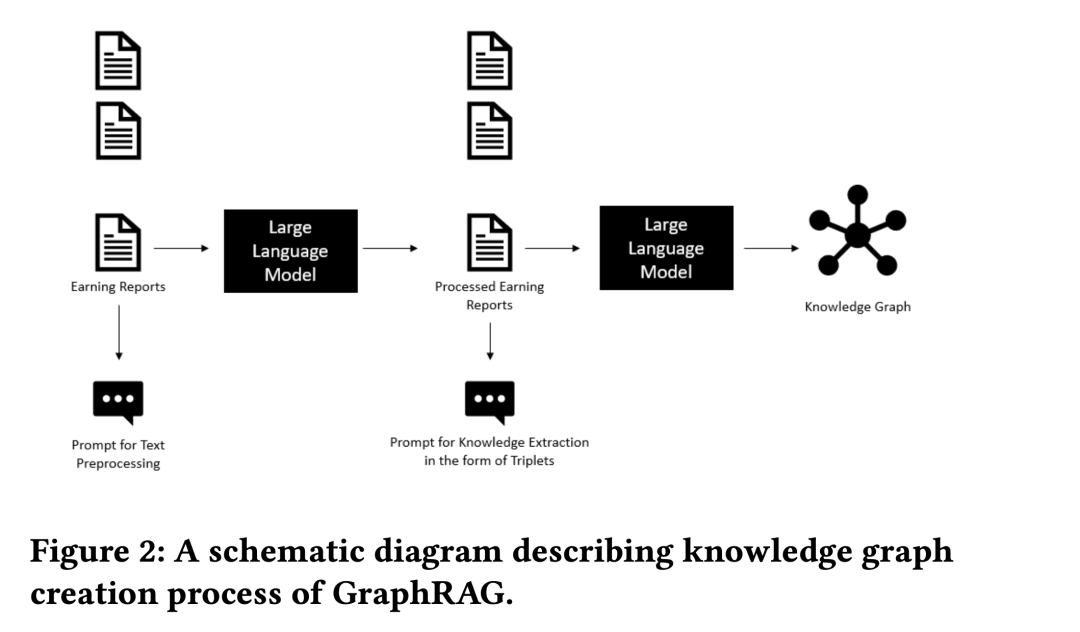
本文对近几月我了解到的RAG优化策略进行总结, 每个优化策略都有相应的研究论文作为支撑。在01先总结优化方向, 02细化说明相应论文
在介绍RAG优化策略之前, 先说说知识库数据处理:
增强数据粒度:旨在提升文本标准化、一致性、事实准确性和丰富的上下文,以提高 RAG 系统的性能。比如删除不相关的信息、消除实体和数据中的歧义、更新过时文档等。
添加元数据:将引用的元数据(如日期和用途)集成到块中以进行过滤,并合并元数据以提高检索效率。
数据源可以分为非结构化数据 , 结构化数据 和 LLM 生成的内容 ,目前主要是非结构化数据。除了外部知识外,LLM 本身的知识也至关重要。这个会在自适应检索提到, 而像HyDE这种LLM对问题初步回答, 也是利用了LLM本身的知识。
说到这, 整个RAG有这个基本矛盾: LLM训练时自己的知识learned memory和RAG或长文本窗口提供的外部知识的矛盾in context memory
LLM 可能会过度依赖检索到的内容,而忽略本身已经学习到的知识, 也可能即使检索到相关内容, 输出也没有与检索到的相关段落一致。这要看模型是否明确地被训练指导去利用和遵循提供的外部内容
另一个RAG基本矛盾是外部知识增多对大模型回答质量的影响是倒U形, 检测更多相关信息是会提高准确率, 但检测到太多不相关的噪音内容会对模型性能有损害。这是另一个需要考虑的
01
(1)根据问题进行优化
问题意图关键信息提取, 问题细化 : 在检索阶段筛选query表达的真实意图,提取query最相关信息,见Shortwave ; 对比较粗粒度的query拆解成更详细具体的子问题,来提升检索质量, 见RA-ISF
LLM对问题初步回答,提供线索支撑: 对问题先让LLM生成可能回答 ,再将该回到传递给检索器, 检索会比较真实文档和GPT回答内容的差异, 来增加检索内容与问题的相关性, 见HyDE ; 根据问题, 一个负责存储记忆的LLM利用内存和数据库记忆存储, 提供跟问题相关的线索,再让检索器根据线索指导去检索, 见MemoRAG
(2)混合检索
混合向量检索和传统的检索方式,如BM25检索见Standard RAG、全文检索见Shortwave,以及一些更传统的搜索来弥补向量检索的模糊性。
(3)Chunk独立分词导致的缺乏上下文理解
针对Chunk的目前常见优化一是重叠的chunk切割方案;
二是先对整个文档进行总结归纳,基于总结构建一级索引,文档的 Chunk 构建二级索引,检索时先从总结索引中检索。与此有些类似的技术是提示词压缩(Prompt Compression)可以重点压缩不相干的上下文,突出关键段落,减少整体上下文长度。
而其他更灵活的解决方法有:
像GraphRAG, HippoRAG, HybridRAG,GNN,DALK增加知识图谱,解决分词独立编码导致缺少上下文背景, 很难回答需要跨段落总结的问题; RAPTOR则利用知识树让文本对上下文有更多理解;
Anthropic的Standard RAG让Claude先对chunk生成解释性上下文, 让LLM再检索时不仅检索chunk, 也检索这段GPT生成的解释性context,让检索器更好理解这段文本 ;
Late Chunking通过先嵌入再分割让注意力层先学习理解相应内容后再分割, 让LLM理解"它"等代词;
RAPTOR对文本块chunk进行聚类,并生成这些聚类的文本摘要,自下而上地构建出一个结构化的树形模型
这里额外多说一句, Chunk大小和上下文窗口大小的关系:
Chunk 太大时:如果每个 Chunk 包含过多信息,可能会超出大语言模型的上下文窗口大小限制。大部分 LLM 有一个固定的上下文窗口,也就是一次可以处理的最大文本长度。如果 Chunk 太大,模型可能无法一次读取和理解所有信息,这会导致重要的信息丢失或无法进行完整的推理。有时还需要考虑 prompt 占据的长度,为 prompt 留下足够空间
Chunk 太小时:如果每个 Chunk 过小,虽然不会超过上下文窗口的限制,但可能会把本该连在一起的相关信息分割开来。例如,一段话中的上下文信息可能被分成不同的 Chunk,导致模型无法看到完整的信息来做出正确的理解或推理,影响检索的质量,最终降低模型的准确性和效果
