0、快速访问
论文阅读笔记:Denoising Diffusion Implicit Models (1)
论文阅读笔记:Denoising Diffusion Implicit Models (2)
论文阅读笔记:Denoising Diffusion Implicit Models (3)
论文阅读笔记:Denoising Diffusion Implicit Models (4)
论文阅读笔记:Denoising Diffusion Implicit Models (5)
5、接上文论文阅读笔记:Denoising Diffusion Implicit Models (4)
这里使用中的
σ
t
\sigma_t
σt是可以自己定义的量。有两种特殊的情况:
1、
σ
t
2
=
0
\sigma_t^2=0
σt2=0:此时,
x
t
−
1
x_{t-1}
xt−1满足公式(3)
x
t
−
1
=
α
t
−
1
⋅
x
t
−
1
−
α
t
⋅
z
t
α
t
+
1
−
α
t
−
1
−
σ
t
2
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
0
+
1
−
α
t
−
1
⋅
z
t
\begin{equation} \begin{split} x_{t-1}&=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{1-\alpha_{t-1}-\sigma_t^2}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot x_0+\sqrt{1-\alpha_{t-1}}\cdot z_t \\ \end{split} \end{equation}
xt−1=αt−1⋅αtxt−1−αt⋅zt+1−αt−1−σt2⋅zt+σt2ϵt=αt−1⋅x0+1−αt−1⋅zt
x
t
−
n
x_{t-n}
xt−n满足
x
t
−
n
=
α
t
−
n
⋅
x
t
−
1
−
α
t
⋅
z
t
α
t
+
1
−
α
t
−
n
−
σ
t
2
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
n
⋅
x
0
+
1
−
α
t
−
n
⋅
z
t
\begin{equation} \begin{split} x_{t-n}&=\sqrt{\alpha_{t-n}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{1-\alpha_{t-n}-\sigma_t^2}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-n}}\cdot x_0+\sqrt{1-\alpha_{t-n}}\cdot z_t \\ \end{split} \end{equation}
xt−n=αt−n⋅αtxt−1−αt⋅zt+1−αt−n−σt2⋅zt+σt2ϵt=αt−n⋅x0+1−αt−n⋅zt
可以看出,此时,
x
t
−
1
x_{t-1}
xt−1和
x
t
−
n
x_{t-n}
xt−n退化成上文论文阅读笔记:Denoising Diffusion Implicit Models (2)中的Lemma 1.
2、
σ
t
2
=
1
−
α
t
−
1
1
−
α
t
⋅
(
1
−
α
t
α
t
−
1
)
\sigma_t^2=\frac{1-\alpha_{t-1}}{1-\alpha_t}\cdot (1-\frac{\alpha_t}{\alpha_{t-1}})
σt2=1−αt1−αt−1⋅(1−αt−1αt):此时,
x
t
−
1
x_{t-1}
xt−1满足公式(4)
x
t
−
1
=
α
t
−
1
⋅
x
t
−
1
−
α
t
⋅
z
t
α
t
+
1
−
α
t
−
1
−
σ
t
2
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
−
1
−
α
t
⋅
z
t
α
t
+
1
−
α
t
−
1
−
1
−
α
t
−
1
1
−
α
t
⋅
(
1
−
α
t
α
t
−
1
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
−
1
−
α
t
⋅
z
t
α
t
+
(
1
−
α
t
−
1
)
(
1
−
1
1
−
α
t
⋅
α
t
−
1
−
α
t
α
t
−
1
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
−
1
−
α
t
⋅
z
t
α
t
+
(
1
−
α
t
−
1
)
α
t
−
1
−
α
t
−
1
⋅
α
t
−
α
t
−
1
+
α
t
α
t
−
1
⋅
(
1
−
α
t
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
−
1
−
α
t
⋅
z
t
α
t
+
(
1
−
α
t
−
1
)
−
α
t
−
1
⋅
α
t
+
α
t
α
t
−
1
⋅
(
1
−
α
t
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
−
1
−
α
t
⋅
z
t
α
t
+
(
1
−
α
t
−
1
)
α
t
α
t
−
1
⋅
(
1
−
α
t
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
α
t
−
α
t
−
1
1
−
α
t
⋅
z
t
α
t
+
(
1
−
α
t
−
1
)
α
t
α
t
−
1
⋅
(
1
−
α
t
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
α
t
−
(
α
t
−
1
1
−
α
t
⋅
α
t
−
1
1
−
α
t
−
(
1
−
α
t
−
1
)
⋅
α
t
⋅
α
t
α
t
⋅
α
t
−
1
⋅
(
1
