Hadoop 基础知识综述
在当今大数据领域,Hadoop 已然成为处理海量数据的关键技术之一。本文将对 Hadoop 的基础知识进行专业阐述,以助力读者全面了解这一强大的分布式计算框架。
一、Hadoop 概述
Hadoop 是一个开源的分布式计算框架,主要用于存储和处理大规模数据集。其设计初衷是在由普通硬件构成的集群上运行,具备高可靠性、高扩展性和高效性。Hadoop 基于谷歌的 MapReduce 和 Google File System(GFS)的理念开发,能够在数千台服务器上并行处理数据,使得大数据处理更加便捷高效。
二、Hadoop 核心组件
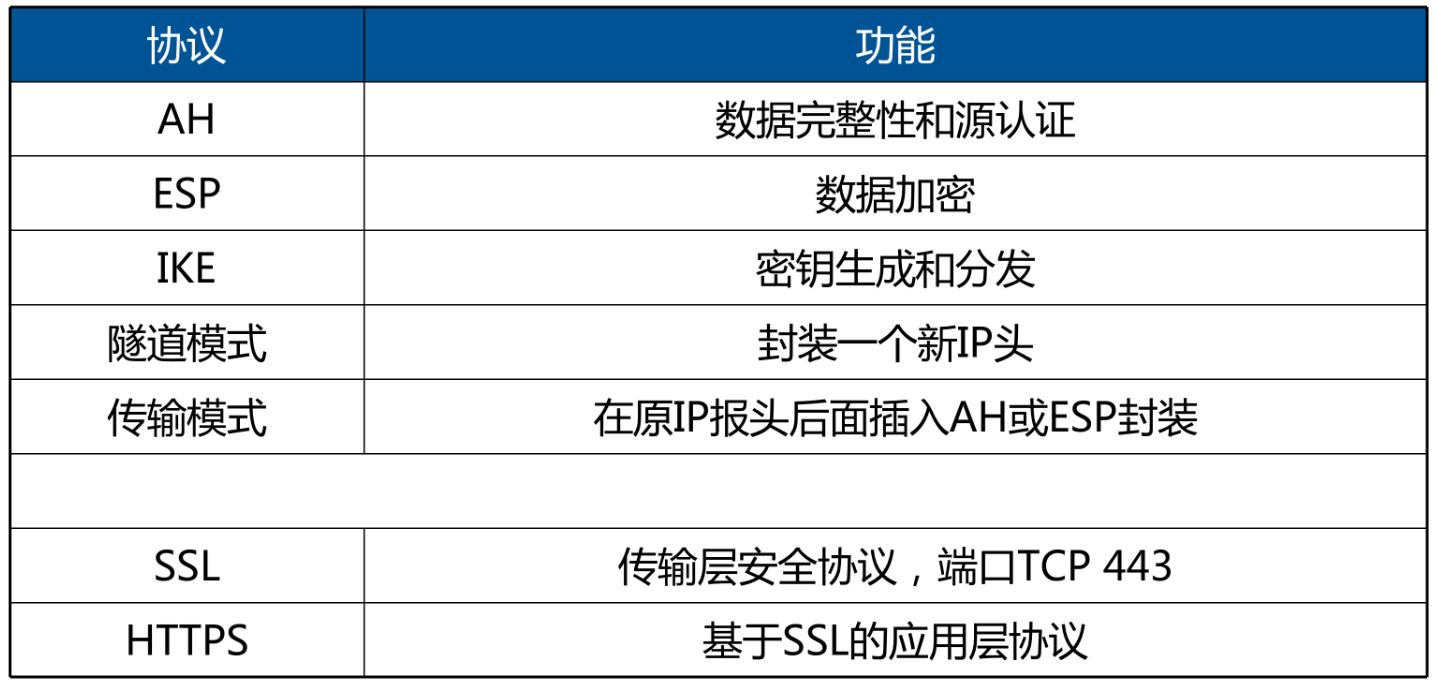
(一)Hadoop 分布式文件系统(HDFS)
- 架构
- HDFS 采用主从(Master-Slave)架构体系。主要由一个 NameNode 和多个 DataNode 组成。
- NameNode 作为 HDFS 的管理节点,负责管理文件系统的命名空间、目录结构、文件和块的元数据等。犹如文件系统的“核心中枢”,存储着文件系统的全部元信息。
- DataNode 是 HDFS 的存储节点,负责实际存储数据块。数据以块(block)的形式存储在 DataNode 上,默认块大小为 128MB(在 Hadoop 3.x 中可进行配置)。每个数据块会在多个 DataNode 上进行冗余备份,以提升数据的可靠性。
- 数据存储原理
- 当用户向 HDFS 写入文件时,文件会被分割成多个数据块。NameNode 会依据数据块的副本策略(通常为默认 3 份),确定每个数据块在哪些 DataNode 上存储。随后,客户端将数据块直接写入对应的 DataNode。DataNode 会定期向 NameNode 发送心跳信号和块报告,以告知 NameNode 自身的状态以及所存储的数据块信息。
- 当用户读取文件时,客户端首先向 NameNode 请求文件的元数据,包括文件块的位置信息。接着,客户端直接从 DataNode 读取数据块,并将它们合并成完整的文件。
- 优势
- 高容错性:数据块的冗余存储使得 HDFS 能够在节点故障时自动恢复数据,确保数据的可靠性。
- 适用于大规模数据存储:能够存储海量数据,并且可通过增加 DataNode 轻松扩展存储容量。
- 流式数据访问:适合一次写入、多次读取的大规模数据集处理场景,对于顺序读取数据具有很高的效率。
(二)MapReduce
- 原理
- MapReduce 是一种编程模型,用于大规模数据集的并行处理。它将计算任务划分为两个阶段:Map 阶段和 Reduce 阶段。
- Map 阶段:每个输入记录都会被一个 Map 函数处理。Map 函数会读取输入数据,对其进行处理,并产生一组中间键值对。例如,在一个单词计数的应用中,Map 函数可能会将每一行文本分割成单词,并输出每个单词及其出现次数为键值对(如<单词,1>)。
- Reduce 阶段:Reduce 函数会接收具有相同键的所有中间键值对,并对它们进行合并和进一步处理,最终产生输出结果。在单词计数示例中,Reduce 函数会将所有相同单词的出现次数相加,得到每个单词在整个数据集中的总出现次数。
- 工作流程
- 输入数据首先会被分割成多个输入分片(Input Split),每个分片会由一个 Map 任务处理。
- Map 任务在处理完输入分片后,会将产生的中间键值对进行分区(Partition),相同分区的数据会被发送到同一个 Reduce 任务。
- 在 Reduce 任务执行之前,会对中间数据进行排序(Sort)和合并(Combine,可选)操作,以提高处理效率。
- Reduce 任务处理完数据后,会将最终结果输出到 HDFS 或其他存储系统。
- 优点
- 易于编程:开发人员只需关注 Map 和 Reduce 函数的实现,无需操心分布式计算的细节,如数据分区、任务调度等。
- 高度可扩展性:可以在数千台服务器上并行运行,处理大规模数据。
- 容错性:Hadoop 能够自动处理任务失败,重新调度失败的任务,保证计算的可靠性。
三、Hadoop 的其他重要组件
(一)YARN(Yet Another Resource Negotiator)
- 作用
- YARN 是 Hadoop 2.0 引入的资源管理系统,负责整个集群的资源管理和调度。
- 它将资源管理和作业调度分离,使得 Hadoop 能够支持更多类型的计算框架,如 Spark、Flink 等在 Hadoop 集群上运行。
