1. 初识Flink
1.1 Flink是什么
Apache Flink 是一个框架和分布式处理引擎, 用于对无界和有界数据流进行状态计算. Flink框架处理流程如下图所示:
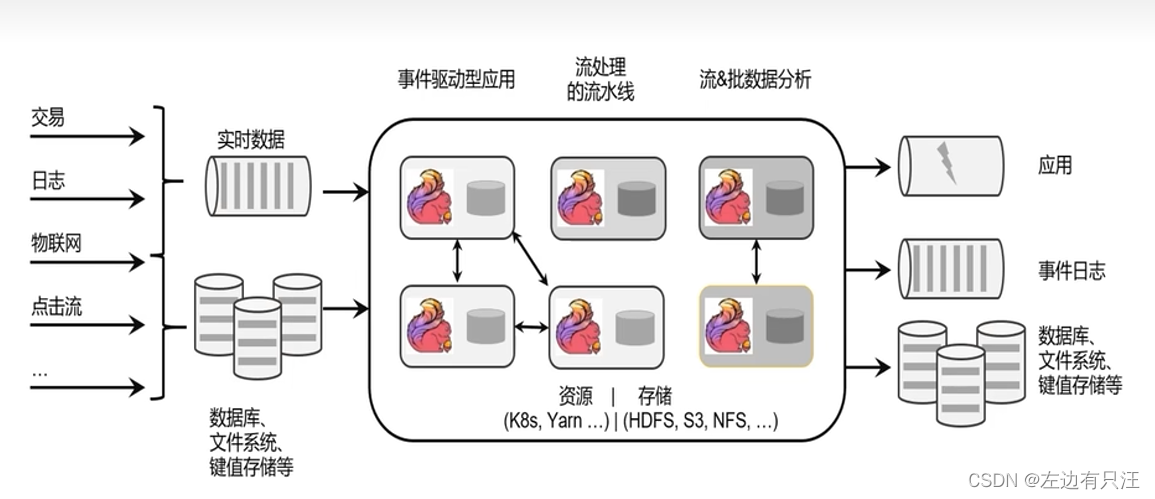
Flink的应用场景:
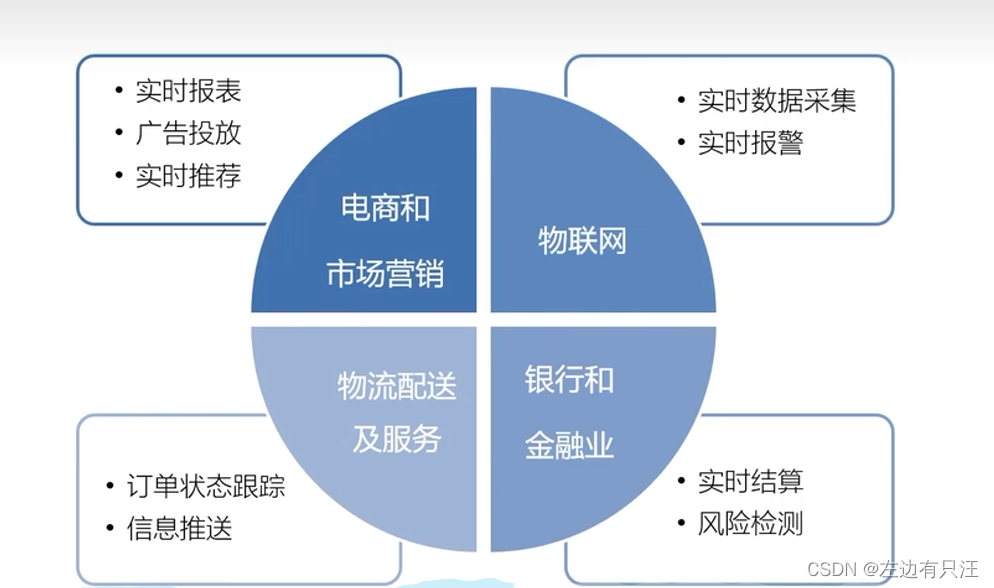
1.2 为什么选择Flink
- 批处理和流处理
- 流数据更真实地反应了我们的生活方式
- 我们的目标
- 低延迟
- 高吞吐
- 结果的准确性和良好的容错性
1.3 数据处理架构的发展
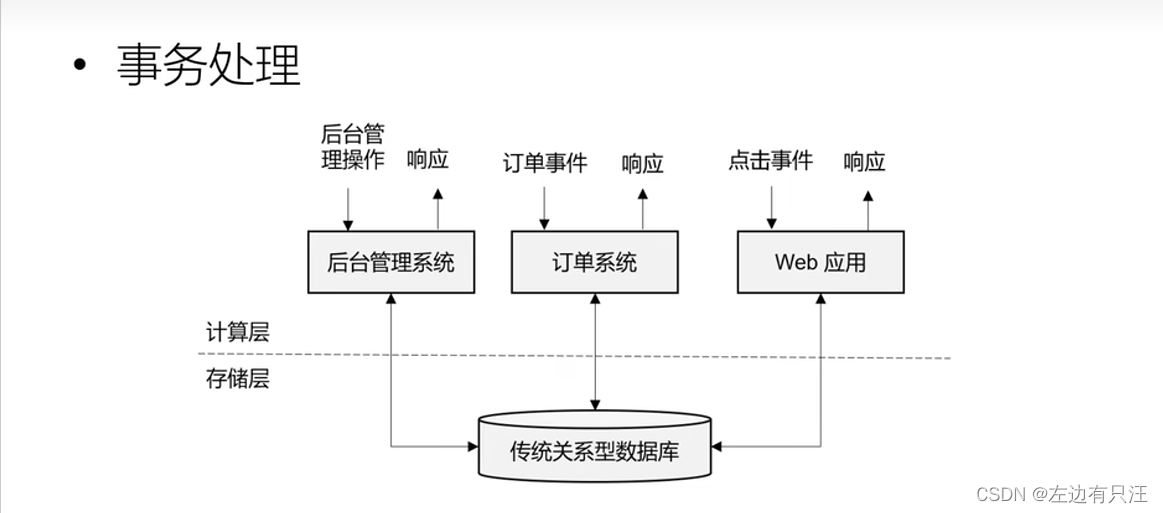
- 事务处理
- 分析处理, 如大数据框架hadoop和hive 都是离线的, 保存一定的数据量后进行处理
- 有状态的流式处理
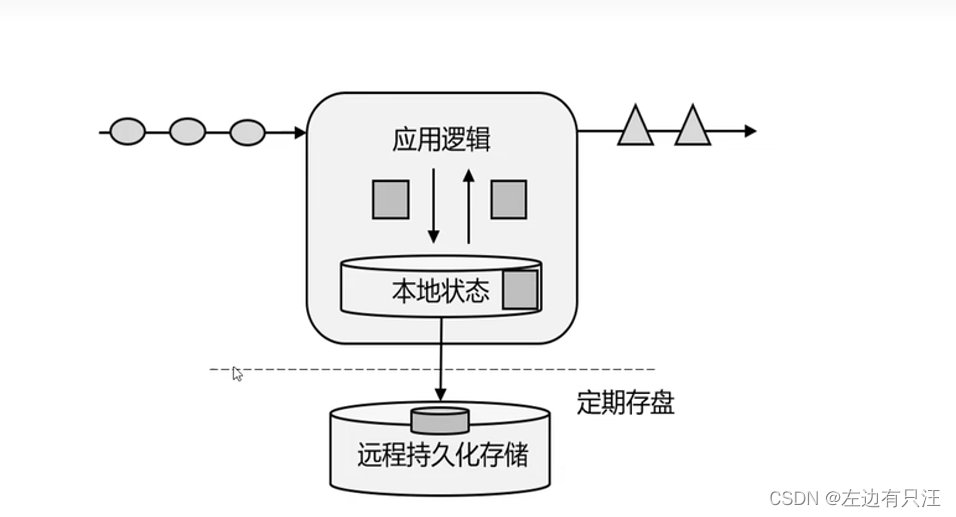
- lambda架构的流式处理
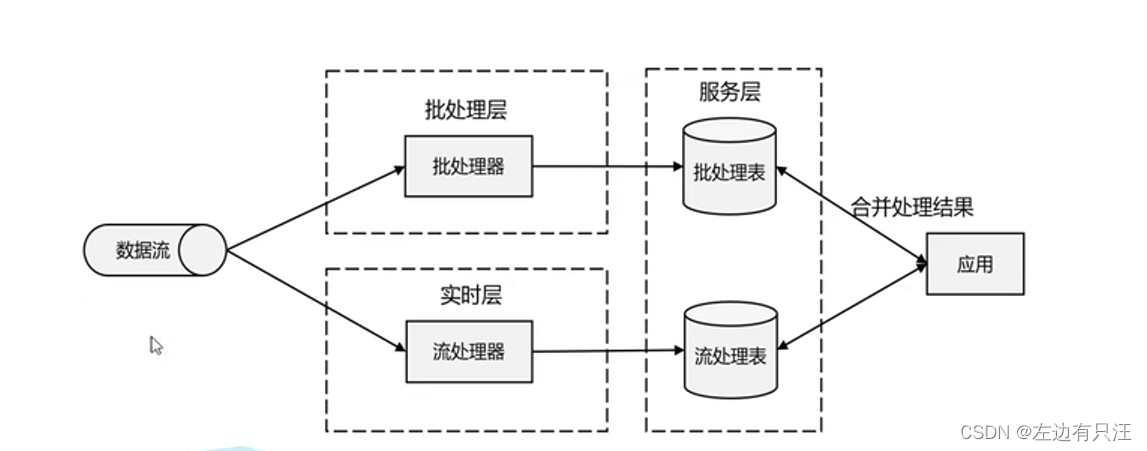
1.4 新一代流处理器Flink
核心特点:
- 高吞吐, 低延迟
- 结果的准确性
- 精确一次(exactly-once)的状态一致性保证
- 可以与众多常用存储系统连接
- 高可用, 支持动态扩展
1.5 Flink的应用场景
-
事件驱动型应用
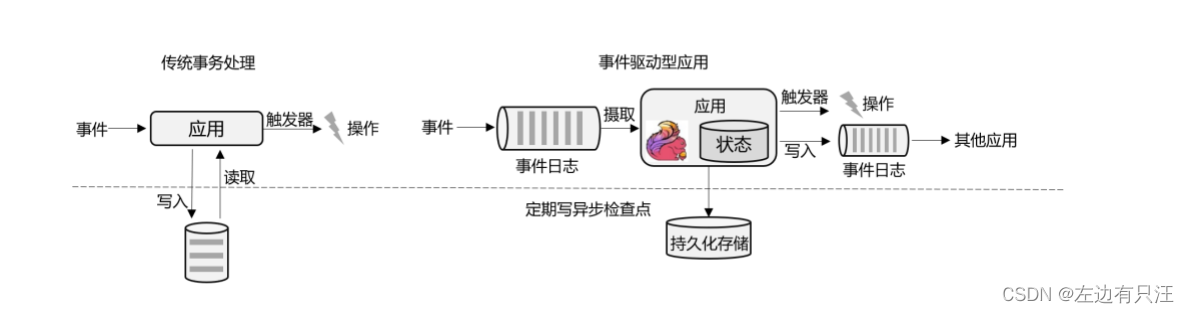
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以 Kafka 为代表的消息队列几乎都是事件驱动型应用。
这其实跟传统事务处理本质上是一样的,区别在于基于有状态流处理的事件驱动应用,不再需要查询远程数据库,而是在本地访问它们的数据,这样在吞吐量和延迟方面就可以有更好的性能。
另外远程持久性存储的检查点保证了应用可以从故障中恢复。检查点可以异步和增量地完成,因此对正常计算的影响非常小。 -
数据分析型应用
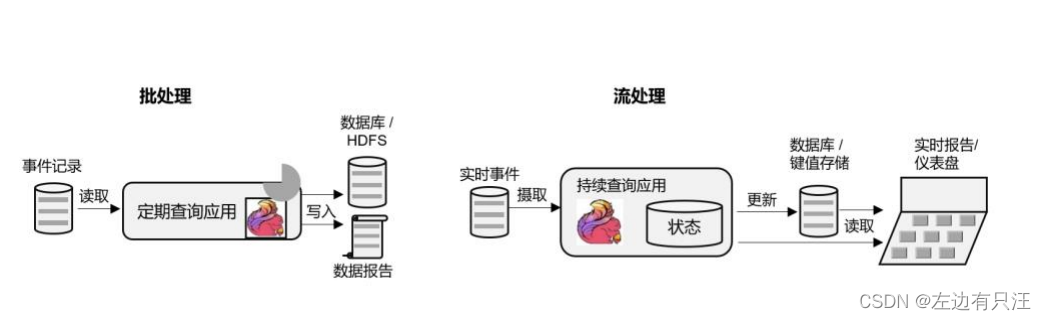
所谓的数据分析,就是从原始数据中提取信息和发掘规律。传统上,数据分析一般是先将数据复制到数据仓库(Data Warehouse),然后进行批量查询。如果数据有了更新,必须将最新数据添加到要分析的数据集中,然后重新运行查询或应用程序。
如今,Apache Hadoop 生态系统的组件,已经是许多企业大数据架构中不可或缺的组成部分。现在的做法一般是将大量数据(如日志文件)写入 Hadoop 的分布式文件系统(HDFS)、S3 或 HBase 等批量存储数据库,以较低的成本进行大容量存储。然后可以通过 SQL-on-Hadoop
类的引擎查询和处理数据,比如大家熟悉的 Hive。这种处理方式,是典型的批处理,特点是可以处理海量数据,但实时性较差,所以也叫离线分析。
如果我们有了一个复杂的流处理引擎,数据分析其实也可以实时执行。流式查询或应用程序不是读取有限的数据集,而是接收实时事件流,不断生成和更新结果。结果要么写入外部数据库,要么作为内部状态进行维护。
Apache Flink 同时支持流式与批处理的数据分析应用。
与批处理分析相比,流处理分析最大的优势就是低延迟,真正实现了实时。另外,流处理不需要去单独考虑新数据的导入和处理,实时更新本来就是流处理的基本模式。当前企业对流式数据处理的一个热点应用就是实时数仓,很多公司正是基于 Flink 来实现的。 -
数据管道型应用
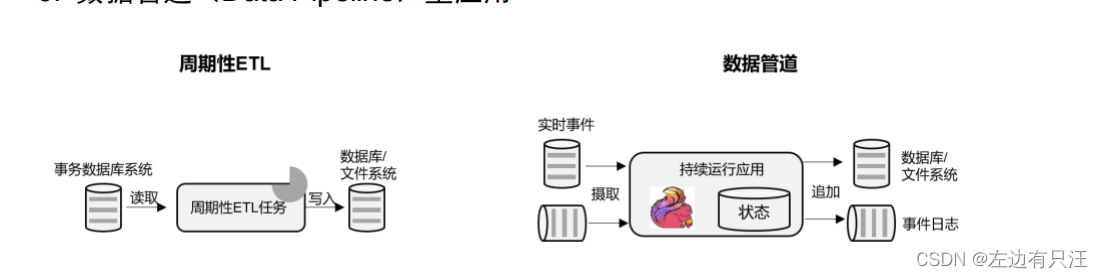
ETL 也就是数据的提取、转换、加载,是在存储系统之间转换和移动数据的常用方法。在数据分析的应用中,通常会定期触发 ETL 任务,将数据从事务数据库系统复制到分析数据库或数据仓库。
所谓数据管道的作用与 ETL 类似。它们可以转换和扩展数据,也可以在存储系统之间移动数据。不过如果我们用流处理架构来搭建数据管道,这些工作就可以连续运行,而不需要再去周期性触发了。比如,数据管道可以用来监控文件系统目录中的新文件,将数据写入事件日志。连续数据管道的明显优势是减少了将数据移动到目的地的延迟,而且更加通用,可以用于更多的场景。如图所示展示了 ETL 与数据管道之间的区别。
有状态的流处理架构上其实并不复杂,很多用户基于这种思想开发出了自己的流处理系统,这就是第一代流处理器。Apache Storm 就是其中的代表。Storm 可以说是开源流处理的先锋,最早是由 Nathan Marz 和创业公司 BackType 的一个团队开发的,后来才成为 Apache 软
件基金会下属的项目。Storm 提供了低延迟的流处理,但是它也为实时性付出了代价:很难实现高吞吐,而且无法保证结果的正确性。用更专业的话说,它并不能保证“精确一次”
(exactly-once);即便是它能够保证的一致性级别,开销也相当大。关于状态一致性和exactly-once,我们会在后续的章节中展开讨论。
Flink的分层API
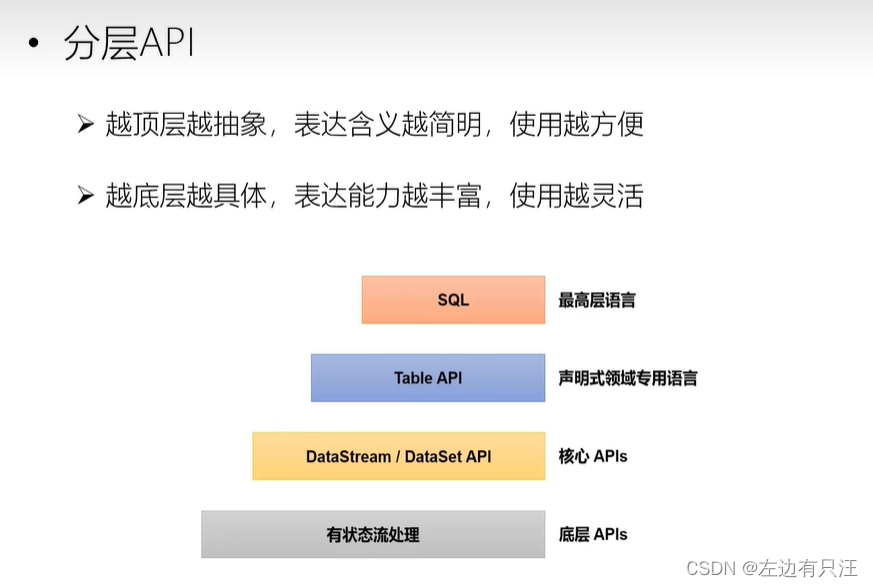
在Flink1.12版本后, 用DataStreamAPI可以实现批流一体化, 现在基本上不用DataSetAPI了
2. Flink快速上手
2.1 创建一个Java项目
引入maven相关依赖
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.3.7.RELEASE</spring-boot.version>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
配置日志管理文件, 在resources下添加log4j.properties
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
2.2 批处理wordCount程序
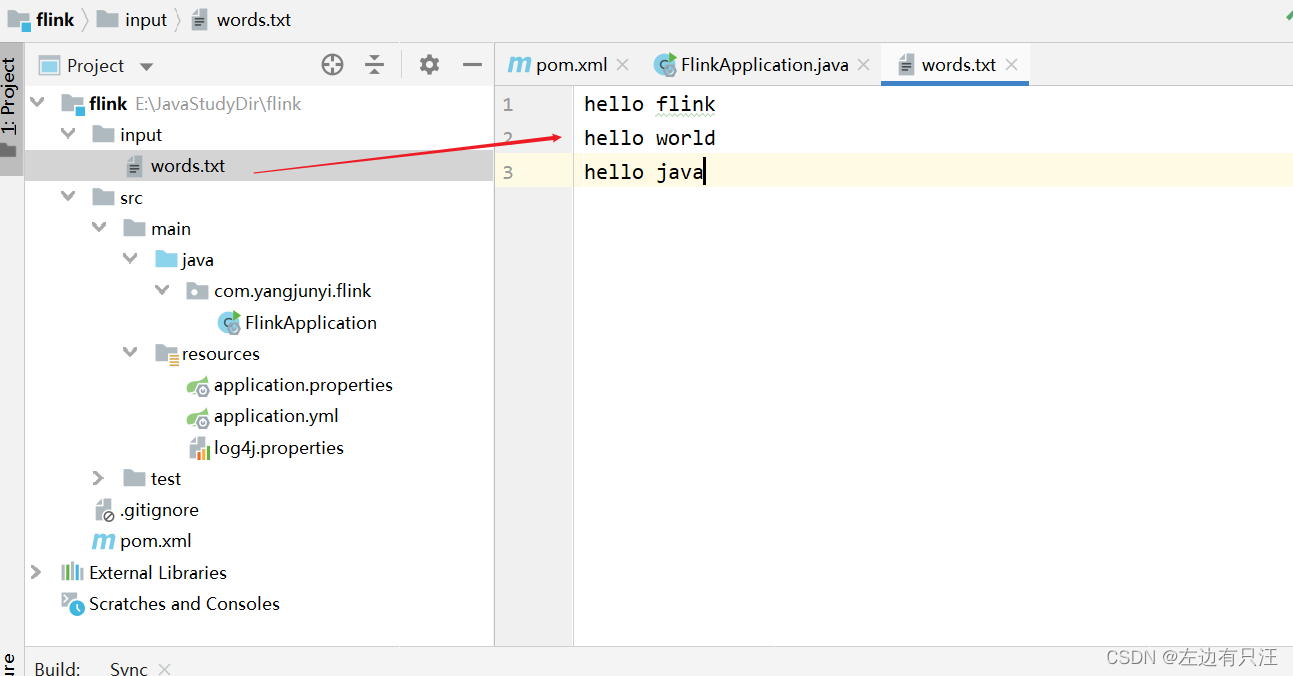
新建一个Java类, 用来测试批处理WordCount程序. 在根目录下创建一个input文件夹, 内部放一个words.txt文件
package com.yangjunyi.flink.batch.wordCount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCount {
public static void main(String[] args) {
// 1. 创建执行环境, 这里没有连接flink环境, 是因为数据源放在idea本地, 所以不需要连接到集群
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 获取数据源
DataSource<String> strDS = env.readTextFile("input/words.txt");
// 3. 转换数据格式, 需要把一行一行的字符串做扁平化处理 flatMap() 扁平化函数
// flatMap后接一个函数式变成, String line 代表读到的一行数据, 后面的Collector<Tuple2<String,Long>>
// 代表需要把line收集成一个tuple(元组类型) 数据结构类似于('hello',1) ('world',1) 这种格式
// 返回值代表扁平化的算子, 代表对运算的结果的中间算术运算, 第一个泛型String, 代表数据源每一行都是String类型
// 第二个泛型Tuple是最终算子的运算结果类型
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = strDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
// 在这里写如何对一个line进行操作, 使其变成多个元组
String[] lineStrs = line.split(" ");
for (String lineStr : lineStrs) {
// 使用Collector收集器对循环出来的每一个字符串进行收集,
// 每获得一个字符串就在元组中记录该字符串的数量为1
out.collect(Tuple2.of(lineStr, 1L));
}
// 在函数式变成的最后, 声明返回值是一个Tuple类型, Tuple的泛型为String 和Long
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 按照word进行分组, 0这个参数是对元组中哪个索引位置的数据进行分组, 我们对tuple中的第一个位置String类型的word进行分组
UnsortedGrouping<Tuple2<String, Long>> tuple2UnsortedGrouping = wordAndOne.groupBy(0);
// 5. 进行聚合, 对tuple中索引为1的地方, 也就是word的count进行聚合, 聚合方式是sum加和
AggregateOperator<Tuple2<String, Long>> sum = tuple2UnsortedGrouping.sum(1);
// 该print会抛出异常, 所以需要处理该异常
try {
sum.print();
} catch (Exception e) {
e.printStackTrace();
}
}
}
我在运行这段代码时是报错的. 提示org.apache.flink.runtime.taskexecutor.slot.SlotNotFoundException: Could not find slot for dff66956ba77ffac489f5136cc27364b. 但是通过一步一步debug时 ,我发现是可以打印出来的, 但是输出的结果隐藏在一堆报错中间, 不太方便查看, 这个错误字面意思是不能找到某一个slot, 关于这个的具体原因我会边学边思考.
2.3 流处理wordCount程序
流式处理, 执行结果也是一条一条累加的, 注意:需要使用流式处理环境和最后的执行命令
package com.yangjunyi.flink.stream.wordCount;
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 创建一个流处理环境
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> stringDataStreamSource = executionEnvironment.readTextFile("input/words.txt");
// 对读出来的数据进行扁平化操作
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = stringDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> wordCount) -> {
String[] words = line.split(" ");
for (String word : words) {
wordCount.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 设置分组, 以word进行分组
KeyedStream<Tuple2<String, Long>, String> tuple2StringKeyedStream = wordAndOne.keyBy(data -> data.f0);
// 对tuple中的count进行求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = tuple2StringKeyedStream.sum(1);
sum.print();
// 注意流式处理时, 因为是要一直读取的 所以多了一步启动的命令, 这里有异常, 先抛出去
JobExecutionResult execute = executionEnvironment.execute();
}
}

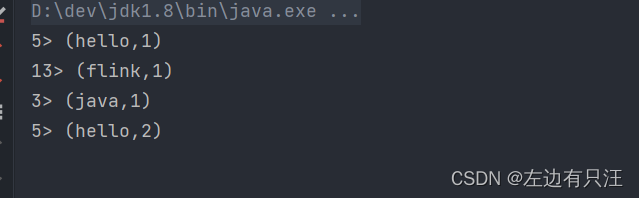
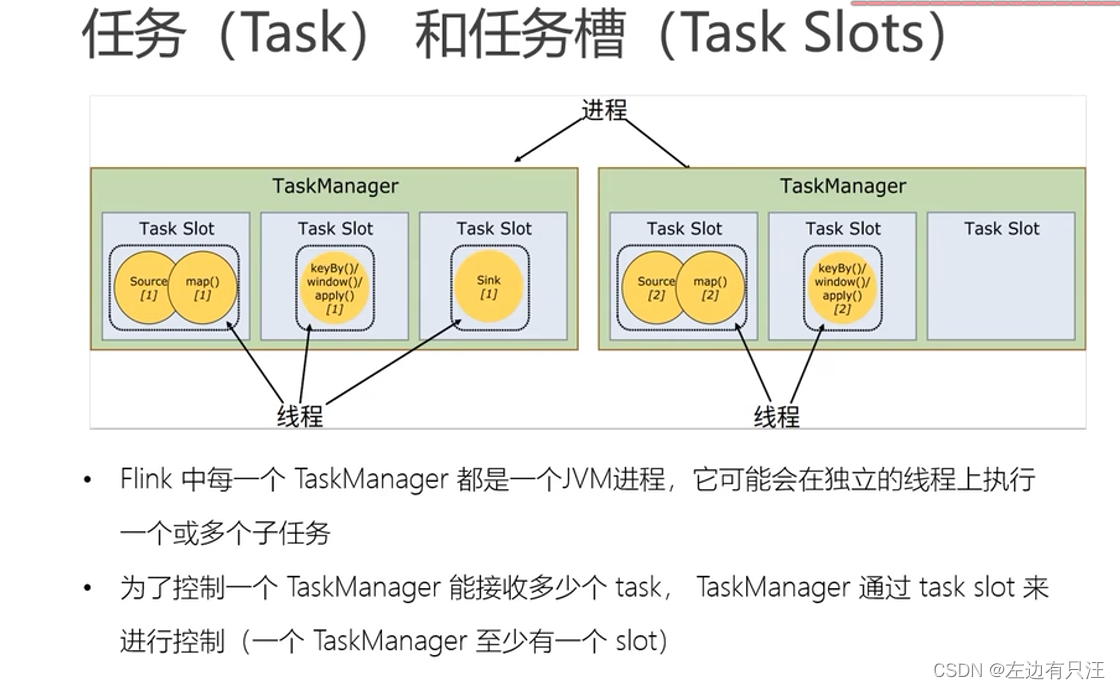
flink是并行执行的大数据框架, 不能保证对每一行的计算都是顺序执行的, 每一个数据是不断变化的, 可以看到依次叠加的过程, 因为流式处理, 数据是一条一条来的, 一共3个hello, 会被flink分配到一个执行单元去执行, 所以才会出现hello,1 hello,2 hello,3的现象. 在开发环境时, Idea用多线程来模拟flink集群, 并行的处理数据. 结果前面的数字, 代表本地以哪个线程来执行并输出任务的, flink中把最小的任务单位叫做任务槽(task slot)
2.4 无界流处理WordCount
正常情况下, 流应该是源源不断的状态过来的, 所以要保持一个监听, 时刻监听需要处理的流数据. 可以用Linux自带的netcat来模拟socket, 实时发送流数据. 在linux服务器中, 使用命令nc -lk 7777启动netcat 并使用7777端口来保持持续发送的功能, 如果没有nc命令的话, 使用yum install nc 来安装.
package com.yangjunyi.flink;
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 创建一个流处理环境
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// DataStreamSource<String> stringDataStreamSource = executionEnvironment.readTextFile("input/words.txt");
// 读取一个socket文本流, 配置主机名, 端口号
DataStreamSource<String> stringDataStreamSource = executionEnvironment.socketTextStream("192.168.0.105", 7777);
// 对读出来的数据进行扁平化操作
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = stringDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> wordCount) -> {
String[] words = line.split(" ");
for (String word : words) {
wordCount.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 设置分组, 以word进行分组
KeyedStream<Tuple2<String, Long>, String> tuple2StringKeyedStream = wordAndOne.keyBy(data -> data.f0);
// 对tuple中的count进行求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = tuple2StringKeyedStream.sum(1);
sum.print();
// 注意流式处理时, 因为是要一直读取的 所以多了一步启动的命令, 这里有异常, 先抛出去
JobExecutionResult execute = executionEnvironment.execute();
}
}
把直接读取文本流, 换成监听socket端口,其余操作不变
在socket中输入hello world

