人工智能咨询培训老师叶梓 转载标明出处
多模态学习正成为连接不同类型数据(如图像、文本、音频等)的桥梁。随着深度学习技术的发展,多模态模型在理解和处理跨领域数据方面表现出了显著的效能。来自普渡大学、混沌工业公司、斯坦福大学和亚马逊的研究人员共同撰写了一篇论文,题为《多模态模型架构的演进》(The Evolution of Multimodal Model Architectures),该论文系统地识别并描述了当代多模态领域中普遍存在的四种多模态模型架构模式。
四种多模态模型架构

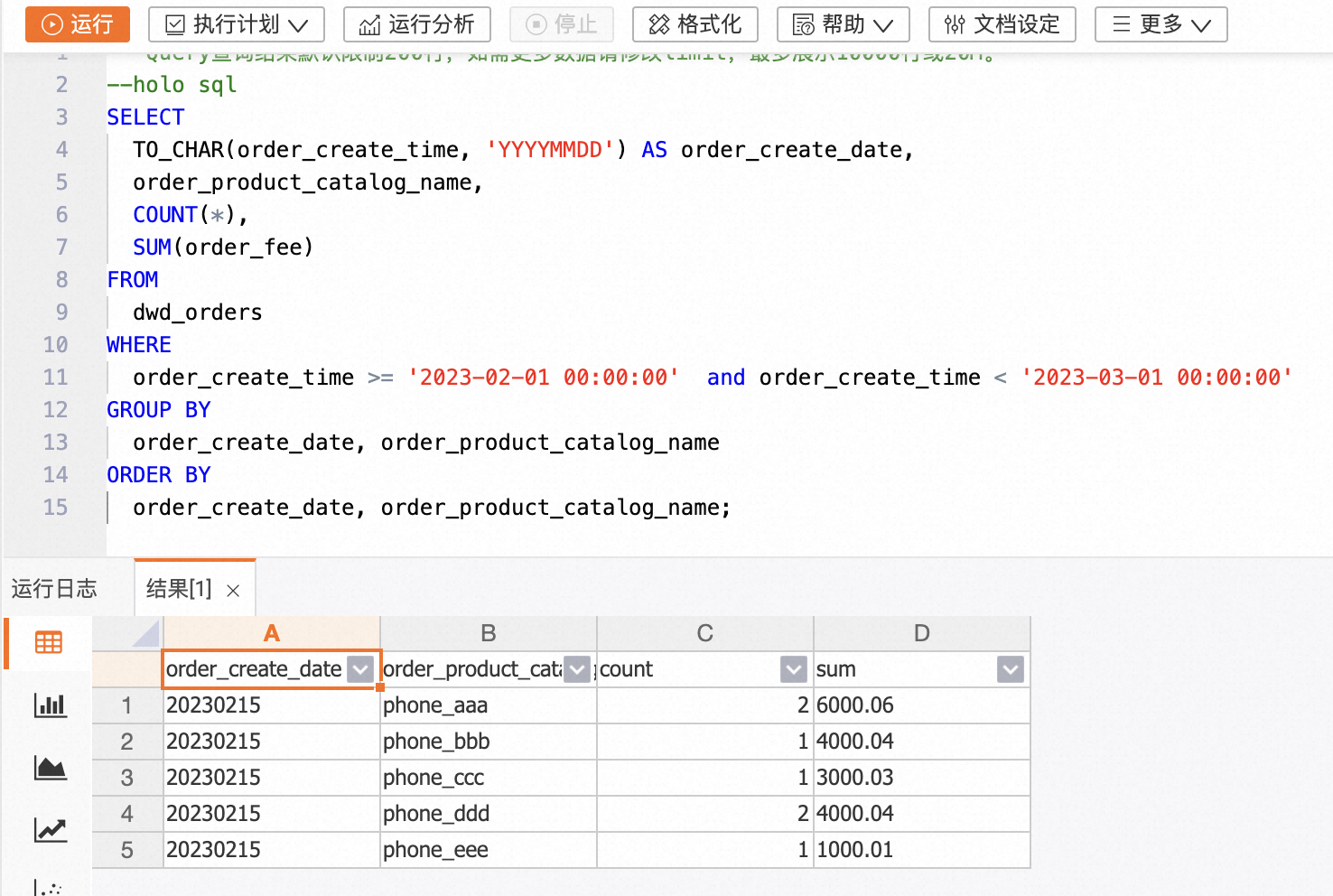
图1展示了四种不同的多模态架构类型及其子类型。两种总体类别分别是:深度融合(Deep Fusion),在模型的内部层次中发生模态的融合;以及早期融合(Early Fusion),以模型输入阶段的模态融合为特征。每种类别中又观察到两个主要的集群。在深度融合领域中,模态与内部层次的整合体现在:类型A(Type-A)采用标准的交叉注意力层,而类型B(Type-B)则使用定制设计层。相反,在早期融合领域中,多模态输入主要有两种形式:非标记化的多模态输入作为类型C(Type-C),以及离散标记化的多模态输入作为类型D(Type-D)。
想要掌握如何将大模型的力量发挥到极致吗?2024年10月26日叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。
留言“参加”即可来叶老师的直播间互动,1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。互动交流,畅谈工作中遇到的实际问题。
类型A(Type-A):基于标准交叉注意力的深度融合(SCDF)
在多模态模型架构的研究中,类型A代表了一种深度融合的方法,其中模态信息在模型的内部层次中进行融合。这种架构主要利用了标准的交叉注意力层来实现这一点。图 3清晰地展示了类型A多模态模型的架构,其中输入模态通过特定的编码器进行处理,然后通过重采样器输出固定数量的模态(视觉/音频/视频)标记,这些标记随后被送入LLM(大模型)的内部层中,使用标准的交叉注意力层进行深度融合。

