文件的判断是否存在,带上文件自己的名字

XmlSerializer
(Person)serializer.Deserialize(reader);
如果出错之后,没有try来接,就会直接程序报错暂停,
有了的话无论如何都会继续正常进final
using则是正常
为什么要用 using:
- 自动释放资源:
using语句保证了StreamReader或StreamWriter在使用完毕后会自动调用其Dispose()方法,释放相关资源,避免占用文件或内存。 - 减少错误:不用
using的话,你需要手动调用Dispose()或Close()方法,如果忘记了调用,资源可能会一直占用,这会导致文件无法访问或内存泄漏。 - 简洁代码:
using语句是一种简便的方式,在块结束时自动关闭资源,避免写额外的代码来管理资源的生命周期。
XmlSerializer 是 C# 中用于将对象序列化为 XML 格式,以及从 XML 格式反序列化为对象的类。它属于 System.Xml.Serialization 命名空间。这个类主要用于将对象的公共字段或公共属性转换为 XML,并可以从 XML 文件或字符串中恢复这些对象。
主要功能:
- 序列化:将对象转换为 XML 格式,方便存储或传输。
- 反序列化:将 XML 格式的数据转换回对象,方便在程序中使用。
适用场景:
- 用于数据持久化(将对象保存到文件中)。
- 在应用中传递或存储配置信息、数据。
- Web 服务中用于 XML 格式的数据交换。
使用示例:
假设我们有一个 Person 类,需要将其序列化为 XML 文件,并从文件中读取回来。
示例类:
using System;
using System.Xml.Serialization;
public class Person
{
public string Name { get; set; }
public int Age { get; set; } // XmlSerializer 需要一个无参数的构造函数
public Person() { }
public Person(string name, int age) { Name = name; Age = age; }
}
1. 序列化对象到 XML 文件:
using System;
using System.IO;
using System.Xml.Serialization;
class Program
{
static void Main()
{ // 创建一个对象
Person person = new Person("John Doe", 30);
// 创建 XmlSerializer 对象,指定要序列化的类型
XmlSerializer serializer = new XmlSerializer(typeof(Person));
// 使用 StreamWriter 写入 XML 到文件
using (StreamWriter writer = new StreamWriter("person.xml"))
{ serializer.Serialize(writer, person); }
Console.WriteLine("Person object serialized to XML file.");
}
}
2. 从 XML 文件反序列化为对象:
using System;
using System.IO;
using System.Xml.Serialization;
class Program
{
static void Main()
{ // 创建 XmlSerializer 对象
XmlSerializer serializer = new XmlSerializer(typeof(Person));
// 使用 StreamReader 从文件读取 XML
using (StreamReader reader = new StreamReader("person.xml"))
{ // 反序列化为 Person 对象
Person person = (Person)serializer.Deserialize(reader);
Console.WriteLine($"Name: {person.Name}, Age: {person.Age}"); }
}
}
关键点:
XmlSerializer只能序列化公共字段和属性。如果你不希望某些字段被序列化,可以使用[XmlIgnore]特性。- 需要序列化的类必须包含一个无参数的构造函数(即使是私有的)。
XmlSerializer不支持序列化字典类型,如果需要,你可以手动处理或使用其他替代方案。
序列化到字符串:
除了序列化到文件,你也可以将对象序列化到字符串或从字符串中反序列化。
using System;
using System.IO;
using System.Xml.Serialization;
class Program
{
static void Main()
{
Person person = new Person("Alice", 25);
XmlSerializer serializer = new XmlSerializer(typeof(Person));
// 序列化到字符串
using (StringWriter writer = new StringWriter())
{ serializer.Serialize(writer, person);
string xml = writer.ToString();
Console.WriteLine("Serialized XML:\n" + xml); }
// 字符串反序列化
string xmlData = "<Person><Name>Alice</Name><Age>25</Age></Person>";
using (StringReader reader = new StringReader(xmlData))