可以看到在idea中已经读取到了输入的行, 并按wordcount的方式输出了

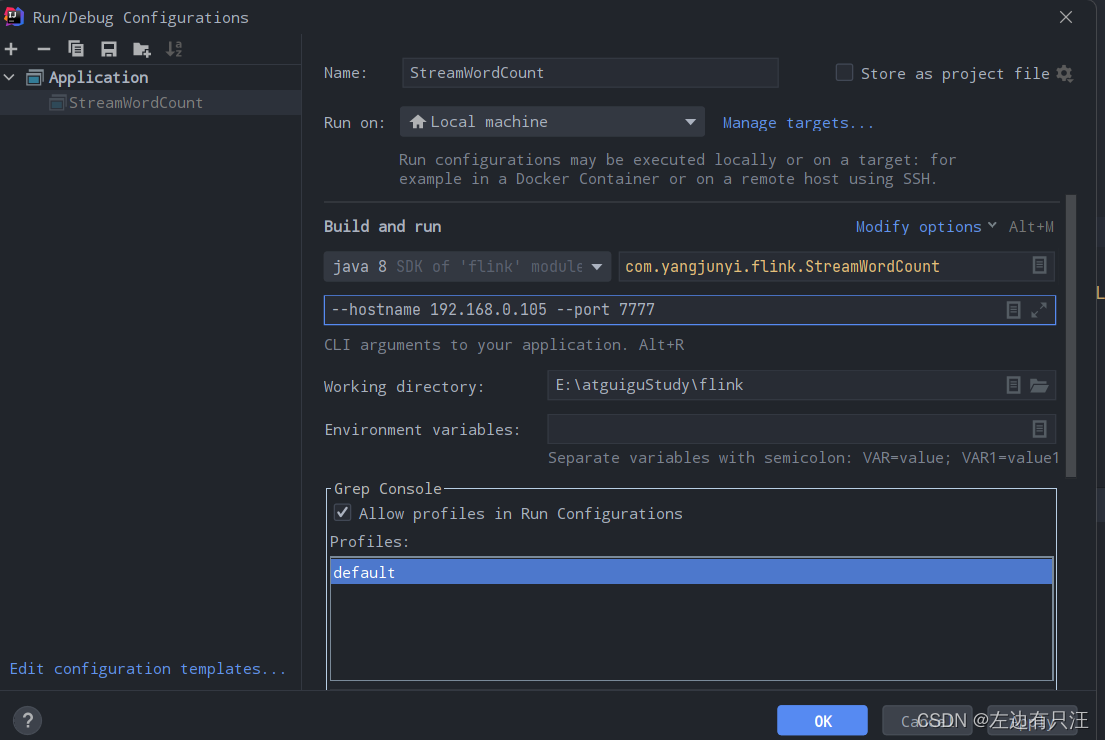
2.5 通过运行时参数配置监听ip和端口
flink提供的通过main方法的args参数来提取参数的工具ParameterTool.formArgs()
把前面写死的ip和端口号通过参数的配置来读取出来

配置idea的启动命令参数
在netcat中输入文本后, 在idea中可以看到结果
3.Flink部署
在idea中启动flink流处理时, 不会已启动就执行相关代码的, 在启动时, 首先要把计算机模拟成一个flink集群, 然后把中间的代码打包成一个job发布到flink集群上, 在数据进来后才会依次执行.
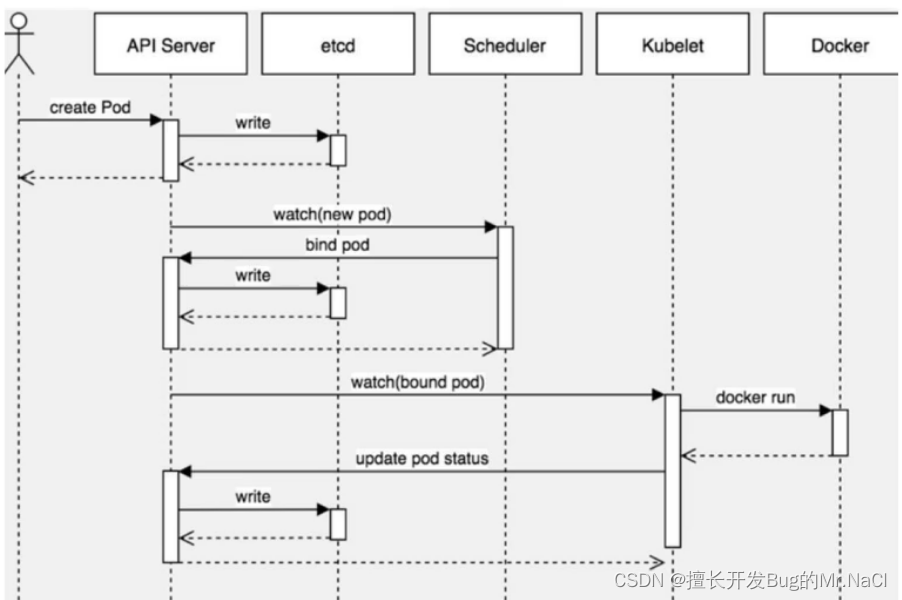
这里需要提到 Flink 中的几个关键组件:客户端(Client)、作业管理器(JobManager)和任务管理器(TaskManager)。我们的代码,实际上是由客户端获取并做转换,之后提交给JobManger 的。所以 JobManager 就是 Flink 集群里的“管事人”,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的 TaskManager。这里的 TaskManager,就是真正“干活的人”,数据的处理操作都是它们来做的.
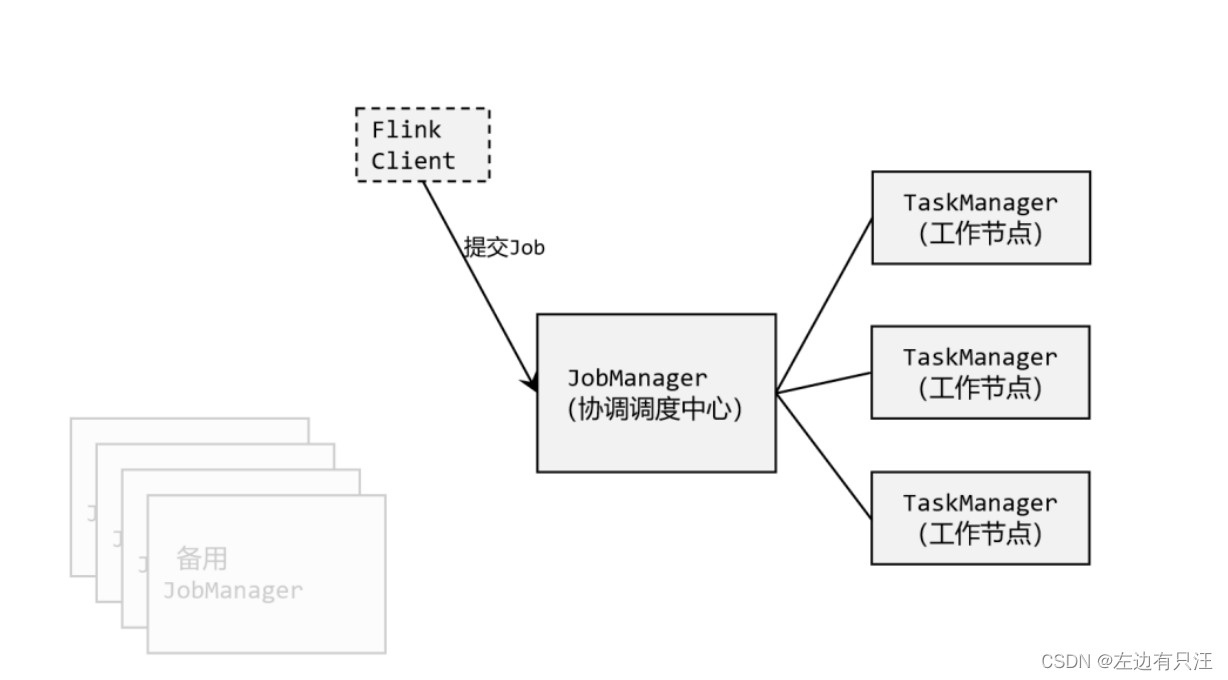
3.1 快速启动
3.1.1 环境配置
Flink 是一个分布式的流处理框架,所以实际应用一般都需要搭建集群环境。我们在进行Flink 安装部署的学习时,需要准备 3 台 Linux 机器。具体要求如下:

3.1.2 本地启动
最简单的启动方式,其实是不搭建集群,直接本地启动。本地部署非常简单,直接解压安装包就可以使用,不用进行任何配置;一般用来做一些简单的测试。
- 下载安装包
进入 Flink 官网,下载 1.13.0 版本安装包 flink-1.13.0-bin-scala_2.12.tgz,注意此处选用对
应 scala 版本为 scala 2.12 的安装包。 - 解压
在 hadoop102 节点服务器上创建安装目录/opt/module,将 flink 安装包放在该目录下,并
执行解压命令,解压至当前目录。
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/ - 启动
进入解压后的目录,执行启动命令,并查看进程。
$ cd flink-1.13.0/
$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
$ jps
10369 StandaloneSessionClusterEntrypoint
10680 TaskManagerRunner
10717 Jps
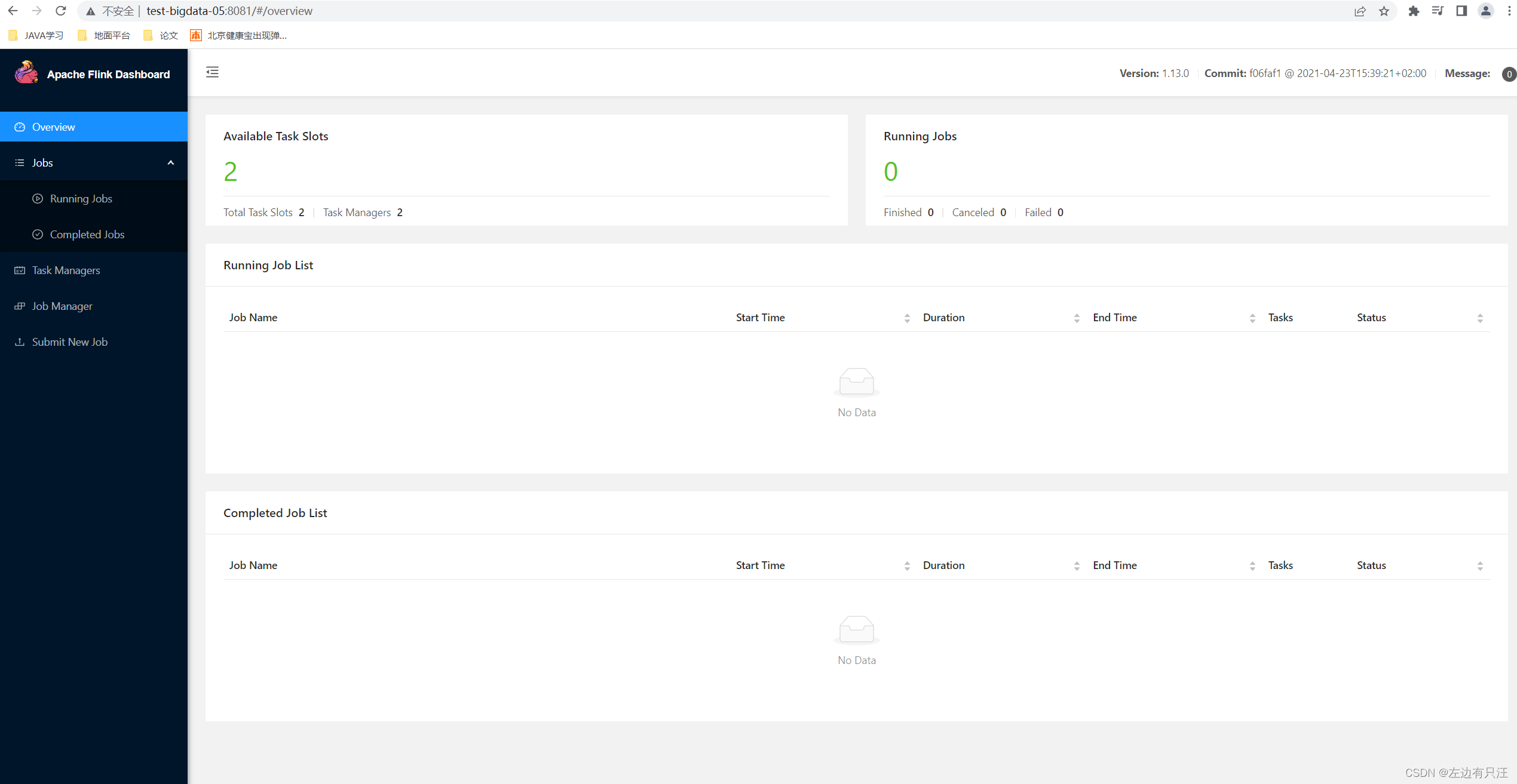
- 访问 Web UI
启动成功后,访问 http://hadoop102:8081,可以对 flink 集群和任务进行监控管理,如图 3-2
所示。 - 关闭集群
如果想要让 Flink 集群停止运行,可以执行以下命令:
bin/stop-cluster.sh
3.1.3 集群启动
Flink 是典型的 Master-Slave 架构的分布式数据处理框架,其中 Master 角色对应着JobManager,Slave 角色则对应 TaskManager。我们对三台节点服务器的角色分配如下所示。

- 下载并解压安装包
具体操作与上节相同。 - 修改集群配置
进入 conf 目录下,修改 flink-conf.yaml 文件,修改 jobmanager.rpc.address 参数为
hadoop102,如下所示:
cd conf/
vim flink-conf.yaml
# JobManager 节点地址.
jobmanager.rpc.address: hadoop102
这就指定了 hadoop102 节点服务器为 JobManager 节点。修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点,具体修改如下:
vim workers
hadoop103
hadoop104
这样就指定了 hadoop103 和 hadoop104 为 TaskManager 节点。
另外,在 flink-conf.yaml 文件中还可以对集群中的 JobManager 和 TaskManager 组件
进行优化配置,主要配置项如下:
jobmanager.memory.process.size:对 JobManager 进程可使用到的全部内存进行配置,
包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
taskmanager.memory.process.size:对 TaskManager 进程可使用到的全部内存进行配置,
包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
taskmanager.numberOfTaskSlots:对每个 TaskManager 能够分配的 Slot 数量进行配置,
默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓
Slot 就是 TaskManager 中具体运行一个任务所分配的计算资源。
parallelism.default:Flink 任务执行的默认并行度,优先级低于代码中进行的并行度配
置和任务提交时使用参数指定的并行度数量。
- 分发安装目录
配置修改完毕后,将 Flink 安装目录发给另外两个节点服务器。
$ scp -r ./flink-1.13.0 atguigu@hadoop103:/opt/module
$ scp -r ./flink-1.13.0 atguigu@hadoop104:/opt/module
-
启动集群
在 hadoop102 节点服务器上执行 start-cluster.sh 启动 Flink 集群:
bin/start-cluster.sh使用jps查看进程启动情况 -
访问 Web UI
启动成功后,同样可以访问 http://hadoop102:8081 对 flink 集群和任务进行监控管理,如图
所示。
这里可以明显看到,当前集群的 TaskManager 数量为 2;由于默认每个 TaskManager 的 Slot
数量为 1,所以总 Slot 数和可用 Slot 数都为 2。
-
关闭集群
如果想要让 Flink 集群停止运行,可以执行以下命令:bin/stop-cluster.sh
3.1.4 向集群提交作业和取消作业
- 程序打包
(1)为方便自定义结构和定制依赖,我们可以引入插件 maven-assembly-plugin 进行打包。在 Flink项目的 pom.xml 文件中添加打包插件的配置,具体如下:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
(2)插件配置完毕后,可以使用 IDEA 的 Maven 工具执行 package 命令,出现如下提示即
表示打包成功。
打 包 完 成 后 , 在 target 目 录 下 即 可 找 到 所 需 JAR 包 , JAR 包 会 有 两 个 ,
FlinkTutorial-1.0-SNAPSHOT.jar 和 FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar,因
为集群中已经具备任务运行所需的所有依赖,所以建议使用 Flink-1.0-SNAPSHOT.jar
-
在 Web UI 上提交作业
(1)任务打包完成后,我们打开 Flink 的 WEB UI 页面,在右侧导航栏点击“Submit New
Job”,然后点击按钮“+ Add New”,选择要上传运行的 JAR 包.
(2)点击该 JAR 包,出现任务配置页面,进行相应配置。主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。

(3)任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况
启动报错了, 在jobManager中查看任务运行日志, 看到是没有启动nc,导致socket连接失败,启动nc后重新执行
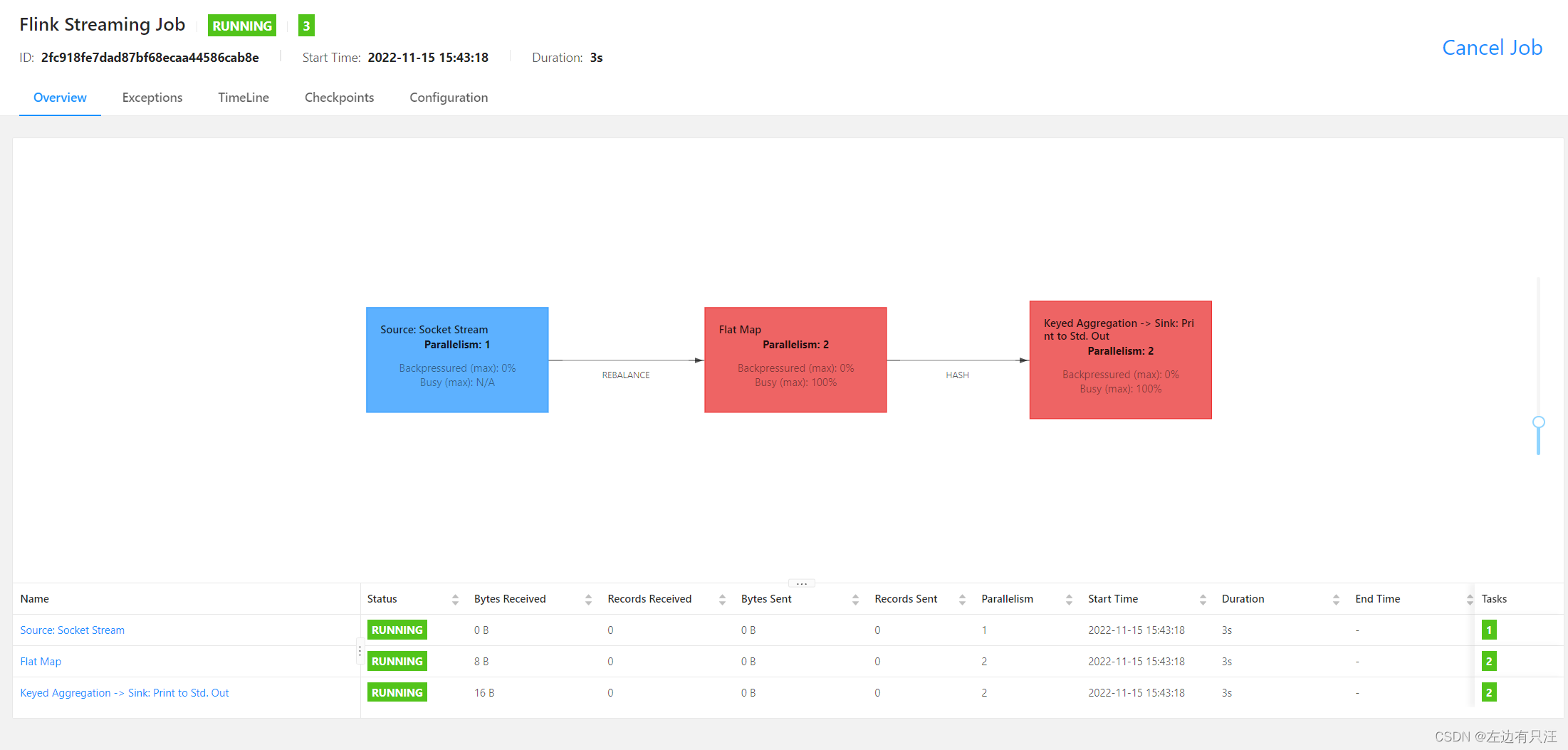
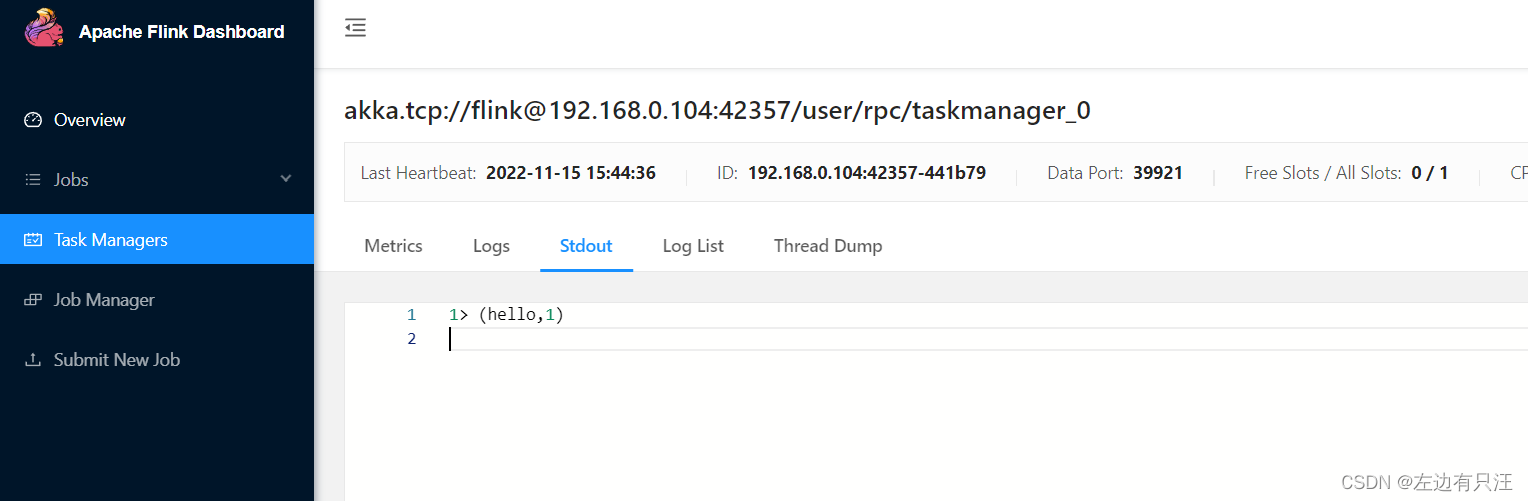

在taskManager的控制台, 可以看到输出结果, 我们有两个taskManager并且任务的并行度是2, 所以这两个会同时输出.
(4)点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任
务运行 -
使用命令行提交作业
除了通过 WEB UI 界面提交任务之外,也可以直接通过命令行来提交任务。这里为方便
起见,我们可以先把 jar 包直接上传到目录 flink-1.13.0 下. 先把控制台执行的task停止
再进入到 Flink 的安装路径下,在命令行使用 flink run 命令提交作业.
./bin/flink run -m TEST-BIGDATA-05:8081 -c com.yangjunyi.flink.StreamWordCount -p 2 ./flink-1.0-SNAPSHOT.jar --hostname 192.168.0.105 --port 7777
在命令行中ctrl+c退出后, 对正在运行的task没有影响
这里的参数 –m 指定了提交到的 JobManager,-c 指定了入口类, 如果想指定运行时参数, 在jar包后面添加相应的即可, 再去flink-ui中也可以看到用命令行提交应用的执行情况.
运行后, 当前的task slot变成了0

如果slot为0时,再次提交任务, 则提交时会直接报错Could not acquire the minimum required resources获取不到最小运行需要的资源
在命令行中取消正在执行的任务
./bin/flink cancel jobId jobId是命令行提交后输出的值

3.2 部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink 为各种场景提供了不同的部署模式,主要有以下三种:
- 会话模式(Session Mode)
- 单作业模式(Per-Job Mode)
- 应用模式(Application Mode)
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的 main 方法到底在哪里执行是客户端(Client)还是 JobManager。接下来我们就做一个展开说明。
3.2.1 会话模式(Session Mode)
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业,如图 所示。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
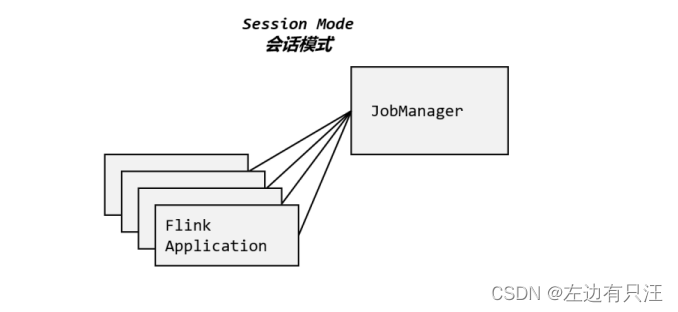
这样的好处很明显,我们只需要一个集群,就像一个大箱子,所有的作业提交之后都塞进去;集群的生命周期是超越于作业之上的,铁打的营盘流水的兵,作业结束了就释放资源,集群依然正常运行。当然缺点也是显而易见的:因为资源是共享的,所以资源不够了,提交新的作业就会失败。另外,同一个 TaskManager 上可能运行了很多作业,如果其中一个发生故障导致 TaskManager 宕机,那么所有作业都会受到影响。之前先启动集群再提交作业, 这种方式就是会话模式. 会话模式比较适合于单个规模小, 执行时间短的大量作业
3.2.2 单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个
提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式,
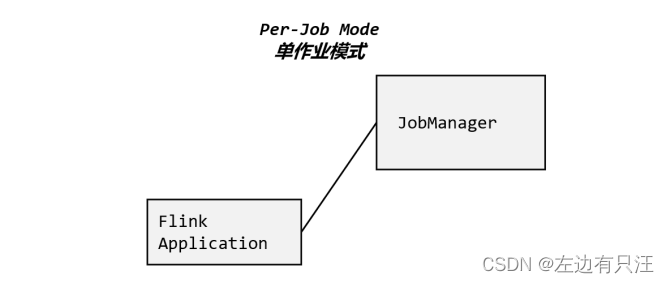
单作业模式也很好理解,就是严格的一对一,集群只为这个作业而生。同样由客户端运行应用程序,然后启动集群,作业被提交给 JobManager,进而分发给 TaskManager 执行。作业作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的 JobManager管理,占用独享的资源,即使发生故障,它的 TaskManager 宕机也不会影响其他作业。
这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
需要注意的是,Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如 YARN、Kubernetes。
3.3.3 应用模式(Application Mode)
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给 JobManager的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到 JobManger 上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了,这就是所谓的应用模式,
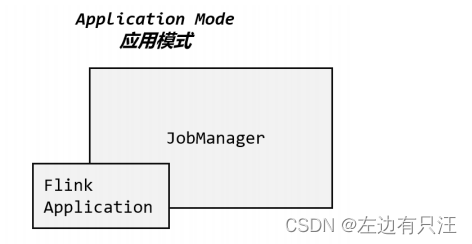
应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应用程序的,并且即使应用包含了多个作业,也只创建一个集群。
总结一下,在会话模式下,集群的生命周期独立于集群上运行的任何作业的生命周期,并且提交的所有作业共享资源。而单作业模式为每个提交的作业创建一个集群,带来了更好的资源隔离,这时集群的生命周期与作业的生命周期绑定。最后,应用模式为每个应用程序创建一个会话集群,在 JobManager 上直接调用应用程序的 main()方法。
我们所讲到的部署模式,相对是比较抽象的概念。实际应用时,一般需要和资源管理平台结合起来,选择特定的模式来分配资源、部署应用。接下来,我们就针对不同的资源提供者(Resource Provider)的场景,具体介绍 Flink 的部署方式。
3.3 独立模式部署
独立模式部署使用的很少, 不再赘述了.
3.4 YARN模式部署
独立(Standalone)模式由 Flink 自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但我们知道,Flink 是大数据计算框架,不是资源调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架集成更靠谱。而在目前大数据生态中,国内应用最为广泛的资源管理平台就是 YARN 了。所以接下来我们就将学习,在强大的 YARN 平台上 Flink 是如何集成部署的。
整体来说,YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager, Yarn 的ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业所需要的 Slot 数量动态分配 TaskManager 资源。
3.4.1 相关准备和配置
在 Flink1.8.0 之前的版本,想要以 YARN 模式部署 Flink 任务时,需要 Flink 是有 Hadoop支持的。从 Flink 1.8 版本开始,不再提供基于 Hadoop 编译的安装包,若需要 Hadoop 的环境支持,需要自行在官网下载 Hadoop 相关版本的组件 flink-shaded-hadoop-2-uber-2.7.5-10.0.jar,并将该组件上传至 Flink 的 lib 目录下。在 Flink 1.11.0 版本之后,增加了很多重要新特性,其中就包括增加了对Hadoop3.0.0以及更高版本Hadoop的支持,不再提供“flink-shaded-hadoop-*”jar 包,而是通过配置环境变量完成与 YARN 集群的对接。
在将 Flink 任务部署至 YARN 集群之前,需要确认集群是否安装有 Hadoop,保证 Hadoop版本至少在 2.2 以上,并且集群中安装有 HDFS 服务。
具体配置步骤如下:
(1)按照 3.1 节所述,下载并解压安装包,并将解压后的安装包重命名为 flink-1.13.0-yarn,
本节的相关操作都将默认在此安装路径下执行。
(2)配置环境变量,增加环境变量配置如下:
vim /etc/profile.d/my_env.sh
HADOOP_HOME=/opt/module/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
这里必须保证设置了环境变量 HADOOP_CLASSPATH
(3)启动 Hadoop 集群,包括 HDFS 和 YARN。
start-dfs.sh
start-yarn.sh
分别在 3 台节点服务器查看进程启动情况。
(4)进入 flink的conf 目录,修改 flink-conf.yaml 文件,修改以下配置,这些配置项的含义在进
行 Standalone 模式配置的时候进行过讲解,若在提交命令中不特定指明,这些配置将作为默认
配置。
cd /opt/module/flink-1.13.0-yarn/conf/
$ vim flink-conf.yaml
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 8
parallelism.default: 1

