论文题目:《Get To The Point: Summarization with Pointer-Generator Networks》
主要内容:seq2seq,文本摘要
《切中要害:指针生成器网络概述》
摘要
神经序列到序列模型为抽象文本摘要提供了一种可行的新方法(这意味着它们不限于从原始文本中简单地选择和重新排列段落)。然而,这些模型有两个缺点:它们容易不准确地再现事实细节,而且往往会重复自己。在这项工作中,我们提出了一种新的架构,该架构以两种正交的方式增强了标准序列间注意模型。首先,我们使用混合指针生成器网络,该网络可以通过指向从源文本复制单词,这有助于信息的准确再现,同时保留通过生成器生成新单词的能力。第二,我们使用覆盖范围来跟踪总结的内容,这不鼓励重复。我们将我们的模型应用于CNN/Daily Mail摘要任务,比当前的抽象技术领先至少2分。
1. Introduction
摘要是将一段文本浓缩成一个较短的版本,其中包含原始文本的主要信息。概括有两种广泛的方法:提取式和抽象式。提取方法仅从直接从源文本中提取的段落(通常是整句)中汇总摘要,而提取方法可能会生成源文本中未出现的新单词和短语,正如人类撰写的摘要通常所做的那样。提取方法更容易,因为从源文档复制大块文本可以确保语法和准确性的基线水平。另一方面,对于高质量概括至关重要的复杂能力,如释义、概括或结合真实世界知识,只有在抽象框架中才能实现(见图5)。

文章:cnn的一项调查显示,走私者通过提供折扣来吸引阿拉伯和非洲移民,如果人们带来更多潜在乘客,他们可以登上拥挤的船只。
(…)概要:cnn调查发现了一个人口走私团伙内部的生意。
文章:一段目击者视频显示,北查尔斯顿白人警察迈克尔·斯莱格枪杀了一名手无寸铁的黑人男子,这段视频暴露了现场第一批警察的报告中的差异。(…)总结:在有争议的美国警察枪击案中,问题多于答案。
图5:高度抽象的参考摘要示例(粗体表示新单词)。
由于抽象概括的困难,过去的大部分工作都是抽象的(Kupiec等人,1995年;Paice,1990年;Saggion和Poibau,2013年)。然而,最近序列间模型的成功(Sutskever et al., 2014), 递归神经网络(RNN)既能阅读又能自由生成文本,这使得抽象摘要变得可行(Chopra等人,2016;Nallapati等人,2016年;Rush等人,2015年;Zeng等人,2016)。尽管这些系统很有前途,但它们表现出不可取的行为,如不准确地再现事实细节、无法处理词汇外(OOV)单词以及重复自己(见图1)。

原文(删节):尼日利亚拉各斯(cnn)在赢得尼日利亚总统一天后,穆罕默杜·布哈里告诉cnn的克里斯蒂娜·阿曼普尔,他计划积极打击长期困扰尼日利亚的腐败,并寻找国家动荡的根源。布哈里表示,他将“迅速关注”尼日利亚东北部地区的暴力行为,那里是恐怖组织博科哈拉姆的活动地。他表示,通过与邻国乍得、喀麦隆和尼日尔的合作,他的政府有信心挫败犯罪分子和其他助长尼日利亚不稳定的因素。
在尼日利亚历史上,反对派首次在民主选举中击败了执政党。尼日利亚独立国家选举委员会称,布哈里以约200万票的优势击败了现任总统古德勒克·乔纳森。这场胜利是在这个非洲人口最多的国家经历了漫长的军事统治、政变和拙劣的民主尝试之后取得的。
Baseline Seq2Seq + Attention:UNK UNK表示,他的政府有信心能够破坏尼日利亚经济的稳定。UNK表示,他的政府有信心挫败犯罪分子和其他尼日利亚人。
他说,尼日利亚和尼日利亚的经济长期存在。