因此, 也出现像LongRAG, GLM4 Long这样的项目来扩大检索器, 阅读器和分词单元的长度。
(4)迭代、递归检索
迭代检索允许模型参与多个检索周期,从而增强获得信息的深度和相关性,为 LLM 生成提供更全面的知识库。
这里没必要对迭代和递归做区分 ,我理解的就是迭代, 一般都是设计的迭代
FunSearch在生成提示、模型生成程序、评估、存储的不断循环中保持生成程序总是最好的
EfficientRAG会结合原始查询生成一个新的、更具体的查询,以用于下一轮检索。
递归检索是指可以将之前的检索输出作为后续的检索输入。递归检索通常用于需要渐进式收敛到最终答案的场景 ,比如学术研究、法律案例分析等。针对多级索引(比如摘要索引,Chunk 索引),可以使用递归检索;此外,针对具有图结构的数据源,使用递归检索也可以检索更全面的信息。
(5)自适应检索
RA-ISF的文章相关性模块PRM跟下面介绍的re rank重排序思想类似, 但不需要非得排序, 找不到相关内容可以直接不检索, 让LLM直接回答。像这种需要LLM自己判断是否使用检索内容的, 就是自适应检索
Self RAG也是, 检索到的内容会比较相关性、支持有用性或完整性, 检索到的内容谁最相关 ,最有用, 最完整, 该内容就排在前面, 实在没有相关内容直接不检索, 用LLM训练时学会的内容回答
(6) rerank重排序
传统排序是根据相似度大小排序,排序还可以考虑知识密度, 知识颗粒度, 多样性, LLM对内容的敏感度等考量因素。
OP-RAG也计算了相识度但是按照原文顺序排序;还有更复杂的重排序, 如Shortwave的MiniLM排序还考虑了回答和问题的匹配性, 并且能对索引到的内容进行boost or penalize , Self RAG跟Shortwave类似, 检索到的内容会比较相关性、支持有用性或完整性, 检索到的内容谁最相关 ,最有用, 最完整, 该内容就排在前面。
- Search Module :这里的 Search 模块专指针对特定应用场景的模块。这种能力可以通过 LLM 的代码能力来获得,比如直接让 LLM 生成对应的 SQL 代码。
- Memory Module :通常是指存储之前的历史记录,然后在当前的任务中根据 query 的相似性比对等检索历史数据,并辅助当前的生成。Memlong,
- Routing :用户任务可能比较复杂,此时往往需要多个步骤完成,Routing 模块就是负责任务拆解和分流,比如有多个检索数据源,Routing 负责挑选对应的数据源。
- Task Adapter :是指将 RAG 适配为特定的下游任务,比如从预先构建好的数据池中检索 zero-shot 任务的输入以扩展 prompt,从而增强任务的通用性。
而针对embedding模型,也可以专门出一个话题,这里只做简要介绍。本文所有内容跟embedding模型有关联的只有Late Chunking技术, 它是jina的向量嵌入模型的机制。
Embedding 优化主要包括:
- 挑选合适的 embedding 模型 :检索任务通常是判断 两段内容 是否 相关 ,相似任务是判断两段内容是否 相似 ,相关的内容不一定相似。因此随意挑选一个文本模型用于提取 embedding 不一定合适,学习的目标也不一定相同。
- 针对任务进行微调 :embedding 模型的训练预料和实际检索的语料分布可能并不相同,此时在对应语料上进行 finetuning 可以显著提升检索到的内容的相关性。比如 OpenAI 也提供了代码相关的 code embedding 模型。
- Adapter :如下图所示,也有研究者引入 Adapter,在提取 query embedding 后进一步让 embedding 经过 Adapter,以便实现与索引更好的对齐。
02
Shortwave
问题意图关键信息feature提取, 利用 feature 信息缩小向量搜索的范围,比如问题提取出来的feature 有时间,姓名,需要近因效应, 则相应的部分会得到最大的boost 激励, 其他次相关的得到较小的激励, 甚至是惩罚