- 架构
- YARN 主要由三个组件组成:ResourceManager、NodeManager 和 ApplicationMaster。
- ResourceManager:是集群资源的管理者,负责整个集群资源的分配和调度。它接收来自各个节点的资源报告,并根据应用程序的资源需求分配资源。
- NodeManager:运行在每个计算节点上,负责管理本节点的资源,如 CPU、内存、磁盘等。它会定期向 ResourceManager 汇报本节点的资源使用情况,并接收 ResourceManager 的指令来启动和停止任务。
- ApplicationMaster:每个应用程序都会有一个 ApplicationMaster,它负责向 ResourceManager 申请资源,并与 NodeManager 协同工作来执行任务。例如,在一个 MapReduce 作业中,ApplicationMaster 会负责协调 Map 任务和 Reduce 任务的执行,监控任务的进度和状态。
- 资源调度策略
- YARN 支持多种资源调度策略,如 FIFO(First In First Out,先进先出)、Capacity Scheduler(容量调度器)和 Fair Scheduler(公平调度器)。
- FIFO 调度策略按照作业提交的顺序执行,先提交的作业先执行,适用于单个大作业的场景。但在多用户环境下,可能会导致一些小作业长时间等待。
- Capacity Scheduler 允许为不同的用户或队列分配一定的资源容量,保证每个队列都能获得一定的资源来运行作业。它适合多用户、多团队共享集群资源的场景,可以根据用户需求进行资源分配的定制。
- Fair Scheduler 旨在为所有运行的作业提供公平的资源分配,使每个作业都能获得大致相等的资源份额。它会根据作业的资源需求和运行时间动态调整资源分配,确保小作业也能及时得到处理。
(二)Hive
- 简介
- Hive 是基于 Hadoop 的一个数据仓库工具,它可以将结构化的数据文件映射为一张数据库表,并提供类似 SQL 的查询语言(HiveQL),使得用户能够方便地进行海量数据的离线处理和分析。
- Hive 本质上是将 HiveQL 语句转换为 MapReduce 任务在 Hadoop 集群上执行,因此它适合处理大规模的、对实时性要求不高的数据处理任务。
- 数据模型
- Hive 支持多种数据模型,包括表(Table)、分区(Partition)和桶(Bucket)。
- 表:是 Hive 中最基本的数据存储单元,类似于关系数据库中的表。可以定义表的结构,包括列名、数据类型等。
- 分区:是为了方便数据管理和查询优化而引入的概念。可以根据某个字段(如日期)对表进行分区,不同分区的数据存储在不同的目录下。这样在查询时,可以根据分区条件快速定位到需要的数据,减少数据扫描量。
- 桶:是对表或分区进行进一步划分的方式,它是根据某个字段的值进行哈希划分,将数据分配到不同的桶中。桶的作用主要是用于数据采样和一些基于哈希的查询优化。
- HiveQL 基本操作
- 创建表:可以使用
CREATE TABLE语句创建 Hive 表,并指定表的结构和存储格式等。例如:
CREATE TABLE student (
id INT,
name STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
- 插入数据:可以使用
INSERT INTO或LOAD DATA语句向表中插入数据。例如:
-- 从本地文件系统加载数据到表中
LOAD DATA LOCAL INPATH '/path/to/data.csv' INTO TABLE student;
-- 通过查询结果插入数据
INSERT INTO TABLE student2 SELECT id, name FROM student WHERE age > 18;
- 查询数据:使用
SELECT语句进行数据查询,其语法与标准 SQL 类似。例如:
SELECT name, age FROM student WHERE age > 20 ORDER BY age DESC;
(三)HBase
- 简介
- HBase 是一个分布式的、面向列的开源数据库,它基于 Hadoop HDFS 存储,提供了对大规模数据的实时读写访问能力。
- HBase 适合存储需要随机读写、实时性要求较高的大数据集,如物联网数据、用户行为数据等。