3.4.2 会话模式部署(常用)
YARN 的会话模式与独立集群略有不同,需要首先申请一个 YARN 会话(YARN session)来启动 Flink 集群。具体步骤如下:
- 启动集群
(1)启动 hadoop 集群(HDFS, YARN)。
(2)执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群。bin/yarn-session.sh -nm test -d
可用参数解读:
-d:分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session 也可以后台运行。
-jm(–jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。
-nm(–name):配置在 YARN UI 界面上显示的任务名。
-qu(–queue):指定 YARN 队列名。
-tm(–taskManager):配置每个 TaskManager 所使用内存。
注意:Flink1.11.0 版本不再使用-n 参数和-s 参数分别指定 TaskManager 数量和 slot 数量,
YARN 会按照需求动态分配 TaskManager 和 slot。所以从这个意义上讲,YARN 的会话模式也
不会把集群资源固定,同样是动态分配的。
YARN Session 启动之后会给出一个 web UI 地址以及一个 YARN application ID,如下所示,
用户可以通过 web UI 或者命令行两种方式提交作业。

- 提交作业
(1)通过 Web UI 提交作业 这种方式比较简单,与上文所述 Standalone 部署模式基本相同。
(2)通过命令行提交作业, 将 Standalone 模式讲解中打包好的任务运行 JAR 包上传至集群,执行以下命令将该任务提交到已经开启的 Yarn-Session 中运行。bin/flink run -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
客户端可以自行确定 JobManager 的地址,也可以通过-m 或者-jobmanager 参数指定
JobManager 的地址,JobManager 的地址在 YARN Session 的启动页面中可以找到。
任务提交成功后,可在 YARN 的 Web UI 界面查看运行情况。
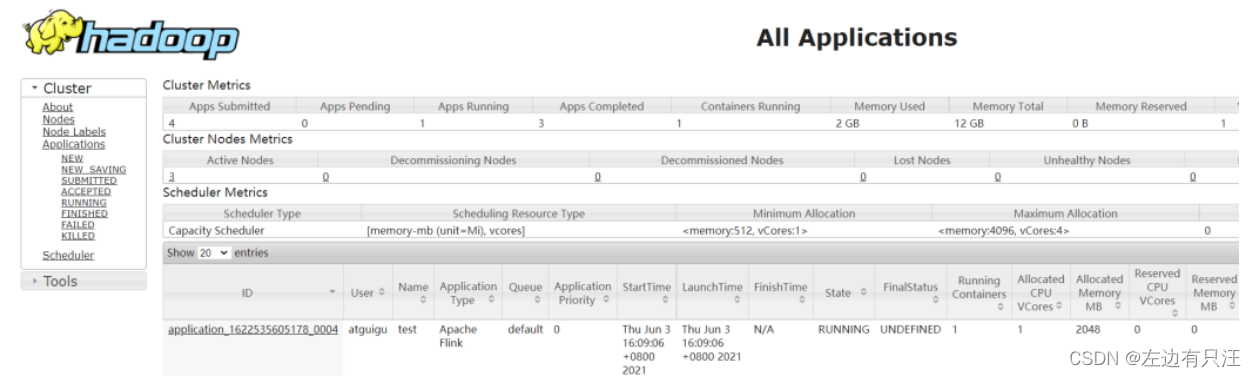
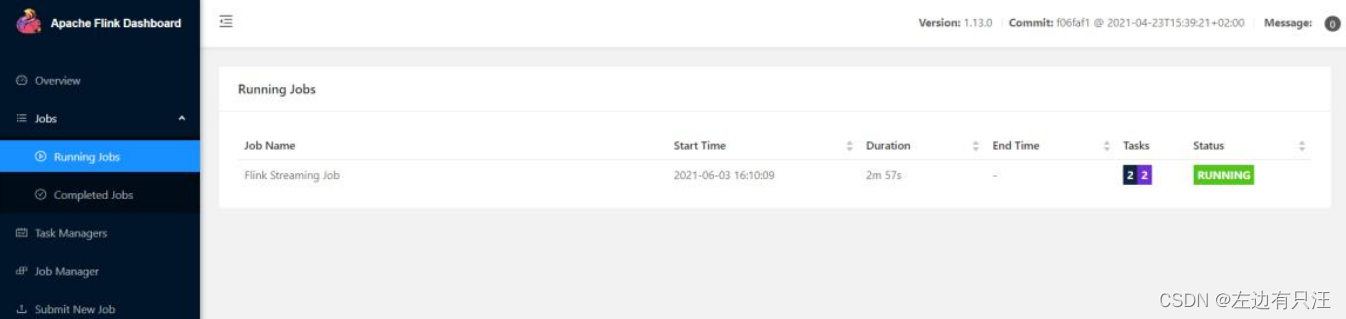
从图中可以看到我们创建的 Yarn-Session 实际上是一个 Yarn 的Application,并且有唯一的 Application ID。也可以通过 Flink 的 Web UI 页面查看提交任务的运行情况
3.4.3 单作业模式部署
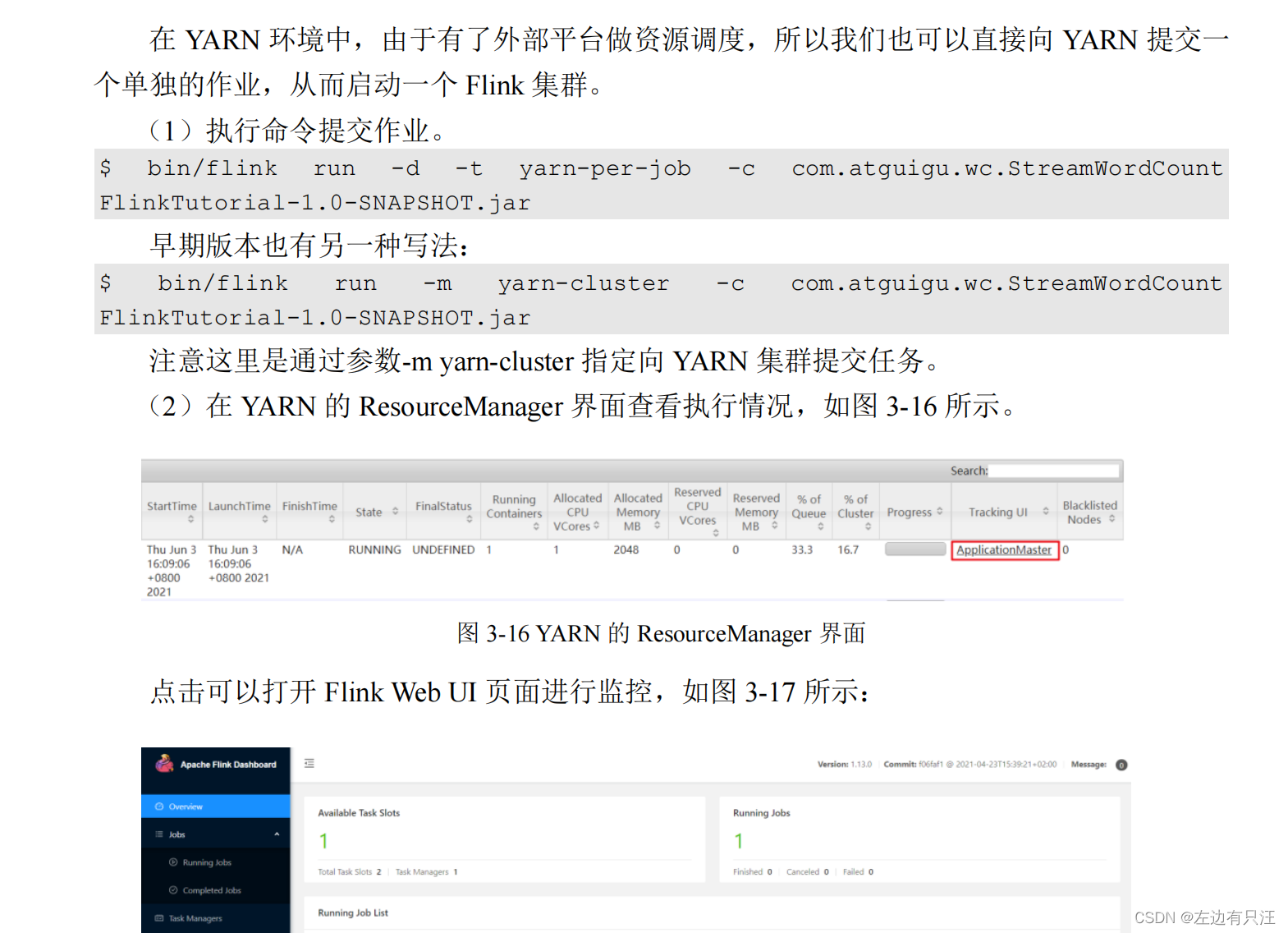

这里的 application_XXXX_YY 是当前应用的 ID,是作业的 ID。注意如果取消作业,整个 Flink 集群也会停掉。
3.4.4 应用模式部署

3.4.5 高可用
YARN 模式的高可用和独立模式(Standalone)的高可用原理不一样。
Standalone 模式中, 同时启动多个 JobManager, 一个为“领导者”(leader),其他为“后备”(standby), 当 leader 挂了, 其他的才会有一个成为 leader。
而 YARN 的高可用是只启动一个 Jobmanager, 当这个 Jobmanager 挂了之后, YARN 会再次启动一个, 所以其实是利用的 YARN 的重试次数来实现的高可用。
(1)在 yarn-site.xml 中配置。
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
注意: 配置完不要忘记分发, 和重启 YARN。
(2)在 flink-conf.yaml 中配置。
yarn.application-attempts: 3
high-availability: zookeeper
high-availability.storageDir: hdfs://hadoop102:9820/flink/yarn/ha
high-availability.zookeeper.quorum:
hadoop102:2181,hadoop103:2181,hadoop104:2181
high-availability.zookeeper.path.root: /flink-yarn
(3)启动 yarn-session。
(4)杀死 JobManager, 查看复活情况。
注意: yarn-site.xml 中配置的是 JobManager 重启次数的上限, flink-conf.xml 中的次数应该小于这个值。
4. Flink运行时架构
4.1 Flink系统架构
4.1.1 整体构成

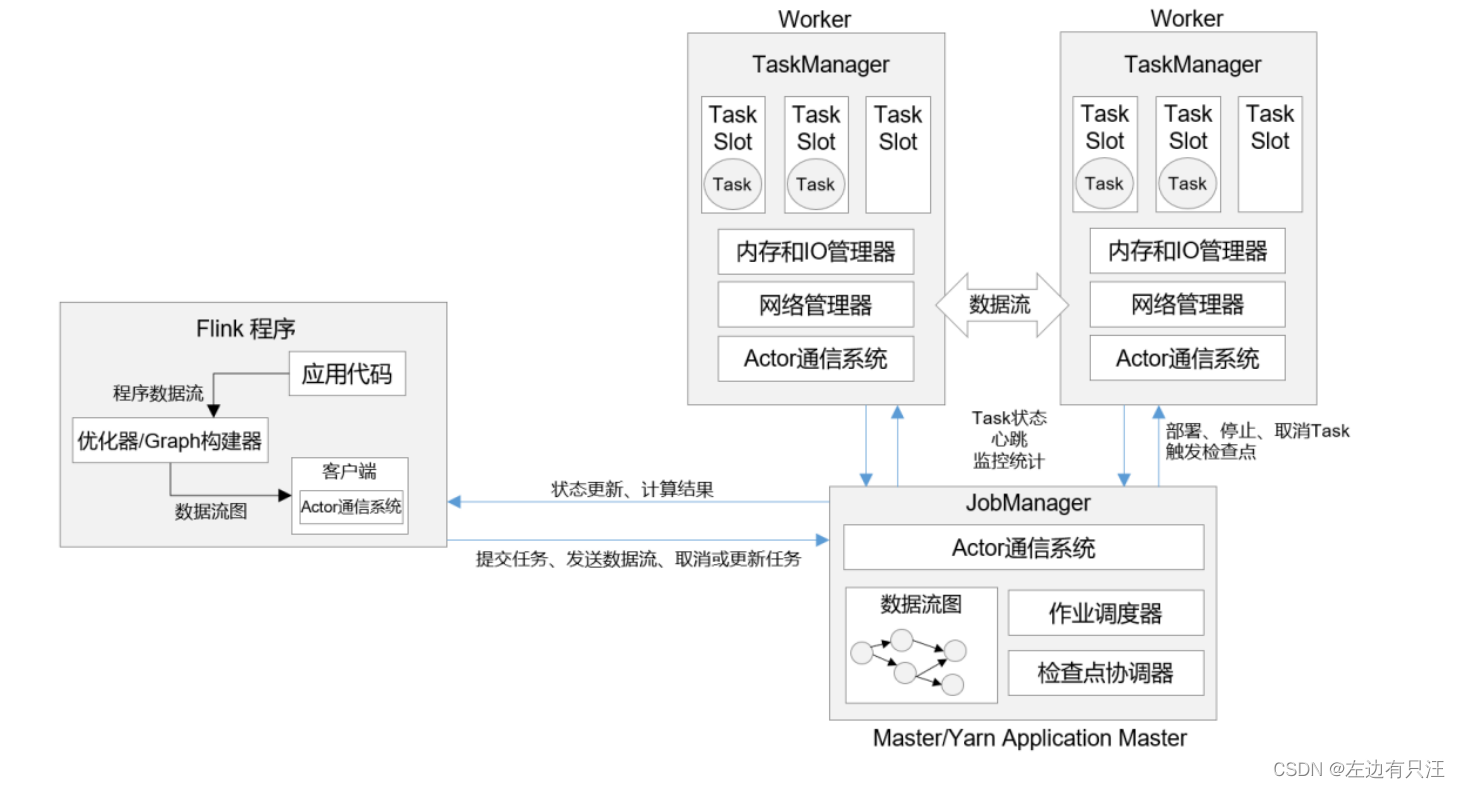

4.1.2 作业管理器JobManager




4.1.3 任务管理器TaskManager

4.2 Flink作业提交流程
4.2.1 高层级抽象视角
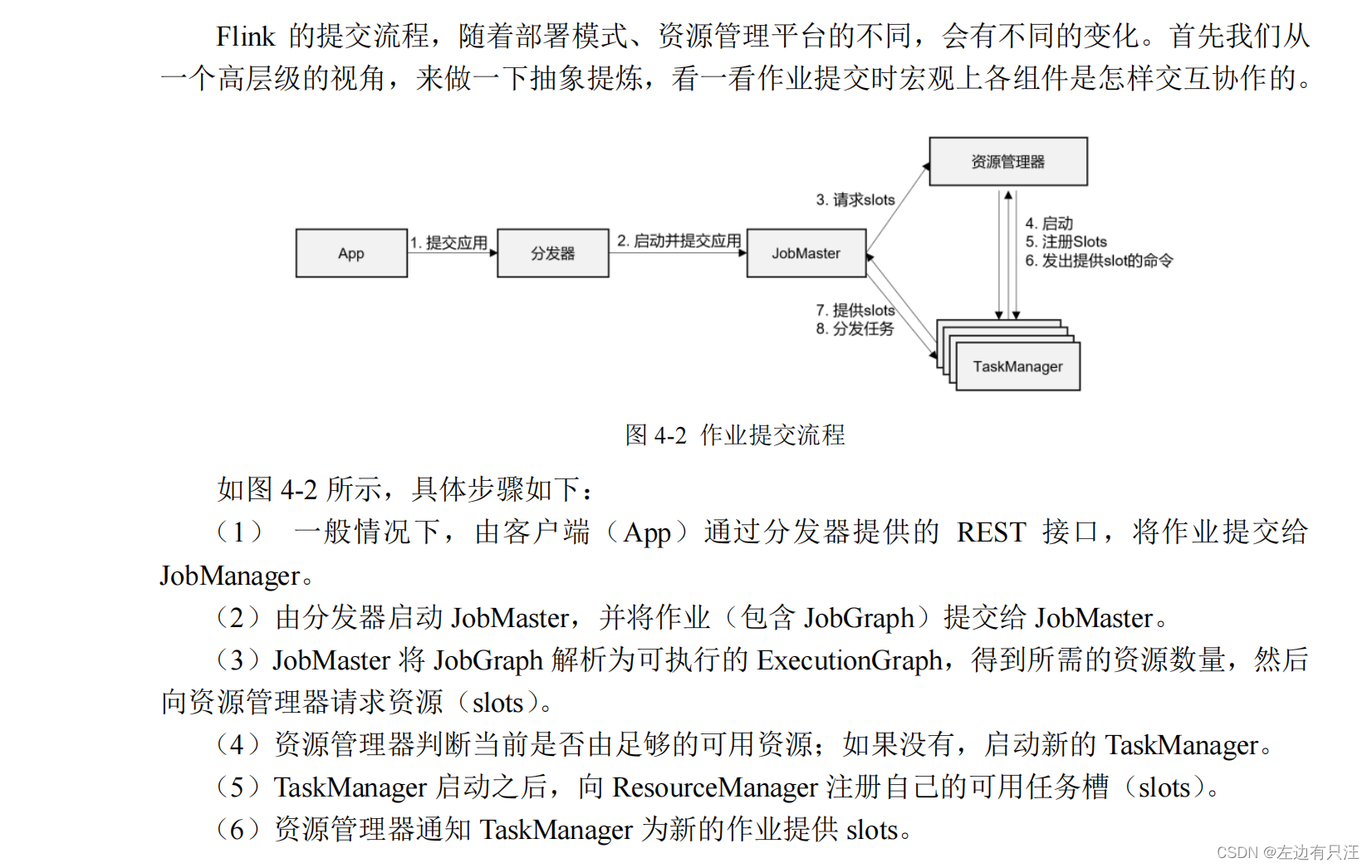

4.2.2 独立模式(Standalone)
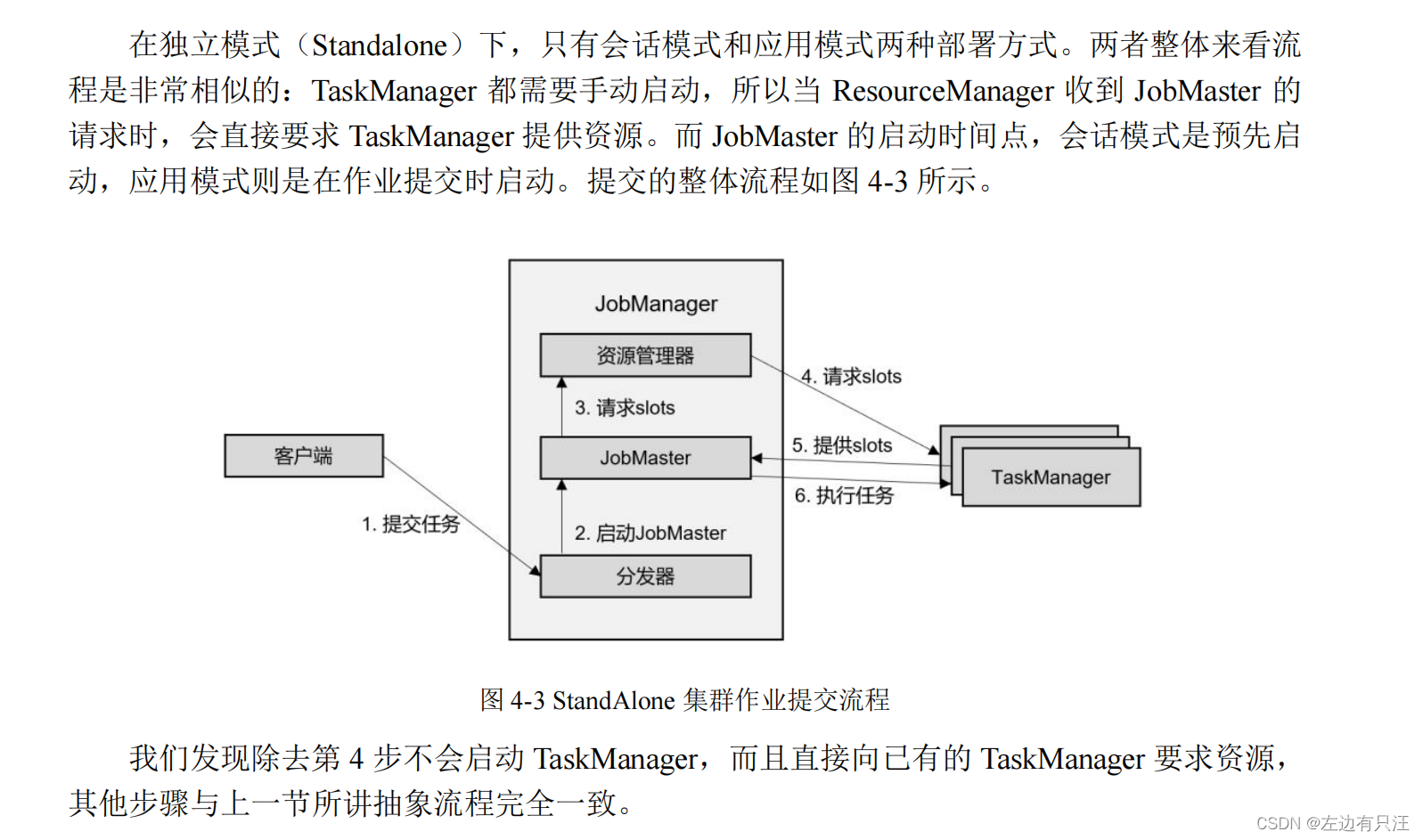
4.2.3 YARN 集群

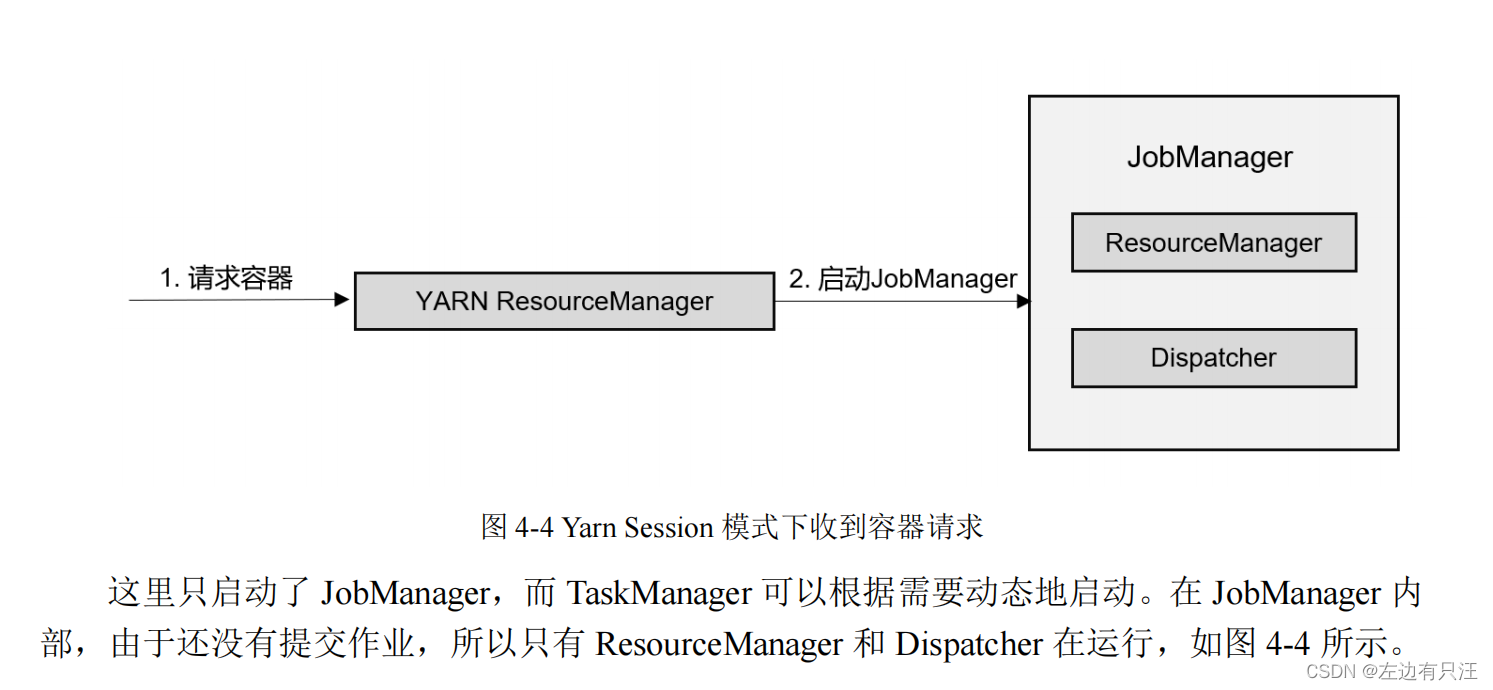
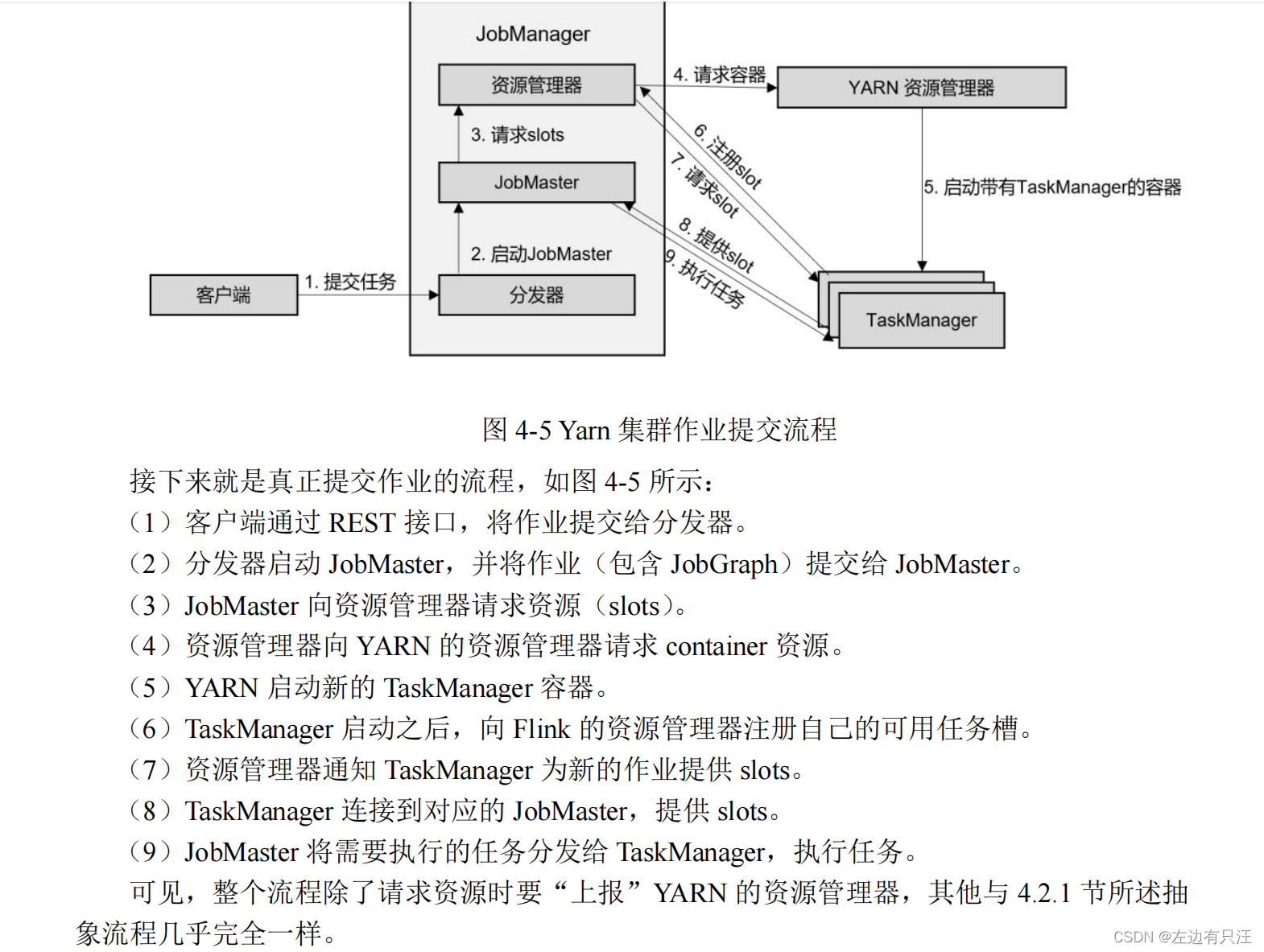

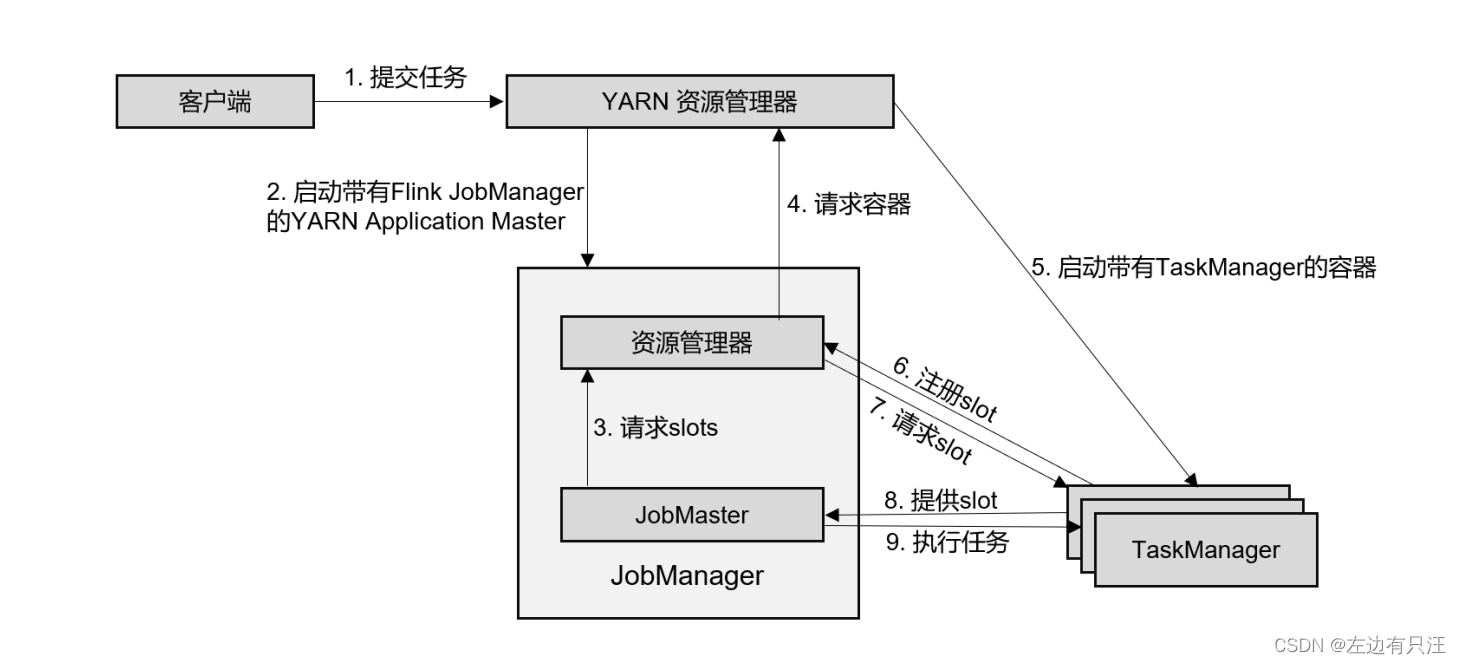


4.3 一些重要概念
4.3.1 数据流图(DataFlow Graph)