−
α
t
)
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
α
t
−
(
α
t
−
1
1
−
α
t
⋅
α
t
−
1
1
−
α
t
−
(
1
−
α
t
−
1
)
⋅
α
t
⋅
α
t
α
t
⋅
α
t
−
1
⋅
(
1
−
α
t
)
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
α
t
−
(
α
t
−
1
⋅
(
1
−
α
t
)
−
(
1
−
α
t
−
1
)
⋅
α
t
α
t
⋅
α
t
−
1
⋅
(
1
−
α
t
)
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
α
t
−
(
α
t
−
1
−
α
t
⋅
α
t
−
1
−
α
t
+
α
t
⋅
α
t
−
1
α
t
⋅
α
t
−
1
⋅
(
1
−
α
t
)
)
⋅
z
t
=
α
t
−
1
⋅
x
t
α
t
−
(
α
t
−
1
−
α
t
α
t
⋅
α
t
−
1
⋅
(
1
−
α
t
)
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
⋅
x
t
α
t
−
(
α
t
−
1
⋅
(
α
t
−
1
−
α
t
)
α
t
−
1
⋅
α
t
⋅
(
1
−
α
t
)
)
⋅
z
t
+
σ
t
2
ϵ
t
=
α
t
−
1
α
t
(
x
t
−
α
t
−
1
−
α
t
α
t
−
1
⋅
1
−
α
t
)
+
σ
t
2
ϵ
t
=
α
t
−
1
α
t
(
x
t
−
1
1
−
α
t
⋅
(
1
−
α
t
α
t
−
1
)
)
⋅
z
t
+
σ
t
2
ϵ
t
=
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
)
⋅
z
t
+
σ
t
2
ϵ
t
(换成
D
D
P
M
中的符号)
\begin{equation} \begin{split} x_{t-1}&=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{1-\alpha_{t-1}-\sigma_t^2}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{1-\alpha_{t-1}-\frac{1-\alpha_{t-1}}{1-\alpha_t}\cdot (1-\frac{\alpha_t}{\alpha_{t-1}})}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{(1-\alpha_{t-1})(1-\frac{1}{1-\alpha_t}\cdot \frac{\alpha_{t-1}-\alpha_t}{\alpha_{t-1}})}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{(1-\alpha_{t-1})\frac{\alpha_{t-1}-\alpha_{t-1}\cdot \alpha_{t}-\alpha_{t-1}+\alpha_t}{\alpha_{t-1}\cdot(1-\alpha_{t})}}\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+\sqrt{(1-\alpha_{t-1})\frac{-\alpha_{t-1}\cdot \alpha_{t}+\alpha_t}{\alpha_{t-1}\cdot(1-\alpha_{t})}}\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t-{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+(1-\alpha_{t-1})\sqrt{\frac{\alpha_t}{\alpha_{t-1}\cdot(1-\alpha_{t})}}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}}-\frac{\sqrt{\alpha_{t-1}}{\sqrt{1-\alpha_t}\cdot z_t}}{\sqrt{\alpha_t}}+(1-\alpha_{t-1})\sqrt{\frac{\alpha_t}{\alpha_{t-1}\cdot(1-\alpha_{t})}}\cdot z_t + \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\sqrt{\alpha_{t-1}}{\sqrt{1-\alpha_t}}\cdot\sqrt{\alpha_{t-1}}{\sqrt{1-\alpha_t}}-(1-\alpha_{t-1})\cdot\sqrt{\alpha_t}\cdot\sqrt{\alpha_t}}{\sqrt{\alpha_t}\cdot \sqrt{\alpha_{t-1}\cdot(1-\alpha_t)}} \Bigg)\cdot z_t+ \sigma_t^2 \epsilon_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\sqrt{\alpha_{t-1}}{\sqrt{1-\alpha_t}}\cdot\sqrt{\alpha_{t-1}}{\sqrt{1-\alpha_t}}-(1-\alpha_{t-1})\cdot\sqrt{\alpha_t}\cdot\sqrt{\alpha_t}}{\sqrt{\alpha_t}\cdot \sqrt{\alpha_{t-1}\cdot(1-\alpha_t)}}\Bigg)\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\alpha_{t-1}\cdot({1-\alpha_t)}-(1-\alpha_{t-1})\cdot \alpha_t}{\sqrt{\alpha_t}\cdot \sqrt{\alpha_{t-1}\cdot(1-\alpha_t)}} \Bigg)\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\alpha_{t-1}-\bcancel{\alpha_t\cdot \alpha_{t-1}}-\alpha_t+\bcancel{\alpha_t\cdot \alpha_{t-1}}}{\sqrt{\alpha_t}\cdot \sqrt{\alpha_{t-1}\cdot(1-\alpha_t)}} \Bigg)\cdot z_t \\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\alpha_{t-1}-\alpha_t}{\sqrt{\alpha_t}\cdot \sqrt{\alpha_{t-1}\cdot(1-\alpha_t)}} \Bigg)\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\sqrt{\alpha_{t-1}}\cdot\frac{x_t}{\sqrt{\alpha_t}} -\Bigg(\frac{\sqrt{\alpha_{t-1}}\cdot (\alpha_{t-1}-\alpha_t)}{\alpha_{t-1}\cdot\sqrt{\alpha_t}\cdot \sqrt{(1-\alpha_t)}} \Bigg)\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\frac{\sqrt{\alpha_{t-1}}}{\sqrt{\alpha_{t}}}\Bigg(x_t-\frac{\alpha_{t-1}-\alpha_t}{\alpha_{t-1}\cdot\ \sqrt{1-\alpha_t}}\Bigg) + \sigma_t^2 \epsilon_t\\ &=\frac{\sqrt{\alpha_{t-1}}}{\sqrt{\alpha_{t}}}\Bigg(x_t-\frac{1}{\ \sqrt{1-\alpha_t}}\cdot (1-\frac{\alpha_t}{\alpha_{t-1}})\Bigg)\cdot z_t + \sigma_t^2 \epsilon_t\\ &=\frac{1}{\sqrt{\alpha_{t}}}\Bigg(x_t-\frac{\beta_t}{\ \sqrt{1-\bar\alpha_t}}\Bigg)\cdot z_t + \sigma_t^2 \epsilon_t(换成DDPM中的符号)\\ \end{split} \end{equation}
xt−1=αt−1⋅αtxt−1−αt⋅zt+1−αt−1−σt2⋅zt+σt2ϵt=αt−1⋅αtxt−1−αt⋅zt+1−αt−1−1−αt1−αt−1⋅(1−αt−1αt)⋅zt+σt2ϵt=αt−1⋅αtxt−1−αt⋅zt+(1−αt−1)(1−1−αt1⋅αt−1αt−1−αt)⋅zt+σt2ϵt=αt−1⋅αtxt−1−αt⋅zt+(1−αt−1)αt−1⋅(1−αt)αt−1−αt−1⋅αt−αt−1+αt⋅zt+σt2ϵt=αt−1⋅αtxt−1−αt⋅zt+(1−αt−1)αt−1⋅(1−αt)−αt−1⋅αt+αt⋅zt+σt2ϵt=αt−1⋅αtxt−1−αt⋅zt+(1−αt−1)αt−1⋅(1−αt)αt⋅zt+σt2ϵt=αt−1⋅αtxt−αtαt−11−αt⋅zt+(1−αt−1)αt−1⋅(1−αt)αt⋅zt+σt2ϵt=αt−1⋅αtxt−(αt⋅αt−1⋅(1−αt)αt−11−αt⋅αt−11−αt−(1−αt−1)⋅αt⋅αt)⋅zt+σt2ϵt=αt−1⋅αtxt−(αt⋅αt−1⋅(1−αt)αt−11−αt⋅αt−11−αt−(1−αt−1)⋅αt⋅αt)⋅zt+σt2ϵt=αt−1⋅αtxt−(αt⋅αt−1⋅(1−αt)αt−1⋅(1−αt)−(1−αt−1)⋅αt)⋅zt+σt2ϵt=αt−1⋅αtxt−(αt⋅αt−1⋅(1−αt)αt−1−αt⋅αt−1
−αt+αt⋅αt−1
)⋅zt=αt−1⋅αtxt−(αt⋅αt−1⋅(1−αt)αt−1−αt)⋅zt+σt2ϵt=αt−1⋅αtxt−(αt−1⋅αt⋅(1−αt)αt−1⋅(αt−1−αt))⋅zt+σt2ϵt=αtαt−1(xt−αt−1⋅ 1−αtαt−1−αt)+σt2ϵt=αtαt−1(xt− 1−αt1⋅(1−αt−1αt))⋅zt+σt2ϵt=αt1(xt− 1−αˉtβt)⋅zt+σt2ϵt(换成DDPM中的符号)
可以看出,此时,DDIM退化成了DDPM。
论文讨论了
σ
t
2
\sigma_t^2
σt2选取
η
⋅
1
−
α
t
−
1
1
−
α
t
⋅
(
1
−
α
t
α
t
−
1
)
,
η
∈
[
0
,
1
]
\eta\cdot \frac{1-\alpha_{t-1}}{1-\alpha_t}\cdot (1-\frac{\alpha_t}{\alpha_{t-1}}),\eta\in[0,1]
η⋅1−αt1−αt−1⋅(1−αt−1αt),η∈[0,1],即在0和DDPM之间变化时。不同
η
\eta
η以及跳不同步时所对应的表现,如下图所示。
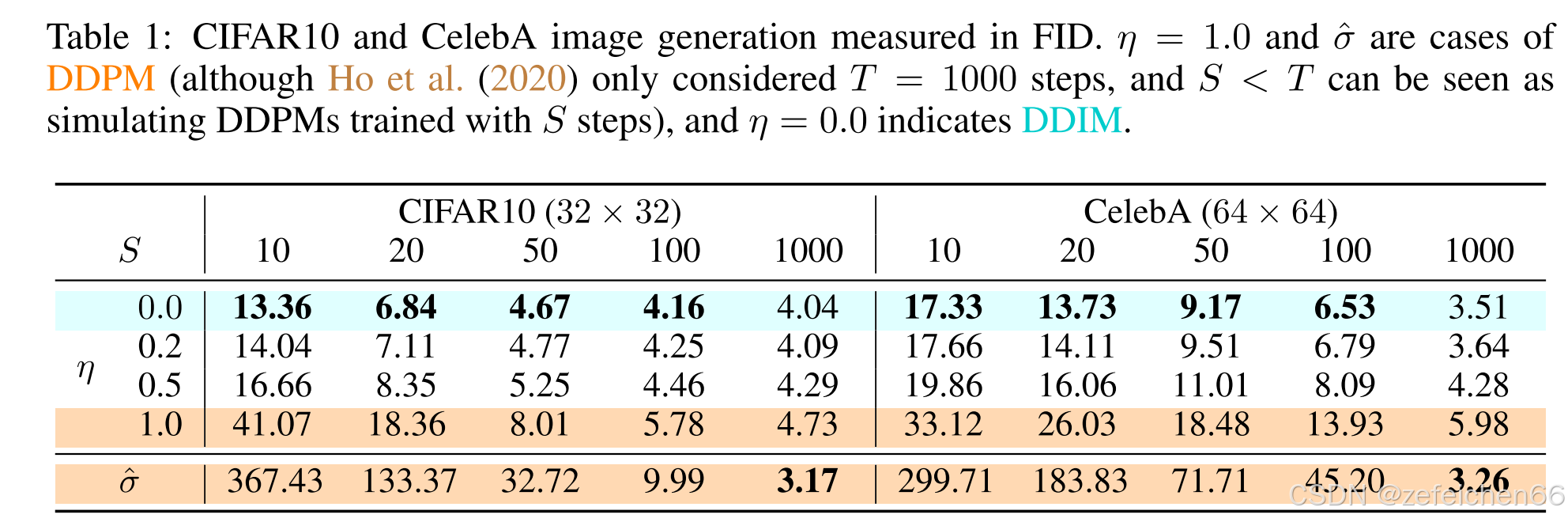
6、代码
class DDIMPipeline(DiffusionPipeline):
model_cpu_offload_seq = "unet"
def __init__(self, unet, scheduler):
super().__init__()
# make sure scheduler can always be converted to DDIM
scheduler = DDIMScheduler.from_config(scheduler.config)