- 数据模型
- HBase 表由行键(Row Key)、列族(Column Family)和列限定符(Column Qualifier)组成。
- 行键:是表中每行数据的唯一标识,用于快速查找和排序数据。行键的设计非常重要,它会影响数据在 HBase 中的存储分布和查询性能。
- 列族:是一组相关列的集合,在创建表时需要预先定义列族。列族中的列可以动态添加,每个列都有一个时间戳,用于记录数据的版本。
- 列限定符:用于进一步区分列族中的列,它和列族一起构成了列的完整标识。例如,一个表中有一个列族
info,其中可以包含列限定符name、age等。
- 操作示例
- 创建表:
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.TableDescriptor;
import org.apache.hadoop.hbase.client.TableDescriptorBuilder;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseCreateTableExample {
public static void main(String[] args) throws Exception {
// 创建 HBase 配置
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
// 创建 HBase 连接
Connection connection = ConnectionFactory.createConnection(config);
// 获取 HBase 管理员
Admin admin = connection.getAdmin();
// 定义表名
String tableName = "my_table";
// 定义列族
byte[] family1 = Bytes.toBytes("cf1");
byte[] family2 = Bytes.toBytes("cf2");
// 创建表描述符
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(Bytes.toBytes(tableName));
tableDescriptorBuilder.setColumnFamily(TableDescriptorBuilder.newBuilder(family1).build());
tableDescriptorBuilder.setColumnFamily(TableDescriptorBuilder.newBuilder(family2).build());
// 创建表
admin.createTable(tableDescriptorBuilder.build());
// 关闭连接
admin.close();
connection.close();
}
}
- 插入数据:
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseInsertDataExample {
public static void main(String[] args) throws Exception {
// 创建 HBase 配置
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
// 创建 HBase 连接
Connection connection = ConnectionFactory.createConnection(config);
// 获取表
Table table = connection.getTable(Bytes.toBytes("my_table"));
// 插入数据
Put put = new Put(Bytes.toBytes("row1"));
put.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("value1"));
put.addColumn(Bytes.toBytes("cf2"), Bytes.toBytes("col2"), Bytes.toBytes("value2"));
table.put(put);
// 关闭表和连接
table.close();
connection.close();
}
}