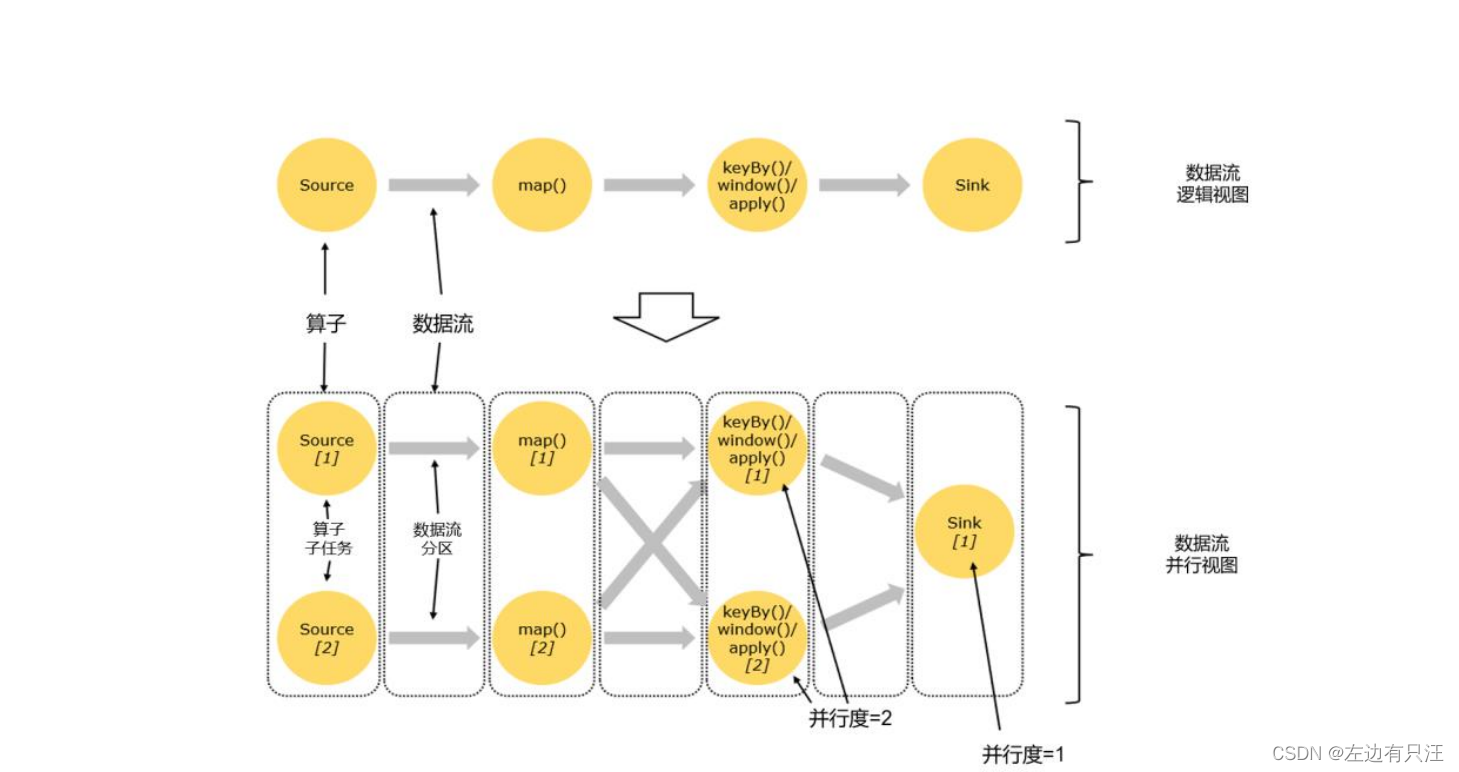
4.3.2 并行度(Parallelism)


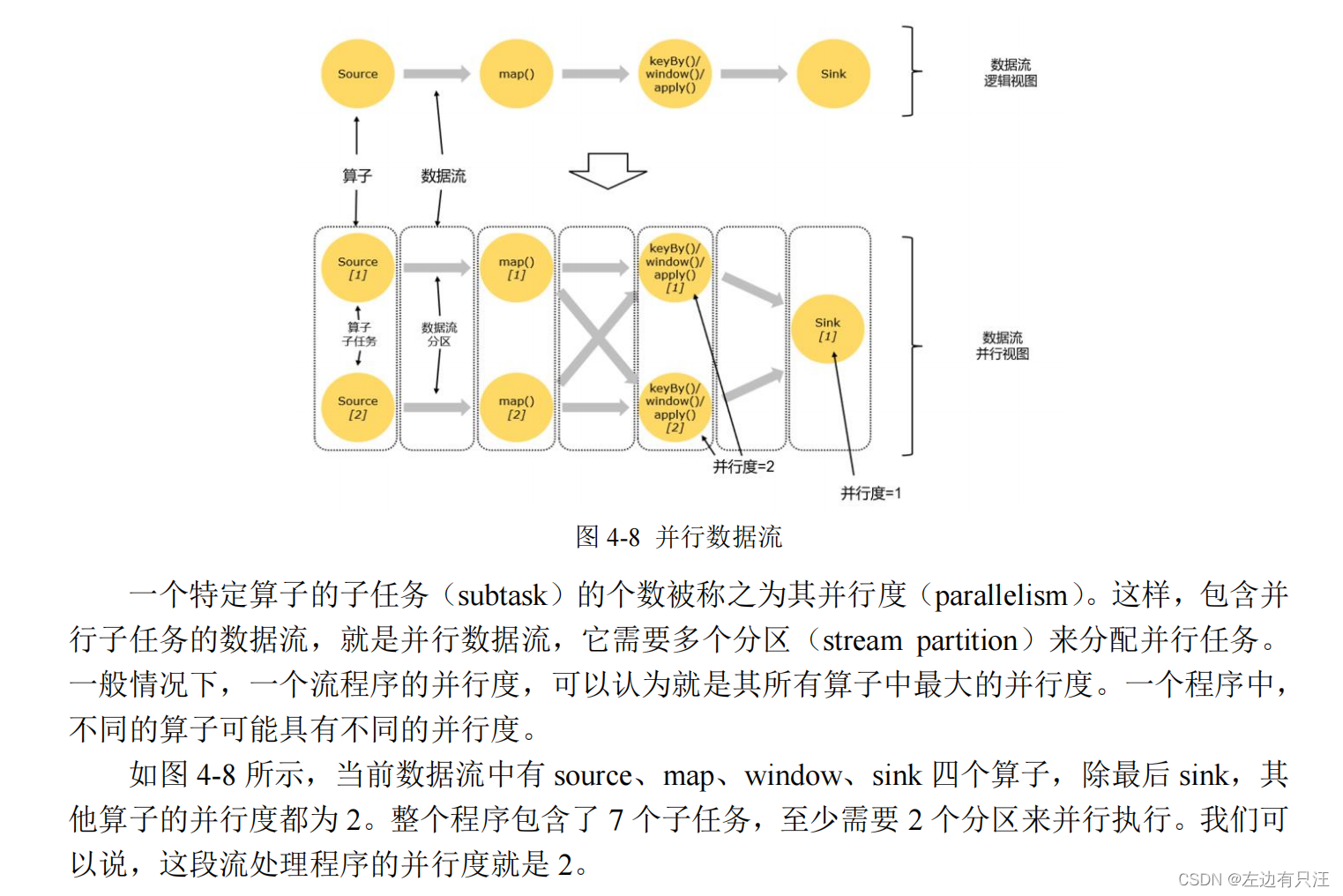

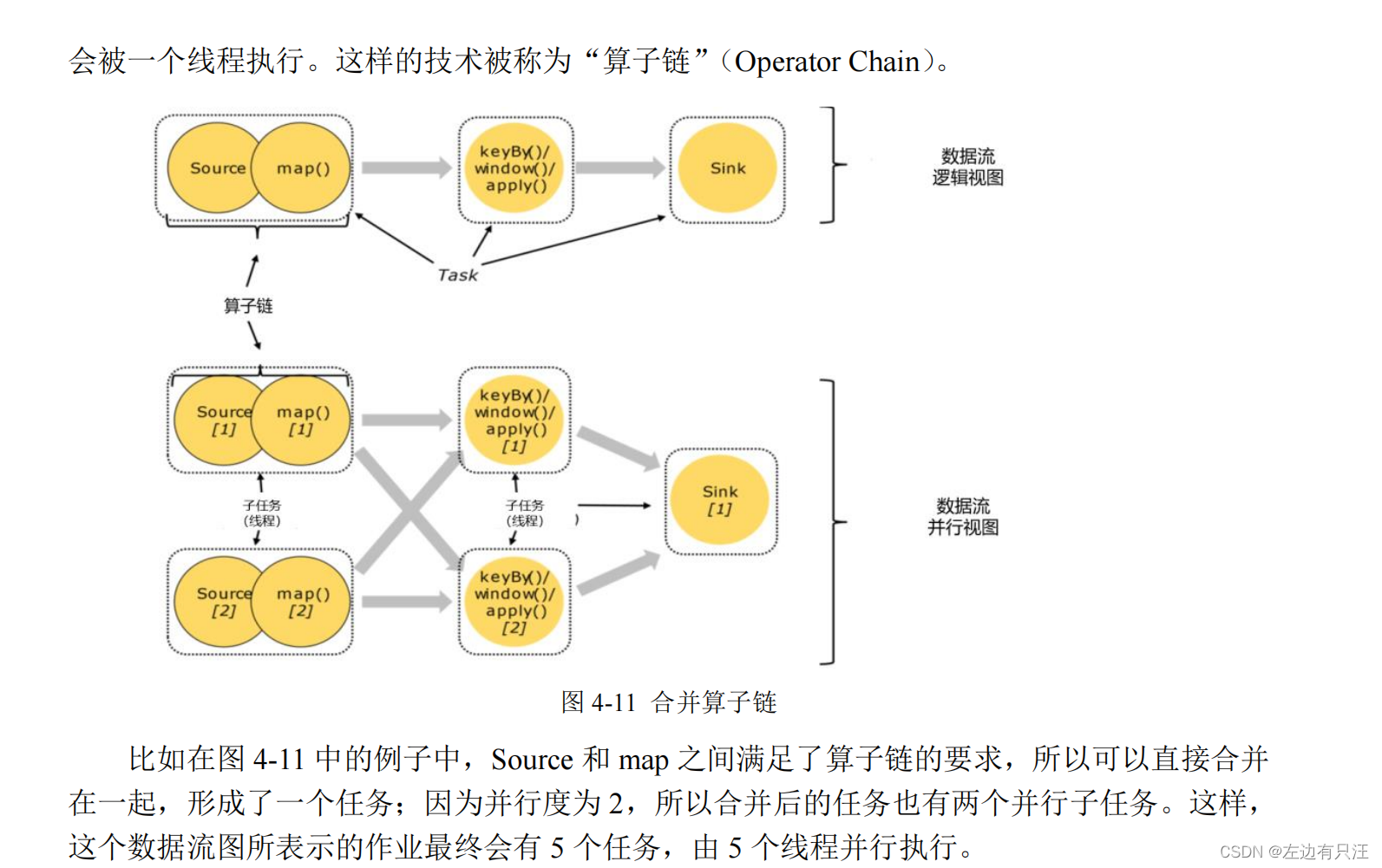
4.3.3 算子链(Operator Chain)
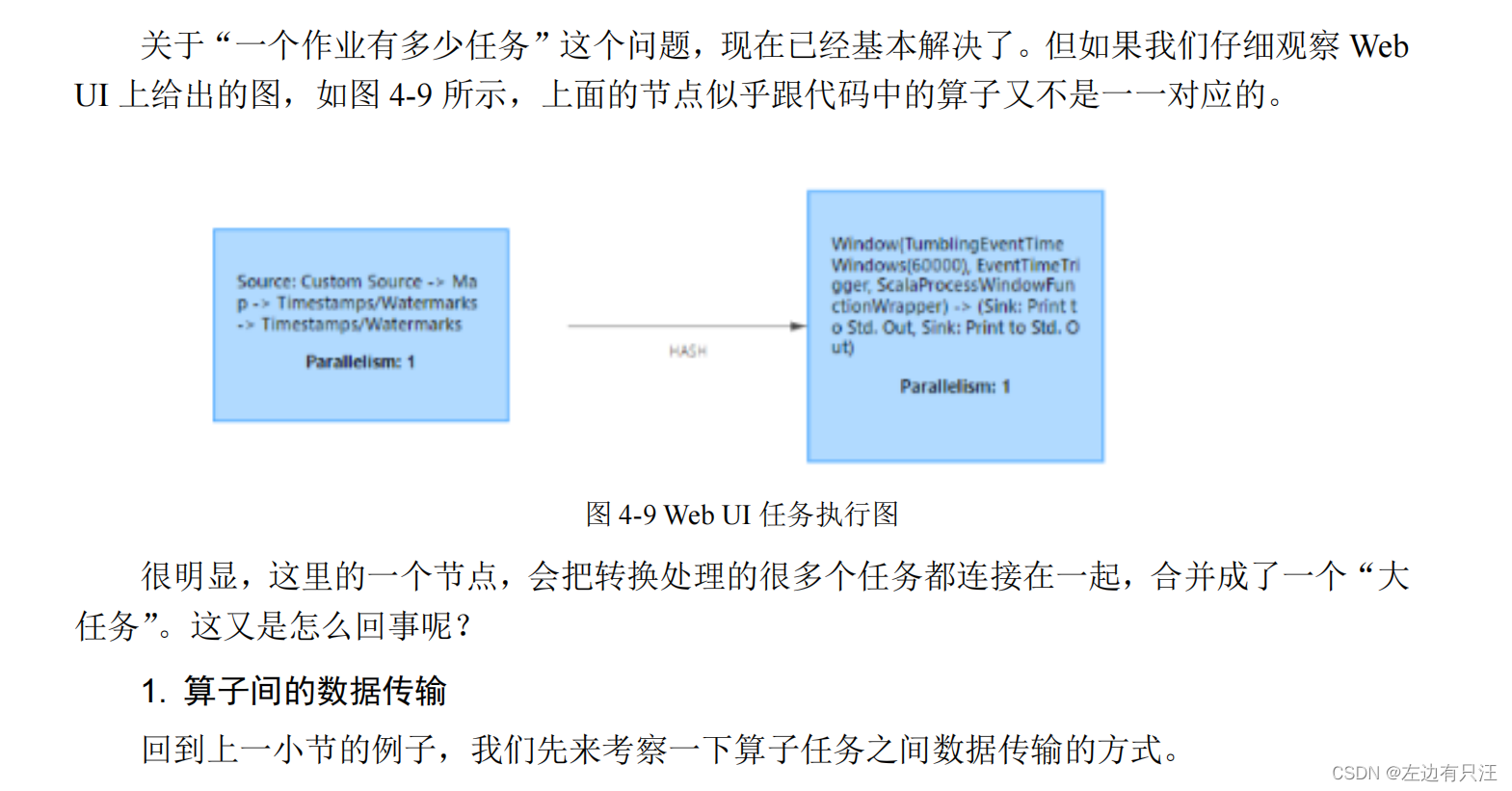



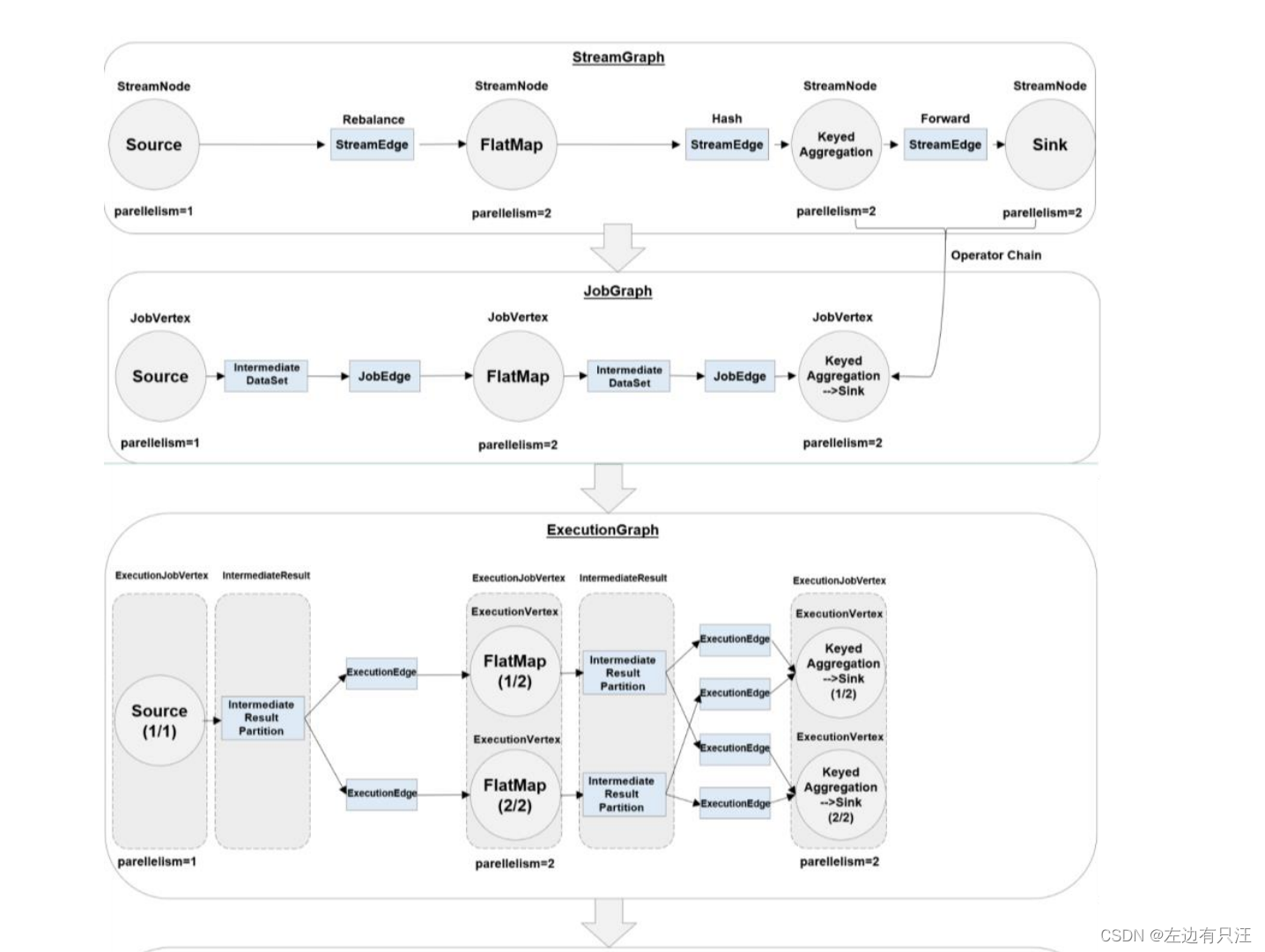
4.3.4 作业图(JobGraph)和执行图(ExecutionGraph)


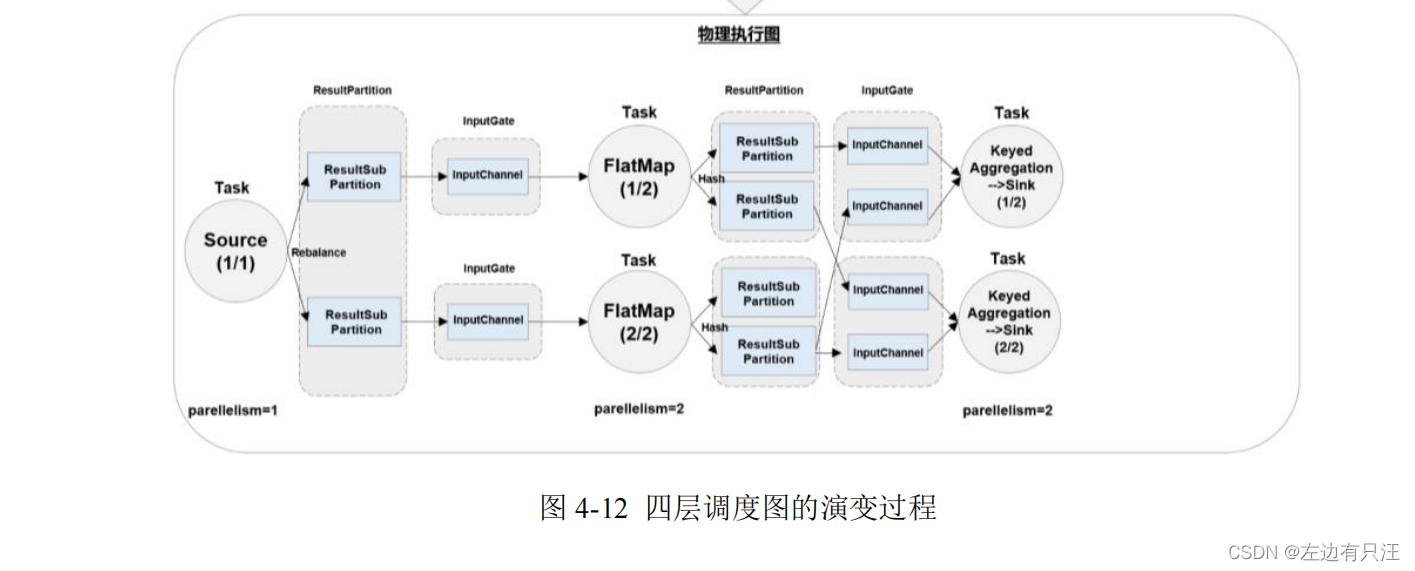


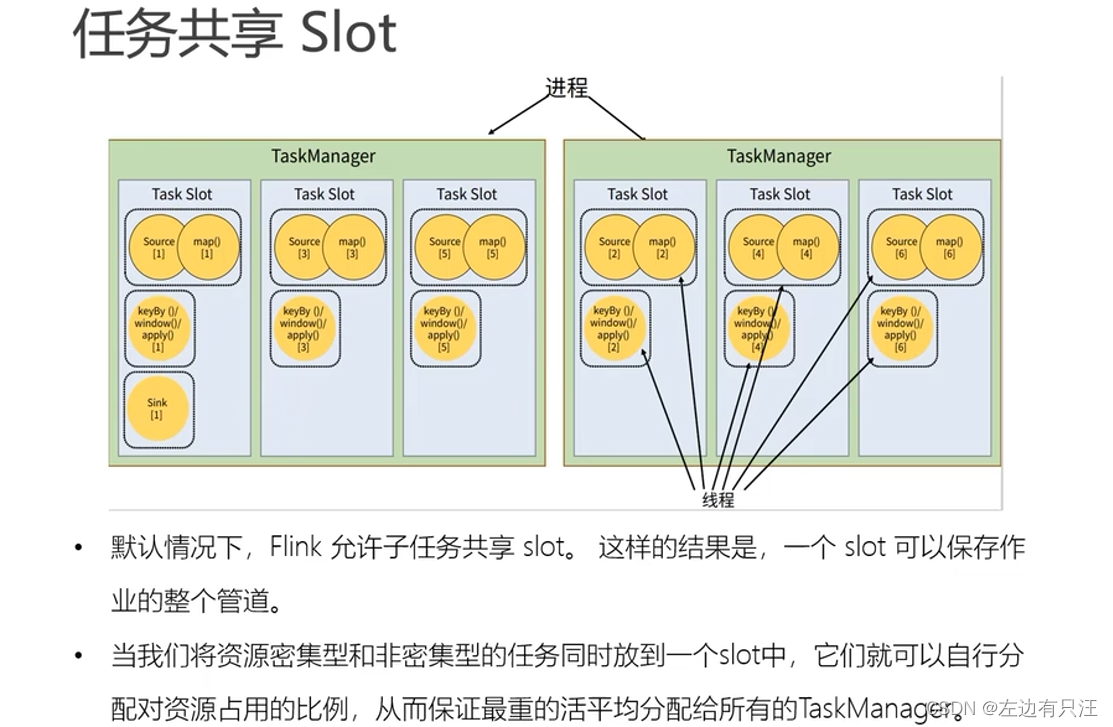
4.3.5 任务(Task)和任务槽(Task Slots)


5. DataStreamAPI(基础篇)
5.1 执行环境(Execution Environment)
5.1.1 创建执行环境
-
getExecutionEnvironment
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了 jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
这种“智能”的方式不需要我们额外做判断,用起来简单高效,是最常用的一种创建执行环境的方式. -
createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果
不传入,则默认并行度就是本地的 CPU 核心数
StreamExecutionEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment(); -
createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定
要在集群中运行的 Jar 包。
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment
.createRemoteEnvironment(
"host", // JobManager 主机名
1234, // JobManager 进程端口号
"path/to/jarFile.jar" // 提交给 JobManager 的 JAR 包
);
在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程
序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。关于时间语义和容错
机制,我们会在后续的章节介绍。
5.1.2 执行模式(Execution Mode)
上节中我们获取到的执行环境,是一个 StreamExecutionEnvironment,顾名思义它应该是做流处理的。那对于批处理,又应该怎么获取执行环境呢?
在之前的 Flink 版本中,批处理的执行环境与流处理类似,是调用类 ExecutionEnvironment的静态方法,返回它的对象:
// 批处理环境
ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();
// 流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
基于 ExecutionEnvironment 读入数据创建的数据集合,就是 DataSet;对应的调用的一整套转换方法,就是 DataSet API。这些我们在第二章的批处理 word count 程序中已经有了基本了解。
而从 1.12.0 版本起,Flink 实现了 API 上的流批统一。DataStream API 新增了一个重要特性:可以支持不同的“执行模式”(execution mode),通过简单的设置就可以让一段 Flink 程序在流处理和批处理之间切换。这样一来,DataSet API 也就没有存在的必要了。

- BATCH 模式的配置方法
由于 Flink 程序默认是 STREAMING 模式,我们这里重点介绍一下 BATCH 模式的配置。
主要有两种方式:
(1)通过命令行配置bin/flink run -Dexecution.runtime-mode=BATCH ...在提交作业时,增加 execution.runtime-mode 参数,指定值为 BATCH。
(2)通过代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
在代码中,直接基于执行环境调用 setRuntimeMode 方法,传入 BATCH 模式。
建议: 不要在代码中配置,而是使用命令行。这同设置并行度是类似的:在提交作业时指定参数可以更加灵活,同一段应用程序写好之后,既可以用于批处理也可以用于流处理。而在代码中硬编码(hard code)的方式可扩展性比较差,一般都不推荐。
- 什么时候选择 BATCH 模式

5.1.3 触发程序执行

5.2 源算子
5.2.1 准备工作
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
@Data
// 链式赋值
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
public class Event {
private String user;
private String url;
private Long timestamp;
}

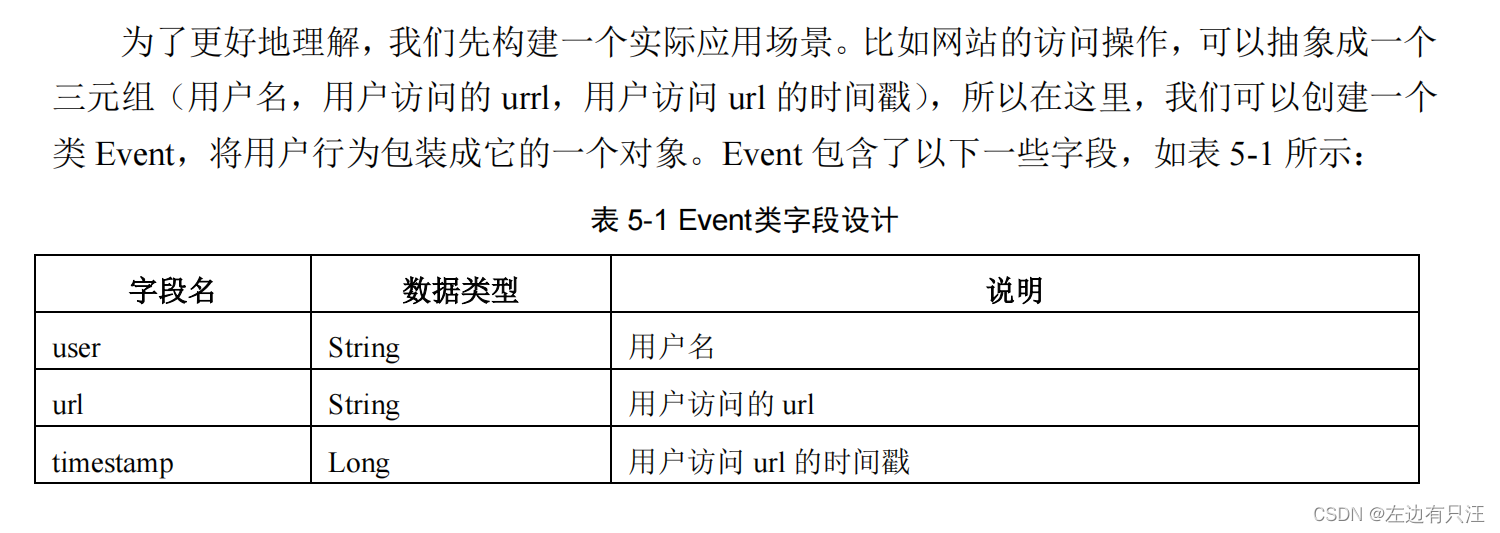
5.2.2 从集合/元素/文件中获取数据
最简单的读取数据的方式,就是在代码中直接创建一个 Java 集合,然后调用执行环境的fromCollection 方法进行读取。这相当于将数据临时存储到内存中,形成特殊的数据结构后,作为数据源使用,一般用于测试。
import com.yangjunyi.flink.entity.Event;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
import java.util.List;
public class SourceTest {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1. 从文件中读取数据
DataStreamSource<String> stream1 = env.readTextFile("input/clicks.txt");
// 2.从集合中读取数据
List<Integer> nums = new ArrayList<Integer>();
nums.add(2);
nums.add(5);
DataStreamSource<Integer> numStream = env.fromCollection(nums);
ArrayList<Event> events = new ArrayList<>();
events.add(new Event("Mary","./home",1000L));
events.add(new Event("Bob","./cart",2000L));
DataStreamSource<Event> stream2 = env.fromCollection(events);
// 3. 从元素读取数据
DataStreamSource<Event> elementStream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
stream1.print("stream1");
numStream.print("numStream");
stream2.print("stream2");
elementStream.print("elementStream");
env.execute();
}
}
如果要从hdfs中读取数据的话
5.2.3 从socket中读取数据