查询:“What did Alex work on yesterday?”
a. 时效性偏差提取器(Recency bias extractor):给出0.99的分数,表示这是一个关于最近事件的查询。
b. 关键词提取器(Keyword extractor):识别出两个关键词 “work”(工作,分数0.8)和 “yesterday”(昨天,分数0.6)。
c. 命名实体提取器(Named entity extractor):识别出人名 “Alex”(分数0.99)。
d. 日期范围提取器(Date range extractor):推断出日期范围是 09/26 到 09/27(分数0.95)。
e. 查询嵌入(Query embeddings):将查询转换为向量表示 0.12, -0.34, 0.56, …
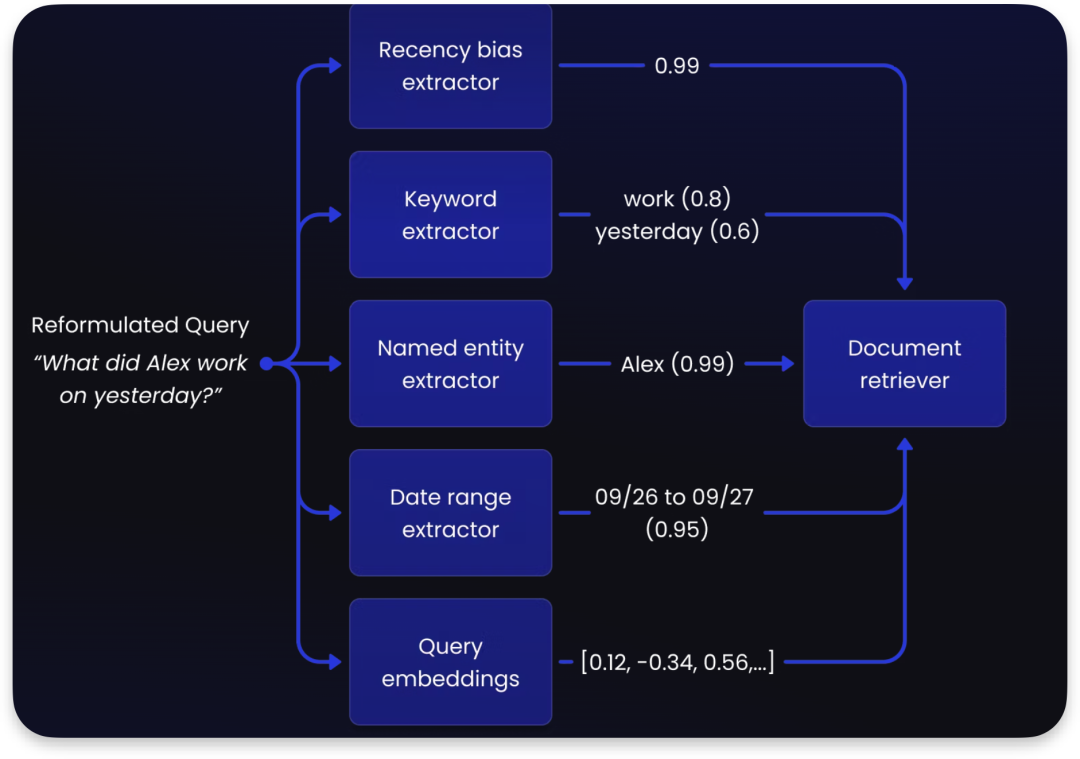
keyword + embedding Search通过上面提取的特征信息结合来做最初的检索 initial retrieve
Feature extraction + Full-text search: 它与特征提取一起使用LLM(大型语言模型)来处理。全文搜索是一种搜索技术,它检索文档中的所有词语,并试图根据搜索条件的相关性来匹配文档。
使用开源MS Marco MiniLM模型来做 cross Encoder,也是本地运行,效果更好, 但消耗算力大, 因此只用上一步 heuristic embedding 排名最靠前的信息进行进一步 re-ranking
MiniLM 的输入,除了上一步的排名靠前信息也有reformulated query, 根据上一步内容与问题的匹配性进行评分, 再把这个评分给 heuristic re-ranking, 让它对索引的内容进行 boost or penalize再重新评分,最后把这份信息提供给 LLM
根据上面 3 个标准或其他来优化 re-ranking 机制, 还包括cross-Encoder 的 re-ranking
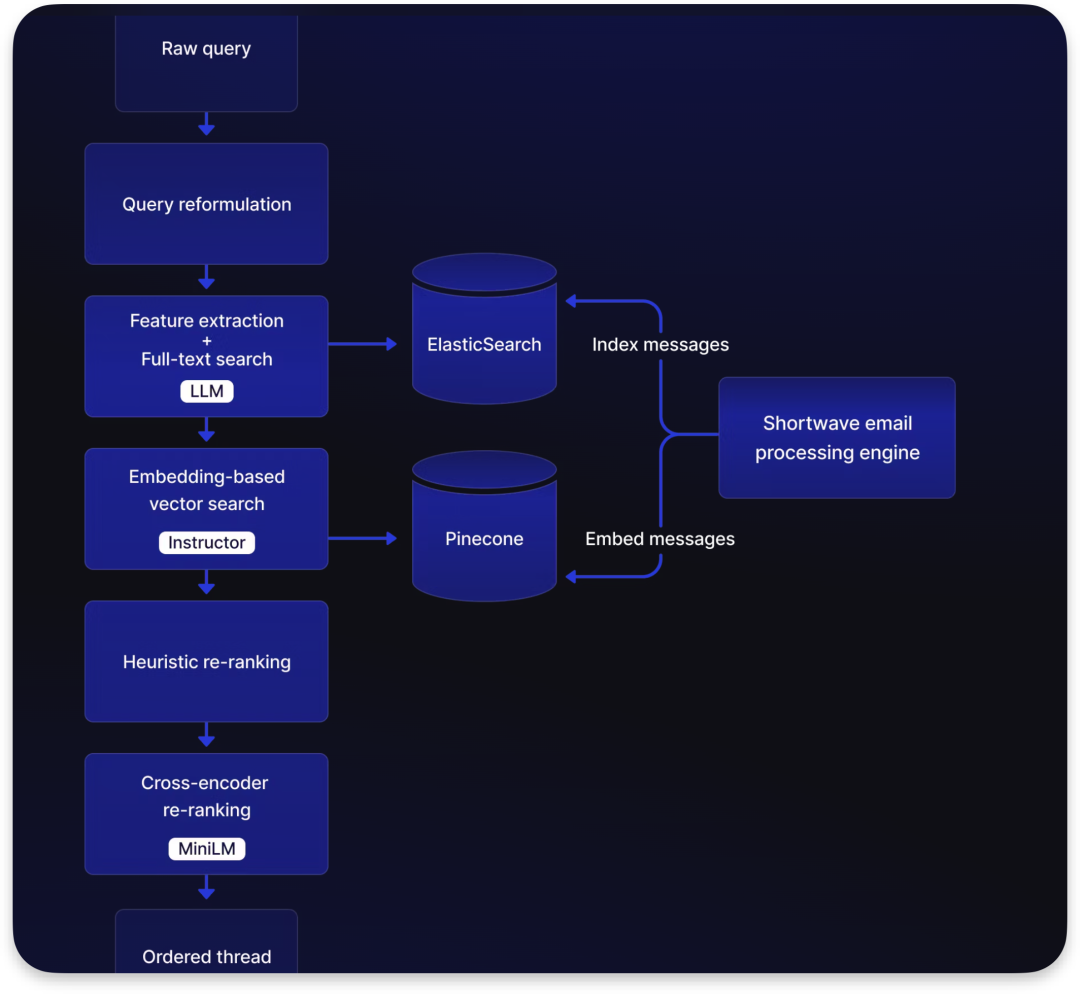 image.png
image.png
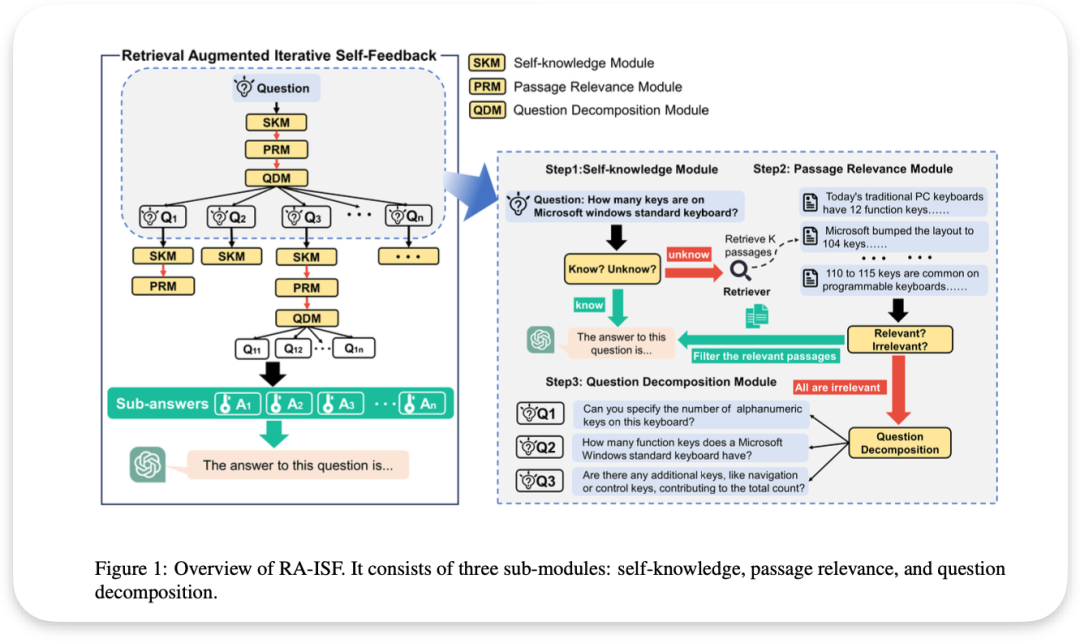
RA-ISF
论文名称: RA-ISF: Learning to Answer and Understand from Retrieval Augmentation via Iterative Self-Feedback
右图解析:
自知识模块(Self-knowledge Module, SKM):
系统首先接收一个问题:“How many keys are on Microsoft windows standard keyboard?”
SKM判断系统是否已知答案。如果是"Know"则LLM直接回答, 是"unknow"才进行检索。这种LLM自己的判断就是(5)自适应检索
段落相关性模块(Passage Relevance Module, PRM):
图中显示了三个检索到的段落
PRM评估每个段落的相关性。如果是相关的, 右图绿色箭头则会过滤筛选先关信息提供给LLM,当被标记为"All are irrelevant"则会调用红色箭头进行问题细化分解,
问题分解模块(Question Decomposition Module, QDM):
当检索到的段落都不相关时,系统会将原始问题分解为多个子问题, 再在每个子问题继续上述循环, 直达LLM找到相关内容(见左半图)
- Q1: Can you specify the number of alphanumeric keys on this keyboard?
- Q2: How many function keys does a Microsoft Windows standard keyboard have?
- Q3: Are there any additional keys, like navigation or control keys, contributing to the total count?
