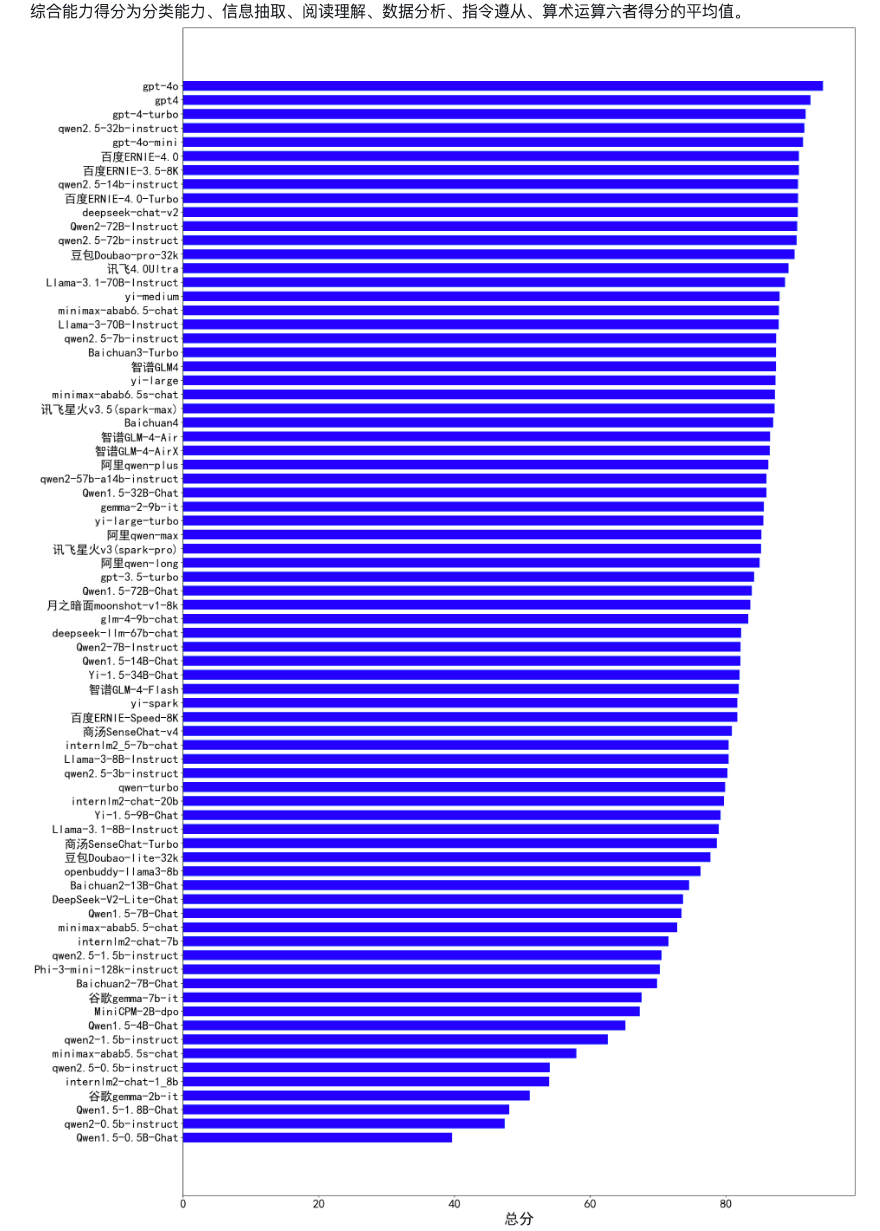
摘要
文档级关系提取旨在对文档中任意两个实体之间的关联进行分类。以往的文档级关系提取方法在充分利用不同噪声水平的大量训练数据的潜力方面是无效的。例如,在ReDocRED基准数据集中,在大规模、低质量、远距离监督的训练数据上训练的最先进的方法通常不会比那些仅在较小、高质量、人工注释的训练数据上训练的方法表现得更好。为了充分释放大规模噪声训练数据在文档级关系提取方面的潜力,我们提出了TTM-RE,一种新的方法,集成了可训练内存模块,称为令牌图灵机,与噪声鲁棒损失函数来解释正未标记设置。在用于文档级关系提取的基准数据集ReDocRED上进行的大量实验表明,TTM-RE达到了最先进的性能(F1的绝对分数提高了超过3%)。消融研究进一步说明了TTM-RE在其他领域(生物医学领域的化学诊断基因数据集)和在高度未标记的设置下的优越性。
一、引言
借鉴了记忆增强模型方面的最新进展中,提出了TTM-RE,这是专门为文档级关系提取而设计的初始内存增强架构。通过经验证据,证明了这种架构能够显著增强对来自经验观察的广泛的遥远标记数据的微调。具体来说,添加来自TTM(Ryoo et al.,2023),通过允许对头部和尾部实体进行再处理,同时共同考虑学习到的记忆标记,增强了下游关系分类(见图1)。