5.2.4 从Kafka读取数据
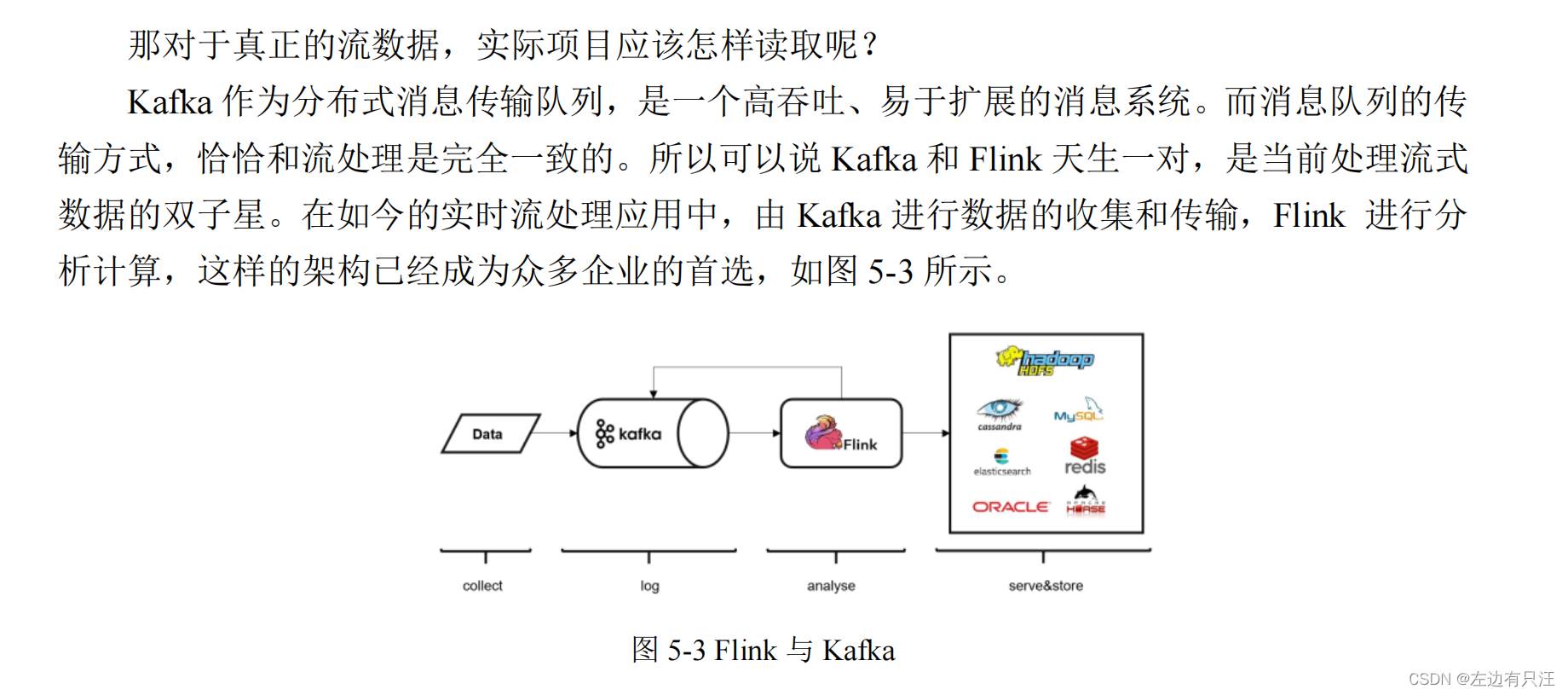

<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
// kafka连接节点
properties.setProperty("bootstrap.servers","192.168.0.75:9092");
// groupId
properties.setProperty("group.id","flinktest");
// 消费者key序列化
properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringSerializer");
// 消费者value序列化
properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringSerializer");
// 偏移量设置
properties.setProperty("auto.offset.reset","latest");
// 从kafka中读取数据 第一个参数:topic 第二个参数: value序列化模式, 第三个参数:kafka连接properties参数
DataStreamSource<String> kafkaStream = env.addSource(new FlinkKafkaConsumer<String>("X429Deplane", new SimpleStringSchema(), properties));
kafkaStream.print();
env.execute();
5.2.5 自定义Source

public class ClickSource implements SourceFunction<Event> {
// 声明一个标志位,在下面的run中不停的生成数据, 直到running为false. running什么时候才能置成false呢, 就是在调用cancel方法的时候
private boolean running = true;
@Override
public void run(SourceContext<Event> sourceContext) throws Exception {
// 随机生成数据
Random random = new Random();
// 定义字段选取数据范围
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
while (running) {
String user = users[random.nextInt(users.length)];
String url = urls[random.nextInt(users.length)];
Long timestamp = Calendar.getInstance().getTimeInMillis();
sourceContext.collect(new Event(user,url,timestamp));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
this.running = false;
}
}
link使用自定义source作为源算子
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> objectDataStreamSource = env.addSource(new ClickSource());
objectDataStreamSource.print();
env.execute();
}
这里要注意的是 SourceFunction 接口定义的数据源,并行度只能设置为 1,如果数据源设置为大于 1 的并行度,则会抛出异常。如果想要设置并行的数据源, 需要实现ParallelSourceFunction接口
public class ParallelCustomSource implements ParallelSourceFunction<Integer> {
private boolean running = true;
Random random = new Random();
@Override
public void run(SourceContext<Integer> sourceContext) throws Exception {
while(running) {
sourceContext.collect(random.nextInt());
Thread.sleep(1000);
}
}
@Override
public void cancel() {
this.running= false;
}
}
接下来再把并行度调高就可以了
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Integer> objectDataStreamSource = env.addSource(new ParallelCustomSource()).setParallelism(2);
objectDataStreamSource.print();
env.execute();
}
5.2.6 Flink支持的数据类型



再次强调一下Flink对POJO类的定义, 类必须是公共的(public)和独立的(没有非静态的内部类). 类必须有公共的无参构造方法, 类内部的字段是public且非final的, 或者有公共的getter和setter方法, 且满足Java命名规范



5.3 转换算子(Transformation)
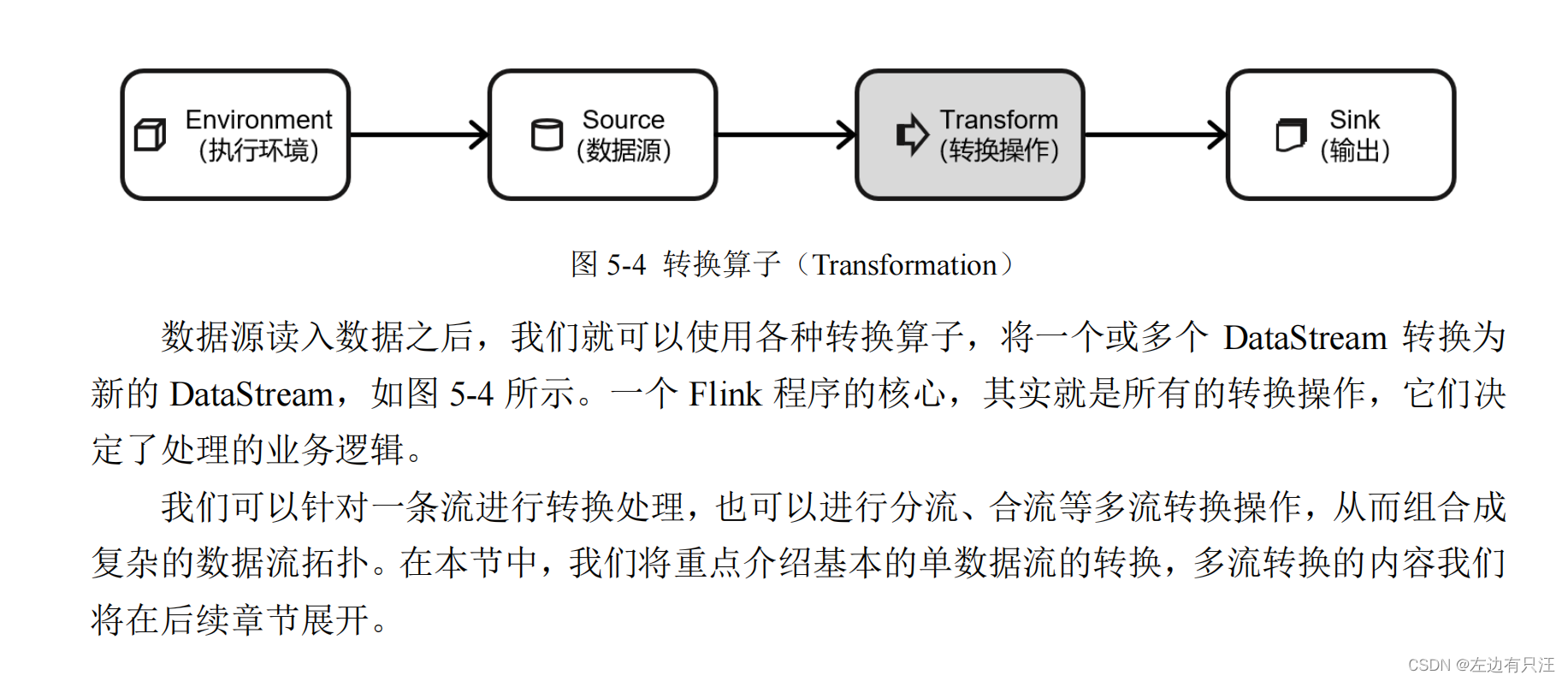
5.3.1 基本转换算子
在基本转换算子后, 如果lambda中使用了泛型, 需要在后面跟一个returns方法
- 映射(map)
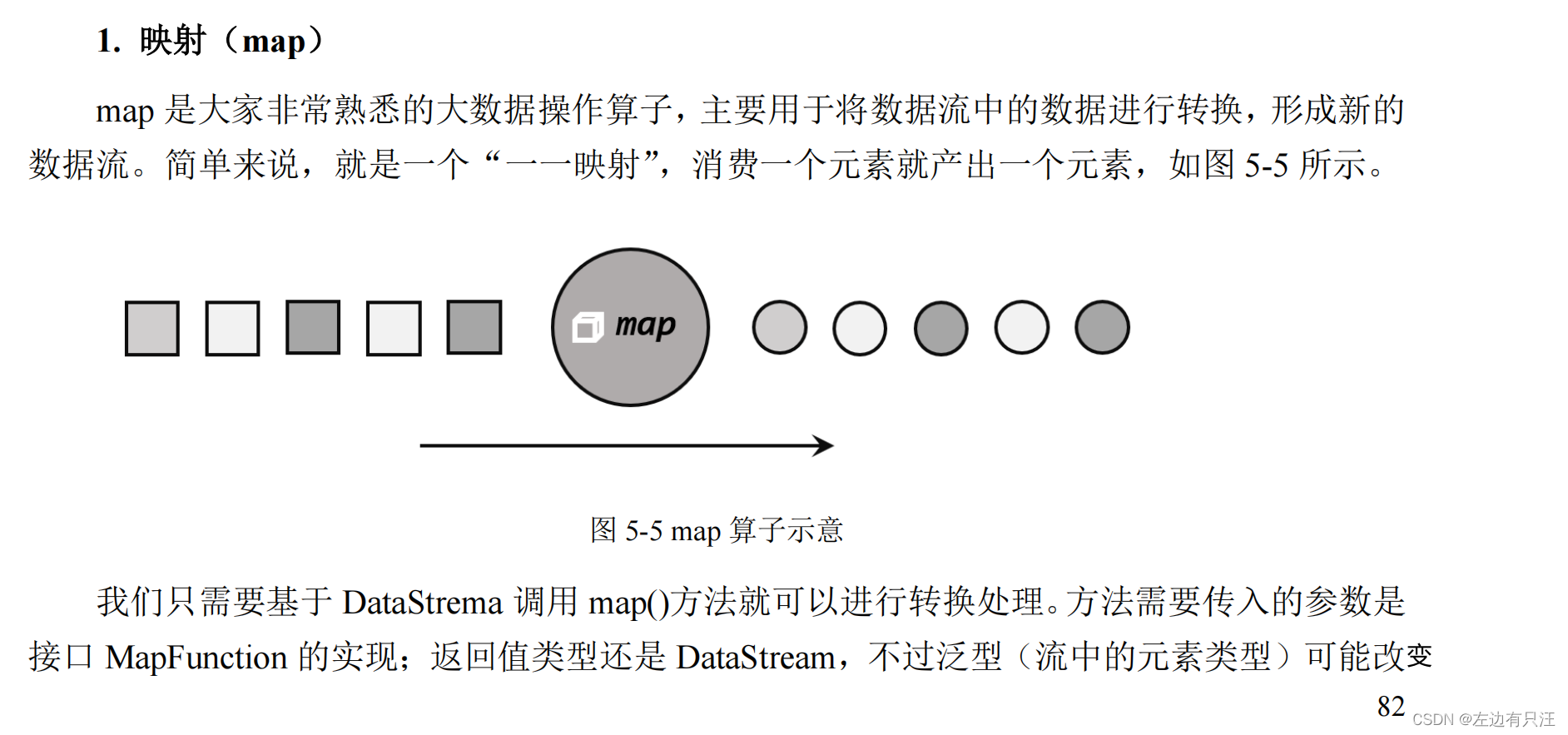
public class TransformMapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.addSource(new ClickSource());
// 进行map转换计算, 提取user字段
// 1.使用自定义类实现MapFunction接口
//SingleOutputStreamOperator<String> map = streamSource.map(new MyMapper());
// 2.使用匿名类实现MapFunction接口
/*SingleOutputStreamOperator<String> map = streamSource.map(new MapFunction<Event, String>() {
@Override
public String map(Event event) throws Exception {
return event.getUser();
}
});*/
// 3.使用lambda表达式
SingleOutputStreamOperator<String> map = streamSource.map(data -> data.getUser());
map.print();
env.execute();
}
// 自定义mapFunction
public static class MyMapper implements MapFunction<Event,String>{
@Override
public String map(Event event) throws Exception {
return event.getUser();
}
}
}
- 过滤(filter)
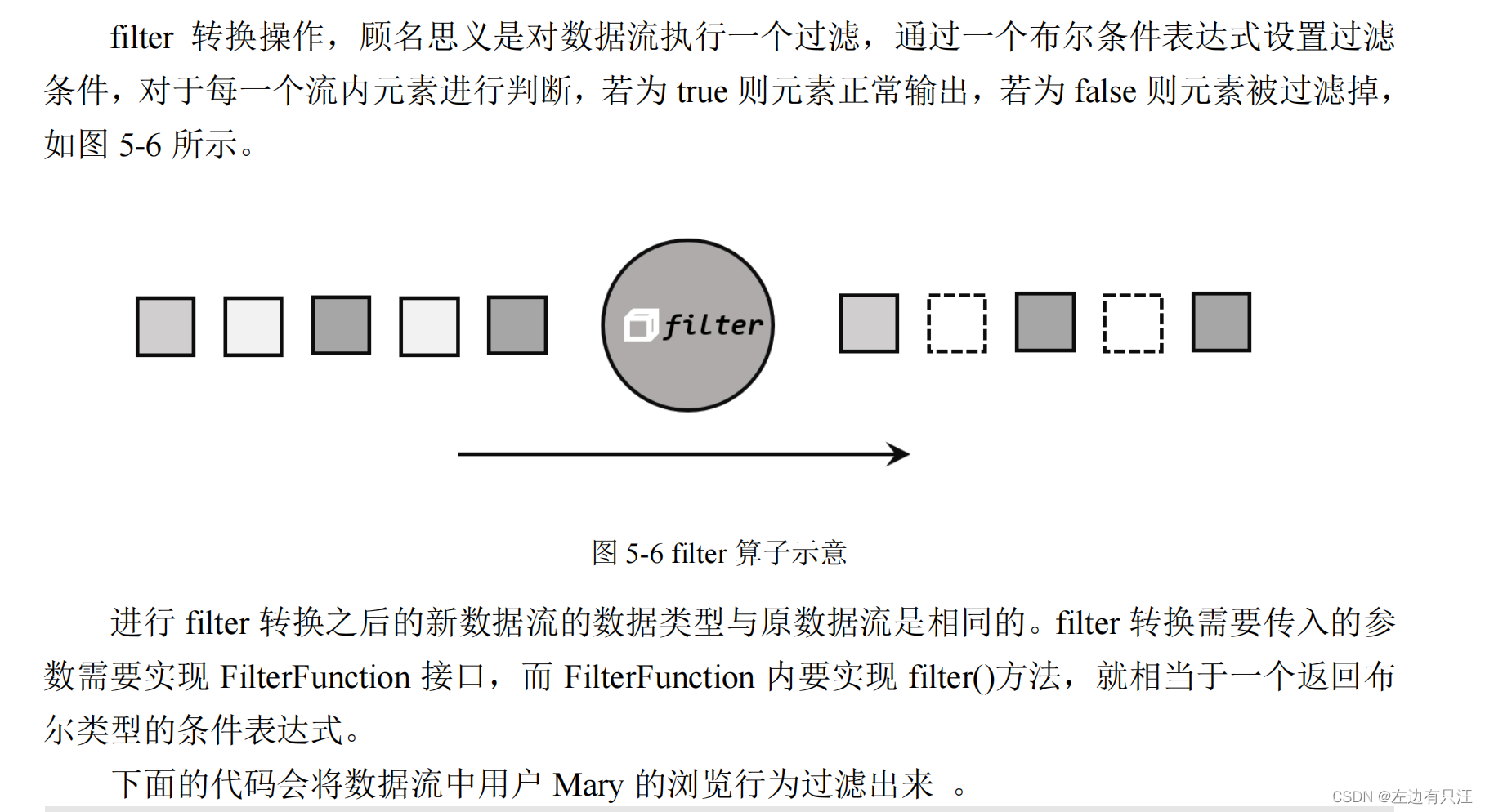
public class TransformFliterTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.addSource(new ClickSource());
// 1. 传入一个实现了filterFunction的自定义类对象
//SingleOutputStreamOperator<Event> filter = streamSource.filter(new MyFilter());
// 2. 传入一个匿名类
/*SingleOutputStreamOperator<Event> filter = streamSource.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event event) throws Exception {
return "Mary".equals(event.getUser());
}
});*/
// 3. 传入lambda表达式
SingleOutputStreamOperator<Event> filter = streamSource.filter(data -> "Mary".equals(data.getUser()));
filter.print();
env.execute();
}
public static class MyFilter implements FilterFunction<Event>{
@Override
public boolean filter(Event event) throws Exception {
return "Mary".equals(event.getUser());
}
}
}
- 扁平映射(flatMap)
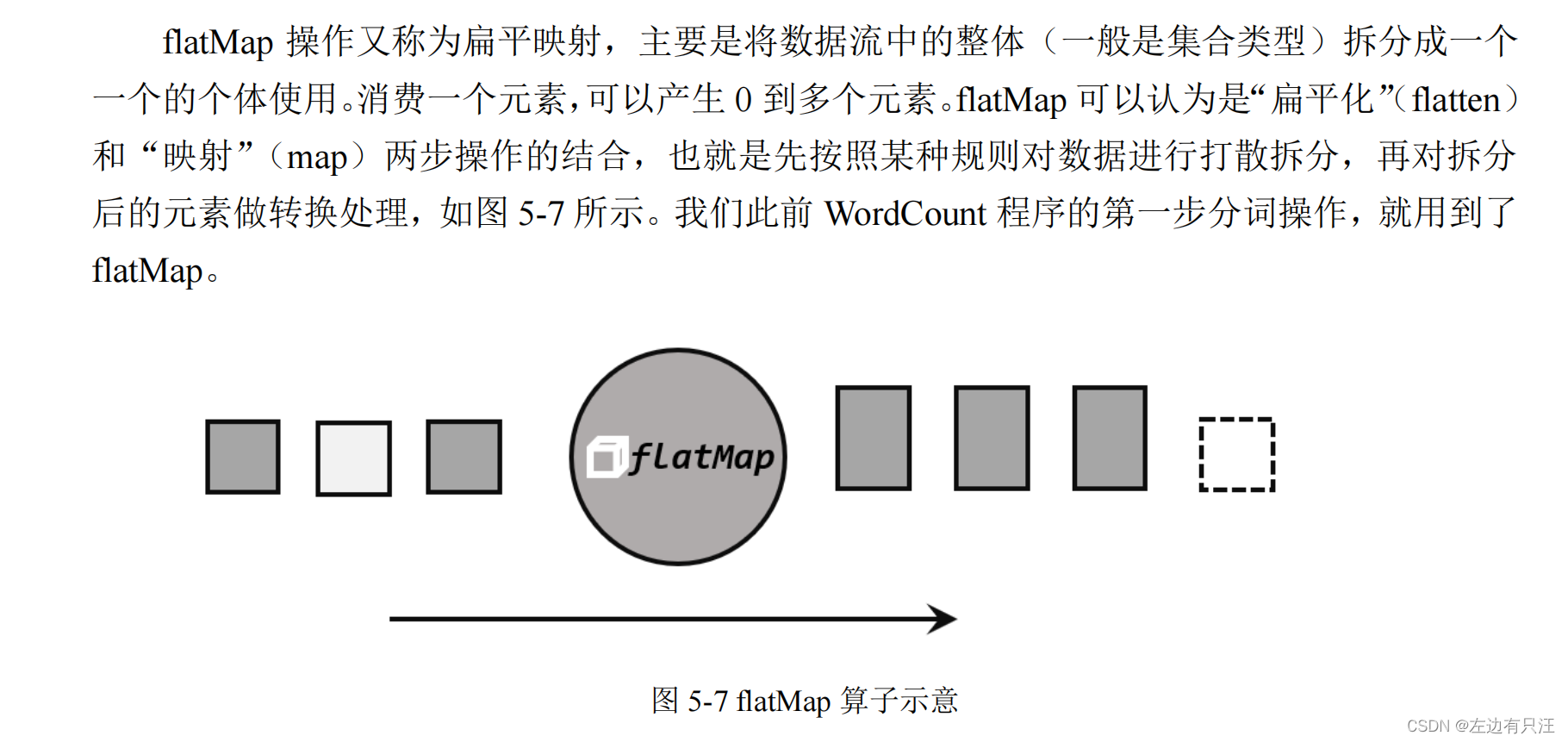

public class TransformFlatMapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.addSource(new ClickSource());
// 1. 传入一个实现了flatMapFunction的自定义类对象
// SingleOutputStreamOperator<String> flatMap = streamSource.flatMap(new MyFlatMap());
// 3. 传入lambda表达式
SingleOutputStreamOperator<String> flatMap = streamSource.flatMap((Event value, Collector<String> out) -> {
if("Mary".equals(value.getUser())) {
out.collect(value.getUser());
}else if("Bob".equals(value.getUrl())){
out.collect(value.getUser());
out.collect(value.getUrl());
out.collect(value.getTimestamp().toString());
}
// 不是Mary和Bob以外的其他数据, 这里不做任何处理, 相当于是被过滤掉了
// 这里还是会出现Java Lambda的泛型擦除. 因为在Lambda里使用了泛型, 当输出时Java会把泛型擦除, 所以这里需要手动添加return
}).returns(new TypeHint<String>() {});
flatMap.print();
env.execute();
}
public static class MyFlatMap implements FlatMapFunction<Event, String> {
@Override
public void flatMap(Event event, Collector<String> collector) throws Exception {
collector.collect(event.getUser());
collector.collect(event.getUrl());
collector.collect(event.getTimestamp().toString());
}
}
}
如果不加returns方法指定返回类型的话, 这里会报错

5.3.2 聚合算子(Aggregation)

- 按键分区(key by)

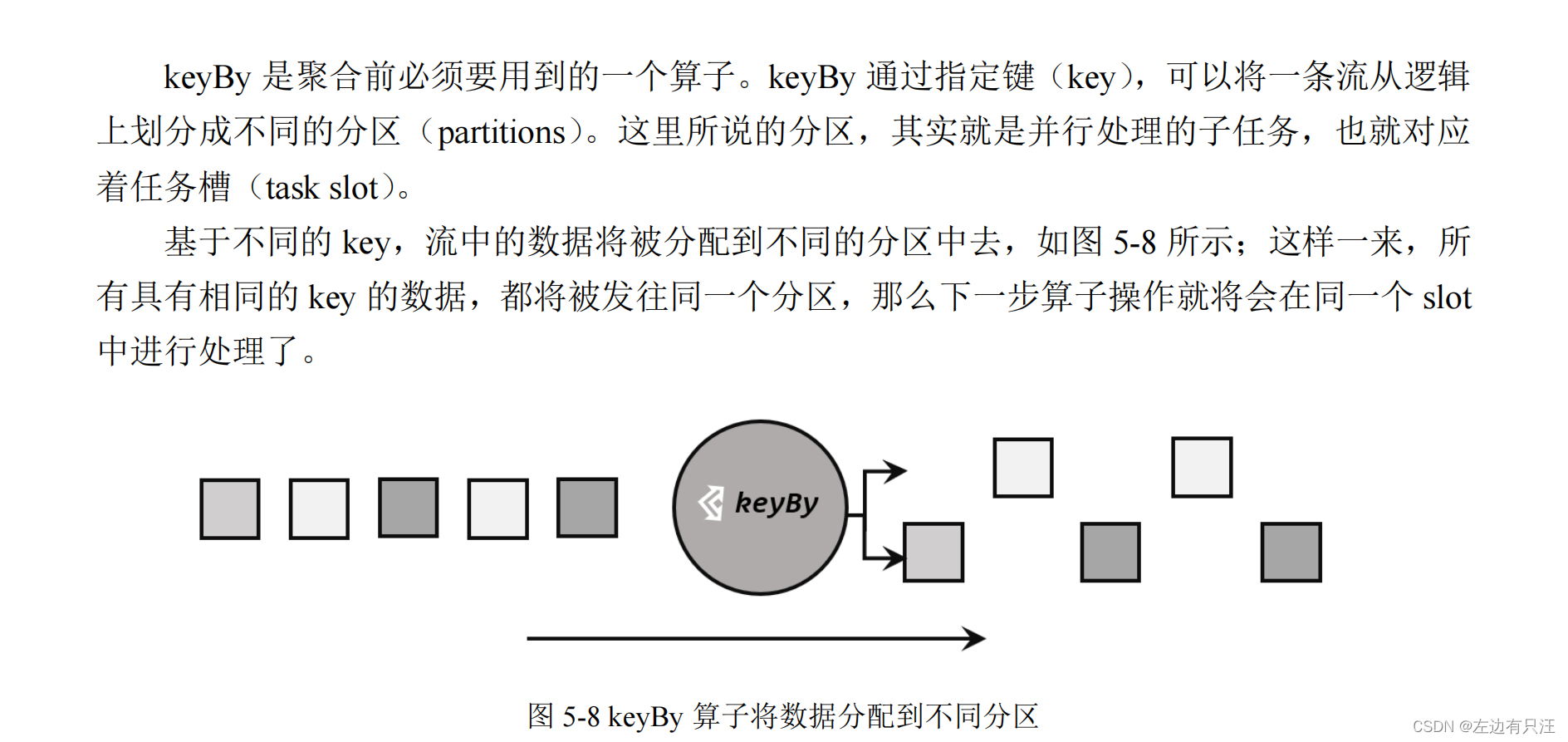

public class AggregationKeyByTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.fromElements(new Event("Mary","./home",1000L),
new Event("Bob","./cart",2000L),
new Event("Alice","./prod?id=100",3000L),
new Event("Bob","./prod?id=200",3400L)
);
// 按键分析后进行聚合
KeyedStream<Event, String> keyedStream = streamSource.keyBy(( event -> event.getUser()));
SingleOutputStreamOperator<Event> operatorMax = keyedStream.max("timestamp");
SingleOutputStreamOperator<Event> operatorMaxBy = keyedStream.maxBy("timestamp");
// max方法除了修改了timestamp的值以外, 对其他的参数还是使用最初的值, 而maxby除了对timestamp修改了以外, 也对其他的值取最新的数据
operatorMax.print("max");
operatorMaxBy.print("maxBy");
env.execute();
}
}
- 简单聚合