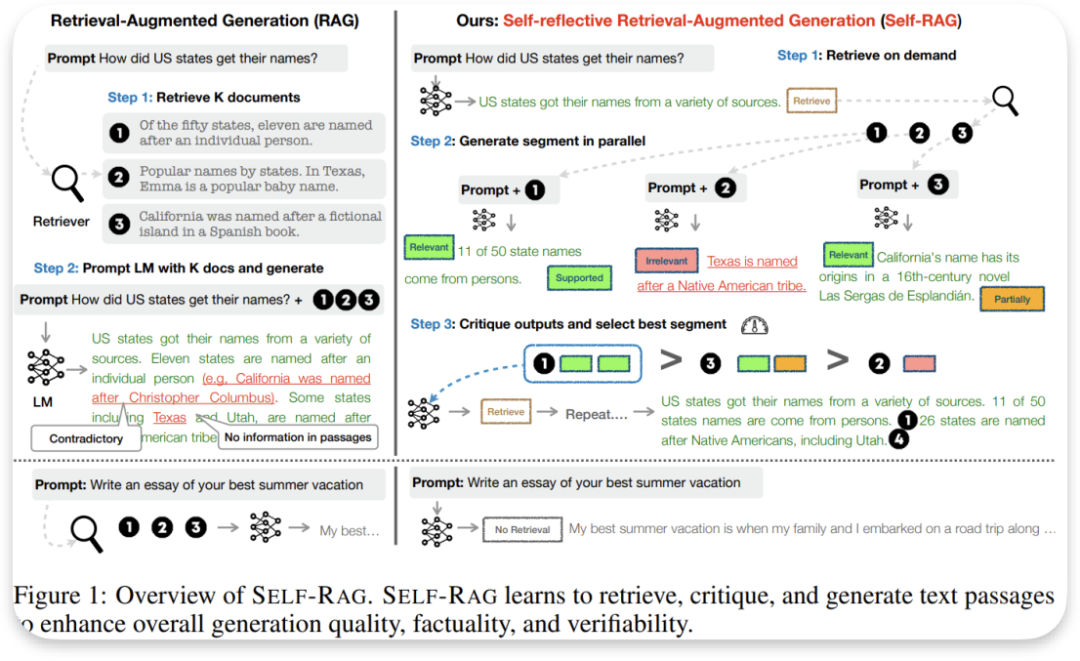
Self RAG
论文名称: SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION
SELF-RAG 通过自适应检索和ReRank提高大型语言模型的生成质量和事实准确性,同时不牺牲 LLM 原有的创造力和多功能性。如果需要,可以引用检索到的段落,并通过学习生成特殊标记来批评输出。这些反思标记明了检索的需求或确认输出的相关性、支持有用性或完整性
给定一个输入提示和前面的生成,SELF-RAG 首先决定是否通过检索段落来增强。如果是,它输出一个检索标记,按需调用检索器模型。对应(5)自适应检索
随后,SELF-RAG 同时处理多个检索到的段落,评估它们的相关性irrelevant, relevant, partiality,supported,然后生成相应的任务输出
然后,它生成批评标记来批评自身的输出,并选择最佳输出①>③>②,对应(6)ReRank机制
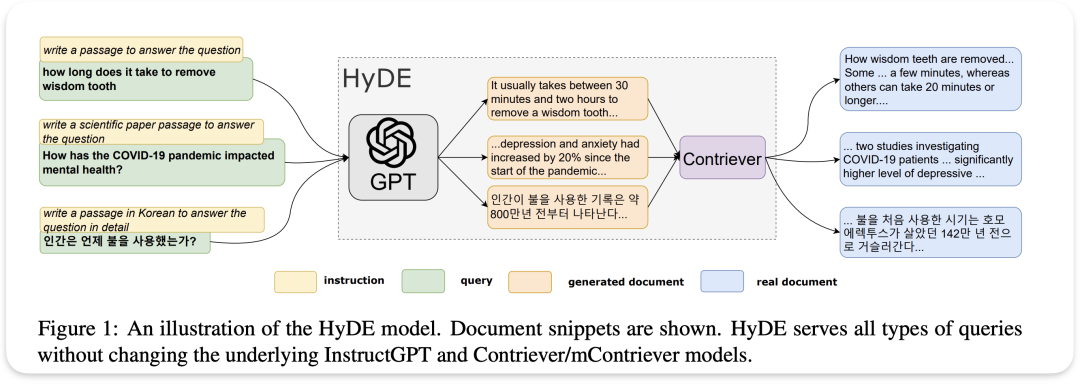
HyDE
论文名称: Precise Zero-Shot Dense Retrieval without Relevance Labels
HyDE模型的创新之处在于它利用大语言模型(如GPT)生成假设性文档Hypothetical Document Embeddings,生成的文档片段然后传递给名为Contriever的检索模型。Contriever模型将GPT生成的文档与真实文档进行比较和检索,找出最相关的真实文档片段作为答案。用GPT的猜测来帮助在真实文档中找到最相关的信息,这种方法结合了生成模型的灵活性和检索系统的准确性
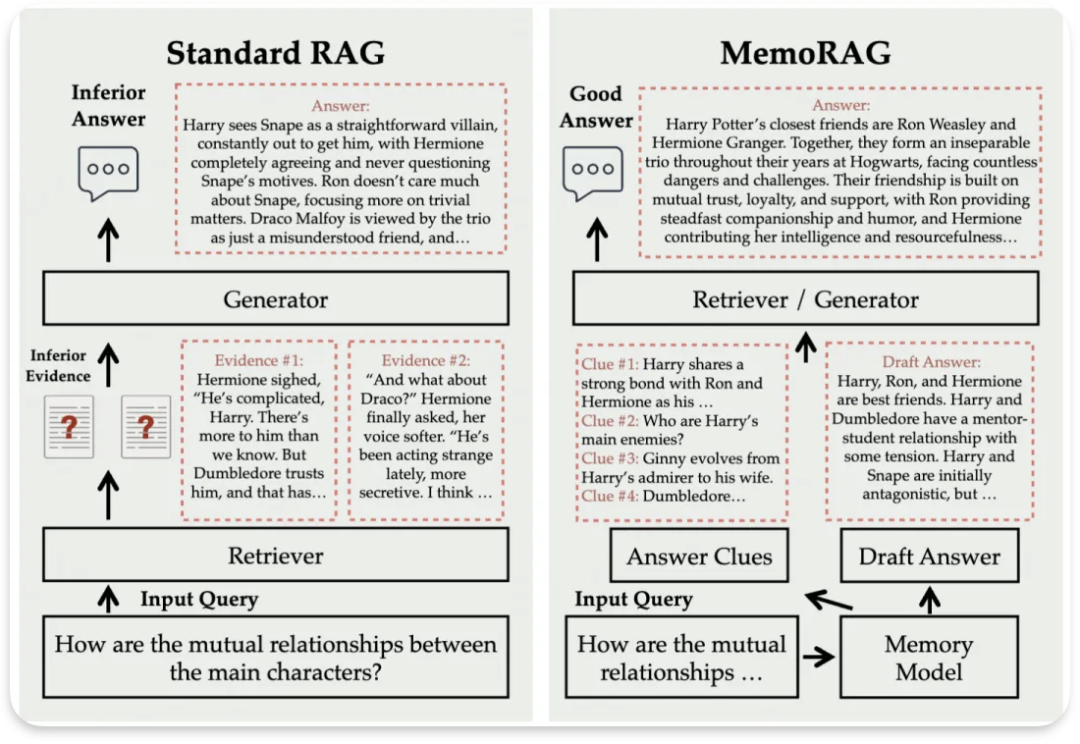
memoRAG
论文名称: MEMORAG: MOVING TOWARDS NEXT-GEN RAG VIA MEMORY-INSPIRED KNOWLEDGE DISCOVERY
对于每个呈现的任务,MemoRAG 会提示其记忆模块生成检索线索。这些线索本质上是基于数据库的压缩表示(即记忆)起草的答案。尽管可能存在错误细节,但这些线索明确揭示了所呈现任务的潜在信息需求
1)记忆性:记住整个数据库的全局信息 2)指导性:提供有用的线索,基于这些线索可以全面检索所需的所有知识。下图右侧Clue 1, Clue 2