Pointer-Gen:穆罕默杜·布哈里表示,他计划在尼日利亚东北部积极打击腐败。他表示,他将“迅速关注”遏制尼日利亚东北部地区的暴力。他说,他的政府有信心挫败犯罪分子。
Pointer-Gen + Coverage:穆罕默杜·布哈里表示,他计划积极打击长期困扰尼日利亚的腐败。他说,他的政府有信心挫败犯罪分子。这场胜利是在这个非洲人口最多的国家经历了漫长的军事统治、政变和拙劣的民主尝试之后取得的。
图1:一篇新闻文章上3个抽象摘要模型的输出比较。基线模型会产生事实错误,一个荒谬的句子,并与OOV单词muhammadu buhari作斗争。指针生成器模型是准确的,但会重复。覆盖消除重复。最后的总结由几个片段组成。
在本文中,我们提出了一种在多句子摘要的背景下解决这三个问题的架构。虽然最近的摘要工作集中于标题生成任务(将一两句话缩减为一个标题),但我们认为,较长的文本摘要不仅更具挑战性(需要更高层次的抽象,同时避免重复),而且最终更有用。因此,我们将我们的模型应用于最近引入的CNN/Daily Mail数据集(Hermann等人,2015年;Nallapati等人,2016年),该数据集包含新闻文章(平均39个句子)和多句子摘要,并表明我们比最先进的摘要系统至少高出2个ROUGE点。
我们的混合指针生成器网络有助于通过指向从源文本复制单词(Vinyals等人,2015),这提高了OOV单词的准确性和处理,同时保留了生成新单词的能力。该网络可以被视为提取和抽象方法之间的平衡,与Gu等人(2016)的CopyNet和Miao and Blunsom(2016)《强迫注意句子压缩》相似,应用于短文本摘要。我们从神经机器翻译中提出了覆盖向量的一种新变体(Tu等人,2016),我们使用它来跟踪和控制源文档的覆盖。我们发现覆盖对于消除重复非常有效。
2.我们的模型
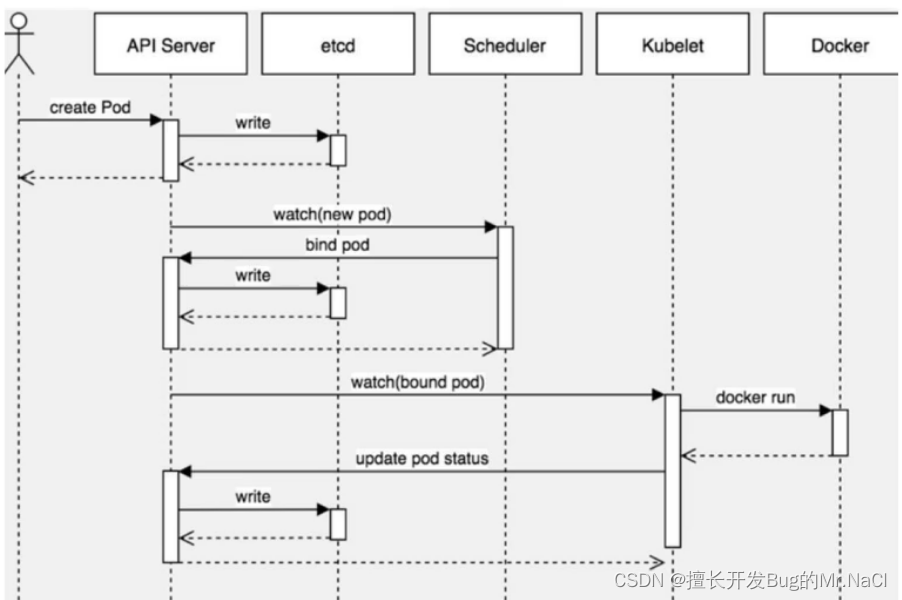
在本节中,我们将描述(1)我们的基线序列到序列模型,(2)我们的指针生成器模型,以及(3)我们可以添加到前两个模型中的任何一个的覆盖机制。我们型号的代码可在线获取。
2.1 Sequence-to-sequence attentional model
我们的基线模型与Nallapati等人(2016)的模型相似,如图2所示。

图2:带注意力的基线序列到序列模型。该模型可以关注源文本中的相关单词以生成新单词,例如,为了在摘要摘要中生成新单词节拍,德国2-0击败阿根廷,该模型可以注意源文本中获胜和获胜的单词。
文章wi的令牌一个接一个地送入编码器(单层双向LSTM),产生一系列编码器隐藏状态hi。在每个步骤t上,解码器(单层单向LSTM)接收前一单词的单词嵌入(在训练时,这是参考摘要的前一单词;在测试时,它是解码器发出的前一个单词),并具有解码器状态st。按照Bahdanau等人(2015)的方法计算注意力分布:
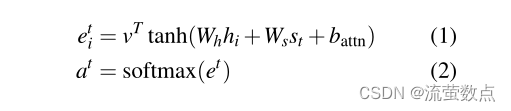
其中v、Wh、Ws和battn是可学习的参数。注意力分布可以被视为源单词上的概率分布,它告诉解码器在哪里寻找以产生下一个单词。接下来,注意力分布用于产生编码器隐藏状态的加权和,称为上下文向量ht∗时间:

上下文向量(可以被视为该步骤从源读取的内容的固定大小表示)与解码器状态st连接,并通过两个线性层馈送以产生词汇分布Pvocab:
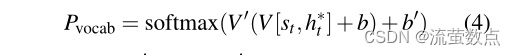
其中V、V0、b和b0是可学习的参数。
Pvocab是词汇表中所有单词的概率分布,它为我们提供了预测单词w的最终分布:
![]()
在训练期间,时间步长t的损失是目标单词w的负对数似然性wt∗表示该时间步:

整个序列的总损失为:

2.2 Pointer-generator network
指针发生器网络
我们的指针生成器网络是我们的基线和指针网络之间的混合(Vinyals等人,2015),因为它允许通过指向复制单词,并从固定词汇表生成单词。
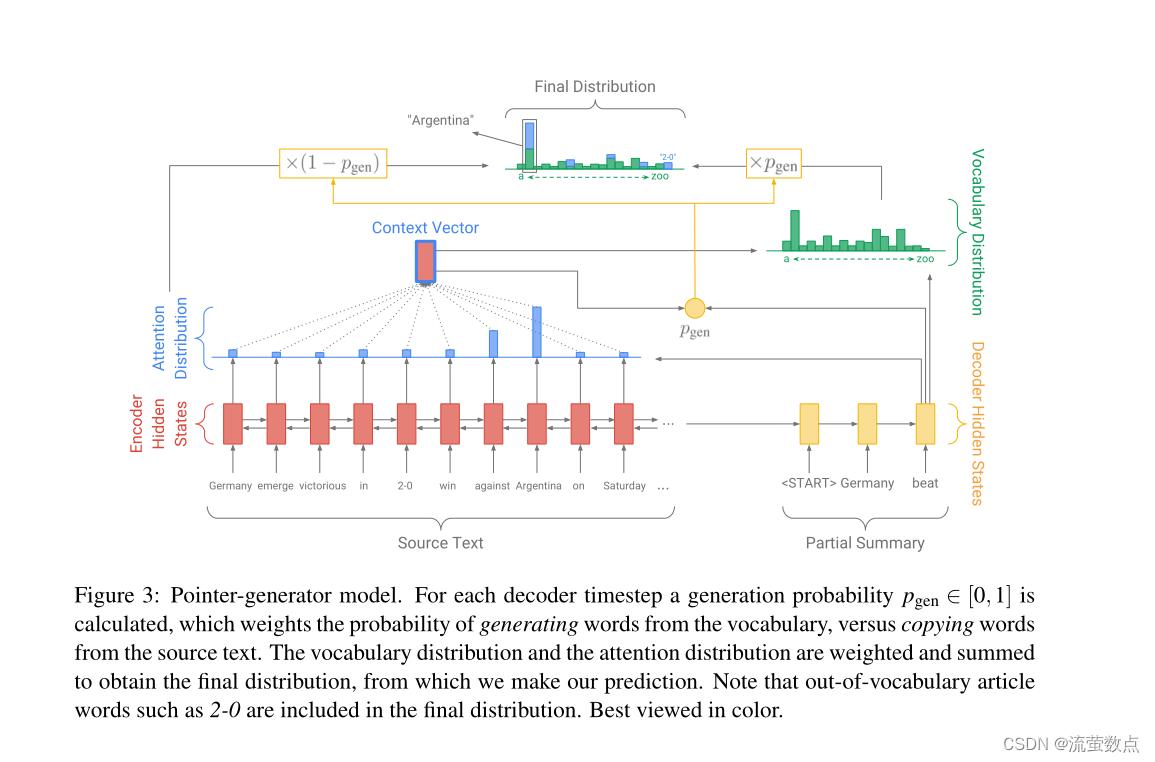
图3:指针生成器模型。对于每个解码器时间步长,生成概率pgen∈ [0,1]被计算,它加权了从词汇表中生成单词的概率,而不是从源文本中复制单词的概率。对词汇分布和注意力分布进行加权和求和,以获得最终分布,并据此进行预测。注意,词汇表外的文章单词(如2-0)包含在最终分发中。最佳颜色。
在指针生成器模型(如图3所示)中,注意力分布和上下文向量h∗t按第2.1节计算。此外,发电概率pgen∈ 时间步t的[0,1]由上下文向量计算h∗t、解码器状态st和解码器输入xt:

其中向量wh∗, ws、wx和标量bptr是可学习的参数,σ是sigmoid函数。
接下来,pgen被用作软开关,在通过从Pvocab采样从词汇表中生成单词,或通过从注意分布采样从输入序列中复制单词之间进行选择。对于每个文档,让扩展词汇表表示词汇表和源文档中出现的所有单词的联合。
我们在扩展词汇表上获得以下概率分布:
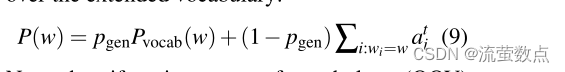
注意,如果w是词汇表外(OOV)单词,则Pvocab(w)为零;类似地,如果w不显示在源文档中,则∑i: wi=w ati为零。产生OOV单词的能力是指针生成器模型的主要优点之一;相比之下,我们的基线等模型仅限于其预设词汇。
损失函数如方程(6)和(7)所述,但与方程(9)中给出的修正概率分布P(w)有关。
2.3覆盖机制
重复是sequence-to-sequence模型的一个常见问题(Tu et al,2016;Mi等人,2016;Sankaran等人,2016年;Suzuki和Nagata,2016),并且在生成多句文本时特别明显(见图1)。我们采用Tu等人(2016)的覆盖模型来解决这个问题。在我们的覆盖模型中,我们维护了一个覆盖向量ct,它是所有先前解码器时间步长上注意力分布的总和:
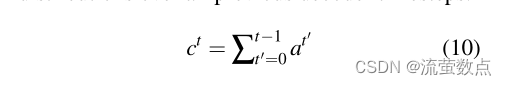
直观地说,ct是源文档单词的(非标准化)分布,它代表了到目前为止这些单词从注意力机制获得的覆盖程度。注意c0是一个零向量,因为在第一个时间步中,没有一个源文档被覆盖。
覆盖向量被用作注意力机制的额外输入,将等式(1)改变为:
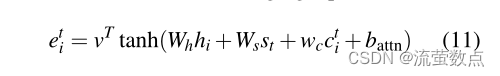
其中wc是与v长度相同的可学习参数向量。这确保了注意力机制的当前决定(选择下一个参加的地点)通过其先前决定的提醒(总结在ct中)来通知。这将使注意力机制更容易避免重复关注相同的位置,从而避免产生重复的文本。
我们发现有必要(见第5节)额外定义承保损失,以惩罚重复出现在相同地点的情况:

注意,覆盖损失是有界的;特别是colosst≤ ∑i ati=1。等式(12)不同于机器翻译中使用的覆盖损失。在机器翻译中,我们假设应该有大致一对一的翻译比率;因此,如果最终覆盖向量大于或小于1。我们的损失函数更加灵活:因为摘要不需要统一的覆盖范围,所以我们只惩罚到目前为止每个注意力分布和覆盖范围之间的重叠——防止重复注意力。最后,通过一些超参数λ重新加权的覆盖损失被添加到主要损失函数中,以产生新的复合损失函数:
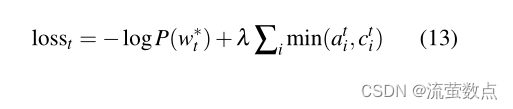
3.相关工作
神经抽象摘要。Rush等人(2015)首次将现代神经网络应用于抽象文本摘要,在DUC-2004和Gigaword两个句子级摘要数据集上实现了最先进的性能。他们的方法以注意力机制为中心,通过循环解码器(Chopra等人,2016)、抽象意义表示(Takase等人,2016年)、分层网络(Nalapati等人,2015年)、变分自动编码器(Miao和Blunsom,2016)和性能度量的直接优化(Ranzato等人,2016,进一步提高这些数据集的性能
然而,用于较长文本摘要的大规模数据集是罕见的。Nallapati等人(2016年)将DeepMind问答数据集(Hermann等人,2015年)用于汇总,生成了CNN/Daily Mail数据集,并提供了第一个抽象基线。同样的作者随后发表了一种神经提取方法(Nallapati等人,2017),该方法使用分层RNN来选择句子,并发现它在粗糙度度量方面显著优于他们的抽象结果。据我们所知,这是完整数据集上仅有的两个已发布结果。
在现代神经方法之前,抽象摘要比提取摘要受到的关注更少,但Jing(2000)探索了切割句子中不重要的部分来创建摘要,Cheung和Penn(2014)探索了使用依赖树的句子融合。
指针生成器网络。指针网络(Vinyals等人,2015)是一个序列到序列模型,它使用Bahdanau等人(2015)的软注意力分布来产生一个输出序列,该输出序列由以下元素组成:输入序列。指针网络已用于为NMT(Gulcehre等人,2016)、语言建模(Merity等人,2016年)和总结(Gu等人,2015;Gulcehree等人,2016;Miao和Blunsom,2016;Nallapati等人,2016,Zeng等人,2016。)创建混合方法。
我们的方法接近于Miao和Blunsom(2016)的强迫注意句子压缩模型和Gu等人的CopyNet模型(2016),有一些小的区别:(i)我们计算了显式切换概率pgen,而Gu等人通过共享的softmax函数诱导竞争。(ii)我们回收注意力分布作为副本分布,但Gu等人使用了两个单独的分布。(iii)当一个单词在源文本中出现多次时,我们将注意力分布的所有对应部分的概率质量相加,而Miao和Blunsom则没有。我们的推理是:(i)计算一个显式pgen有助于我们一次提高或降低所有生成单词或所有复制单词的概率,而不是单独地;(ii)这两个分布具有相似的目的,我们发现我们的简单方法就足够了,以及(iii)我们观察到,指针机制经常复制一个单词,同时注意源文本中该单词的多次出现。
我们的方法与Gulcehre等人(2016)和Nalapati等人(2016)大不相同. 这些工作训练它们的指针组件,使其仅针对词汇表外的单词或命名实体激活(而我们允许我们的模型自由学习何时使用指针),并且它们不混合来自副本分布和词汇分布的概率。我们认为这里所描述的混合方法对于抽象概括更好——在第6节中,我们表明复制机制对于准确复制罕见但词汇丰富的单词至关重要,在第7.2节中我们观察到混合模型使语言模型和复制机制能够协同工作以执行抽象复制。
覆盖。源于统计机器翻译(Koehn,2009),Tu等人(2016)和Mi等人对NMT的覆盖范围进行了调整(2016),他们都使用GRU来更新每个步骤的覆盖向量。我们发现,一种更简单的方法——对注意力分布求和以获得覆盖向量——就足够了。在这方面,我们的方法类似于Xu等人(2015),他们将类似覆盖的方法应用于图像字幕,以及Chen等人(2016),他们还将等式(11)中描述的覆盖机制(他们称之为“分散注意力”)结合到长文本的神经摘要中。