- 规约聚合



public class AggregationReduceTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.fromElements(new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=2", 3200L),
new Event("Bob", "./prod?id=200", 3400L),
new Event("Bob", "./home", 3300L),
new Event("Bob", "./prod?id=2", 3800L),
new Event("Bob", "./prod?id=3", 4200L)
);
// 统计访问量最大的用户和访问量
// 1. 统计每个用户的访问频次
// 在这里的map使用匿名内部类的形式不会出现泛型擦除, 如果使用lambda会出现泛型擦除, 所以在转换操作后, 尽量跟一个returns方法
SingleOutputStreamOperator<Tuple2<String, Long>> reduce = streamSource.map( event -> Tuple2.of(event.getUser(), 1L))
.returns(new TypeHint<Tuple2<String, Long>>() {})
.keyBy(data -> data.f0)
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
// 规约时, 第一个参数value1是前面规约后得到的数据, 后面的value2是新进来的数据,
// 所以我们要做的操作是,tuple的f0是user,而user名字都是相同的, 因为之前keyBy就是根据名字进行的
// tuple的f1是访问次数, 所以需要把value1的数字和value2的数字相加, 就是之前规约得到的数字加上新进来的数据的数字
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
});
// 2. 根据当前的个数, 选取当前最活跃的用户
// 这里keyBy给定了一个写死的字符串, 代表所有的数据都分配到相同的key中, 都会被分配到同一个分区
reduce.keyBy(data -> "key")
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
// value1的数量和value2的数量谁大就返回谁
return value1.f1 > value2.f1 ? value1 : value2;
}
}).print();
env.execute();
}
}
5.3.3 用户自定义函数(UDF)

- 函数类

- 匿名函数(Lambda)




这些方法对于其它泛型擦除的场景同样适用。 - 富函数类(Rich Function Classes)


public class TransformRichFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.fromElements(new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=2", 3200L),
new Event("Bob", "./prod?id=200", 3400L),
new Event("Bob", "./home", 3300L),
new Event("Bob", "./prod?id=2", 3800L),
new Event("Bob", "./prod?id=3", 4200L)
);
streamSource.map(new MyRichMapFunction()).print();
env.execute();
}
public static class MyRichMapFunction extends RichMapFunction<Event,Integer>{
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("open生命周期" + getRuntimeContext().getIndexOfThisSubtask() + "号任务");
}
@Override
public void close() throws Exception {
super.close();
System.out.println("close生命周期" + getRuntimeContext().getIndexOfThisSubtask() + "号任务结束");
}
@Override
public Integer map(Event event) throws Exception {
return event.getUrl().length();
}
}
}
5.3.4 物理分区(Physical Partitioning)



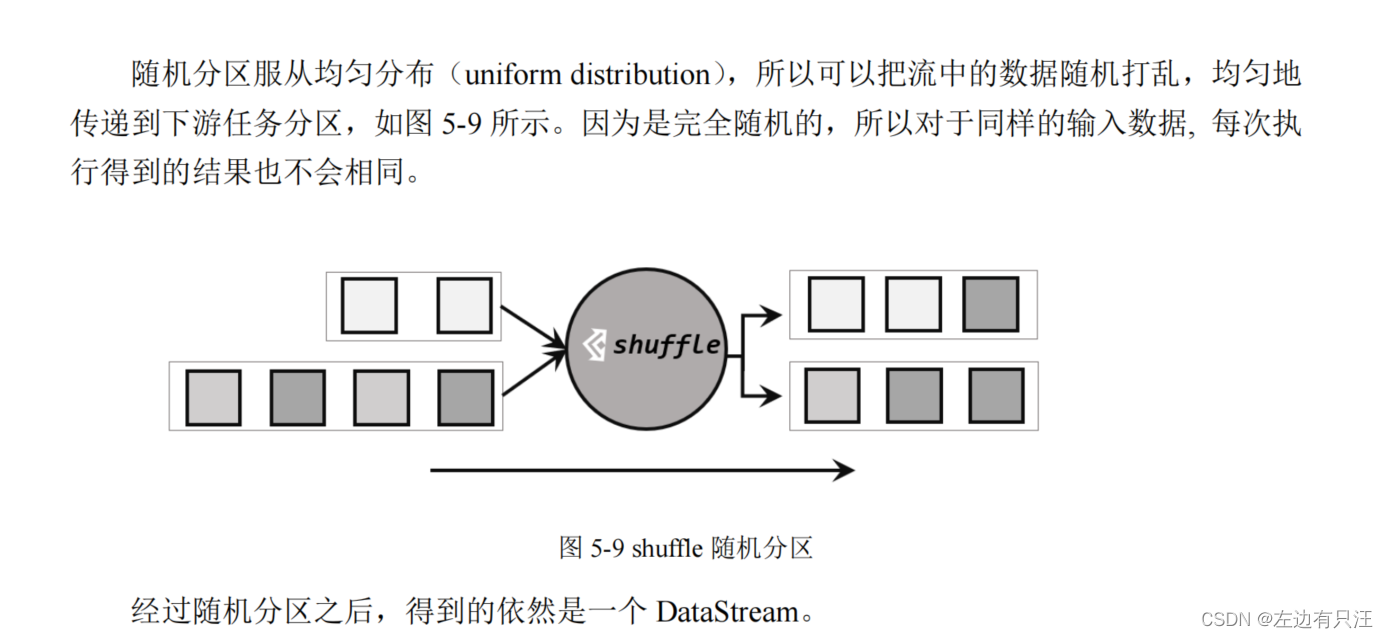
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.fromElements(new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=2", 3200L),
new Event("Bob", "./prod?id=200", 3400L),
new Event("Bob", "./home", 3300L),
new Event("Bob", "./prod?id=2", 3800L),
new Event("Bob", "./prod?id=3", 4200L)
);
streamSource.shuffle().print().setParallelism(4);
env.execute();

整体来看没有什么规律, 在数据量很多的情况下, 会大概率变成均匀分布
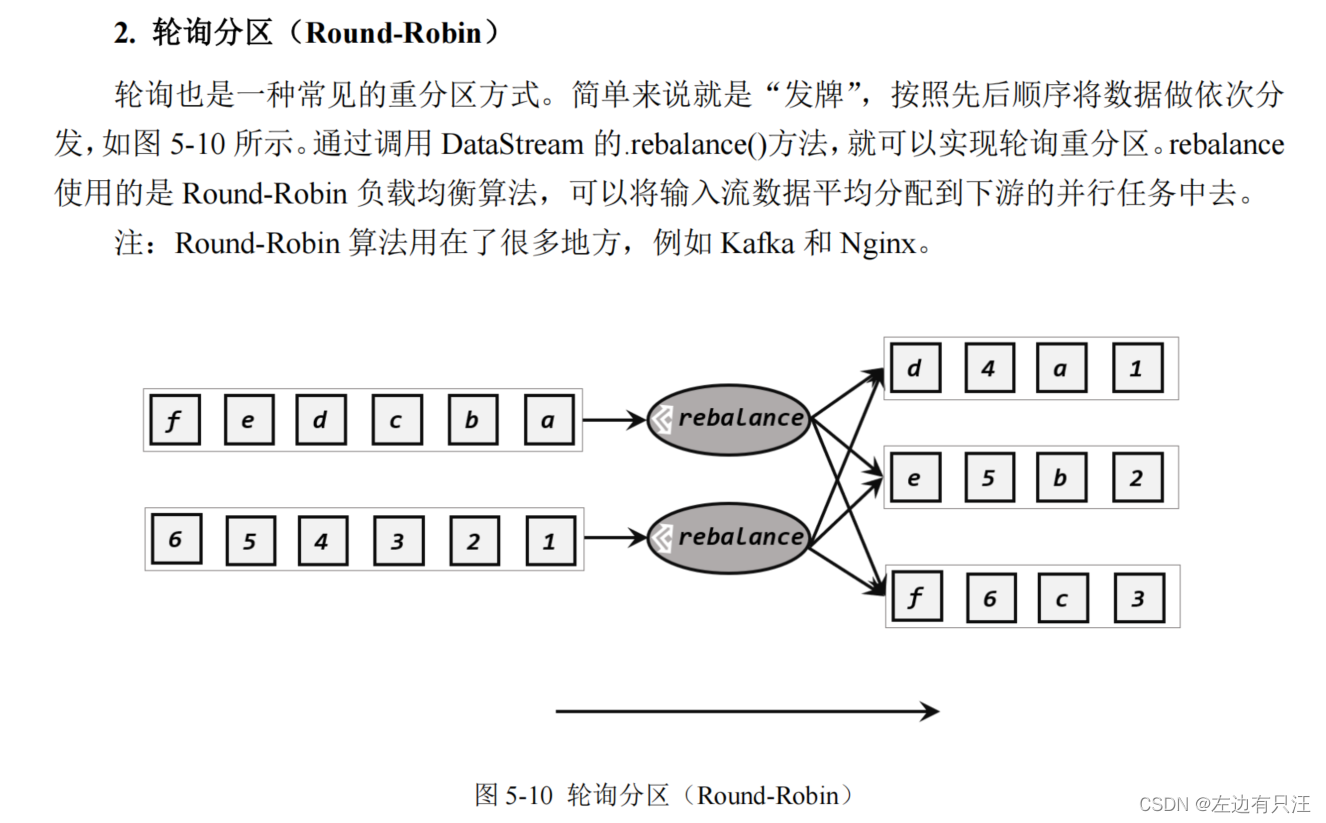
streamSource.rebalance().print().setParallelism(4);
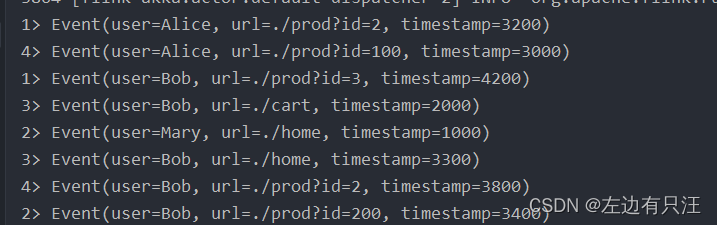
可以看到8条数据被均匀的分给了四个并行算子上,每个slot上都输出了2条数据, 如果不指定物理分区操作, Flink底层默认会使用rebalance分区策略
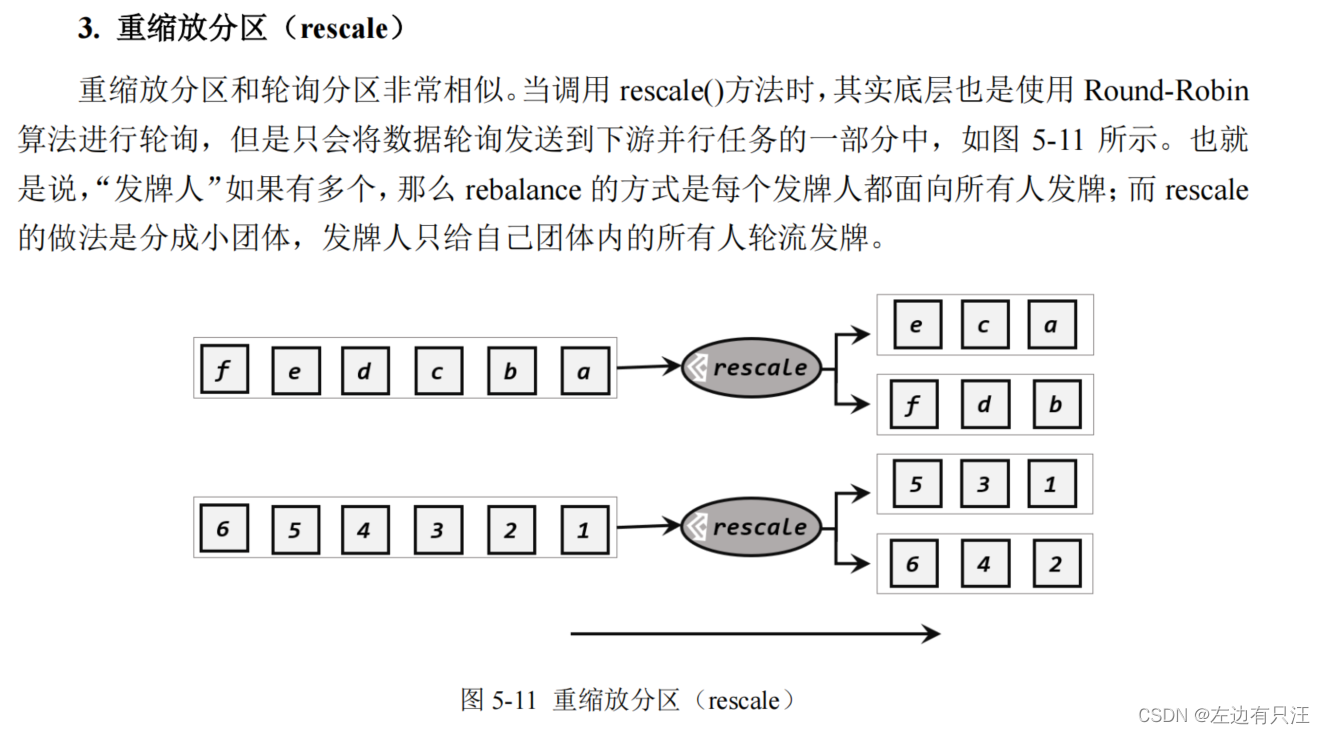





StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 从自定义流中读取数据
env.fromElements(1,2,3,4,5,6,7,8)
.partitionCustom(new Partitioner<Integer>() {
@Override
public int partition(Integer o, int i) {
return o % 2;
}
}, new KeySelector<Integer, Integer>() {
@Override
public Integer getKey(Integer integer) throws Exception {
return integer;
}
}).print().setParallelism(4);
// 自定义重分区
env.execute();
5.4 输出算子(Sink)
5.4.1 连接到外部系统





5.4.2 输出到文件

public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.fromElements(new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=2", 3200L),
new Event("Bob", "./prod?id=200", 3400L),
new Event("Bob", "./home", 3300L),
new Event("Bob", "./prod?id=2", 3800L),
new Event("Bob", "./prod?id=3", 4200L)
);
StreamingFileSink<String> streamingFileSink = StreamingFileSink.<String>forRowFormat(new Path("./output"),
new SimpleStringEncoder<>("UTF-8"))
// 设置文件归档策略, 使用默认的滚动归档策略即可
.withRollingPolicy(DefaultRollingPolicy
.builder()
// 文件的最大大小单位字节 此处为1G
.withMaxPartSize(1024*1024*1024)
// 设置每隔多长时间进行归档 单位ms 此处为15分钟
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
// 设置无操作(不活跃)后多长时间进行归档 此处为5分钟
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.build())
.build();
// 因为streamSource的泛型为Event, 我们这里要转换成String进行归档写入文件, 所以要加一个map转换的操作
streamSource.map(data -> data.toString()).addSink(streamingFileSink);
env.execute();
}

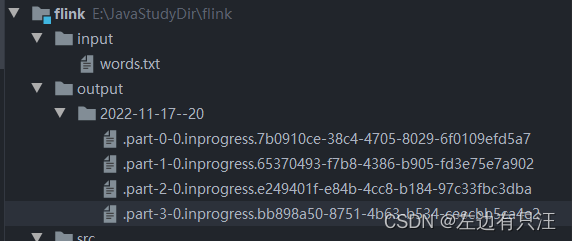
因为设置了4个并行子任务来执行写入, 而且还设置了滚动策略. 所以输出路径如下图所示
5.4.3 输出到Kafka



public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取Kafka数据
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","hadoop102:9092");
DataStreamSource<String> kafkaStream = env.addSource(new FlinkKafkaConsumer<String>("clicks", new SimpleStringSchema(), properties));
// 2. 用flink进行转换处理
SingleOutputStreamOperator<String> map = kafkaStream.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
String[] fields = s.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 3.输出到kafka
map.addSink(new FlinkKafkaProducer<String>("hadoop102:9092","events",new SimpleStringSchema()));
env.execute();
}
5.4.4 输出到Redis

- 导入redis连接器依赖
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>

StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.addSource(new ClickSource());
// 创建一个jedis连接配置
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("hadoop102")
.build();
stream.addSink(new RedisSink<>(config, new MyRedisMapper()));
env.execute();

// 自定义类实现RedisMapper接口
public static class MyRedisMapper implements RedisMapper<Event> {
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET,"clicks");
}
@Override
public String getKeyFromData(Event event) {
return event.getUser();
}
@Override
public String getValueFromData(Event event) {
return event.getUrl();
}
}

5.4.5 输出到ElasticSearch

- 添加ElasticSearch连接器依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>

public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.fromElements(new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=2", 3200L),
new Event("Bob", "./prod?id=200", 3400L),
new Event("Bob", "./home", 3300L),
new Event("Bob", "./prod?id=2", 3800L),
new Event("Bob", "./prod?id=3", 4200L)
);
// 定义hosts的列表
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("hadoop102",9200));
// 定义ElasticSearchSinkFunction 处理数据
ElasticsearchSinkFunction<Event> elasticsearchSinkFunction = new ElasticsearchSinkFunction<Event>() {
@Override
public void process(Event event, RuntimeContext runtimeContext, RequestIndexer requestIndexer) {
HashMap<String, String> map = new HashMap<>();
map.put(event.getUser(),event.getUrl());
// 构建一个IndexRequest
IndexRequest clicks = Requests.indexRequest()
.index("clicks")
.source(map);
requestIndexer.add(clicks);
}
};
streamSource.addSink(new ElasticsearchSink.Builder<>(httpHosts,elasticsearchSinkFunction ).build());
env.execute();
}

5.4.6 输出到MYSQL(jdbc)

<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>

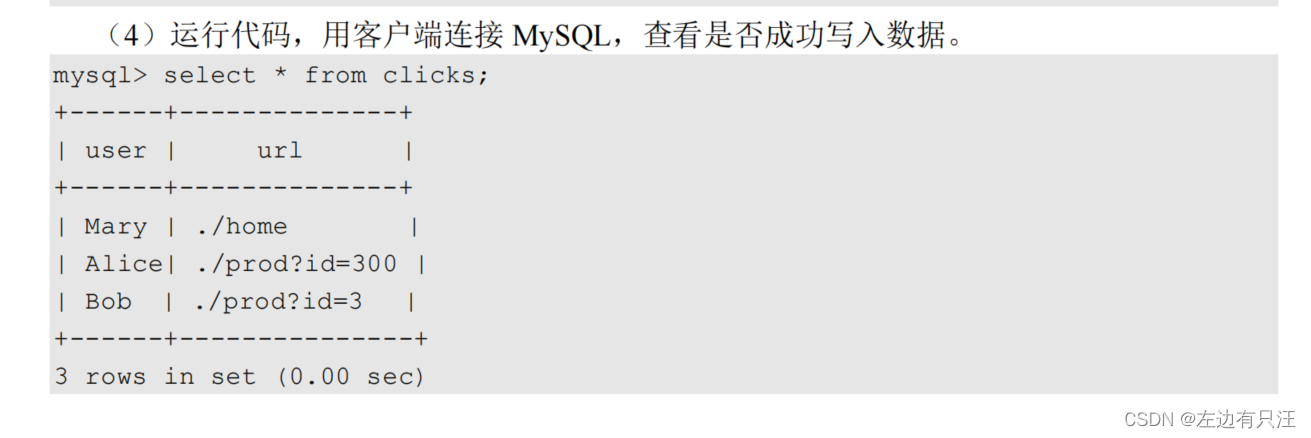
5.4.7 自定义Sink输出如HBase


<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
(2)编写输出到 HBase 的示例代码
package com.yangjunyi.flink.sink;
package com.yangjunyi.flink.sink;
import com.yangjunyi.flink.entity.Event;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import java.nio.charset.StandardCharsets;
import java.sql.PreparedStatement;
public class SinkToHBase {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.fromElements("hello", "world")
.addSink(
new RichSinkFunction<String>() {
public org.apache.hadoop.conf.Configuration configuration; // 管理 Hbase 的配置信息,这里因为 Configuration 的重名问题,将类以完整路径导入
public Connection connection; // 管理 Hbase 连接
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "hadoop102:2181");
connection = ConnectionFactory.createConnection(configuration);
}
@Override
public void invoke(String value, Context context) throws Exception {
Table table = connection.getTable(TableName.valueOf("test")); // 表名为 test
Put put = new Put("rowkey".getBytes(StandardCharsets.UTF_8)); // 指定 rowkey
put.addColumn("info".getBytes(StandardCharsets.UTF_8) // 指定列名
, value.getBytes(StandardCharsets.UTF_8) // 写入的数据
, "1".getBytes(StandardCharsets.UTF_8)); // 写入的数据
table.put(put); // 执行 put 操作
table.close(); // 将表关闭
}
@Override
public void close() throws Exception {
super.close();
connection.close(); // 关闭连接
}
}
);
env.execute();
}
}
public class SinkToHBase {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.fromElements("hello", "world")
.addSink(
new RichSinkFunction<String>() {
public org.apache.hadoop.conf.Configuration configuration; // 管理 Hbase 的配置信息,这里因为 Configuration 的重名问题,将类以完整路径导入
public Connection connection; // 管理 Hbase 连接
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "hadoop102:2181");
connection = ConnectionFactory.createConnection(configuration);
}
@Override
public void invoke(String value, Context context) throws Exception {
Table table = connection.getTable(TableName.valueOf("test")); // 表名为 test
Put put = new Put("rowkey".getBytes(StandardCharsets.UTF_8)); // 指定 rowkey
put.addColumn("info".getBytes(StandardCharsets.UTF_8) // 指定列名
, value.getBytes(StandardCharsets.UTF_8) // 写入的数据
, "1".getBytes(StandardCharsets.UTF_8)); // 写入的数据
table.put(put); // 执行 put 操作
table.close(); // 将表关闭
}
@Override
public void close() throws Exception {
super.close();
connection.close(); // 关闭连接
}
}
);
env.execute();
}
}
6.Flink中的时间和窗口
6.1 时间语义
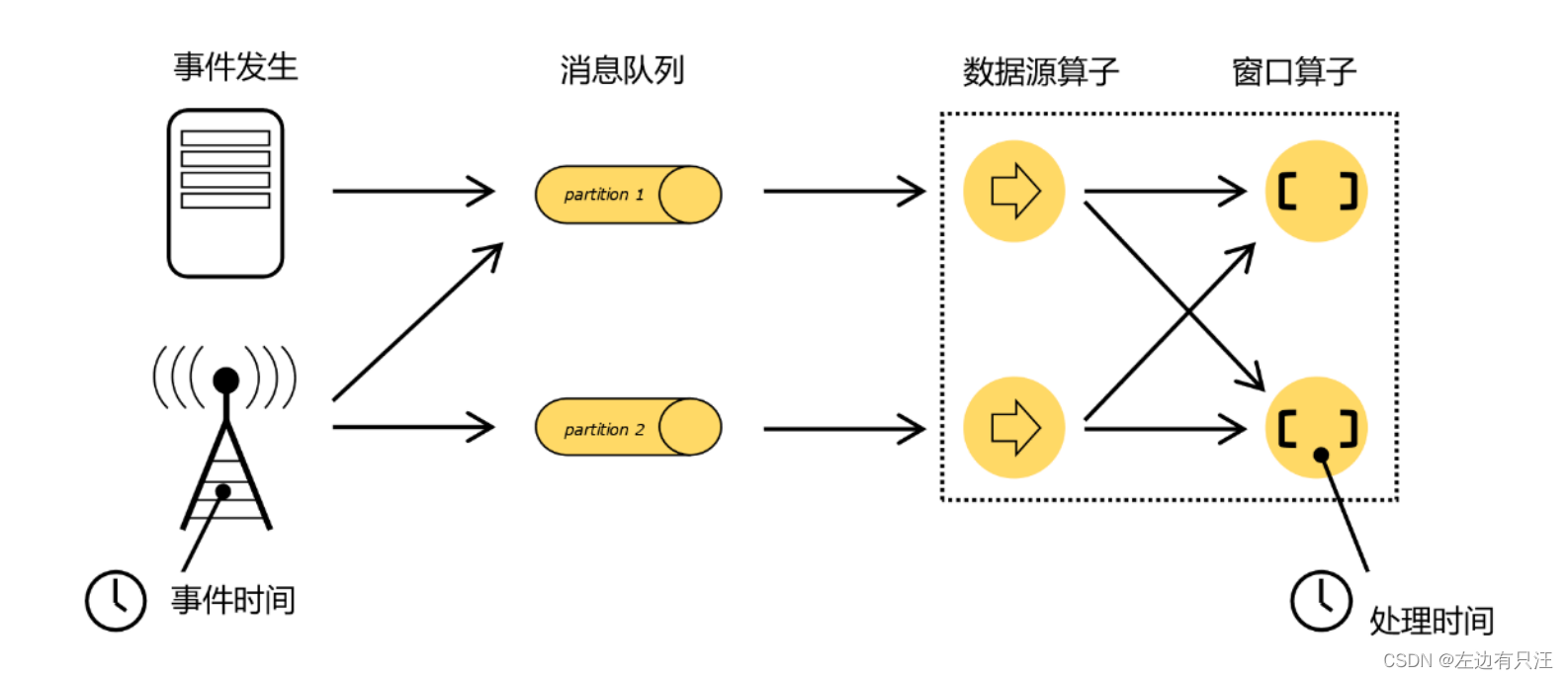
6.1.1 Flink中的时间语义




6.1.2 哪种时间语义更重要



6.2 水位线
6.2.1 事件时间和窗口




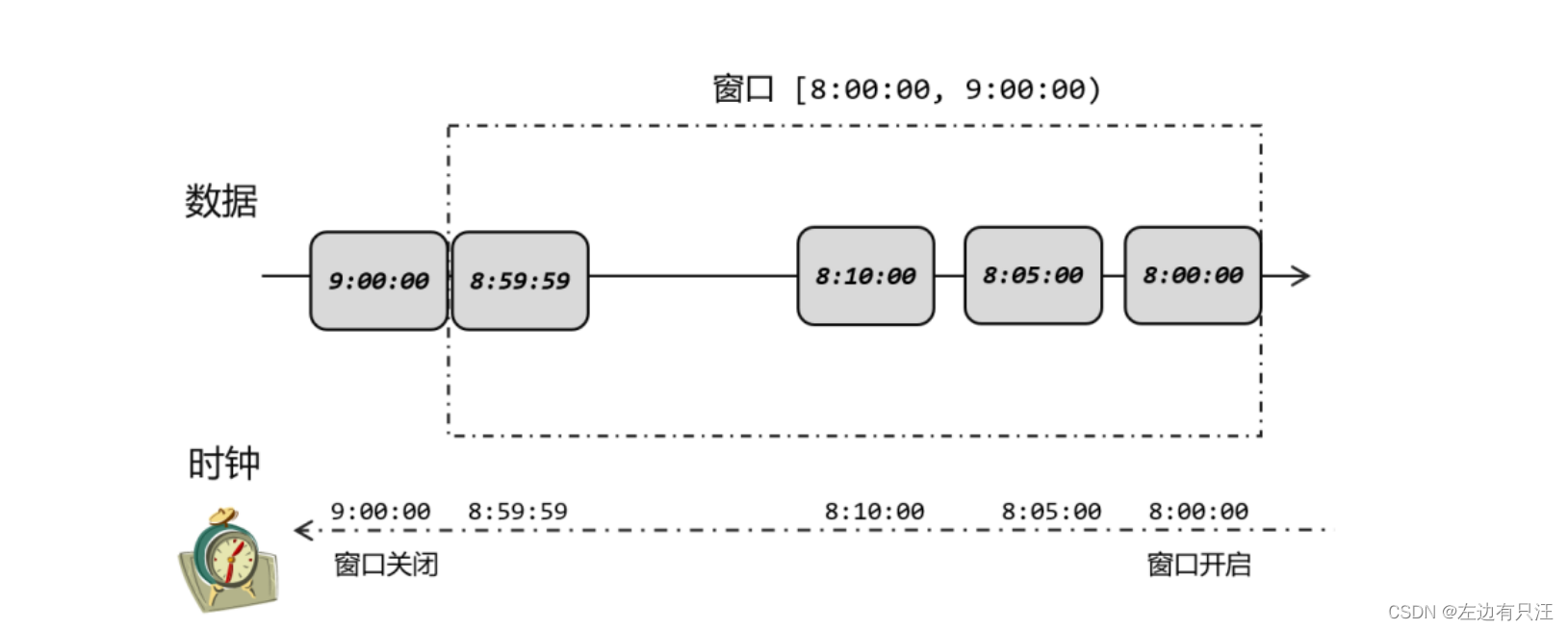

6.2.2 什么是水位线





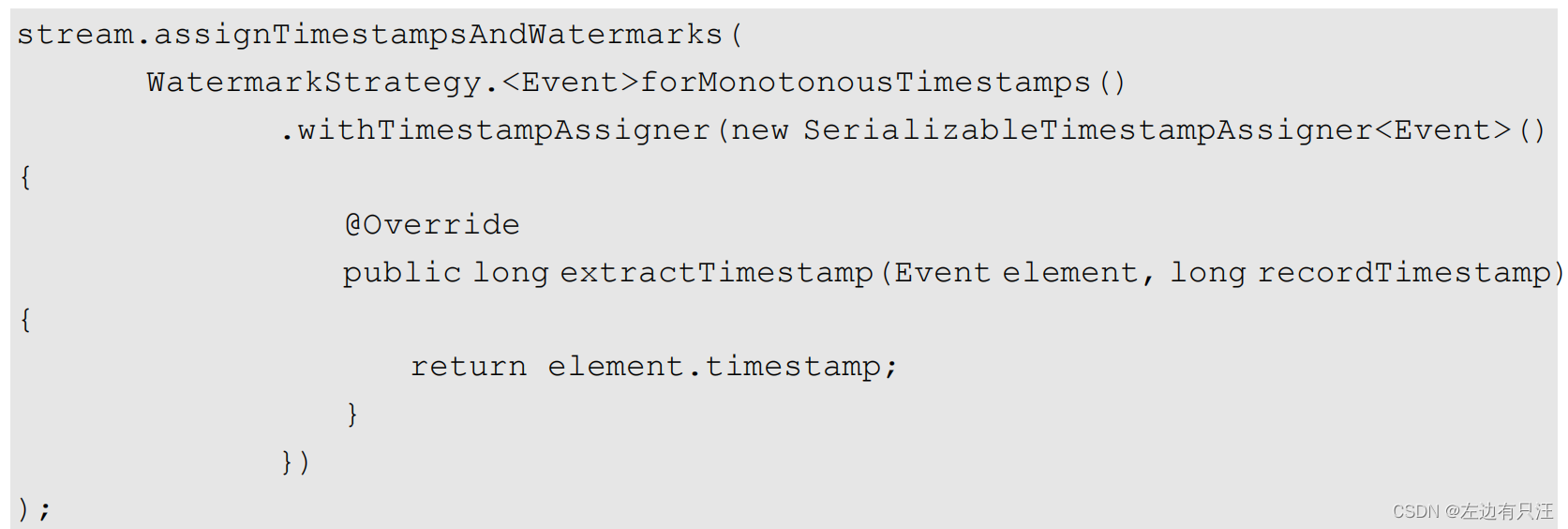
6.2.3 如何生成水位线







水位线的周期性生成间隔时间设置env.getConfig().setAutoWatermarkInterval(100L) 单位是ms表示每隔100ms生成一次水位线, 默认值是200ms

public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 设置水位线自动生成时间间隔为100ms 默认值是200ms
env.getConfig().setAutoWatermarkInterval(100L);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.fromElements(new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=2", 3200L),
new Event("Bob", "./prod?id=200", 3400L),
new Event("Bob", "./home", 3300L),
new Event("Bob", "./prod?id=2", 3800L),
new Event("Bob", "./prod?id=3", 4200L)
);
// 水位线生成策略建议离source算子越近越好, 因为在source处设置了水位线, 后续的其他算子都可以用到
// 有序流额watermark生成,有序流就是基于自增长的时间戳作为水位线即可
SingleOutputStreamOperator<Event> stream1 = streamSource.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTimestamp) {
return event.getTimestamp();
}
})
);
// 乱序流watermark生成
SingleOutputStreamOperator<Event> stream2 = streamSource.assignTimestampsAndWatermarks(
// 设置水位线延时2秒
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2L))
// 设置水位线基于时间戳数据
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTimestamp) {
return event.getTimestamp();
}
})
);
env.execute();
}


public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(new CustomWatermarkStrategy())
.print();
env.execute();
}
public static class CustomWatermarkStrategy implements WatermarkStrategy<Event> {
@Override
public TimestampAssigner<Event> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.getTimestamp(); // 告诉程序数据源里的时间戳是哪一个字段
}
};
}
@Override
public WatermarkGenerator<Event> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new CustomPeriodicGenerator();
}
}
public static class CustomPeriodicGenerator implements WatermarkGenerator<Event> {
private Long delayTime = 5000L; // 延迟时间
private Long maxTs = Long.MIN_VALUE + delayTime + 1L; // 观察到的最大时间戳
@Override
public void onEvent(Event event, long eventTimestamp, WatermarkOutput output) {
// 每来一条数据就调用一次
maxTs = Math.max(event.getTimestamp(), maxTs); // 更新最大时间戳
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 发射水位线,默认 200ms 调用一次
output.emitWatermark(new Watermark(maxTs - delayTime - 1L));
}
}

public class CustomPunctuatedGenerator implements WatermarkGenerator<Event> {
@Override
public void onEvent(Event r, long eventTimestamp, WatermarkOutput output) {
// 只有在遇到特定的 itemId 时,才发出水位线
if (r.user.equals("Mary")) {
output.emitWatermark(new Watermark(r.timestamp - 1));
}
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 不需要做任何事情,因为我们在 onEvent 方法中发射了水位线
}
}

