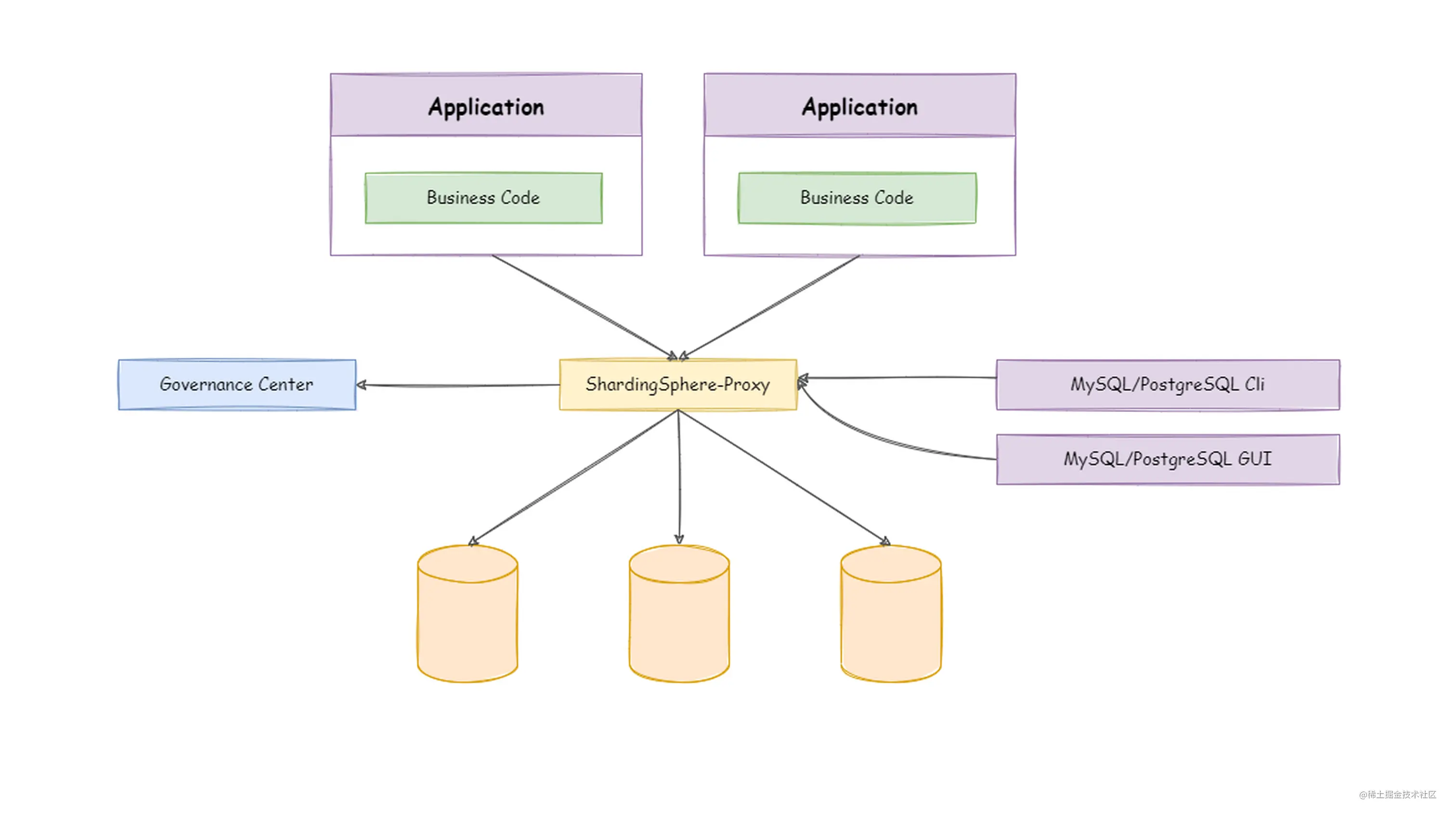
分库分表-分片算法运用
ShardingSphere 分片算法
用于将数据分片的算法,支持 =、>=、<=、>、<、BETWEEN 和 IN 进行分片。分片算法可由开发者自行 实现,也可使用 Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高。原理简单来说就是在解析sql后分析对应的分片键和分库键,如果存在,则采用对应算法进行路由,改写sql,合并结果。分片算法一般包括如下算法:
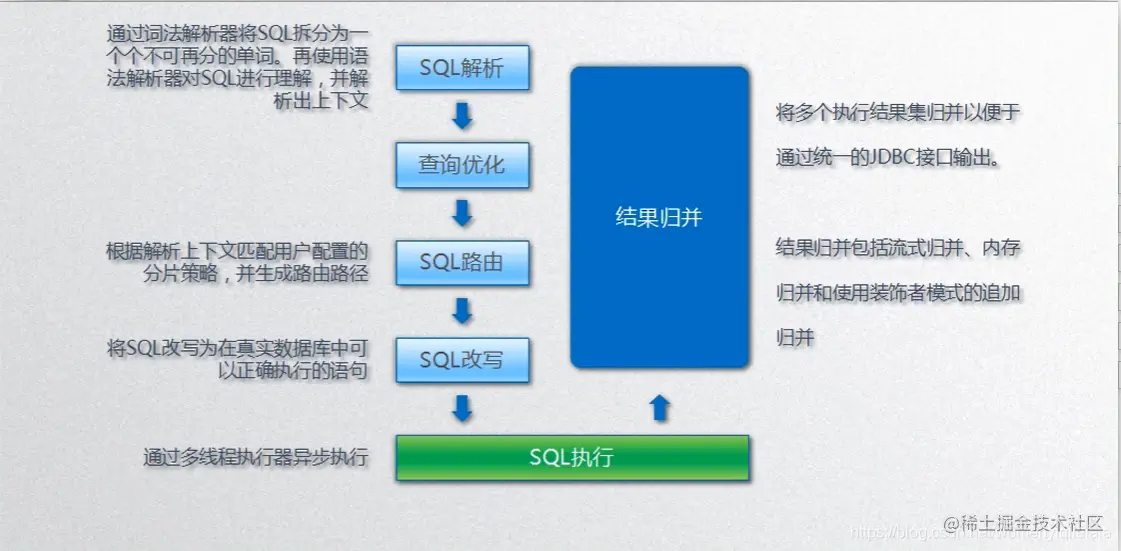
自动化分片算法
分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。包括取模、哈希、 范围、时间等常用分片算法的实现。自动化分片在实际情况中使用比较少,功能较为单一。
标准分片算法(InlineShardingStrategy)
1.用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<= 进行分片的场景。
这里使用inline的语法,将userId 和2取模,得到分库的数据库是demo0还是demo1,同理,将pay_parent中id主键取模,得到对应的分表。
sharding:
binding-tables: pay_parent,pay_parent_item
broadcast-tables: t_address
default-database-strategy:
## 实际数据库分库路由键和路由算法
inline:
algorithm-expression: demo$->{user_id % 2}
sharding-column: user_id
tables:
pay_parent:
## 实际数据库分库数量和分表数量
actual-data-nodes: demo$->{0..1}.pay_parent_$->{0..1}
## 表主键策略
key-generator:
column: id
props:
worker:
id: 123
type: SNOWFLAKE
table-strategy:
## 实际数据库分表路由键和路由算法
inline:
algorithm-expression: pay_parent_$->{id % 2}
sharding-column: id
2.标准分片策略(StandardShardingStrategy)
这里使用两张表,分别两个库和两个表来存储。数据库是demo0还是demo1,分表情况如下。
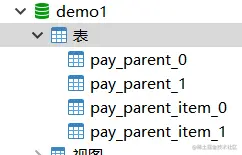
配置如下,User_id作为库和表的路由键,分别实现了分库分表的精准路由和范围路由算法。这两个算法作用区别是,如果解析的sql带有切确的路由字段值,“=”、“IN”之类运算符相对较多的场景。,这里是user_id,那么会使用精准路由算法去路由具体的库和表;如果是带有范围sql例如使用“>”、“<”、“BETWEEN ... AND ...”之类运算符相对较多的场景。这种语法,那么会走范围路由算法。
sharding:
binding-tables: pay_parent,pay_parent_item
broadcast-tables: t_address
default-database-strategy:
## 实际数据库分库路由键和路由算法
standard:
precise-algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.DatabasePreciseShardingAlgorithm
range-algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.DatabasePreciseRangeShardingAlgorithm
sharding-column: user_id
tables:
pay_parent:
## 实际数据库分库数量和分表数量
actual-data-nodes: demo$->{0..1}.pay_parent_$->{0..1}
## 表主键策略
key-generator:
column: id
props:
worker:
id: 123