Temporal attention时间注意力是一种相关技术,已应用于NMT(Sankaran等人,2016年)和总结(Nallapati等人,2016)。在这种方法中,每个注意力分布被前一个注意力分布的总和所除,这有效地抑制了重复注意力。我们尝试了这种方法,但发现它太具有破坏性,扭曲了注意力机制的信号,降低了性能。我们假设,早期干预方法(如覆盖)比事后干预方法(例如时间注意)更可取——告知注意机制以帮助其做出更好的决定,而不是完全推翻其决定。与同一任务的时间注意力所带来的较小提升相比,覆盖率为我们的ROUGE评分提供了较大提升(见表1),这一理论得到了支持(Nallapati等人,2016)。
4.数据集
我们使用了CNN/每日邮报数据集(Hermann等人,2015年;Nallapati等人,2016年),该数据集包含在线新闻文章(平均781个标记)和多句子摘要(平均3.75个句子或56个标记)。我们使用Nallapati等人(2016)提供的脚本来获得相同版本的数据,该数据包含287226个训练对、13368个验证对和11490个测试对。数据集的两个已发布结果(Nallapati等人,20162017)都使用了数据的匿名版本,该数据已被预处理,以替换每个命名实体,例如联合国,并使用其自己的示例对唯一标识符,例如@entity5。相比之下,我们直接对原始文本(或数据的非匿名版本)进行操作,2,我们认为这是需要解决的有利问题,因为它不需要预处理。
5.实验
对于所有实验,我们的模型具有256维隐藏状态和128维单词嵌入。对于指针生成器模型,我们对源和目标都使用了50k个单词的词汇表–请注意,由于指针网络处理OOV单词的能力,我们可以使用比Nallapati等人(2016)的150k源和60k目标词汇表的词汇量小。对于基线模型,我们还尝试了150k的更大词汇量。
注意,指针和覆盖机制为网络引入了很少的额外参数:对于词汇大小为50k的模型,基线模型有21499600个参数,指针生成器添加了1153个额外参数(例如wh∗, 公式8中的ws、wx和bptr),覆盖范围增加了512个额外参数(公式11中的wc)。
与Nallapati等人(2016)不同,我们没有对嵌入这个词进行预处理——它们是在训练过程中从头开始学习的。我们使用Adagrad(Duchi等人,2011)进行训练,学习率为0.15,初始累加器值为0.1。(发现这在随机梯度下降、Adadelta、Momentum、Adam和RMSProp中效果最好)。我们使用最大梯度范数为2的梯度裁剪,但不使用任何形式的正则化。我们使用验证集上的损失来实现早期停止。
在培训期间和测试时,我们将文章截断为400个令牌,并将摘要的长度限制为100个令牌用于培训,在测试时限制为120个令牌。这样做是为了加快训练和测试,但我们也发现缩短文章可以提高模型的性能(详见第7.1节)。对于训练,我们发现从高度截断的序列开始,然后在收敛后提高最大长度是有效的。我们在一个批量大小为16的特斯拉K40m GPU上进行训练。在测试时,我们使用波束大小为4的波束搜索生成总结。
我们对两个基线模型进行了约600000次迭代(33个时期)的训练——这与Nallapati等人(2016)的最佳模型所需的35个时期相似。50k词汇模型的培训时间为4天14小时,150k词汇模型为8天21小时。我们发现指针生成器模型训练速度更快,需要不到230000次训练迭代(12.8次);总共3天4小时。特别是,指针生成器模型在训练的早期阶段进步更快。