本文引入了双系统架构,使用一个轻量级 LLM 作为记忆,另一个重量级 LLM 执行检索增强生成。轻量级 LLM 必须具有成本效益和长上下文能力,能够在有限的计算预算内容纳整个数据库。其次,本文对记忆进行微调,以便生成的线索能够实现优化的检索质量。
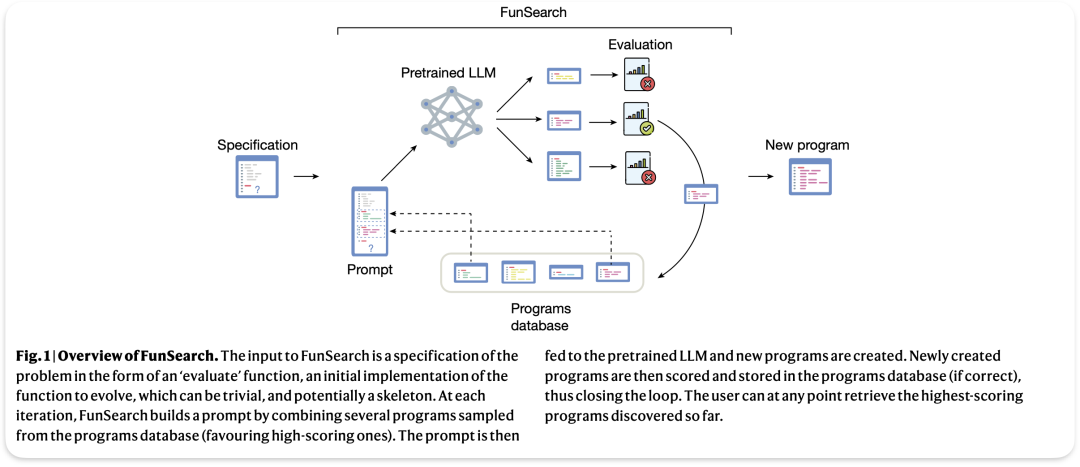
FunSearch
论文名称: Mathematical discoveries from program search with large language models
这里你首先需要给出一个“评估”函数,这个函数定义了你要解决的问题,并且给出一个初始的函数实现。这个实现可能非常简单,甚至只是一个框架(也就是“skeleton”),并不需要完整。
生成提示 (Prompt Generation):
FunSearch系统会从一个已有的程序数据库中抽取出一些程序,特别是那些得分较高的程序,然后把它们组合起来,生成一个新的提示(Prompt)。这些提示可能包括函数代码片段、结构等。
预训练的大型语言模型 (Pretrained LLM):
生成的提示会被输入到一个预训练的大型语言模型中(例如GPT这样的模型),由它来生成新的程序实现。
评估 (Evaluation):
生成的新程序会进行评估(使用最初给出的“评估”函数)。如果新生成的程序通过了评估,它就会被存入程序数据库中。
闭环 (Closing the Loop):
整个过程会重复多次,每次都会通过生成提示、模型生成程序、评估、存储的循环来不断优化程序的实现。用户可以随时取回数据库中得分最高的程序
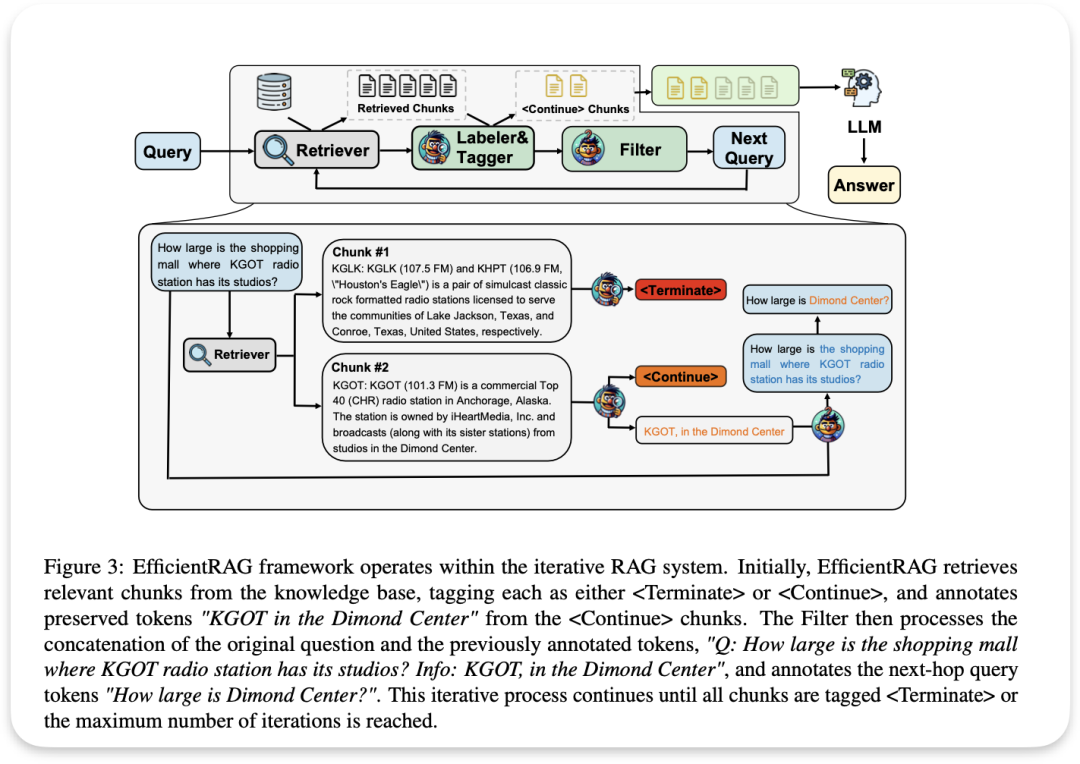
EfficientRAG
论文名称: EfficientRAG: Efficient Retriever for Multi-Hop Question Answering
该框架的核心特色就在 labeler & tagger 以及filter, 将复杂的多跳问题分解为简单的子问题,并在每一步过滤出无关信息, 既不需调用很消耗算力LLM ,也减少了无用信息的干扰
查询接收(Query Reception):系统首先接收到用户的查询。
检索器(Retriever):检索器从数据库中提取相关的文本片段(chunks),这些片段包含了潜在的有用信息,可以用于回答查询。
标签和标记(Labeler & Tagger):该模块对检索到的每个文本片段进行标注,判断其中的关键信息是否有助于回答查询。具体来说,系统会将这些片段标记为 Continue或Terminate,以指示该片段是否包含足够的信息来继续推导下一个问题或已经可以结束检索。