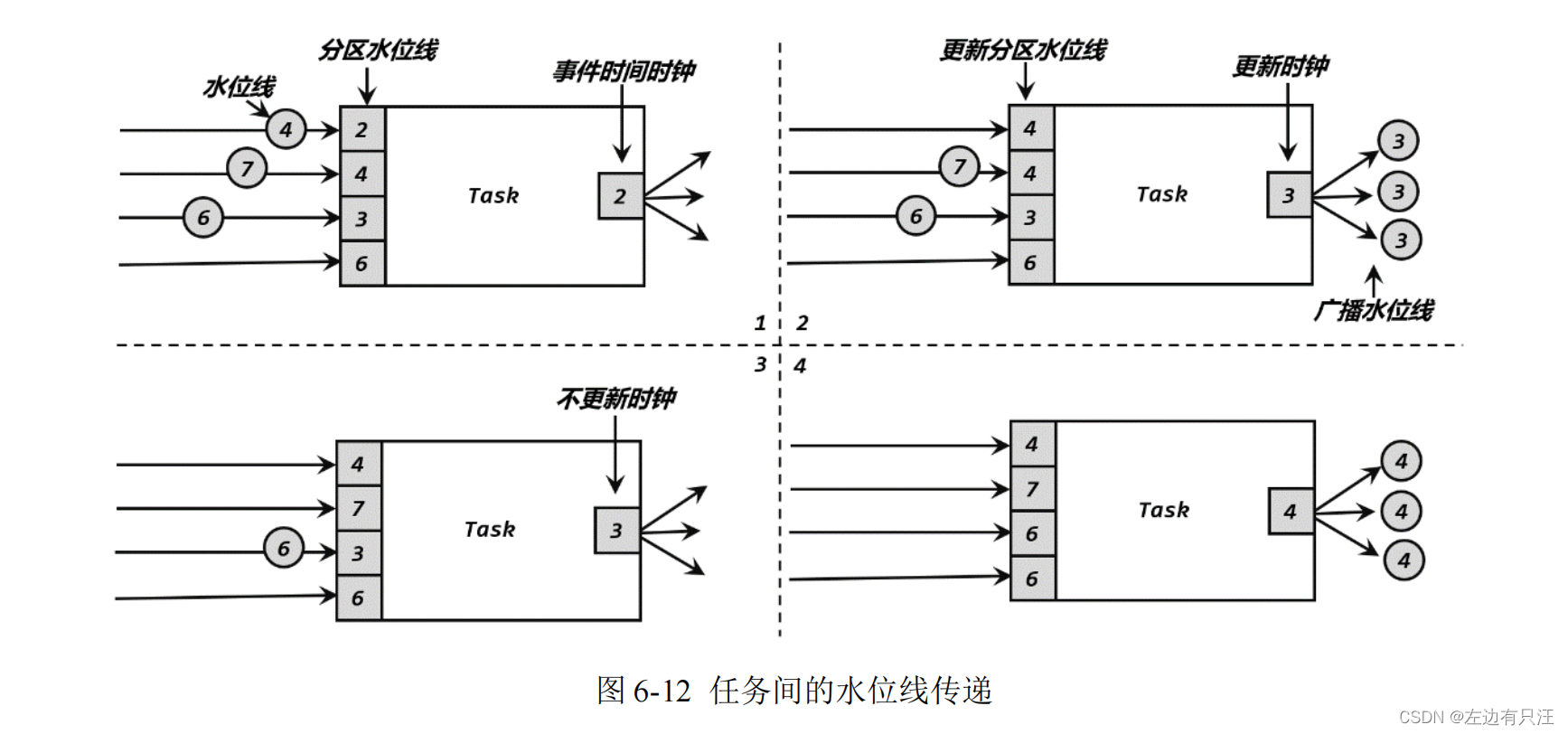
6.2.4 水位线的传递


6.3 窗口
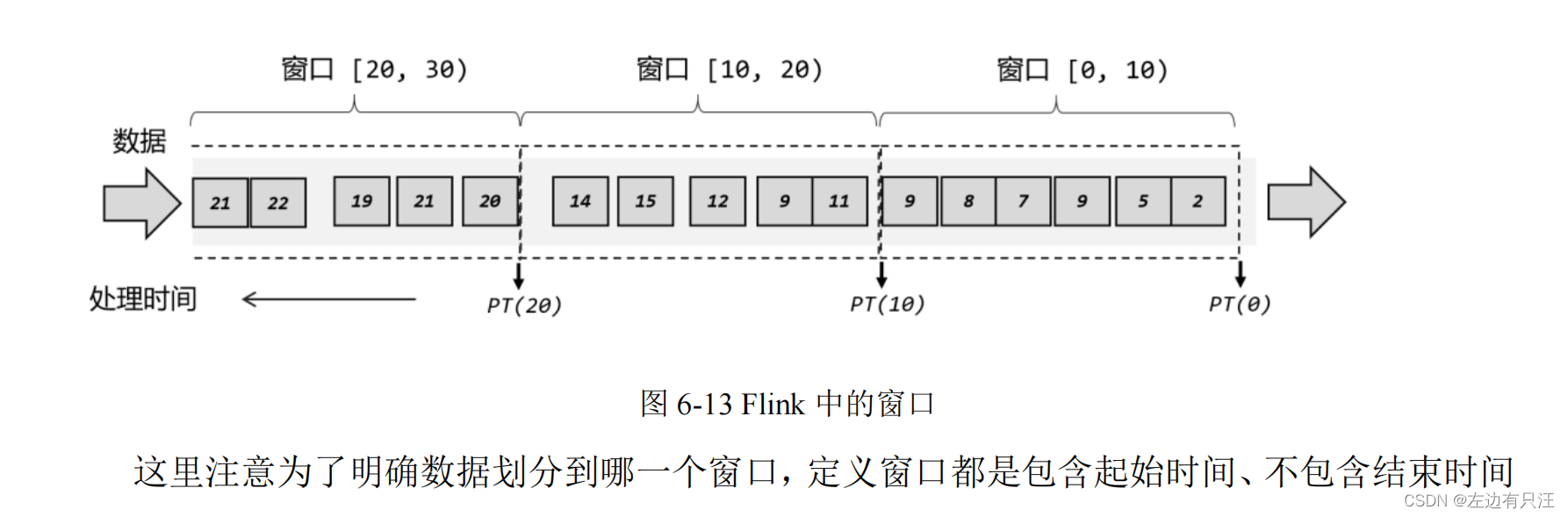
6.3.1 窗口的概念



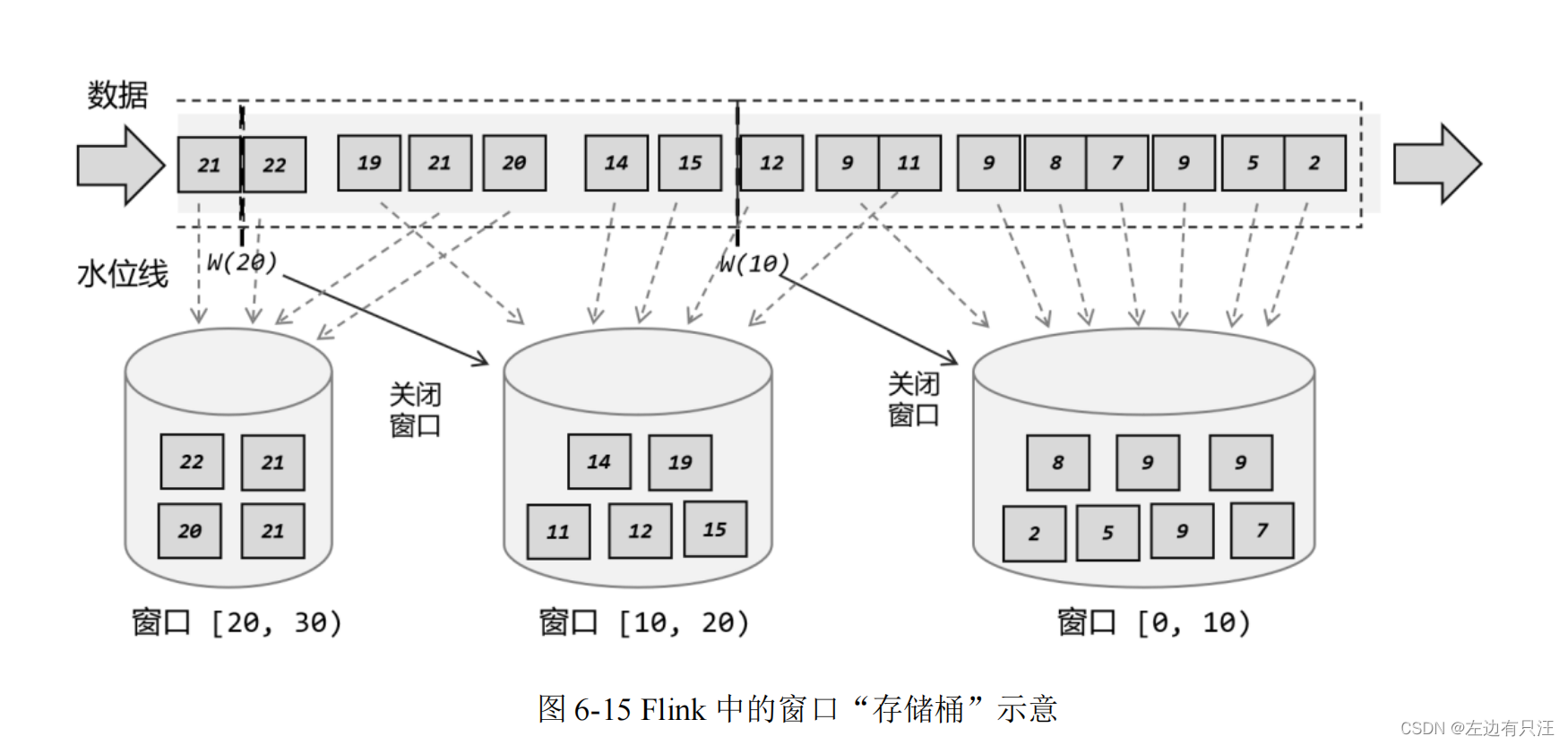

6.3.2 窗口的分类
- 按照驱动类型分类
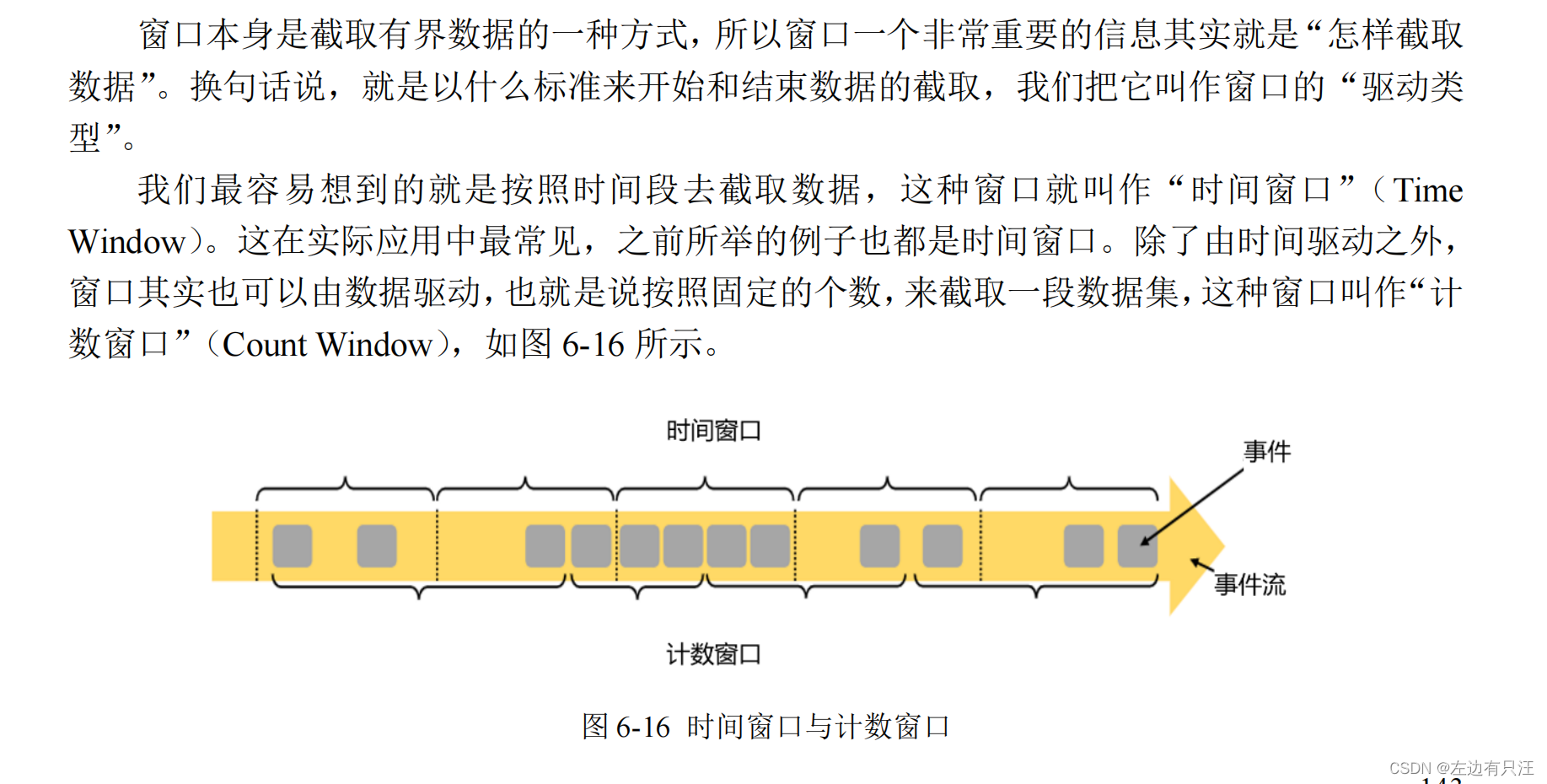
(1)时间窗口(Time Window)


(2)计数窗口(Count Window)

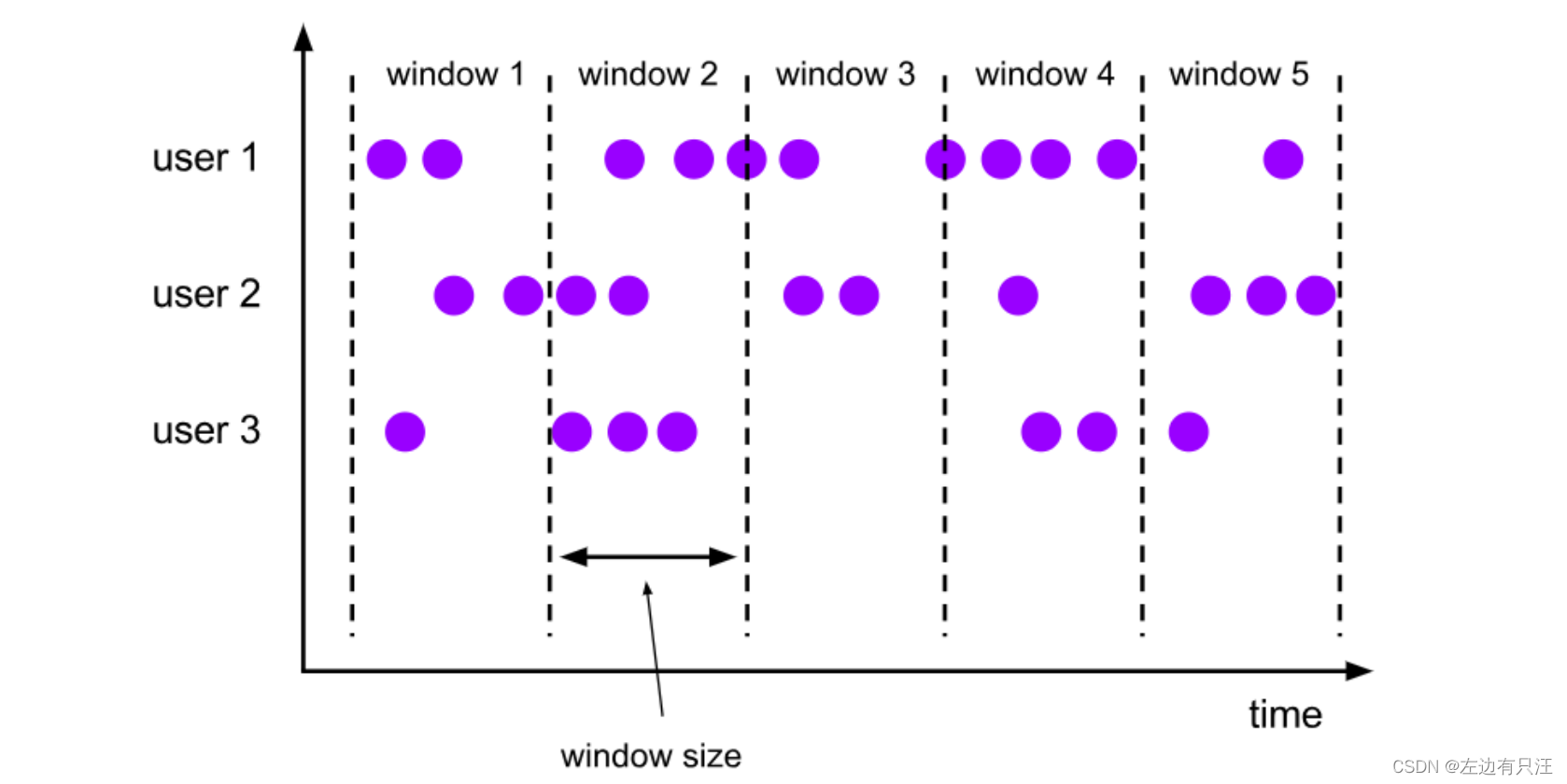
- 按照窗口分配数据的规则分类

(1)滚动窗口(Tumbling Windows)


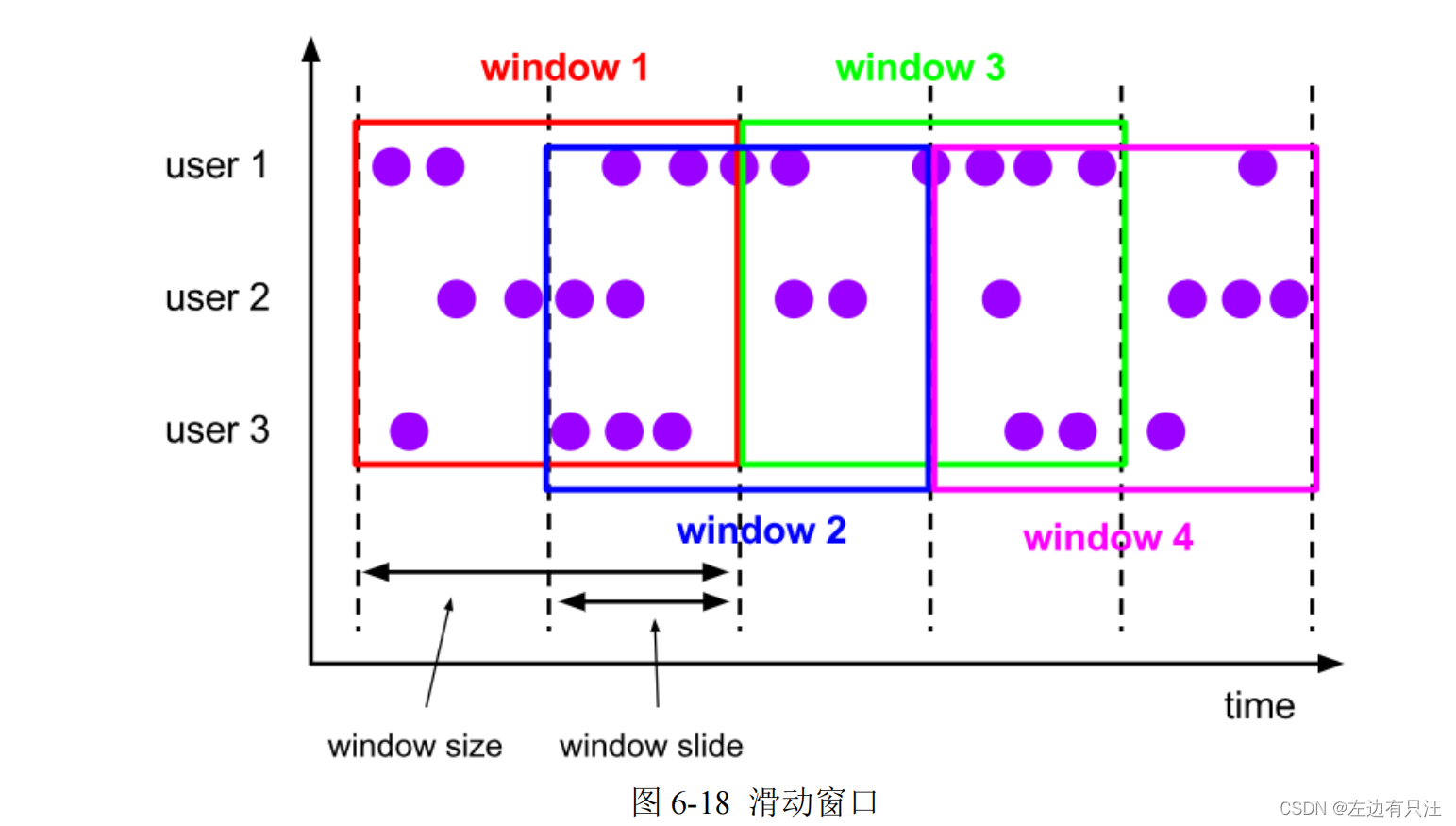
(2)滑动窗口(Sliding Windows)


(3)会话窗口(Session Windows)


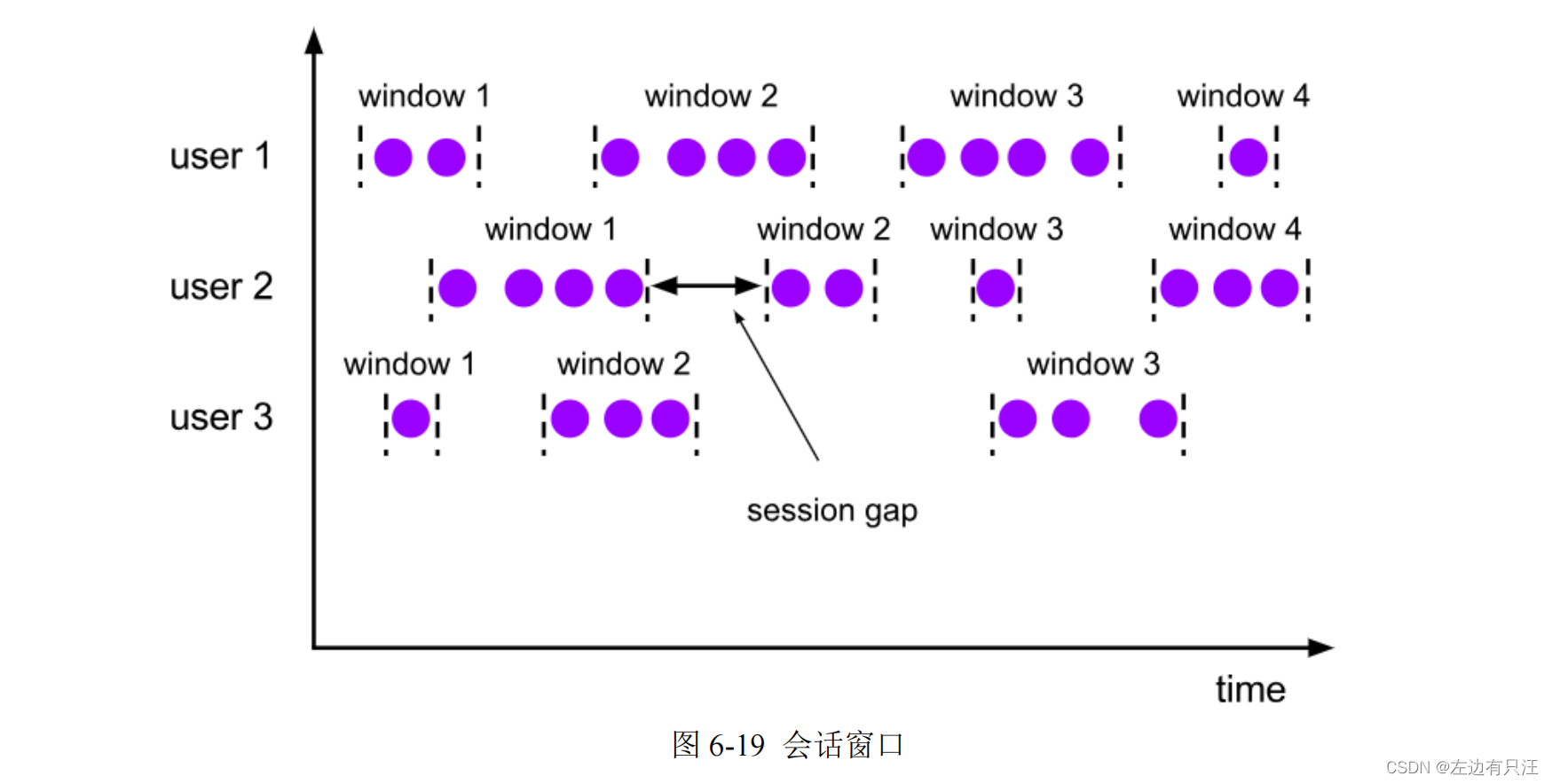

(4)全局窗口(Global Windows)


6.3.3 窗口API概览



6.3.4 窗口分配器(Window Assigners)