为了获得我们的最终覆盖模型,我们添加了覆盖损失加权为λ=1的覆盖机制(如等式13所述),并进一步训练了3000次迭代(约2小时)。在这段时间内,覆盖损失从初始值约0.5下降到约0.2。我们还尝试了更积极的值λ=2;这减少了覆盖损失,但增加了主要损失函数,因此我们没有使用它。
我们尝试在没有损失函数的情况下训练覆盖模型,希望注意力机制可以自己学习不重复出现在同一地点,但我们发现这是无效的,重复次数没有明显减少。我们还尝试了从一开始就覆盖的培训迭代而不是作为单独的训练阶段,但发现在训练的早期阶段,覆盖目标干扰了主要目标,从而降低了整体性能。
6.结果
6.1准备工作
表1给出了我们的结果。我们使用标准ROUGE度量(Lin,2004b)评估了我们的模型,报告了ROUGE1、ROUGE-2和ROUGE-L的F1分数(分别测量参考摘要和待评估摘要之间的单词重叠、双字重叠和最长公共序列)。我们使用Pyruge软件包获得ROUGE分数。4我们还使用METEOR度量进行评估(Denkowski和Lavie,2014年),包括精确匹配模式(仅奖励单词之间的精确匹配)和完整模式(额外奖励匹配的词干、同义词和释义)。
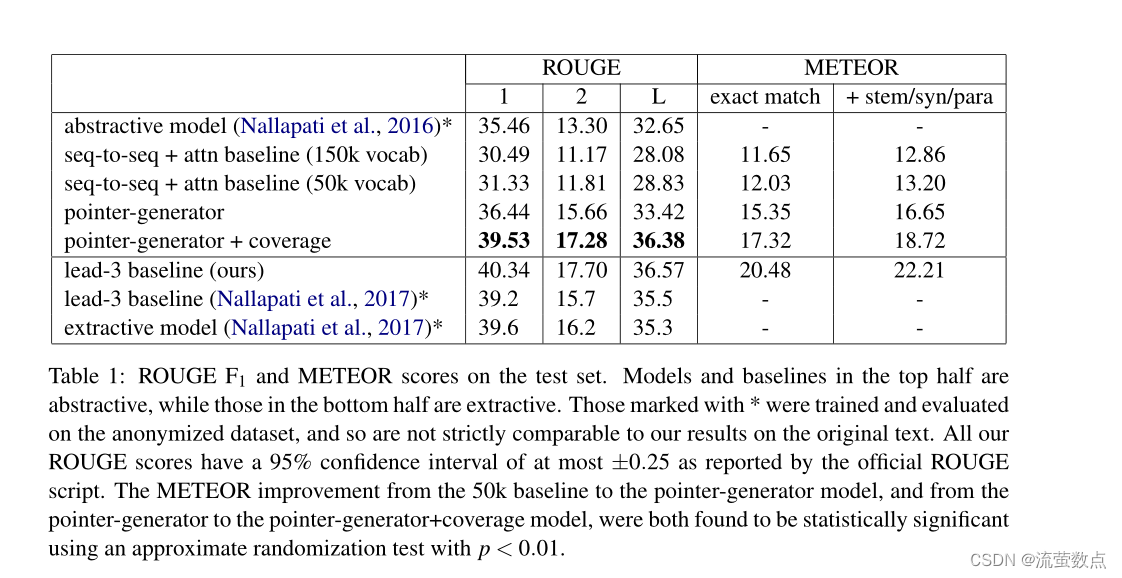
表1:测试集的ROUGE F1和METEOR分数。上半部分的模型和基线是抽象的,而下半部分的是抽象的。那些标有*的人是在匿名数据集上训练和评估的,因此不能严格与我们在原始文本上的结果进行比较。根据官方ROUGE脚本的报告,我们所有的ROUGE分数的95%置信区间最多为±0.25。从50k基线到指针生成器模型,以及从指针生成器到指针生成器+覆盖模型,METEOR的改善均通过近似随机检验发现具有统计学意义,p<0.01。
除了我们自己的模型外,我们还报告了前导3基线(使用文章的前三句作为摘要),并与完整数据集上唯一现有的抽象模型(Nallapati等人,2016)和提取模型(Nalapati等人,2017)进行了比较。我们的模型的输出可在线获得。
考虑到我们生成纯文本摘要,但Nallapati等人(2016;2017)生成匿名摘要(见第4节),我们的ROUGE分数并非严格可比。有证据表明,与匿名数据集相比,原始文本数据集通常会导致更高的ROUGE分数——前者的前导3基线高于后者。一种可能的解释是,多个单词命名的实体导致更高的n-gram重叠率。不幸的是,ROUGE是与Nallapati等人的工作进行比较的唯一可用方法。然而,考虑到前导3得分的差异分别为(+1.1 ROUGE-1、+2.0 ROUGE-2、+1.1 ROOGEL)分,并且我们的最佳模型得分超过Nallapati等人(2016)(+4.07 ROUGE1、+3.98 ROUGE-1、+3.73 ROUGE-L)分,我们可以估计,我们在所有方面都超过了之前唯一的抽象系统至少2个ROUGE分。
6.2观察结果
我们发现,我们的两个基线模型在ROUGE和METEOR方面表现不佳,事实上,更大的词汇量(150k)似乎没有帮助。即使是表现更好的基线(拥有50k词汇)也会产生一些常见问题的总结。事实细节经常被错误地复制,经常用一个更常见的替代词替换一个不常见的(但在词汇中)词。例如,在图1中,基线模型似乎与“阻挠”这个罕见的词斗争,反而产生了不稳定,这导致了编造的短语“破坏尼日利亚经济稳定”。更可怕的是,总结有时会演变成重复的废话,如图1中基线模型生成的第三句话。此外,基线模型无法复制词汇表外的单词(如图1的muhammadu buhari)。补充材料中提供了所有这些问题的进一步示例。