过滤器(Filter):过滤器处理由标签和标记模块生成的文本片段,并将有用的信息提取出来,结合原始查询生成一个新的、更具体的查询,以用于下一轮检索。
迭代检索(Iterative Retrieval):系统会根据新生成的查询继续检索,直到所有片段被标记为 Terminate,或者达到最大迭代次数为止。
生成答案(Answer Generation):最后,所有有用的文本片段被传递给大语言模型(LLM),以生成最终的答案
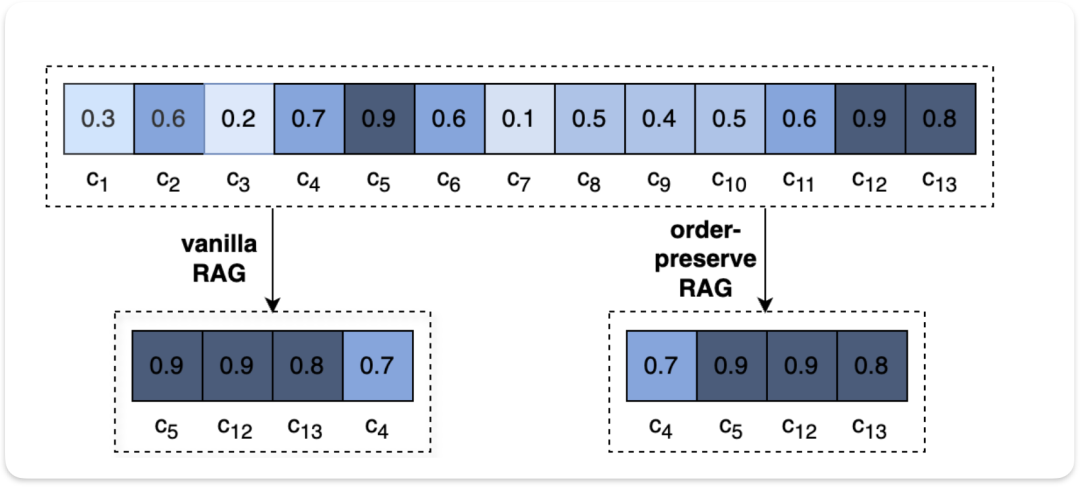
OP-RAG
论文名称: In Defense of RAG in the Era of Long-Context Language Models
传统的RAG,检索与查询最相关的前k个文本块。按照相似度分数排序, OP RAG也会出现相似度分数 ,但根据检索文本在原文本的顺序排序。也就是说,如果一个文本块在原文中出现在另一个文本块之前,那么在处理答案时,它也会被放在前面。
这个相比前面介绍的Self RAG等根据相关性, 问题匹配性等来说 ,更简单, 在选择较高相识度的chunk时保留了原来的文本顺序。
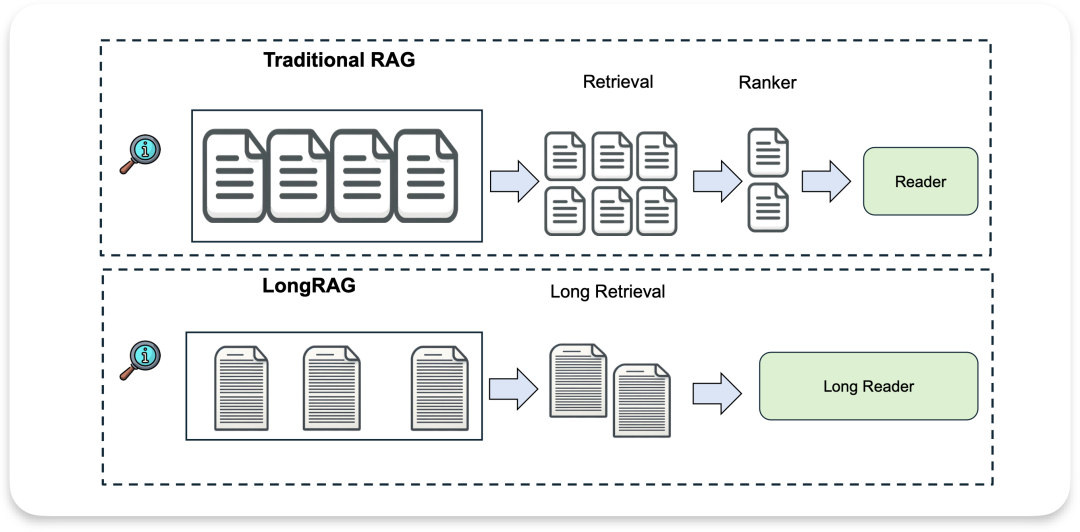
long RAG
论文名称: LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs
增加单元长度, 检索器长度,阅读器长度: 每个单元从之前只能读几百字, 到现在 4K token
把零碎的文档合成group长文档, 检索器检索这些长文档
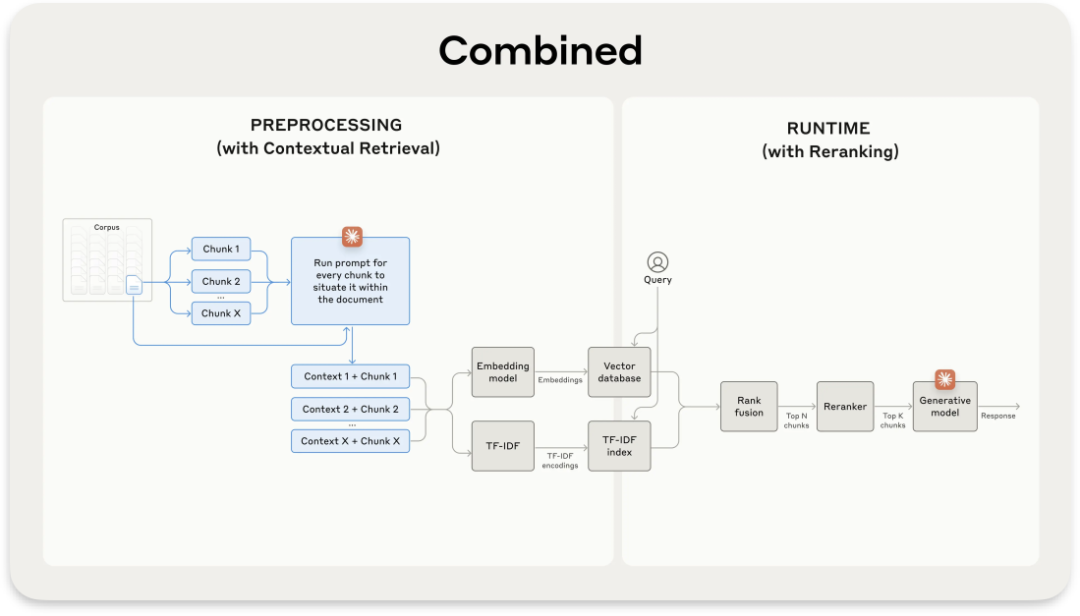
Standard RAG
文章地址:https://www.anthropic.com/news/contextual-retrieval
Standard除了用到BM25索引, 还在嵌入或索引之前,为每个文本块添加相关的上下文信息。这样一来,即使是孤立的文本块,也能携带足够的背景信息,大大提高了检索的准确性。
系统会将每个文本块连同其所属的完整文档一起输入Claude,让AI生成针对该块的解释性上下文。这个过程就像是给每个文本块配备了一个"小秘书",随时为它补充必要的背景信息。
原始文本块:“公司收入较上一季度增长3%。”
经Claude处理后的上下文化文本块:“这段内容来自ACME公司2023年第二季度的SEC文件。上一季度收入为3.14亿美元。收入较上一季度增长3%。”
①使用Claude为每个文本块chunk生成上下文,输入包括文本块和完整文档。