{ Person deserializedPerson = (Person)serializer.Deserialize(reader); Console.WriteLine($"Deserialized Person: {deserializedPerson.Name}, {deserializedPerson.Age}"); }
}
}
常用特性:
[XmlIgnore]:标记该字段或属性在序列化时被忽略。[XmlElement]:将字段或属性标记为 XML 元素,并可以自定义其名称。[XmlAttribute]:将字段或属性标记为 XML 属性,而不是元素。
public class Person
{
[XmlAttribute]
public string Name { get; set; }
[XmlElement("YearsOld")]
public int Age { get; set; }
[XmlIgnore]
public string SensitiveData { get; set; }
}
总结:
XmlSerializer非常适合用于数据持久化,尤其是当你需要将对象保存为 XML 格式时。- 它适用于轻量级 XML 数据交换,但对于更复杂的场景,可能需要考虑使用其他 XML 库或数据格式(如 JSON)。
StreamWriter
C# 中用于写入文本到文件或流中的一个类,属于 System.IO 命名空间。它可以将字符写入到文件、网络流等支持的各种流对象中,常用于保存数据到文件的操作。
功能:
- 写入字符串:
StreamWriter能够以文本的形式写入字符串到文件中。 - 自动编码:支持设置编码格式,默认为 UTF-8 编码。
- 缓冲区支持:使用内部缓冲区来提升写入性能,能高效处理大量数据。
关键点:
- 使用
StreamWriter时,通常会使用using语句 来确保写入操作完成后流会被正确关闭和释放资源。 - 它可以写入到任何支持流操作的对象,不仅仅限于文件。
示例:
using System.IO;
public class Example
{
public static void Main()
{ string filePath = "example.txt"; // 文件路径
// 创建 StreamWriter 对象,并写入文本
using (StreamWriter writer = new StreamWriter(filePath))
{ writer.WriteLine("Hello, World!");
writer.WriteLine("Writing to a file using StreamWriter.");
} // 关闭后,文本已经被写入到 example.txt 文件中
System.Console.WriteLine("Data written to file.");
}
}
StreamWriter 的构造函数:
StreamWriter(string path):通过文件路径创建一个StreamWriter对象,并写入文件。StreamWriter(Stream stream):将数据写入指定的流(如文件流、网络流等)。
常用方法:
Write(string value):写入字符串,但不换行。WriteLine(string value):写入字符串并自动换行。Flush():刷新缓冲区,将数据写入文件或流中。Close():关闭流并释放资源。
注意:
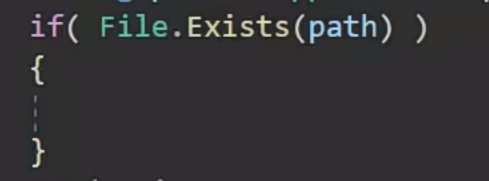
- 如果文件不存在,
StreamWriter会创建一个新文件。 - 如果文件已存在,默认会覆盖原有的内容。你可以通过指定
true参数来追加内容,例如new StreamWriter(path, true)。
总之,StreamWriter 是一个强大且常用的工具,用于处理文件写入操作,在进行文件读写操作时配合 StreamReader 类来读取文件内容。
Application.persistentDataPath
Application.persistentDataPath 是 Unity 提供的一个路径,用于存储需要持久化的数据。这是一个跨平台的解决方案,保证你的游戏在不同设备上都有一个可靠的路径来保存数据,并且这些数据不会在应用程序关闭或更新后丢失。
Windows:
Application.dataPath: 应用的appname_Data/
Application.streamingAssetsPath: 应用的appname_Data/StreamingAssets
Application.temporaryCachePath: C:\Users\username\AppData\Local\Temp\company name\product name
Application.persistentDataPath: C:\Users\username\AppData\LocalLow\company name\product name
————————————————版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_46472622/article/details/129583483
Application.dataPath:应用程序资源的根目录,常用于读取内置的资源文件,不适合写入。Application.streamingAssetsPath:专用于存储原始数据文件(如视频、音频、配置文件),应用中可以直接读取,但只读。Application.temporaryCachePath:临时文件的存储路径,适合缓存数据,操作系统可能会自动清除该目录。Application.persistentDataPath:持久化存储路径,用于保存需要长期保存的数据,数据在应用关闭后依然存在。
主要用途:
- 持久化存储:通常用于保存玩家的进度、设置、日志、游戏数据等。比如保存游戏的存档、玩家自定义设置、关卡进度等信息。
- 跨平台:
Application.persistentDataPath在不同的操作系统上会指向不同的位置。Unity 会根据目标平台(如 Android、iOS、Windows、Mac 等)选择合适的目录来存储数据。
具体平台上的路径:
- Windows:通常在
C:\Users\[Username]\AppData\LocalLow\[CompanyName]\[ProductName] - MacOS:在
/Users/[Username]/Library/Application Support/[CompanyName]/[ProductName] - Android:在
/data/data/[com.Company.Product]/files/ - iOS:在
~/Documents目录下
不同平台的路径会自动适应,所以开发者不需要手动判断路径,只需使用 Application.persistentDataPath 即可。
代码示例:
假设你想将玩家的分数存储到一个文本文件中:
csharp
复制代码
using System.IO; using UnityEngine; public class SaveManager : MonoBehaviour { public int playerScore = 100; void SavePlayerScore() { string filePath = Application.persistentDataPath + "/playerScore.txt"; // 获取持久化数据路径 File.WriteAllText(filePath, playerScore.ToString()); // 将分数写入文件 Debug.Log("数据已保存到: " + filePath); } void LoadPlayerScore() { string filePath = Application.persistentDataPath + "/playerScore.txt"; if (File.Exists(filePath)) { string scoreString = File.ReadAllText(filePath); playerScore = int.Parse(scoreString); Debug.Log("读取到的玩家分数: " + playerScore); } else { Debug.LogError("存档文件不存在!"); } } }
优点:
- 自动管理平台差异:不需要担心不同平台的存储路径差异,Unity 自动处理这些细节。
- 安全性:数据存储在应用专有的文件夹中,通常不会被其他应用程序访问或修改。
- 持久性:数据在应用关闭、重启后依然存在,除非用户手动删除应用或数据。
Application.persistentDataPath 是非常方便的工具,适合所有需要保存和读取玩家数据的场景。
using 语句
C# 语言的一个特性,专门用于管理资源的自动释放。它的主要作用是确保实现了 IDisposable 接口的对象在使用完毕后会自动调用 Dispose 方法,释放资源,比如文件、网络连接等。
using 语句的作用:
- 自动释放资源:在
using块结束时,StreamWriter(或其他实现了IDisposable的对象)的Dispose方法会被自动调用。这意味着不需要手动写代码去释放资源,减少了内存泄漏或资源占用的风险。 - 简洁性:它是简化资源管理的便捷方式,避免了需要手动写
try-finally块去释放资源。
示例解释:
using (StreamWriter writer = new StreamWriter(path))
{ writer.WriteLine("Hello, World!"); } // 在这里,StreamWriter 会被自动关闭和释放资源
在这个例子中,StreamWriter 是用于写入文件的类。通过 using 语句,确保当程序执行完 using 块时,writer 对象会被关闭和释放,即使在块内出现异常。
传统做法:
如果不用 using 语句,你通常需要这样做:
StreamWriter writer = null;
try { writer = new StreamWriter(path); writer.WriteLine("Hello, World!"); }
finally { if (writer != null) { writer.Dispose(); } }
using 语句就是对这种模式的简化,它自动帮你处理 try-finally 和 Dispose。
总结来说,using 是 C# 的标准功能,用来简化资源管理,特别适合需要显式释放资源的情况。
什么时候用这种语法?
- 资源清理:你希望确保某些资源(如文件、数据库连接、网络流等)在使用完毕后始终被正确释放,即使发生了错误。这时候,
try-finally是标准做法。
为什么用 finally 而不是 catch?
catch捕获异常:如果你需要处理某个异常,避免程序崩溃,可以使用catch块。但它不一定总是需要。finally清理资源:无论程序是否有异常,资源都要被释放,所以finally是一个合适的地方来放置资源释放的代码。
using 语句的作用:
- 自动释放资源:在
using块结束时,StreamWriter(或其他实现了IDisposable的对象)的Dispose方法会被自动调用。这意味着不需要手动写代码去释放资源,减少了内存泄漏或资源占用的风险。 - 简洁性:它是简化资源管理的便捷方式,避免了需要手动写
try-finally块去释放资源。
XML
每个XML文档都有且只有一个根元素(Root Element)
第一行必须是XML的声明<?xml ?>
version:xml的版本,必须设定,当前只有'1.0'版本
encoding:当前xml里面的数据格式,默认UTF-8
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
standalone:标记是否是一个独立的xml,默认yes
