天的文章到这里就要结束了。如果你喜欢这个系列,请不要吝啬你的一键三连。同时也欢迎你把这个系列分享给你的朋友,我们一起进步。。。我们下期再见。
![图书管理系统(Java实现)[附完整代码]](https://img-blog.csdnimg.cn/de47c8fe281d40b2acb0bfe054ca268e.png)






![[附源码]java毕业设计物理中考复习在线考试系统](https://img-blog.csdnimg.cn/baccf72d81e643938e123886630aadff.png)