②在嵌入前,将生成的上下文context添加到文本块chunk之前。
③在检索步骤中,结合使用上下文化嵌入、上下文化BM25和重排序。
目前价格在每百万文档token的上下文化成本为1.02美元
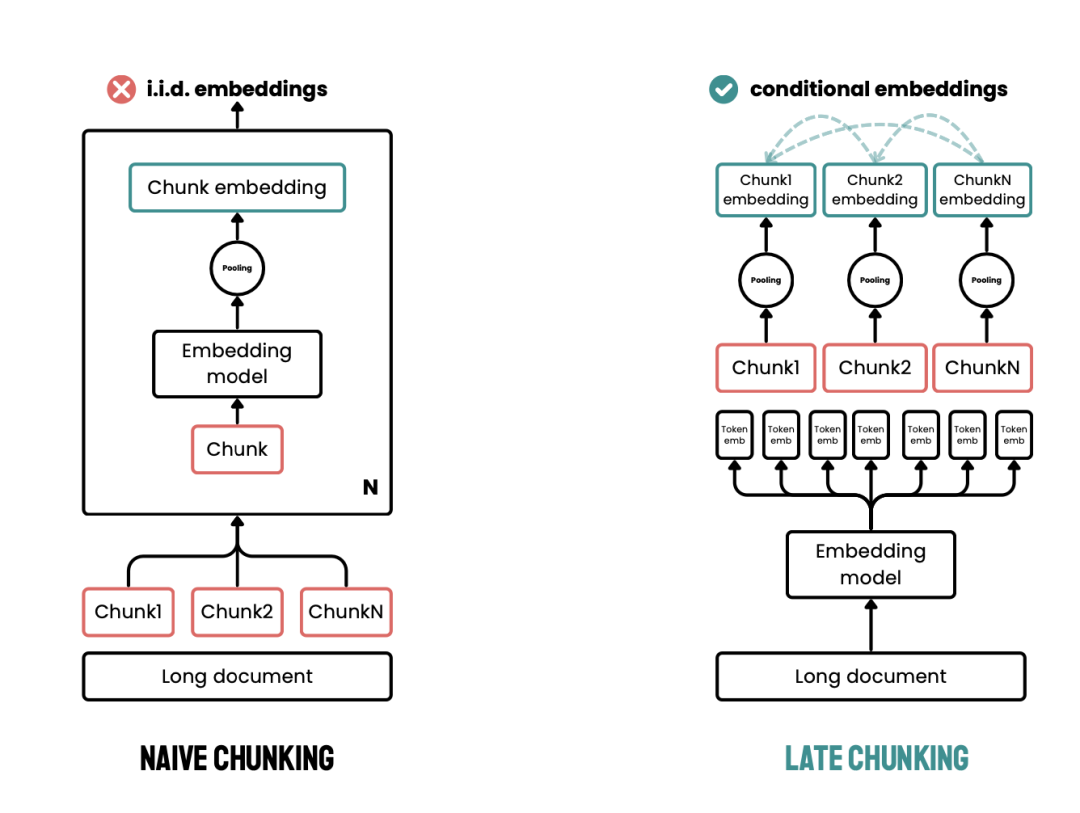
Late chunking
论文地址: LATE CHUNKING: CONTEXTUAL CHUNK EMBED- DINGS USING LONG-CONTEXT EMBEDDING MODELS
在常规的RAG文本切块过程中,为了能够让某个文本块保留一些其相邻文本块的信息,最常规的做法就是在切块过程中让相邻文本块之间保留一些重叠的部分。更激进一些的,还有父文本检索策略,如果召回了一小段文本,那么就把这小段文本所属的那一大段文本都塞进LLM的上下文中。但是这些都更倾向于“规则”层面的优化方法,很少有在“算法”层面的技术。Late Chunking就是一种在算法层面增强文本块上下文感知的技术。
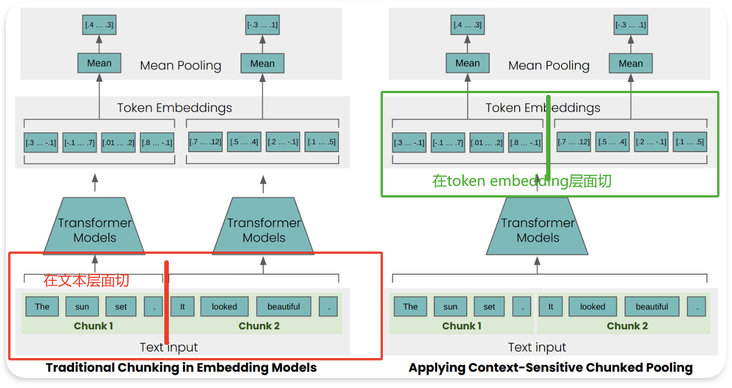
先过 Embedding 模型再分块,我们先将 Embedding 模型的 transformer 层应用到整个文本或尽可能多的连续文本,为每个 token 生成一个包含丰富上下文信息的向量表示序列(Transformer的self attention机制是能够学习到其中的意思的)。随后,再对这些 token 向量序列进行平均池化,进而得到考虑了整个文本上下文的块 Embedding。
DALK
论文名称: DALK: Dynamic Co-Augmentation of LLMs and KG to answer Alzheimer’s Disease Questions with Scientific Literature
该论文以阿尔茨海默病(AD)的知识图谱为例,利用LLM构建了一个AD特定的知识图谱,并使用自适应知识检索方法来增强LLM的推理能力
LLMs for KG 数据集收集。使用由墨尔本大学领域专家Colin Masters教授收集的AD语料库,该语料库基于他广泛的代表性广告相关论文的参考书目。重点关注2011年以来反映该领域最新知识的论文,共获得9764篇。
实体识别。利用NCBI开发并持续维护的PubTator Central从语料库中提取相关实体,将PTC应用于所有AD论文的摘要,并获得相关的命名实体,这些实体将作为知识图中的节点。
关系抽取。在两个相关实体之间分配特定的关系类型,我们将LLM当前方法分为两大类:
1)成对关系提取旨在促使法学硕士描述文本片段中任意两个实体之间的关系。