如果设置 no 表示这个XML不是独立的而是依赖于外部的DTD约束文件(后面说)









Stream的中间方法



concat合并流,有父子关系要求






为什么值类型不用常量池
大坑,深奥的很
栈内存与堆内存的区别
-
栈内存:
- 栈内存用于存储方法的局部变量和调用时的上下文信息。
- 对于基本数据类型(如
int、float等),栈中的变量直接存储其值。这使得访问速度更快,因为栈的操作是 LIFO(后进先出)结构,效率高。 - 当方法调用结束时,栈中的局部变量会被自动释放,不会产生额外的垃圾回收开销。
-
堆内存:
- 堆内存用于存储对象(如字符串、数组、类实例等)。
- 堆内存中的对象是通过
new关键字创建的,并且可能会涉及到复杂的内存管理(如垃圾回收)。 - 字符串和其他引用类型可以共享同一内存地址,从而节省内存,这就是常量池的用武之地。
常量池的作用
- 字符串常量池:Java 使用字符串常量池来优化内存使用。相同内容的字符串字面量会被存储在常量池中,并被共享。例如,多个
String对象指向同一个常量池中的字符串内容。 - 常量池主要用于管理引用类型的内存,特别是字符串。它的设计目的是为了减少重复存储相同字符串的开销。
基本数据类型不需要常量池
- 直接值存储:基本数据类型的直接值存储在栈中,而不是引用。这使得它们不需要常量池来管理内存。每个变量都有自己的值,快速且高效。
- 性能优化:由于基本数据类型的操作简单且频繁,直接存储在栈中可以提高访问速度,减少不必要的内存管理开销。
基本数据类型的特点
-
大小固定:基本数据类型的大小是固定的,例如
int通常占用 4 字节,float占用 4 字节,double占用 8 字节。这种固定的内存占用使得直接存储其值在性能上没有显著的负担。 -
简单性:基本数据类型的操作相对简单,不涉及复杂的内存管理。每个变量在栈中都有独立的值,而不需要关注引用和共享的问题。
栈的高效管理
-
栈内存管理:栈内存的分配和释放是由系统自动管理的,采用 LIFO(后进先出)策略。当一个方法调用时,栈帧会被创建,方法结束后自动释放。栈的操作效率高,因此在性能上不会成为瓶颈。
-
局部性原则:栈内存中的局部变量在方法调用时创建,方法结束时释放,这样的内存管理方式符合局部性原理(即数据的局部性),在大多数情况下不需要频繁分配和释放内存。
避免复杂的共享逻辑
- 避免冲突:如果基本数据类型使用缓存池,可能会引入共享问题。在多线程环境中,多个线程可能会同时访问和修改同一个缓存值,导致数据一致性问题。而直接存储在栈中的值是独立的,避免了这种复杂性。
内存开销考量
- 相对较小的内存占用:虽然每次方法调用都会开辟新的栈空间,但基本数据类型的内存占用相对较小(例如 4 字节),在内存使用上并不会显著增加开销。此外,栈空间通常比堆空间小得多,允许大量的局部变量使用。
与引用类型的对比
- 引用类型的内存管理:对于引用类型(如对象),使用缓存和共享是合理的,因为对象可能需要在不同地方复用,从而节省内存。Java 的字符串常量池就是一种优化手段,避免创建多个相同内容的字符串对象。
- 基本数据类型直接存储在栈内存中,无需缓存池,因其固定大小和简单性使得这种设计高效且直观。
- 栈的自动管理机制和方法调用的局部性原则使得内存开销相对较小,不会造成显著的性能问题。
为什么new的字符串!=常量池
值类型不能new,所有都是直接用常量池里的
但是值类型不用常量池
对于基本数据类型,Java 不使用常量池,而是直接在栈中存储值。
是因为string是引用类型才这样设计!而int这些值类型则可以直接相等,不管地址类型,因为都是直接使用缓存池里的数据
- 你不能使用
new关键字直接创建基本数据类型的实例。基本数据类型是值类型,直接存储其值。 - 你可以使用
new关键字创建相应的包装类对象(如Integer、Float),并且可以利用自动装箱来简化代码。 - 使用包装类时,可能会涉及到内存开销和性能考虑,因为包装类是对象,存储在堆内存中,而基本数据类型是直接存储在栈内存中。
内容会引用,但是判断相等的时候又不等于?这样设计干嘛
在 Java 中,字符串的比较有两个方面:
- 引用比较(使用
==):判断两个引用是否指向同一个对象。 - 内容比较(使用
.equals()):判断两个字符串的内容是否相同。
a. 性能和内存优化
- 常量池的使用:常量池机制使得相同字符串值的实例共享内存,节省内存。这在很多情况下提高了性能,尤其是当程序中频繁使用相同字符串时。
- 新对象创建:使用
new String(...)创建字符串时,总是会得到一个新的对象,这对于某些特定场景(如需要确保每次都有独立实例的情况)是有用的。
b. 灵活性
- 不变性:字符串在 Java 中是不可变的。通过引用和内容的分开比较,程序员可以在需要时明确知道对象的来源和内存使用。不可变性意味着字符串一旦创建,其内容不能更改,这使得字符串在多线程环境中更加安全。
c. 控制和明确性
- 明确性:程序员可以选择是比较引用还是比较内容,这提供了更大的控制能力。例如,在需要快速判断两个对象是否是同一个实例时,可以使用
==。而在需要验证两个字符串的实际内容是否一致时,可以使用.equals()。 - 创建新的实例:某些情况下,可能希望每次都创建新的字符串实例,以便于不影响其他引用或进行特定操作(如在算法中)。
常量池的都是常量,new的字符串是贴在变量上的,
常量池的字面量是不变的,他们贴在池子上,只是因为的确可能会写很多遍一样的字符串,而且这些字符串内容又不变(换句话说,这些字面量不变),所以搞个池子,装这些标签
可以把常量池里的字符串(别的也可以)看做一个武器制作书,上面写了要怎么做,
每次new的字符串,是贴在变量上的制作书(玩家可操控),也就是说,这些是可变,他们随时可以换别的制作书去制作武器,
但是制作书反反复复就是那么几套,每个玩家都可以选不同的,也可以选相同的制作书,
如果是选相同的,然后两个玩家偏要把一份已存的制作书(常量池里)复制成两份制作书,
然后再分别让自己的变量制作书再copy,难道不是多此一举中的多此一举?