- 时间窗口


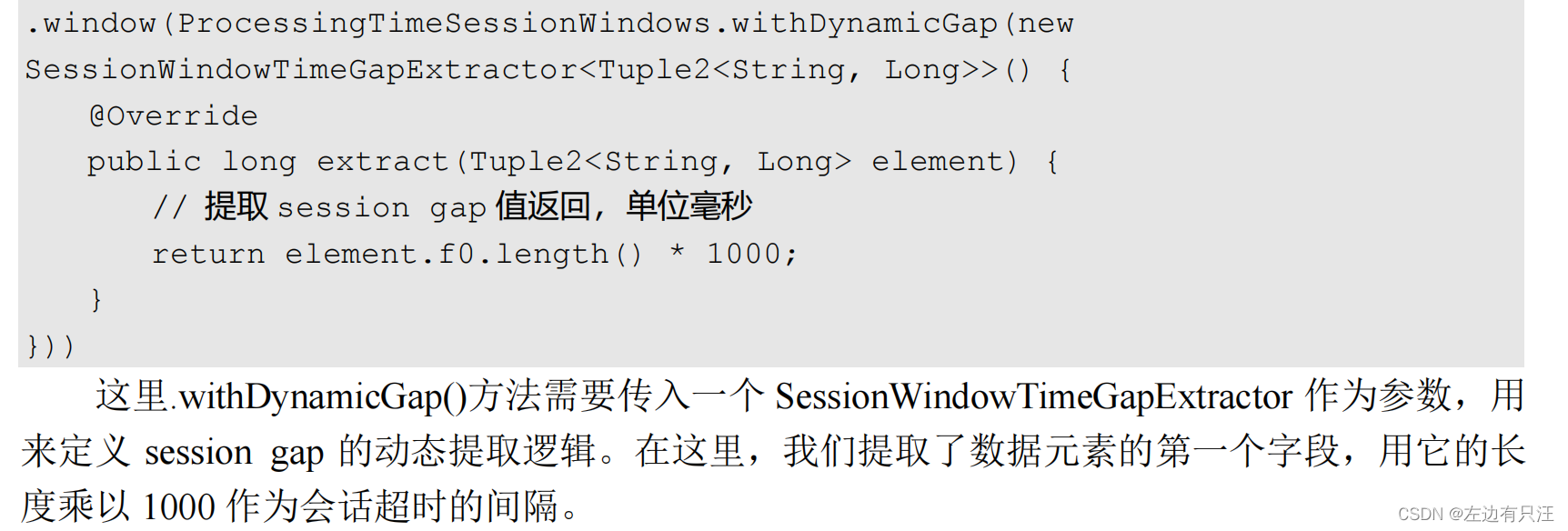

- 计数窗口

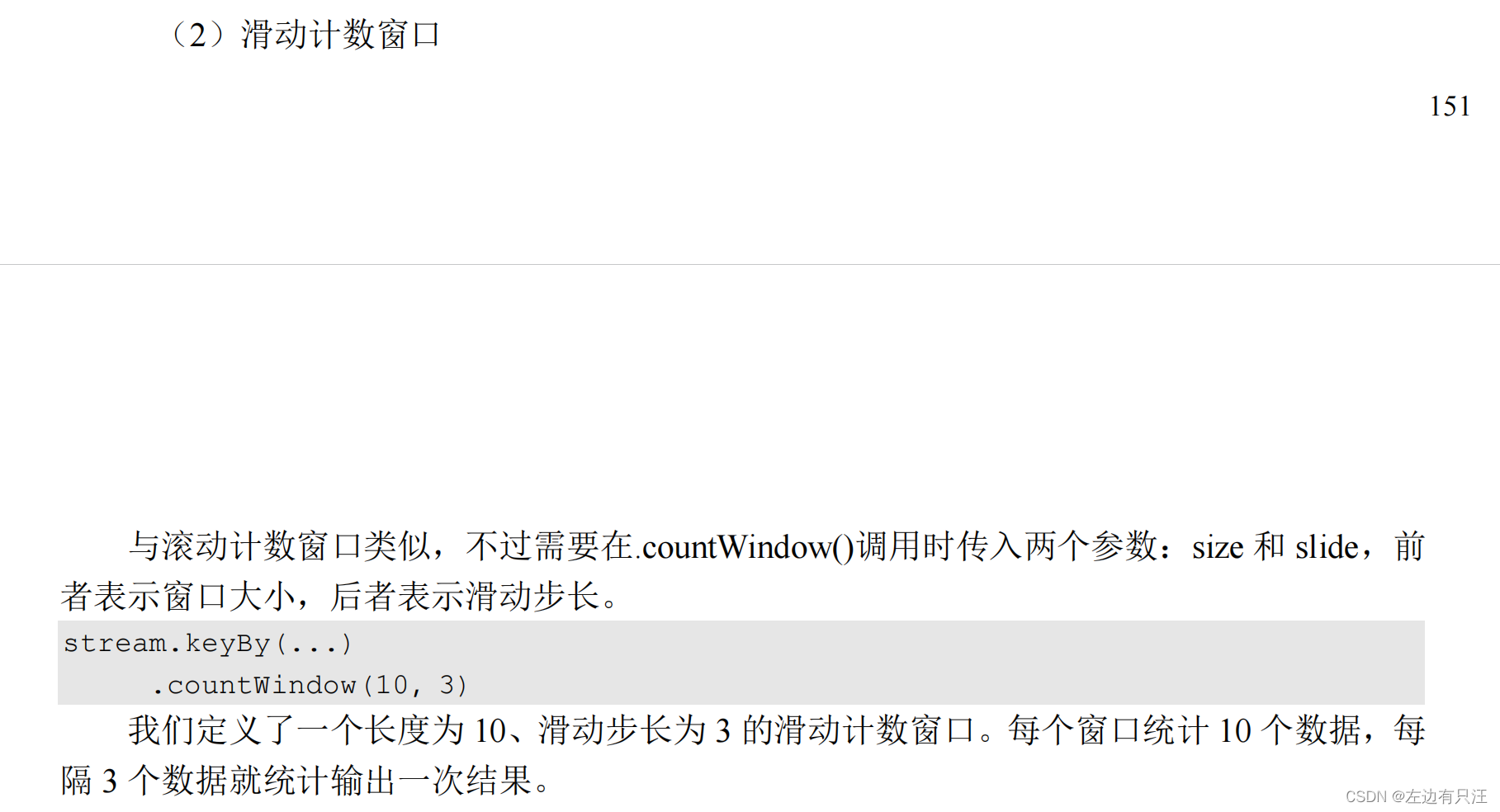
- 全局窗口

public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 设置水位线自动生成时间间隔为100ms 默认值是200ms
env.getConfig().setAutoWatermarkInterval(100L);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.fromElements(new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=2", 3200L),
new Event("Bob", "./prod?id=200", 3400L),
new Event("Bob", "./home", 3300L),
new Event("Bob", "./prod?id=2", 3800L),
new Event("Bob", "./prod?id=3", 4200L)
);
// 乱序流watermark生成
SingleOutputStreamOperator<Event> stream = streamSource.assignTimestampsAndWatermarks(
// 设置水位线延时2秒
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2L))
// 设置水位线基于时间戳数据
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTimestamp) {
return event.getTimestamp();
}
})
);
// 注意开窗前必须指定水位线
stream.keyBy(data -> data.getUser())
// 滚动事件时间窗口, 指定事件时间1小时的窗口
//.window(TumblingEventTimeWindows.of(Time.hours(1)))
// 时间窗口都有一个参数是offset偏移量,我们时区为东8区, 代码获取的时间应该减去8小时才是我们的时间
// 这样才可以得到北京时间每天 0 点开启的滚动窗口
//.window(TumblingEventTimeWindows.of(Time.days(1),Time.hours(-8)))
// 滑动事件时间窗口, 指定事件时间窗口大小为1小时, 每5分钟滑动一次
//.window(SlidingEventTimeWindows.of(Time.hours(1),Time.minutes(5)))
// 事件时间会话窗口
//.window(EventTimeSessionWindows.withGap(Time.seconds(2)))
// countWindow计数窗口, 一个参数的就是滚动窗口, 2个参数的就是滑动窗口
.countWindow(10L);
// 注意所有的开窗都不是一个完整的算子, 只能算是一个中间步骤返回值是WindowedStream, 只有开窗函数+窗口函数完成后才返回的是完整的算子
env.execute();
}
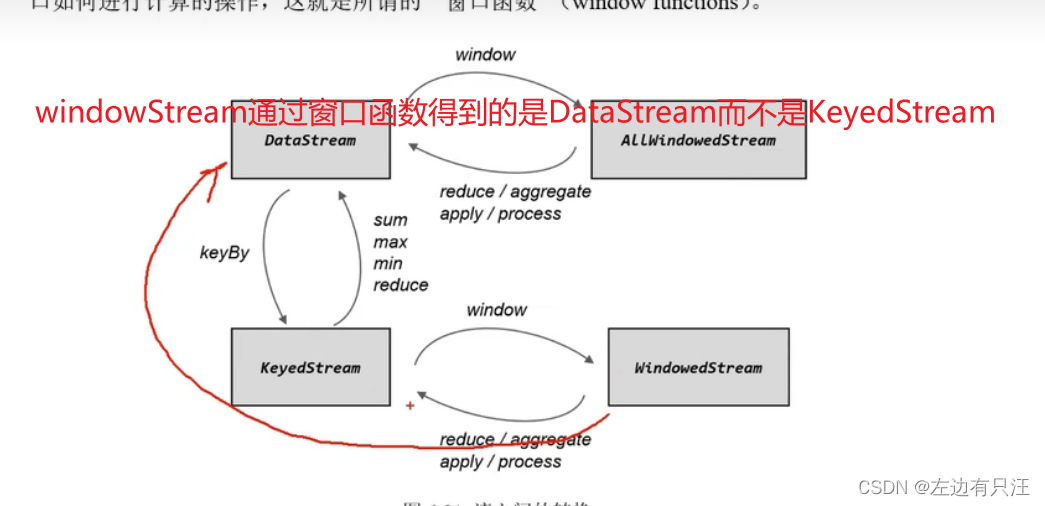
6.3.5窗口函数

对WindowStream进行窗口函数后, 才能得到一个DataStream
- 增量聚合函数(incremental aggregation functions)流处理思路增量的计算

(1)归约函数(ReduceFunction)

public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 设置水位线自动生成时间间隔为100ms 默认值是200ms
env.getConfig().setAutoWatermarkInterval(100L);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.addSource(new ClickSource());
// 乱序流watermark生成
SingleOutputStreamOperator<Event> stream = streamSource.assignTimestampsAndWatermarks(
// 设置水位线延时2秒
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2L))
// 设置水位线基于时间戳数据
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTimestamp) {
return event.getTimestamp();
}
})
);
// 把点击数据转换成二元组 用户名和点击次数1次
stream.map(data -> Tuple2.of(data.getUser(), 1L))
// 指定返回值二元组
.returns(new TypeHint<Tuple2<String, Long>>() {})
// 对user进行分组
.keyBy(data -> data.f0)
// 开窗函数 指定滚动事件时间窗口, 窗口大小为10秒
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 窗口函数 增量聚合函数 实现规约操作, 把每个人的点击数字相加, 得到每个人最终的点击次数
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return Tuple2.of(value1.f0,value1.f1 + value2.f1);
}
}).print();
env.execute();
}

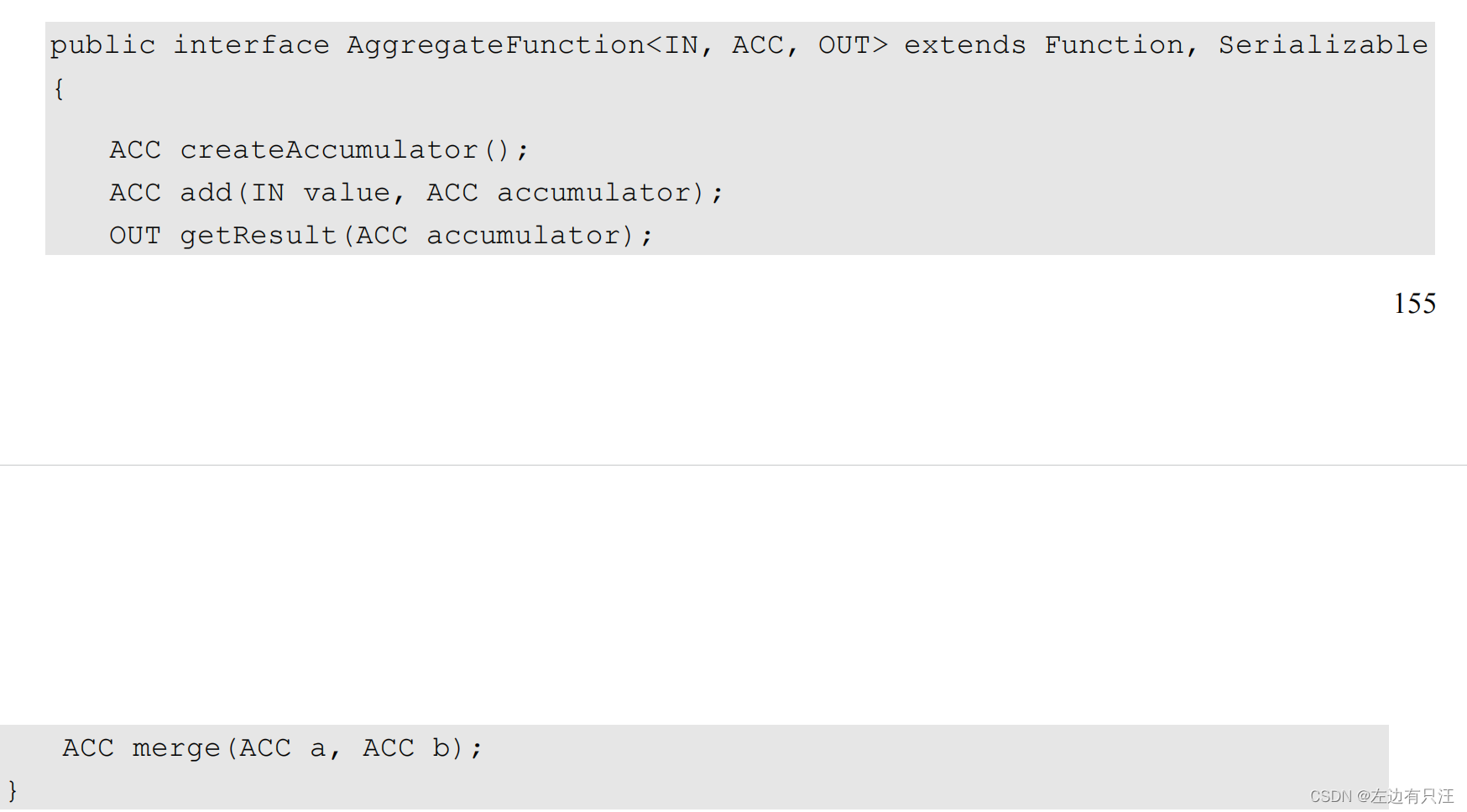
(2)聚合函数(AggregateFunction)重要



public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 设置水位线自动生成时间间隔为100ms 默认值是200ms
env.getConfig().setAutoWatermarkInterval(100L);
// 从自定义流中读取数据
DataStreamSource<Event> streamSource = env.addSource(new ClickSource());
// 乱序流watermark生成
SingleOutputStreamOperator<Event> stream = streamSource.assignTimestampsAndWatermarks(
// 设置水位线延时2秒
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2L))
// 设置水位线基于时间戳数据
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTimestamp) {
return event.getTimestamp();
}
})
);
// keyBy
stream.keyBy(date -> date.getUser())
// 开窗
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 三个参数, 第一个参数输入对象,
// 第二个参数累加器我们这里要求timestamp的平均, 所以一个是Long类型的timestamp的和 另一个是count,最后保存user
// 第三个参数,以什么样的形式返回, 我们需要user,平均数 这样的二元组返回
.aggregate(new AggregateFunction<Event, Tuple3<Long,Integer,String>, Tuple2<String,String>>() {
@Override
public Tuple3<Long, Integer,String> createAccumulator() {
// 创建一个累加器, 这里给一个初始值就行
return Tuple3.of(0L,0,"");
}
@Override
public Tuple3<Long, Integer,String> add(Event event, Tuple3<Long, Integer,String> accumulator) {
// 每来一个数据就要调用当前add方法, event当前到来的数据, accumulator当前累加器的状态
// 累加器add时, 我们需要把timestamp累加, 并把count + 1
return Tuple3.of(accumulator.f0 + event.getTimestamp(),accumulator.f1 + 1,event.getUser());
}
@Override
public Tuple2<String, String> getResult(Tuple3<Long, Integer,String> accumulator) {
// 获取最终结果, 把当前累加器中得到的数据计算成想要的结果
return Tuple2.of(accumulator.f2,new Timestamp(accumulator.f0/accumulator.f1).toString());
}
@Override
public Tuple3<Long, Integer,String> merge(Tuple3<Long, Integer,String> accumulator1, Tuple3<Long, Integer,String> accumulator2) {
// 合并两个累加器, 在会话窗口有实际意义, 这里是滚动窗口, 不实现也可以
return Tuple3.of(accumulator1.f0+accumulator2.f0, accumulator2.f1 + accumulator2.f1, accumulator1.f2);
}
}).print();
env.execute();
}
public static void main(String[] args) throws Exception {
// 开窗统计pv和uv, 两者相除得到平均用户活跃度
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置全局并行度
env.setParallelism(1);
// 设置自动水位线生成时间间隔为100ms
env.getConfig().setAutoWatermarkInterval(100);
DataStreamSource<Event> stream = env.addSource(new ClickSource());
// 设置串行流的时间戳
SingleOutputStreamOperator<Event> operator = stream.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTime) {
return event.getTimestamp();
}
}));
operator.print();
// 所有数据放在一起统计
operator.keyBy(data -> true)
// 设置一个基于事件时间的滑动窗口, 窗口大小为10s 偏移量为2s , 每隔2s统计一次上10s的数据情况
.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(2)))
.aggregate(new MyAggregate())
.print();
env.execute();
}
// 自定义一个AggregateFunction, 用long保存pv个数, 用hashset做uv去重
public static class MyAggregate implements AggregateFunction<Event, Tuple2<Long, HashSet<String>>,Double>{
@Override
public Tuple2<Long, HashSet<String>> createAccumulator() {
return Tuple2.of(0L,new HashSet<>());
}
@Override
public Tuple2<Long, HashSet<String>> add(Event event, Tuple2<Long, HashSet<String>> accumulator) {
// 每来一条数据, pv个数+1 将user放入HashSet中
accumulator.f1.add(event.getUser());
return Tuple2.of(accumulator.f0 + 1,accumulator.f1);
}
@Override
public Double getResult(Tuple2<Long, HashSet<String>> accumulator) {
// 窗口结束时., 输出pv和uv的比值, 这里有可能会有除0的风险, 实际开发中需要判断
return (double)accumulator.f0/accumulator.f1.size();
}
@Override
public Tuple2<Long, HashSet<String>> merge(Tuple2<Long, HashSet<String>> longHashSetTuple2, Tuple2<Long, HashSet<String>> acc1) {
return null;
}
}


- 全窗口函数(full window functions)批处理思路攒一波最后计算

(1)窗口函数(WindowFunction)不推荐使用
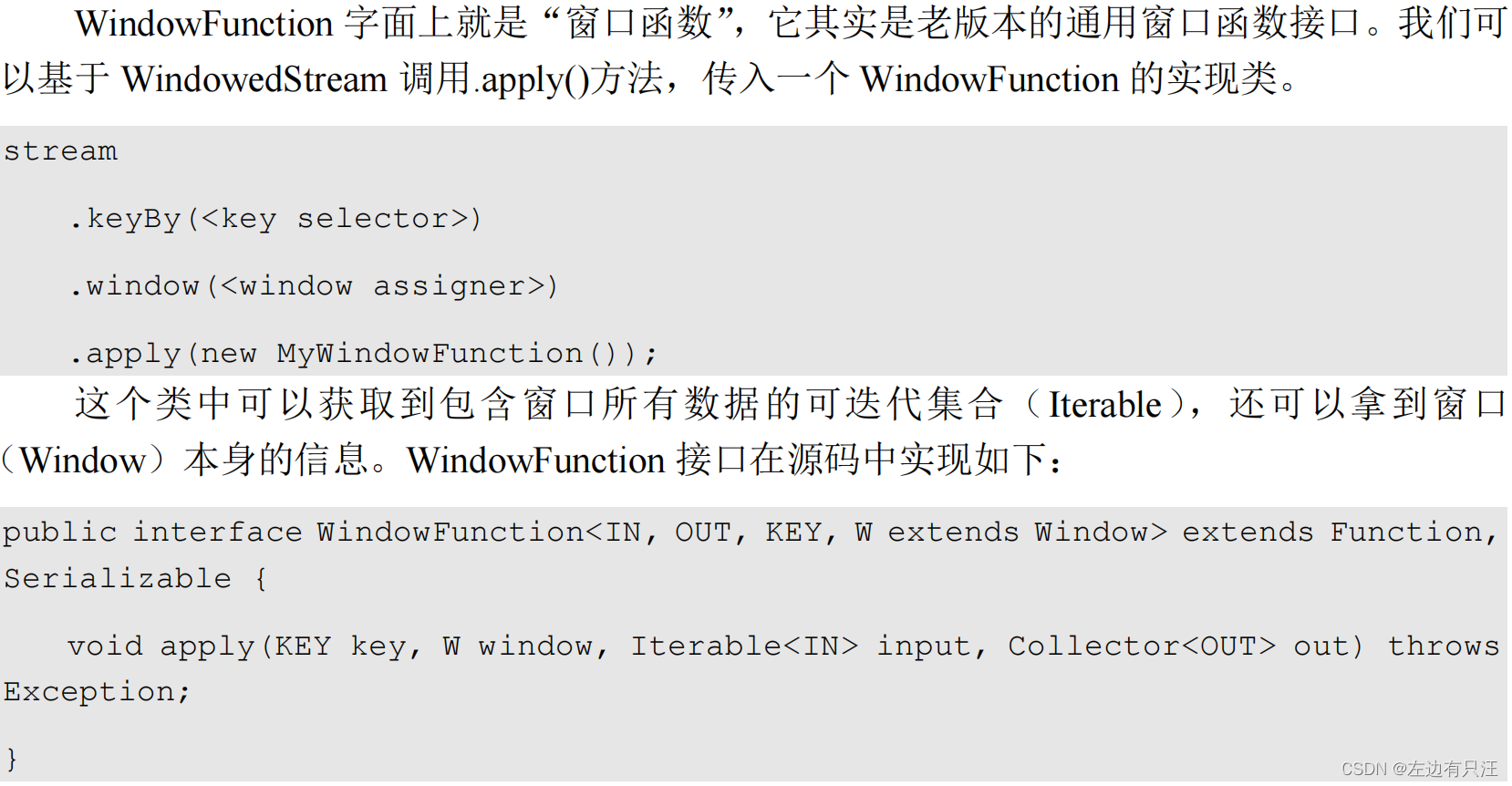

(2)处理窗口函数(ProcessWindowFunction)推荐使用


public static void main(String[] args) throws Exception {
// 开窗统计pv和uv, 两者相除得到平均用户活跃度
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置全局并行度
env.setParallelism(1);
// 设置自动水位线生成时间间隔为100ms
env.getConfig().setAutoWatermarkInterval(100);
DataStreamSource<Event> stream = env.addSource(new ClickSource());
// 设置串行流的时间戳
SingleOutputStreamOperator<Event> operator = stream.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTime) {
return event.getTimestamp();
}
}));
operator.print();
// 使用processWindowFunction计算uv
operator.keyBy(data -> true)
// 设置一个基于事件时间的滑动窗口, 窗口大小为10s 偏移量为2s , 每隔2s统计一次上10s的数据情况
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new MyProcessWindowFunction())
.print();
env.execute();
}
public static class MyProcessWindowFunction extends ProcessWindowFunction<Event, String,Boolean, TimeWindow> {
@Override
public void process(Boolean key, Context context, Iterable<Event> in, Collector<String> out) throws Exception {
// 用一个HashSet保存user
HashSet<String> userSet = new HashSet<>();
// 从in中遍历数据, 放入userSet
for (Event event : in) {
userSet.add(event.getUser());
}
Long uv = (long) userSet.size();
// 结合窗口信息输出
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect("窗口"+new Timestamp(start) + "~" + new Timestamp(end) + "uv值为" + uv );
}
}

- 增量聚合和全窗口函数的结合使用

在aggregate和processWindowFunction一起使用时, aggregate的返回值会传递processWindowFunction的输入Iterable中
public static void main(String[] args) throws Exception {
// 开窗统计pv和uv, 两者相除得到平均用户活跃度
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置全局并行度
env.setParallelism(1);
// 设置自动水位线生成时间间隔为100ms
env.getConfig().setAutoWatermarkInterval(100);
DataStreamSource<Event> stream = env.addSource(new ClickSource());
// 设置串行流的时间戳
SingleOutputStreamOperator<Event> operator = stream.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTime) {
return event.getTimestamp();
}
}));
operator.print();
// 使用aggregate和processWindowFunction结合计算uv
operator.keyBy(data -> true)
// 设置一个基于事件时间的滑动窗口, 窗口大小为10s 偏移量为2s , 每隔2s统计一次上10s的数据情况
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new MyAggregate(),new MyProcessWindowFunction())
.print();
env.execute();
}
// 自定义实现processWindowFunction, 包装窗口信息输出
public static class MyProcessWindowFunction extends ProcessWindowFunction<Integer, String,Boolean, TimeWindow> {
@Override
public void process(Boolean key, Context context, Iterable<Integer> in, Collector<String> out) throws Exception {
Integer uv =in.iterator().next();
// 结合窗口信息输出
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect("窗口"+new Timestamp(start) + "~" + new Timestamp(end) + "uv值为" + uv );
}
}
// 自定义一个AggregateFunction, 增量聚合计算uv值
public static class MyAggregate implements AggregateFunction<Event, HashSet<String>,Integer> {
@Override
public HashSet<String> createAccumulator() {
return new HashSet<>();
}
@Override
public HashSet<String> add(Event event, HashSet<String> accumulator) {
accumulator.add(event.getUser());
return accumulator;
}
@Override
public Integer getResult(HashSet<String> accumulator) {
return accumulator.size();
}
@Override
public HashSet<String> merge(HashSet<String> strings, HashSet<String> acc1) {
return null;
}
}


public static void main(String[] args) throws Exception {
// 开窗统计pv和uv, 两者相除得到平均用户活跃度
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置全局并行度
env.setParallelism(1);
// 设置自动水位线生成时间间隔为100ms
env.getConfig().setAutoWatermarkInterval(100);
DataStreamSource<Event> stream = env.addSource(new ClickSource());
// 设置串行流的时间戳
SingleOutputStreamOperator<Event> operator = stream.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTime) {
return event.getTimestamp();
}
}));
operator.print();
// 统计每个url的访问量
operator.keyBy(data -> data.getUrl())
// 设置一个基于事件时间的滑动窗口, 窗口大小为10s 偏移量为2s , 每隔2s统计一次上10s的数据情况
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new UrlViewCountAgg(),new UrlViewCountResult())
.print();
env.execute();
}
// 泛型 Long是输入是aggregate的结果, UrlViewCount是输出,我们需要输出一个自定义类,
// String是key的类型, 因为是根据url进行keyBy的, 所以是String类型, TimeWindow是当前开窗类型, 按时间进行开窗
public static class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount,String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Long> in, Collector<UrlViewCount> out) throws Exception {
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect(new UrlViewCount(key,in.iterator().next(),start,end));
}
}
// 泛型Event对象 累加器计算个数所以是Long 结果是Long类型
public static class UrlViewCountAgg implements AggregateFunction<Event, Long,Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event event, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long aLong, Long acc1) {
return null;
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public class UrlViewCount {
private String url;
private Long count;
private Long windowStart;
private Long windowEnd;
@Override
public String toString() {
return "UrlViewCount{" +
"url='" + url + '\'' +
", count=" + count +
", windowStart=" + new Timestamp(windowStart) +
", windowEnd=" + new Timestamp(windowEnd) +
'}';
}
}

6.3.6 其他API










6.3.7 Flink处理迟到数据
方式1: 设置 watermark 延迟时间,2 秒钟
方式2: 允许窗口处理迟到数据,设置 1 分钟的等待时间
方式3: 定义侧输出流并将最后的迟到数据输出到侧输出流
public static void main(String[] args) throws Exception {
// 开窗统计pv和uv, 两者相除得到平均用户活跃度
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置全局并行度
env.setParallelism(1);
// 设置自动水位线生成时间间隔为100ms
env.getConfig().setAutoWatermarkInterval(100);
DataStreamSource<String> stream = env.socketTextStream("hadoop102", 7777);
SingleOutputStreamOperator<Event> operator = stream.map(new MapFunction<String, Event>() {
@Override
public Event map(String event) throws Exception {
String[] split = event.split(",");
return new Event(split[0].trim(), split[1].trim(), Long.valueOf(split[2].trim()));
}
});
// 设置无序流的时间戳并给定waterMarks的延迟时间为2秒
// 处理迟到数据方式一:设置 watermark 延迟时间,2 秒钟
SingleOutputStreamOperator<Event> watermarks = operator
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2L))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTime) {
return event.getTimestamp();
}
}));
operator.print();
// 定义测输出流标签,注意这个地方需要指定一个匿名内部类, 否则会有泛型擦除问题
OutputTag<Event> late = new OutputTag<Event>("late"){};
// 统计每个url的访问量
SingleOutputStreamOperator<UrlViewCount> result = operator.keyBy(data -> data.getUrl())
// 设置一个基于事件时间的滑动窗口, 窗口大小为10s 偏移量为2s , 每隔2s统计一次上10s的数据情况
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 方式二:允许窗口处理迟到数据,设置 1 分钟的等待时间
.allowedLateness(Time.minutes(1))
// 方式三:将最后的迟到数据输出到侧输出流 注意需要定义侧输出流标签
.sideOutputLateData(late)
.aggregate(new UrlCountExample.UrlViewCountAgg(), new UrlCountExample.UrlViewCountResult());
result.print("result");
// 最后要把侧输出流的执行的操作绑定到窗口函数算子上
result.getSideOutput(late).print("late");
env.execute();
}
// 泛型 Long是输入是aggregate的结果, UrlViewCount是输出,我们需要输出一个自定义类,
// String是key的类型, 因为是根据url进行keyBy的, 所以是String类型, TimeWindow是当前开窗类型, 按时间进行开窗
public static class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount,String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Long> in, Collector<UrlViewCount> out) throws Exception {
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect(new UrlViewCount(key,in.iterator().next(),start,end));
}
}
// 泛型Event对象 累加器计算个数所以是Long 结果是Long类型
public static class UrlViewCountAgg implements AggregateFunction<Event, Long,Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event event, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long aLong, Long acc1) {
return null;
}
}