我们的指针生成器模型实现了比基线更好的ROUGE和METEOR分数,尽管训练时间更少。摘要中的差异也很明显:词汇表外的单词很容易处理,事实细节几乎总是正确复制,没有捏造(见图1)。然而,重复仍然很常见。
我们的具有覆盖率的指针生成器模型进一步提高了ROUGE和METEOR分数,令人信服地超越了Nallapati等人(2016)的最佳抽象模型,超过了几个ROUGE点。尽管覆盖训练阶段很短(约占总训练时间的1%),但重复问题几乎完全消除,这可以从定性(图1)和定量(图4)两方面看到。然而,我们的最佳模型并没有完全超过铅-3基线的ROUGE分数,也没有超过当前最佳提取模型(Nallapati等人,2017)。我们在第7.1节中讨论了这个问题。

图4:覆盖消除了不期望的重复。我们的非覆盖模型的摘要包含许多重复的n-gram,而我们的覆盖模型产生的数字与参考摘要相似。
7.讨论
7.1与提取系统的比较
从表1中可以明显看出,提取式系统往往比抽象式系统获得更高的ROUGE分数,并且提取式前导3基线非常强(即使是最好的提取式系统也仅以很小的优势击败它)。我们为这些观察提供了两种可能的解释。
首先,新闻文章往往一开始就包含最重要的信息;这部分解释了前导3基线的强度。事实上,我们发现,仅使用文章的前400个标记(约20个句子)产生的ROUGE分数比使用前800个标记高得多。
其次,任务的性质和粗糙度度量使得提取方法和引线3基线难以超越。参考摘要的内容选择是相当主观的——有时句子形成一个独立的摘要;其他时候,他们只是展示文章中一些有趣的细节。考虑到文章平均包含39个句子,有许多同样有效的方法可以选择这种风格的3或4个亮点。摘要引入了更多选项(措辞选择),进一步降低了与参考摘要匹配的可能性。
例如,走私者从绝望的移民中获利是图5中第一个示例的有效替代抽象摘要,但相对于参考摘要,其得分为0 ROUGE。只有一份参考摘要加剧了ROUGE的这种不灵活,与多份参考摘要相比,这已证明降低了ROUGE的可靠性(Lin,2004a)。

文章:cnn的一项调查显示,走私者通过提供折扣来吸引阿拉伯和非洲移民,如果人们带来更多潜在乘客,他们可以登上拥挤的船只。
(…)概要:cnn调查发现了一个人口走私团伙内部的生意。
文章:一段目击者视频显示,北查尔斯顿白人警察迈克尔·斯莱格枪杀了一名手无寸铁的黑人男子,这段视频暴露了现场第一批警察的报告中的差异。(…)总结:在有争议的美国警察枪击案中,问题多于答案。
图5:高度抽象的参考摘要示例(粗体表示新单词)。
由于任务的主观性以及有效摘要的多样性,ROUGE似乎会奖励安全的策略,例如选择首次出现的内容或保留原始措辞。虽然参考摘要有时会偏离这些技术,但这些偏离是不可预测的,以至于更安全的策略平均获得更高的ROUGE分数。这可能解释了为什么提取式系统往往比抽象式系统获得更高的ROUGE分数,甚至提取式系统也不会显著超过前导3基线。
为了进一步探讨这个问题,我们使用METEOR度量评估了我们的系统,该度量不仅奖励精确的单词匹配,还奖励匹配的词干、同义词和释义(来自预定义列表)。我们观察到,通过包含词干、同义词和释义匹配,我们的所有模型都获得了超过1个METEOR点的提升,表明它们可能正在执行某种抽象。然而,我们再次观察到,我们的模型没有超过前导3基线。这可能是因为新闻文章的风格使得lead3基线在任何指标方面都非常强大。我们认为,进一步调查这一问题是今后工作的一个重要方向。
7.2我们的模型有多抽象?