图 3 类型A多模态模型架构展示了输入模态如何被深度融合到LLM的内部层中。交叉注意力层可以在自注意力层之前(子类型A.1)或之后(子类型A.2)添加。模态特定的编码器处理不同的输入模态,并且使用重采样器来输出固定数量的模态(视觉/音频/视频)标记,以适应解码器层的要求。
子类型A.1
子类型A.1的模型在LLM的每个自注意力层之前都设有交叉注意力层。例如,Flamingo模型及其衍生模型通常属于这种架构子类型。这些模型通常涉及预训练的大模型,并集成了标准的交叉注意力层,以实现输入模态的深度融合。
子类型A.2
子类型A.2则包含了标准的编码器-解码器变换器架构,每个解码器中的自注意力层后都设有交叉注意力层。这种架构通常不使用重采样器。例如,VL-BART和VL-T5模型就是基于这种架构子类型。
类型B(Type-B):基于定制层的深度融合(CLDF)
类型B架构使用预训练的大模型、可学习的线性层/MLP/Q-former、定制的交叉注意力层或定制层以及模态编码器构建。与类型A不同的是,类型B使用定制设计层而不是标准交叉注意力层。例如,LLaMA-Adapter-V2模型在交叉注意力层的输出上添加了可学习嵌入,然后才将交叉注意力层的输出与自注意力层的输出进行添加/连接。

图 4 类型B多模态模型架构展示了如何使用定制设计层将输入模态深度融合到LLM的内部层中。这种架构允许更细粒度地控制模态信息如何在模型内部流动,并且可以根据需要进行定制,以适应特定的模态融合需求。
类型C(Type-C):非标记化的早期融合(NTEF)
类型C架构是将模态编码器的输出直接在模型的输入端进行融合,而不是在模型的内部层中。这种架构的特点是简单且易于训练。例如,图 5展示了类型C多模态模型的架构,其中输入模态直接在模型的输入端进行早期融合。不同类型的模块被用来将模态编码器的输出连接到LLM,例如线性层/MLP(子类型C.1)、Q-former和线性层/MLP(子类型C.2)、Perceiver重采样器(子类型C.3)以及定制的可学习层(子类型C.4)。

图 5 类型C多模态模型架构突出了非标记化输入模态如何直接被送入模型的输入端,而不是其内部层,从而实现早期融合。这种架构允许使用现成的大模型和编码器,而无需对它们的内部架构进行重大更改。
类型D(Type-D):标记化的早期融合(TEF)
在类型D中,多模态输入通过通用分词器或模态特定的分词器进行标记化。标记化的输入随后被送入预训练的大模型或编码器-解码器变换器模型,生成多模态输出。图 6展示了类型D多模态模型架构的一般情况,其中标记化的输入模态直接被送入模型的输入端。这种架构允许模型以自回归的方式进行训练,以生成图像、音频和不同模态的标记以及文本标记。