正因为太显而易见,所以比较难发现哪里不太懂,可是理清楚这个又是很必要的
即使我第一次new“123”,常量池里也没有“123”,str!="123"
直接使用 new 关键字创建字符串
当你执行以下代码:
String str = new String("123");
这里的步骤是:
- Java首先会在字符串常量池中查找是否已经存在
"123"。 - 如果常量池中不存在
"123",Java会将这个字面量"123"存储到常量池中。 - 不论常量池中是否存在
"123",都会在堆内存中创建一个新的String对象,并将这个对象的引用赋值给变量str。
内存中的状态
- 常量池中有一份
"123"(如果它之前不存在的话)。 - 堆内存中有一份新的
String对象,内容也是"123"。
使用 == 和 equals() 比较
str == "123"会返回false,因为str引用的是堆内存中的新对象,而不是常量池中的"123"。str.equals("123")会返回true,因为它们的内容相同。
字符串常量池
1. 字符串池机制
-
当你在代码中声明一个字符串,如
"123",这个字符串会被存入字符串池,它是一个常量池,用于优化内存的使用。字符串池确保相同的字符串值在内存中只有一份。 -
例如:
String str1 = "123"; -
String str2 = "123";在这种情况下,
str1和str2都会指向字符串池中同一个"123"实例。换句话说,它们共享同一块内存地址,不会为每个字符串创建新的对象。
2. 字符串池的生命周期
-
在Java:池中存储的字符串是常量,只要程序运行,池中字符串就不会被移除或释放。它们存在整个 JVM 生命周期中,直到程序结束。
-
C#的字符串池:与Java类似,字符串的驻留(interning)机制确保相同的文字字符串指向同一个实例。C#中可以使用
String.Intern()方法来手动控制字符串是否驻留在字符串池中。
3. 字符串创建方式的区别
-
当你使用**字面量(literal)**声明字符串时,例如
String str = "123";,字符串会被放入字符串池。 -
当你使用
new关键字创建字符串时,例如String str = new String("123");,这会强制 JVM 在堆上创建一个新的字符串对象,即使该字符串值已经存在于字符串池中。
4. 字符串池的优点
- 内存优化:字符串池机制减少了重复的字符串实例,节省内存。
- 性能提升:由于池中的字符串是共享的,比较两个字符串的引用(例如
str1 == str2)比逐字符比较更快。
5. 不要的字符串是否会从池中移除
- 通常字符串一旦进入字符串池,它就不会被移除。池中的字符串是常驻内存的,垃圾回收机制不会移除它们,除非JVM被终止或是整个应用生命周期结束。
总结
- 是的,当你写了一个字符串字面量(如
"123"),它会被加入到字符串池中。 - 当你后续再使用相同的字面量(如
"123"),它会直接从字符串池中复用,不会再次创建新的内存空间。 - 池中的字符串不会轻易移除,也不会被垃圾回收,它们会一直存在,直到程序结束。
Stream流
Map不能直接stream,但是通过.keyset和.values和.entryset可以用

Collection<E>提供的方法


原本要遍历然后挑出满足条件的再存到新集合,现在用stream就可以直接通过filter和collect流成新的对象

拿一个新list类型对象去接就可以了
原来的遍历会强调遍历的细节,而现在则是直接的过程