- 提出了第一个记忆增强的TTM-RE文档级关系提取模型。通过合并伪实体,它显著提高了在ReDocRED(+3 F1评分)和ChemDisGene (+5 F1评分)等数据集上的下游关系分类性能。
- 在没有任何人类标记数据的情况下,TTM-RE在看不见数据上取得了令人印象深刻的关系提取性能(+9 F1分数)。此外,在一个非常无监督的场景中(19%的训练标签),TTM-RE比之前的SOTA表现得更好(+12 F1分数)。
- 对模型进行消融分析,检查了TTM-RE在更少、更频繁的关系类中的性能,评估了内存大小、图层大小和不同基模型的使用的影响。
二、模型
提出了TTM-RE,一种内存增强的、文档级的关系提取方法。图2显示了TTM-RE的总体框架的示意图。

2.1 问题定义
在任务公式中,我们检查了一个文档,它包括
个句子
、N个实体
和
个关系类。给定该文档
和一个指定的实体对
,目标是基于从文档中获得的信息来预测实体对之间的一组正相关关系
。需要注意的是,每个实体可能在文档
中出现多次,并且需要考虑每个可能的实体-实体对(例如,如果n个实体,我们需要考虑
种可能的关系)。
2.2 Token Turning Machine(令牌图灵机)
内存,表示为,由
个token的集合组成,每个token的维数为d。输入由
表示的n个token组成,与内存
组合。然后对这个连接的输入进行进一步处理,生成一个表示为
的输出,其中
表示所需的检索token的数量。从这个过程中得到的输出,与前面的输入和当前内存结合起来,构成TTM的输出。在我们的例子中,
,
为头部和尾部实体。
令牌图灵机(Token Turning Machines)以令牌的形式增加了对外部内存的支持(图2 内存模块(Memory Module))。在令牌图灵机(TTM)中,处理单元和内存之间的接口纯粹是通过“读”和“写”操作来完成的。请注意,在最初的论文中,处理单元的输出被“写入(written)”到内存中,但在我们的例子中,由于我们不是按顺序应用这个模型,我们可以忽略这个步骤,只关注读取(reading)部分。
初始化内存令牌(Initializing Memory Tokens):我们遵循TTM的原始实现,并从头开始初始化内存令牌,但有一个主要的区别。当原始代码从零初始化令牌时,我们发现这导致了缺乏梯度更新。因此,我们从一个正态分布进行初始化,以便学习改进。请注意,我们不能简单地使用实体文本嵌入,因为内存层是在所有的处理步骤之后,而且只在最终的分类层之前。我们发现这种设置是最好的经验,但对记忆层的放置仍需要进一步的研究。
从内存中读取(Reading from Memory):虽然内存是为了封装模型认为重要的浓缩信息,但并非所有这些数据都是相关的。此外,输入中的冗余,表示为,可能是由于已经存储在内存中的信息
或数据本身固有的信息。如果只考虑少量token的选择性阅读,那么应该鼓励模型创建一个包含整个关系分类任务中相关信息的存储库。
通过构建一个token集合来推导一个重要权重向量,即
来,我们利用它来计算n个标记的加权聚合。值得注意的是,每个输出标记,索引为
拥有相应的权重
,使用一个可学习的函数计算,取输入
本身,记为
。这个重要加权函数是通过多层感知器(MLP)来实现的,被定义为
。
随后,这些权重有助于对输入的加权总和。设是我们希望分析的输入token的通用词表。对于我们的具体情况,它是内存token
和输入token
的拼接,即
。让我们获得编码的token
,其中每个标记
在动态加权法
的指导下,有效地压缩了全部
中的所有token。当该模型学习将p个token总结为r个token时,它生成一个矩阵
,其中包含相对于记忆标记的重要性权重。此外,为了允许模型读取位置,利用位置内存token,并将他们与输入标记去分开,在每个读取模块(reading module)之前都有一个可以学习的位置嵌入(positional embedding)。所有的这些都可以在一个内存读取函数中获取:
其中,是拼接的内存M和输入I,
,在我们的实例中,我们设置了r = 2来学习记忆增强的头
和尾
实体的头和尾实体关系分类问题。
2.3 头、尾实体的加工
在检索了我们的记忆增强头和尾
实体后,我们使用了组双线性方法来减少参数的数量,以实现更有效的学习。每个实体被分割成维度为
的k个部分,
表示双线性层,乘积之和表示分组的双线性层。这减少了
的参数,并获得更好的性能。
此外,最终输出是维数R+1(所有关系的预测向量来学习阈值),因为采用Zhou等人(2021b)实现的自适应阈值方法,其他最近的文档级别关系抽取也这样做了。
2.4 噪声-鲁棒损耗函数(SSR-PU)
在标记的关系三元组中存在大量的假否定。Gao等人(2023)证明了学习忽略零镜头提示的假阴性,揭示了提示llm进行文档关系提取的困难。为了解决这个问题,我们采用正无标记(PU)学习,如Wang等人(2022b)(Plessis等人,2015;du Plessis等人,2014)。