图 6 类型D多模态模型架构展示了标记化输入模态如何直接被送入模型的输入端。这种架构可以使用仅解码器的变换器(子类型D.1)或编码器-解码器风格的变换器(子类型D.2)作为多模态变换器。
这些架构类型为多模态模型的设计和开发提供了清晰的分类和指导,有助于研究人员和开发者根据具体的应用需求选择合适的模型架构。
四种多模态模型架构类型的优劣势
类型A (Type-A)
类型A架构能够细粒度控制模态信息在模型中的流动,并且是端到端可训练的。使用标准的变换器层,例如交叉注意力层,来融合模态,而不是设计定制层。然而,这种架构需要大量的训练数据样本和计算资源。与类型B和类型C相比,构建这种架构的模型更具挑战性,需要对大模型的内部层有深入的理解。此外,添加新的模态非常困难,因为一旦在大模型层中添加了图像模态交叉注意力层,就难以再向每个大模型层添加其他模态。
类型B (Type-B)
类型B架构同样能够细粒度控制模态信息的流动,并且是端到端可训练的。与类型A不同,类型B使用了定制设计层,这增加了模态融合的控制能力。这种架构相比类型A更易于扩展,因为它的定制层设计更有效,计算效率更高。但是,与类型C相比,扩展性可能仍然是一个挑战。类型B通过引入门控机制简化了添加更多模态的过程,这使得直接将输入模态添加到输出大模型层成为可能。
类型C (Type-C)
类型C架构是模块化的,可以轻松替换模型架构的部分,并且新模型可以高效地训练用于多模态任务。与类型A和类型B不同,类型C没有对模态信息流动进行细粒度控制,不同模态的输入仅在解码器(大模型)的输入端融合。这种架构易于构建,因为它不需要详细了解大模型的内部层,只需要了解新集成的大模型或编码器的接口细节。类型C架构易于扩展,添加更多模态也相对容易。
类型D (Type-D)
类型D架构由于输入和输出模态的标记化而具有简化的模型架构。标记化所有模态提供了通过标准自回归目标函数进行所有模态训练的优势。然而,这也带来了训练通用分词器或模态特定分词器的挑战。与类型A和类型B不同,类型D没有对模态信息流动进行细粒度控制,不同模态的输入仅在主变换器模型的输入端融合。这种架构易于构建,并且由于模态的标记化,它是可扩展的。然而,添加额外的模态需要为每个新模态训练新的分词器或适应现有的多模态分词器,这可能是一个复杂的任务。
下一代多模态架构

图 7 展示了从单一模态模型到任何模态模型的发展时间线。类型C和类型D的任何到任何多模态模型在图中被注明。
下一代多模态架构的发展聚焦于提升模型处理多样化输入输出的能力。类型C和类型D架构是当前研究的热点,分别通过预训练组件的集成和输入标记化来简化训练过程。类型C架构如Next-GPT和CoDI,无需分词器即可生成多模态输出,而类型D架构如Unified-IO和4M,利用分词器实现多模态输出,简化了训练目标函数。然而,类型D在处理大规模数据和计算需求方面仍面临挑战。
除了端到端可训练的模型,结合类型C与代理的方法也为多模态模型提供了新的视角,如ModaVerse所示。这种方法通过生成特定文本输出来辅助其他模态的生成,尽管它不是端到端可训练的,但也展现了潜力。
另外状态空间模型(SSMs)作为基于变换器模型的有力补充,正在被探索用于解决注意力机制中的二次复杂性问题。VL-Mamba和Cobra等模型展示了SSMs在多模态学习中的潜力,预示着SSMs可能成为未来任何到任何多模态任务的强有力架构。这些新兴架构的发展,不仅推动了多模态模型的进化,也为解决多模态生成的挑战提供了新思路。
https://arxiv.org/pdf/2405.17927




![[翻译]MOSIP Blue Book](https://i-blog.csdnimg.cn/direct/d2190e82daba4e81a940e426f9c9262a.png)