type: SNOWFLAKE
table-strategy:
## 实际数据库分表路由键和路由算法
standard:
precise-algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.MyPreciseTableShardingAlgorithm
range-algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.MyPreciseTableRangeShardingAlgorithm
sharding-column: user_id
pay_parent_item:
actual-data-nodes: demo$->{0..1}.pay_parent_item_$->{0..1}
key-generator:
column: id
props:
worker:
id: 123
type: SNOWFLAKE
table-strategy:
standard:
precise-algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.MyPreciseTableShardingAlgorithm
range-algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.MyPreciseTableRangeShardingAlgorithm
sharding-column: user_id
分表路由算法实现,值得注意的是availableTargetNames指需要路由的表,shardingValue指路由的键,路由的逻辑表具体值发起的主表,例如联接查询l left join r where l.user_id = xx,左表一直为逻辑表,具体的路由表需要到availableTargetNames获取。
@Component
public class MyPreciseTableShardingAlgorithm implements PreciseShardingAlgorithm<Integer> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Integer> shardingValue) {
Integer curValue = shardingValue.getValue();
int tableKey = curValue % 2;
for (String targetTable : availableTargetNames) {
if (targetTable.contains(Integer.toString(tableKey))){
return targetTable;
}
}
throw new RuntimeException("bot find tableKey");
}
}
@Component
public class MyPreciseTableRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return Arrays.asList(rangeShardingValue.getLogicTableName()+ "_0", rangeShardingValue.getLogicTableName()+ "_1");
}
}
2.复杂分片策略(ComplexShardingStrategy)
它支持多分片键的复杂分片策略,配置参数:complex.sharding-columns 分片键(多个),如下面的连两个user_id,update_time两列;complex.algorithm-class-name 分片算法实现类,具体实现的算法样例如下,实现起来可根据字段的实际值返回路由表。值得注意的下,ComplexShardingStrategy解析的sql带有切确的路由字段值,“=”、“IN”之类运算符相对较多的场景。没有适配范围查询的算法,算是一个较大的缺点。
sharding:
binding-tables: pay_parent,pay_parent_item
broadcast-tables: t_address
default-database-strategy:
## 实际数据库分库路由键和路由算法
standard:
precise-algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.DatabasePreciseShardingAlgorithm
range-algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.DatabasePreciseRangeShardingAlgorithm
sharding-column: user_id
tables:
pay_parent:
## 实际数据库分库数量和分表数量
actual-data-nodes: demo$->{0..1}.pay_parent_$->{0..1}
## 表主键策略
key-generator:
column: id
props:
worker:
id: 123
type: SNOWFLAKE
table-strategy:
## 实际数据库分表路由键和路由算法
complex:
algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.MyComplexTableShardingAlgorithm
sharding-columns: user_id,update_time
pay_parent_item:
actual-data-nodes: demo$->{0..1}.pay_parent_item_$->{0..1}
key-generator:
column: id
props:
worker:
id: 123
type: SNOWFLAKE
table-strategy:
standard:
algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.MyComplexTableShardingAlgorithm
sharding-columns: user_id,update_time
@Component
public class MyComplexTableShardingAlgorithm implements ComplexKeysShardingAlgorithm<Comparable<?>> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Comparable<?>> shardingValue) {
Collection<Comparable<?>> cidRange = shardingValue.getColumnNameAndShardingValuesMap().get("update_time");
Collection<Comparable<?>> userIdCol = shardingValue.getColumnNameAndShardingValuesMap().get("user_id");
List<String> res = new ArrayList<>();
for(Object userId: userIdCol){
//course_{userID%2+1}
}
return Collections.singleton("pay_parent_0");
}
}
3.定制连表查询策略(HintShardingStrategy)
不需要分片键的强制分片策略。这个分片策略,简单来理解就是说,他的分片键不再跟SQL语句相关联,而是用程序另行指定。对于一些复杂的情况,例如select count(*) from (select userid from t_user where userid in (1,3,5,7,9))这样的SQL语句,就没法通过SQL语句来指定一个分片键。这个时候就可以通过程序,给他另行执行一个分片键,例如在按userid奇偶分片的策略下,可以指定1作为分片键,然后自行指定他的分片策略。
-- 不支持的复杂sql场景
-- 不支持UNION
SELECT * FROM t_order1 UNION SELECT * FROM t_order2 INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ?
-- 不支持多层子查询
SELECT COUNT(*) FROM (SELECT * FROM t_order o WHERE o.id IN (SELECT id FROM t_order WHERE status = ?))