普通的PU学习假设总体分布与未标记数据的分布相同,这在我们的情况下可能不正确。为了解决这个问题,需要考虑之前训练数据转移下的PU学习(特征法克迪和杉山,2019)。对于每个类,假设原始先前的.让和
其中
或
表示第i类标签或者未标记。
未标记数据下的阳性样本的条件概率为:
训练数据在类先验偏移下的非负风险估计结果如下:
其中,表示类别
的正类先验概率。
是类别i的正类样本数量,
是未标记样本的数量。
是一个凸损失函数,
是预测类别
的评分函数。
和
分别表示类别
的第
个样本是正类和未标记的样本。
三、实验
略
四、结果
主要结果
表3展示了我们实验的主要结果。我们看到,只有人工标注的数据集的表现与当前最先进的结果(DREEAM 和 SSR-PU)处于同一水平。然而,在另外两种设置下,即远程监督和人工+远程监督的组合情况下,TTM-RE 在考虑标准差(分别为 +9 F1 和 +3 F1)的情况下,显著超越了其他方法。这表明,即使在存在噪声的大规模训练数据中,我们的模型也更为有效。比如远距离监督的训练数据集。这在直觉上是有意义的,因为内存标记是从头开始初始化的,并且将从更大规模的训练数据中获益更多。进一步的研究应该寻求改善记忆令牌的初始化,这可能导致更快的训练和进一步的性能提高。

最后,我们观察到,即使在使用远程监督和人工注释的数据进行训练后,其他基线通常也没有显著改善,这可能是由架构限制造成的。值得注意的是,这意味着TTM-RE的内存模块增加了实际上非常有用的处理能力(第5节向我们展示了一个例子,其中添加更多的参数没有帮助)。
ChemDisGene结果 表4显示,TTM-RE确实可以转化为一般任务之外的其他领域,比最佳基线提高了5 F1点。我们观察到TTM-RE在人类标注的训练数据上表现良好。这可能是因为ChemDisGene有一个更大的训练数据集,因此可以更有效地学习记忆标记,因此与ReDocRED完全监督的设置相比,它不会对性能产生负面影响。

之前的工作已经表明,添加一个内存结构在长尾或不平衡的类分类问题上具有更好的性能。我们通常可以在表5中看到这种现象,因为在前10个标签和其他数据上的差异在4 F1和4.5 F1左右。这种差异在前5名中更为明显,因为我们看到了分别为3.5 F1和5.5 F1的差异。这表明基线模型在不常见的类上表现稍差,而TTM-RE的内存组件可以帮助缓解这种性能下降。
极度无标记数据集:Wang等人(2022b)引入了一个“极度无标记”的场景,将训练标签减少到只有原始标签的19%。我们还在ReDocRED(Wang et al.,2022b)中原始训练三组的极未标记设置(19%)上评估了我们的模型(表6)。我们再次看到,在完全监督下,TTM-RE并不比基线更好,但当允许对远端监督数据进行训练时,它比最佳基线增加到12个F1点。我们假设这是由于更好地学习罕见的类,如表5所示。

内存令牌大小:在图4中,当增加READ模块和令牌图灵机的内存令牌大小时,我们通常可以看到模型性能(F1、精度和Ign F1)的提高。虽然由于计算限制,我们在4层和200个令牌停止,但这一趋势是有希望的,因为它表明还有潜在的性能改进探索在未来的努力中,尽管需要增加的计算资源。