self.register_modules(unet=unet, scheduler=scheduler)
@torch.no_grad()
def __call__(
self,
batch_size: int = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
eta: float = 0.0,
num_inference_steps: int = 50,
use_clipped_model_output: Optional[bool] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
) -> Union[ImagePipelineOutput, Tuple]:
# Sample gaussian noise to begin loop
if isinstance(self.unet.config.sample_size, int):
image_shape = (
batch_size,
self.unet.config.in_channels,
self.unet.config.sample_size,
self.unet.config.sample_size,
)
else:
image_shape = (batch_size, self.unet.config.in_channels, *self.unet.config.sample_size)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
# 随即生成噪音
image = randn_tensor(image_shape, generator=generator, device=self._execution_device, dtype=self.unet.dtype)
# 设置步数间隔。例如num_inference_steps = 50,然而总步长为1000,那么就是每次跳20步,例如在当前时刻, timestep=980, prev_timestep=960
self.scheduler.set_timesteps(num_inference_steps)
for t in self.progress_bar(self.scheduler.timesteps):
# 1. 预测出timestep=980时刻对应噪音
model_output = self.unet(image, t).sample
# 2. 调用scheduler的方法step,执行公式()得到prev_timestep=960时刻的图像
image = self.scheduler.step(
model_output, t, image, eta=eta, use_clipped_model_output=use_clipped_model_output, generator=generator
).prev_sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
class DDIMScheduler(SchedulerMixin, ConfigMixin):
_compatibles = [e.name for e in KarrasDiffusionSchedulers]
order = 1
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
beta_start: float = 0.0001,
beta_end: float = 0.02,
beta_schedule: str = "linear",
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
clip_sample: bool = True,
set_alpha_to_one: bool = True,
steps_offset: int = 0,
prediction_type: str = "epsilon",
thresholding: bool = False,
dynamic_thresholding_ratio: float = 0.995,
clip_sample_range: float = 1.0,
sample_max_value: float = 1.0,
timestep_spacing: str = "leading",
rescale_betas_zero_snr: bool = False,
):
if trained_betas is not None:
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
elif beta_schedule == "linear":
self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
elif beta_schedule == "scaled_linear":
# this schedule is very specific to the latent diffusion model.
self.betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
elif beta_schedule == "squaredcos_cap_v2":
# Glide cosine schedule
self.betas = betas_for_alpha_bar(num_train_timesteps)
else:
raise NotImplementedError(f"{beta_schedule} is not implemented for {self.__class__}")
# Rescale for zero SNR
if rescale_betas_zero_snr:
self.betas = rescale_zero_terminal_snr(self.betas)
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