2)生成关系提取LLM直接输出所有相关实体对及其对应关系。我们将这两种关系提取方法合并到我们的知识图谱增强过程中,对它们进行全面的比较。
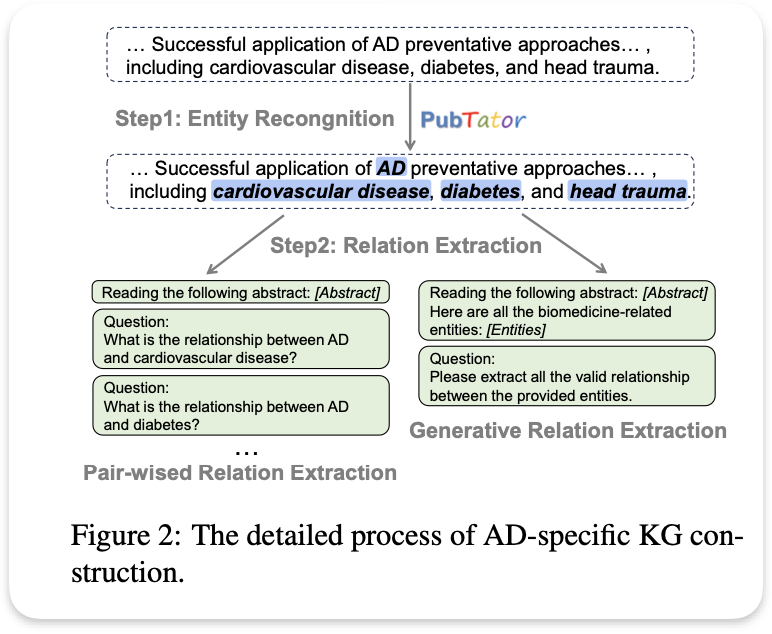 image.png
image.png
KG for LLMs
粗粒度知识图谱检索 给定一个问题查询Q,我们首先构造一个提示符,并要求LLM提取所有特定于领域的实体E。之后,我们执行基于相似性的实体链接过程,将E内的所有实体连接到知识图G中的实体结构
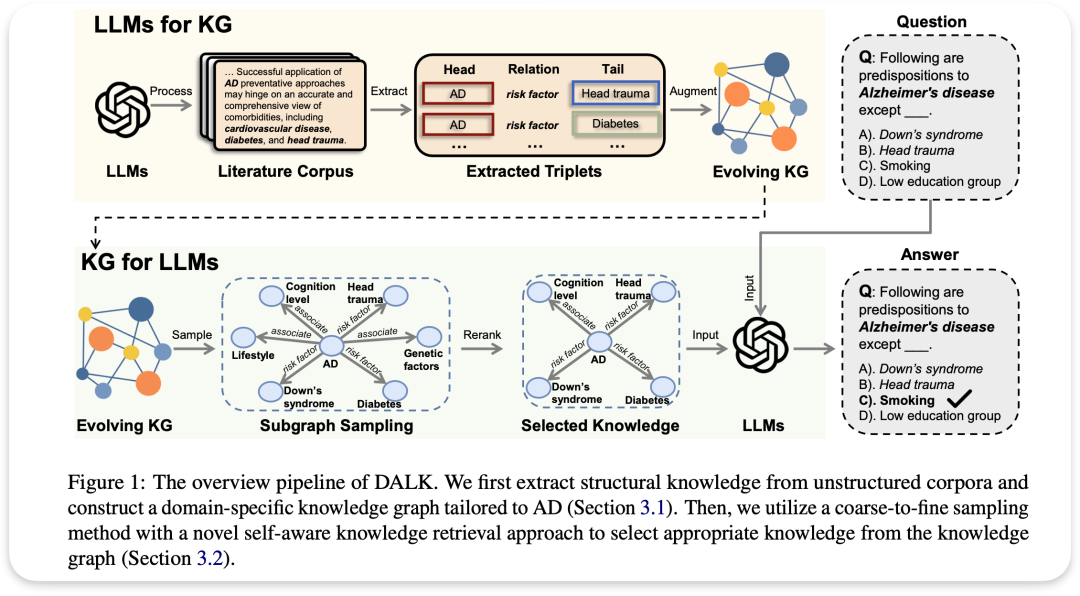
HybridRAG
论文名称: HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction
HybridRAG 结合了 Vector RAG 和 GraphRAG 的优势(虽然GraphRAG 在上下文精确性上现出色,但可能无法匹配全面的召回能力),通过先使用 Vector RAG 获取大量相关信息,然后利用 GraphRAG 对这些信息进行精确的上下文处理。
VectorRAG 阶段:首先使用 VectorRAG 从文档中提取相关的上下文。这一阶段主要依赖向量检索技术来找到与查询最相关的内容。
GraphRAG 阶段:接着使用 GraphRAG 利用知识图谱来补充和优化之前获取的上下文。这一步能够通过知识图谱提供更丰富的语义信息,从而生成更准确的答案。
RAPTOR
论文名称: RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL
首先,需要对文本进行合理的切片处理。然后,RAPTOR 根据其语义embedding递归地对文本块chunk进行聚类,并用LLM生成这些聚类的文本摘要。
RAPTOR采用软聚类方法,允许文本块跨多个聚类,基于高斯混合模型(GMMs)和UMAP技术进行降维,以捕捉文本数据的复杂结构和关系,从而优化文本聚类效果。
最后再自下而上地构建出一个结构化的树形模型。在此树中,相近的节点自然聚集形成兄弟关系,而它们的父节点则承载着整个集群的概要性文本信息。这种设计确保了文本信息的层次化和结构化表达,便于理解和检索。
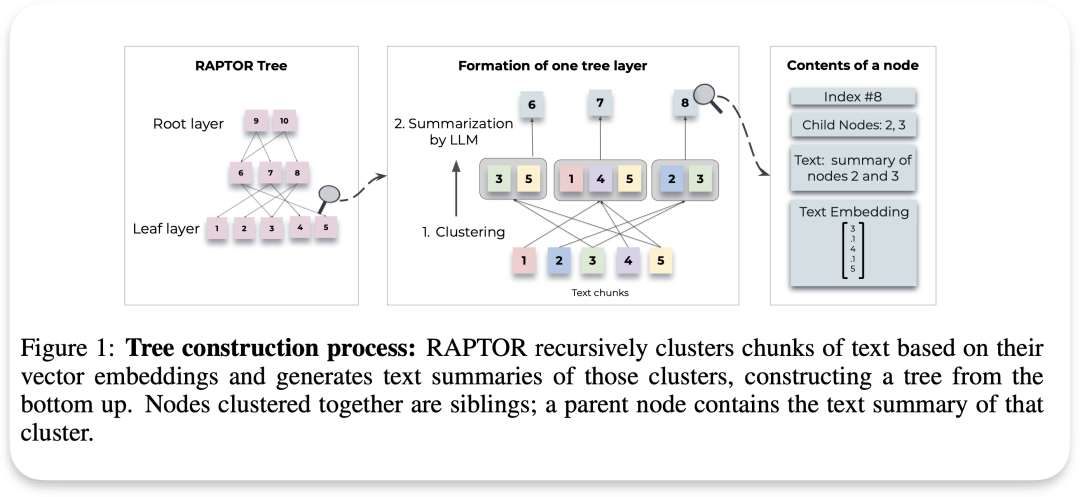
相比于Standard RAG在每一个chunk都提供摘要, RAPTOR这种摘要还是偏模糊。也很少有人提及
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。