- 查询数据:
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseQueryDataExample {
public static void main(String[] args) throws Exception {
// 创建 HBase 配置
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
// 创建 HBase 连接
Connection connection = ConnectionFactory.createConnection(config);
// 获取表
Table table = connection.getTable(Bytes.toBytes("my_table"));
// 创建扫描器
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("col1"));
// 扫描数据
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
byte[] value = result.getValue(Bytes.toBytes("cf1"), Bytes.toBytes("col1"));
System.out.println("Value: " + Bytes.toString(value));
}
// 关闭扫描器和表
scanner.close();
table.close();
connection.close();
}
}
四、Hadoop 的安装与配置
- 系统要求
- Hadoop 能够运行在多种操作系统上,如 Linux(推荐)、Windows(需要一些额外配置)等。
- 硬件要求:一般需要具备足够的内存(建议至少 4GB 以上)、CPU 核心数以及磁盘空间,具体要求依据数据规模和处理任务而定。
- 安装步骤(以 Linux 为例)
- 下载 Hadoop 安装包:可从 Hadoop 官方网站(https://hadoop.apache.org/)下载合适的版本。
- 解压安装包:将下载的压缩包解压至指定目录,如
/opt/hadoop。 - 配置环境变量:编辑
~/.bashrc文件,添加 Hadoop 的相关环境变量,例如:
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 配置 Hadoop 文件:
hadoop-env.sh:设置 Java 环境变量,指定 JAVA_HOME。core-site.xml:配置 HDFS 的 NameNode 地址和端口等信息,例如:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml:配置 HDFS 的相关参数,如数据块副本数、数据存储目录等,例如:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/data/datanode</value>
</property>
</configuration>
mapred-site.xml(如果是 Hadoop 2.x 及以上版本,需要从模板文件复制并命名为mapred-site.xml):配置 MapReduce 的相关参数,如作业运行模式等,例如:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml:配置 YARN 的相关参数,如 ResourceManager 地址和端口等,例如:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 格式化 HDFS 文件系统(首次使用时需要执行):
hdfs namenode -format
- 启动 Hadoop 集群:
- 启动 HDFS:
start-dfs.sh
- 启动 YARN:
start-yarn.sh
- 验证安装
- 可以通过浏览器访问 Hadoop 的 Web 界面来验证安装是否成功。例如,访问 NameNode 的 Web 界面
http://localhost:50070(默认端口可能会因配置不同而有所变化),可以查看 HDFS 的相关信息,如文件系统状态、节点信息等。 - 也可以在命令行执行一些 Hadoop 命令,如
hadoop fs -ls /查看 HDFS 根目录下的文件和目录。