# At every step in ddim, we are looking into the previous alphas_cumprod
# For the final step, there is no previous alphas_cumprod because we are already at 0
# `set_alpha_to_one` decides whether we set this parameter simply to one or
# whether we use the final alpha of the "non-previous" one.
self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
# standard deviation of the initial noise distribution
self.init_noise_sigma = 1.0
# setable values
self.num_inference_steps = None
self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy().astype(np.int64))
def scale_model_input(self, sample: torch.Tensor, timestep: Optional[int] = None) -> torch.Tensor:
"""
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
current timestep.
Args:
sample (`torch.Tensor`):
The input sample.
timestep (`int`, *optional*):
The current timestep in the diffusion chain.
Returns:
`torch.Tensor`:
A scaled input sample.
"""
return sample
def _get_variance(self, timestep, prev_timestep):
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
return variance
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
def _threshold_sample(self, sample: torch.Tensor) -> torch.Tensor:
"""
"Dynamic thresholding: At each sampling step we set s to a certain percentile absolute pixel value in xt0 (the
prediction of x_0 at timestep t), and if s > 1, then we threshold xt0 to the range [-s, s] and then divide by
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
https://arxiv.org/abs/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
if dtype not in (torch.float32, torch.float64):
sample = sample.float() # upcast for quantile calculation, and clamp not implemented for cpu half
# Flatten sample for doing quantile calculation along each image
sample = sample.reshape(batch_size, channels * np.prod(remaining_dims))
abs_sample = sample.abs() # "a certain percentile absolute pixel value"
s = torch.quantile(abs_sample, self.config.dynamic_thresholding_ratio, dim=1)
s = torch.clamp(
s, min=1, max=self.config.sample_max_value
) # When clamped to min=1, equivalent to standard clipping to [-1, 1]
s = s.unsqueeze(1) # (batch_size, 1) because clamp will broadcast along dim=0
sample = torch.clamp(sample, -s, s) / s # "we threshold xt0 to the range [-s, s] and then divide by s"
sample = sample.reshape(batch_size, channels, *remaining_dims)
sample = sample.to(dtype)
return sample
def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
"""
Sets the discrete timesteps used for the diffusion chain (to be run before inference).
Args:
num_inference_steps (`int`):
The number of diffusion steps used when generating samples with a pre-trained model.