-- 不支持函数计算。ShardingSphere只能通过SQL字面提取用于分片的值
SELECT * FROM t_order WHERE to_date(create_time, 'yyyy-mm-dd') = '2019-01-01';
-
-
配置参数:hint.algorithm-class-name 分片算法实现类。
-
实现方式:
- algorithmClassName指向一个实现了org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm接口的java类名。
-
在这个算法类中,同样是需要分片键的。而分片键的指定是通过HintManager.addDatabaseShardingValue方法(分库)和HintManager.addTableShardingValue(分表)来指定。
-
使用时要注意,这个分片键是线程隔离的,只在当前线程有效,所以通常建议使用之后立即关闭,或者用try资源方式打开。
-
-
而Hint分片策略并没有完全按照SQL解析树来构建分片策略,是绕开了SQL解析的,所有对某些比较复杂的语句,Hint分片策略性能有可能会比较好。
和其他3种不同的是,Hint 需要指定分片表 的数据库分片算法 + 表分片算法 ,才能走hint的路由策略
public boolean isRoutingByHint(TableRule tableRule) {
return this.getDatabaseShardingStrategy(tableRule) instanceof HintShardingStrategy && this.getTableShardingStrategy(tableRule) instanceof HintShardingStrategy;
}
yaml的配置如下
tables:
pay_parent:
## 实际数据库分库数量和分表数量
actual-data-nodes: demo$->{0..1}.pay_parent_$->{0..1}
## 表主键策略
key-generator:
column: id
props:
worker:
id: 123
type: SNOWFLAKE
table-strategy:
## 实际数据库分表路由键和路由算法
hint:
algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.MyHintTableShardingAlgorithm
database-strategy:
## 实际数据库分表路由键和路由算法
hint:
algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.MyHintDatabaseShardingAlgorithm
pay_parent_item:
actual-data-nodes: demo$->{0..1}.pay_parent_item_$->{0..1}
key-generator:
column: id
props:
worker:
id: 123
type: SNOWFLAKE
table-strategy:
hint:
algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.MyHintTableShardingAlgorithm
database-strategy:
## 实际数据库分表路由键和路由算法
hint:
algorithm-class-name: com.ilearning.common.datasource.shardingJdbc.MyHintDatabaseShardingAlgorithm
实际使用和路由算法如下,将userId的值作为两张表和库的路由键,路由算法比较简单,和2取模路由,实际情况中可能是更复杂的路由的算法,例如有userId+订单号一起路由的。
@Component
public class MyHintTableShardingAlgorithm implements HintShardingAlgorithm<Comparable<?>> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<Comparable<?>> shardingValue) {
String key = shardingValue.getLogicTableName() + "_" + shardingValue.getValues().toArray()[0];
Integer curValue = (Integer) shardingValue.getValues().toArray()[0];
int databaseKey = curValue % 2;
return Arrays.asList(shardingValue.getLogicTableName() + "_" + + databaseKey);
}
}
public CommonResult<PageResult<ParentRespVO>> getParentDetailPage(@Valid ParentPageReqVO pageVO) {
// Hint分片策略必须要使用 HintManager工具类
HintManager hintManager = HintManager.getInstance();
hintManager.addDatabaseShardingValue("pay_parent", pageVO.getUserId());
hintManager.addTableShardingValue("pay_parent",pageVO.getUserId());
hintManager.addTableShardingValue("pay_parent_item",pageVO.getUserId());
//在读写分离数据库中,Hint 可以强制读主库(主从复制是存在一定延时,但在业务场景中,可能更需要保证数据的实时性)
//hintManager.setMasterRouteOnly();
PageResult<ParentDO2> pageResult = parentService.getParentPageDetail(pageVO);
hintManager.close();
return success(ParentConvert.INSTANCE.convertPage2(pageResult));
}
总结
在实施分库分表时,根据业务主体,选择合适路由字段和合适的分片算法是非常关键的,决定了业务的拓展性。这里有几个情况思考。上述将的四种路由算法各有特点,标准分片策略具有精准和范围两种sql类型,但是绑定的字段只有一个。复杂分片策略适用于多字段,但是对于范围查询还没有找到一个好的解决方案。定制连表查询策略灵活度最高,可以基于非表字段且适用于不同的sql,缺点是和业务耦合在一起,嵌入了业务代码。至于选择何种算法,这与分表的路由键、实际的业务场景有关系,尽量做到灵活度高,准确的,匹配业务的。