使用DebertaV3作为基础模型:最重要的是,所有的基线通常都依赖于罗伯塔大作为基础模型。我们还探索使用3大,提出一个更多的速度和强大的模型由于其更大的参数计数和更高的性能灰色板凳马克(改进包括解开,增强解码层(He等人,2020),和预训练(He等,2021))。然而,从表7中,我们可以看到,对于文档RE,令人惊讶的是,它并没有提高性能。由于这一观察结果,TTM-RE也使用了Roberta-large。此外,这还演示了一个情况,即天真地添加参数并不能帮助提高关系分类性能,而添加内存机制则可以。
五、讨论
内存模块分析
令牌图灵机(TTM)的内存模块在大型训练集上表现最佳。这引出了一个重要问题:还有哪些应用可以提供如此广泛的训练数据?虽然 TTM 确实受益于大型数据集,但潜在的应用包括自然语言处理(NLP)或计算机视觉领域的任何任务。此外,这些数据集不一定需要人工标注。例如,DocRED 数据集是通过使用维基百科和 spaCy 进行命名实体识别(NER)和关系链接,结合 Wikidata,进行远程监督的。类似的方法可以用于为特定任务创建数据集。TTM-RE 已经展示了在使用这些远程监督数据集时,性能相比其他基线有所提高。
数据集大小
我们假设性能与数据集的大小相关。值得注意的是,TTM-RE 在 ChemDisGene 数据集上未经过相关数据集微调的情况下,也优于基线方法。考虑到人工标注的 ReDocRED 数据集仅包含 3,053 份文档,而远程监督数据集包含 101,873 份,ChemDisGene 数据集包含 76,942 份文档,内存机制可能需要一定程度的微调才能完全发挥其效用。这表明需要进一步的研究来找到更有效的优化内存机制的方法。然而,未来的工作还需全面探讨这一现象。
六、结论
在本文中,我们探讨了 TTM-RE,结合了 TTM 的关系分类,并在 ReDocRED 和 ChemDisGene 关系抽取数据集上对我们的模型进行了评估。总结我们的贡献,以前的工作没有在远程监督的设置中探讨内存。因此,TTM-RE 展示了一种全新的提高文档级关系抽取任务性能的方法,这与以往主要改进损失函数的工作(如 Zhou 等人,2021a;Wang 等人,2022b)形成对比。在这项工作中,我们通过消融实验得出了有力的结果,表明增加内存标记/层的数量能够提高相对于基线的性能,而不是单纯使用更大的模型(如 Deberta V3)。表 5 也展示了相对于前 10 个标签(它们占据了数据集的 62%),在较少表示的标签上取得的改进。此外,我们在图 4 中展示了,随着我们增加更多的内存标记,性能持续提升。
我们还观察到,TTM 需要在大型远程标记的数据集上进行微调,或在一个显著大的人工标注数据集(如 ChemDisGene)上优化内存向量的初始化。我们相信这项工作将为未来在这一令人兴奋的领域的研究提供方向,并希望我们的发现能够为未来在信息抽取任务中探索内存增强技术的研究铺平道路。
限制
虽然我们研究了多种不同的大型语言模型(LLM)和参数,以及关系预测的类型分布,并解决了假阳性问题,但与在相同任务上使用监督方法相比,我们所取得的性能仍然有限。尽管 TTM-RE 能够利用远程监督数据,关系预测仍然需要大量的数据。未来的工作应寻求将标签数据创建与当前最先进的文档关系抽取模型相结合,以提高对人工标注的效率。
伦理声明
基于我们目前采用的方法,我们没有预见到任何重大的伦理问题。我们研究中使用的所有文档和模型均来自开源领域,确保了信息来源的透明和可访问性。此外,TTM-RE 仅使用纯粹的开源文档关系抽取数据进行训练,消除了隐私泄露的风险。此外,关系抽取任务在各种自然语言处理应用中是一个广泛认可和深入研究的问题。
然而,必须承认一个较小的因素,即我们分析中使用的预训练语言模型可能存在潜在的隐藏偏见。这些偏见可能源于模型训练时使用的数据,可能无意中引入了隐含的人类偏见。虽然我们使用这些预训练语言模型能够识别任意实体之间的关系,但如果探索敏感的关系类别和实体,可能会出现偏见。
部分写作使用了 ChatGPT 和 Grammarly。总体来说,预训练过程花费了超过 75 小时,在 NVIDIA RTX A6000 上完成。主要的障碍是所有模型在远程监督微调阶段的训练,原因在于数据集的规模。为研究目的而访问的数据的衍生物不应用于研究环境之外。代码将发布在 https://github.com/chufangao/TTM-RE。







![[Git] Git下载及使用 从入门到精通 详解(附下载链接)](https://i-blog.csdnimg.cn/direct/0f99f4f2c6c94b699828ef50f9528028.png)