"""
if num_inference_steps > self.config.num_train_timesteps:
raise ValueError(
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"
f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
f" maximal {self.config.num_train_timesteps} timesteps."
)
self.num_inference_steps = num_inference_steps
# "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = (
np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps)
.round()[::-1]
.copy()
.astype(np.int64)
)
elif self.config.timestep_spacing == "leading":
step_ratio = self.config.num_train_timesteps // self.num_inference_steps
# creates integer timesteps by multiplying by ratio
# casting to int to avoid issues when num_inference_step is power of 3
timesteps = (np.arange(0, num_inference_steps) * step_ratio).round()[::-1].copy().astype(np.int64)
timesteps += self.config.steps_offset
elif self.config.timestep_spacing == "trailing":
step_ratio = self.config.num_train_timesteps / self.num_inference_steps
# creates integer timesteps by multiplying by ratio
# casting to int to avoid issues when num_inference_step is power of 3
timesteps = np.round(np.arange(self.config.num_train_timesteps, 0, -step_ratio)).astype(np.int64)
timesteps -= 1
else:
raise ValueError(
f"{self.config.timestep_spacing} is not supported. Please make sure to choose one of 'leading' or 'trailing'."
)
self.timesteps = torch.from_numpy(timesteps).to(device)
def step(
self,
model_output: torch.Tensor,
timestep: int,
sample: torch.Tensor,
eta: float = 0.0,
use_clipped_model_output: bool = False,
generator=None,
variance_noise: Optional[torch.Tensor] = None,
return_dict: bool = True,
) -> Union[DDIMSchedulerOutput, Tuple]:
if self.num_inference_steps is None:
raise ValueError(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
# 1. get previous step value (=t-1);
# timestep=980,self.config.num_train_timesteps=1000, self.num_inference_steps=50
# prev_timestep = 960,步数的跳跃间隔为20
prev_timestep = timestep - self.config.num_train_timesteps // self.num_inference_steps
# 2. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
pred_epsilon = model_output
elif self.config.prediction_type == "sample":
pred_original_sample = model_output
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
elif self.config.prediction_type == "v_prediction":
pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
else:
raise ValueError(
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
" `v_prediction`"
)
# 4. Clip or threshold "predicted x_0"
if self.config.thresholding:
pred_original_sample = self._threshold_sample(pred_original_sample)
elif self.config.clip_sample:
pred_original_sample = pred_original_sample.clamp(
-self.config.clip_sample_range, self.config.clip_sample_range
)
# 5. compute variance: "sigma_t(η)" -> see formula (16)
# σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
variance = self._get_variance(timestep, prev_timestep)
std_dev_t = eta * variance ** (0.5)
if use_clipped_model_output:
# the pred_epsilon is always re-derived from the clipped x_0 in Glide
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
# 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
# 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
if eta > 0:
if variance_noise is not None and generator is not None:
raise ValueError(
"Cannot pass both generator and variance_noise. Please make sure that either `generator` or"
" `variance_noise` stays `None`."
)
if variance_noise is None:
variance_noise = randn_tensor(
model_output.shape, generator=generator, device=model_output.device, dtype=model_output.dtype
)
variance = std_dev_t * variance_noise
prev_sample = prev_sample + variance
if not return_dict:
return (
prev_sample,
pred_original_sample,
)
return DDIMSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.add_noise
def add_noise(
self,
original_samples: torch.Tensor,
noise: torch.Tensor,
timesteps: torch.IntTensor,
) -> torch.Tensor:
# Make sure alphas_cumprod and timestep have same device and dtype as original_samples
# Move the self.alphas_cumprod to device to avoid redundant CPU to GPU data movement
# for the subsequent add_noise calls
self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device)
alphas_cumprod = self.alphas_cumprod.to(dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.get_velocity
def get_velocity(self, sample: torch.Tensor, noise: torch.Tensor, timesteps: torch.IntTensor) -> torch.Tensor:
# Make sure alphas_cumprod and timestep have same device and dtype as sample
self.alphas_cumprod = self.alphas_cumprod.to(device=sample.device)
alphas_cumprod = self.alphas_cumprod.to(dtype=sample.dtype)
timesteps = timesteps.to(sample.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(sample.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
return velocity
def __len__(self):
return self.config.num_train_timesteps






![[ctfshow web入门] web4](https://i-blog.csdnimg.cn/direct/59f50dae2a7446419257ae805ac5bd25.png)