我们已经证明,我们的指针机制使我们的抽象系统更可靠,更经常地正确复制事实细节。但是,复制的便捷性是否会降低我们的系统的抽象性?
图6显示,与参考摘要相比,我们最终模型的摘要包含的新n元(即,文章中没有出现的)比率要低得多,表明抽象程度较低。请注意,基线模型更频繁地生成新的n-gram——然而,该统计数据包括所有错误复制的单词、UNK标记和捏造以及良好的抽象实例。
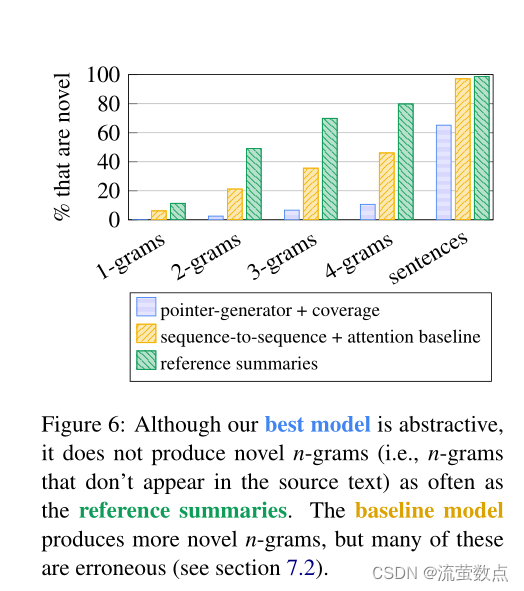
图6:虽然我们最好的模型是抽象的,但它并不像参考摘要那样经常产生新的n元语法(即,源文本中没有出现的n元)。基线模型产生了更新颖的n-gram,但其中许多是错误的(见第7.2节)。
特别是,图6显示,我们的最终模型有35%的时间复制整篇文章的句子;相比之下,参考摘要仅在1.3%的时间内这样做。这是一个需要改进的主要领域,因为我们希望我们的模型超越简单的句子提取。然而,我们观察到,其他65%包含一系列抽象技术。文章句子被截断以形成语法正确的较短版本,而新句子则通过将片段拼接在一起而构成。不必要的感叹词、从句和带括号的短语有时会从复制的段落中省略。图1展示了其中的一些能力,补充材料包含了更多示例。
图7显示了两个更令人印象深刻的抽象示例——两者都具有相似的结构。数据集包含许多体育故事,其摘要遵循模板上的X beat Y <score> on <day>,这可以解释为什么我们的模型对这些示例最有信心。然而,总的来说,我们的模型不会像图7那样常规地生成摘要,也不会像图5那样接近于生成摘要。

文章:安迪·穆雷(…)进入了迈阿密公开赛的半决赛,但在21岁的奥地利选手多米尼克·蒂姆(dominic thiem)吓了一跳之前,他在第二盘将自己推到了4-4,然后在一小时三节的时间里以3-6、6-4、6-1落后。
(…)摘要:安迪·穆雷在一小时零三节的时间里以3-6、6-4、6-1击败多米尼克·蒂姆。
文章:(…)鲁尼在周六曼联3-1战胜阿斯顿维拉的比赛中破门得分。
(…)摘要:曼联周六在老特拉福德3-1击败阿斯顿维拉。
图7:我们的模型生成的抽象摘要示例(粗体表示新颖的单词)。
生成概率pgen的值也给出了模型抽象性的度量。在训练期间,pgen开始时的值约为0.30,然后增加,到训练结束时收敛到约0.53。这表明模型首先学习大部分复制,然后学习生成大约一半的时间。然而,在测试时,pgen严重倾向于复制,平均值为0.17。差异可能是因为在训练期间,模型以参考摘要的形式接受逐字监督,但在测试时却没有。尽管如此,即使在复制模型时,生成器模块也很有用。我们发现,pgen在不确定的时候最高,比如句子的开头,拼接在一起的片段之间的连接,以及产生截断复制句子的句点。我们的混合模型允许网络在同时查询语言模型的同时进行复制,从而使拼接和截断等操作能够在语法上执行。无论如何,鼓励指针生成器模型更抽象地编写,同时保留指针模块的准确性优势,是未来工作的一个令人兴奋的方向。
8.结论
在这项工作中,我们提出了一种具有覆盖范围的混合指针生成器架构,并表明它减少了不准确和重复。我们将我们的模型应用于一个新的具有挑战性的长文本数据集,并显著优于抽象的最新结果。我们的模型显示出许多抽象能力,但实现更高层次的抽象仍然是一个开放的研究问题。