#############【持续更新】##############
LLM基础常见面试题
- 简单介绍一下大语言模型【LLMs】?
大模型:一般指1亿以上参数的模型,但是这个标准一直在升级,目前万亿参数以上的模型也有了。大语言模型(Large Language Models,LLMs)是针对语言的大模型。
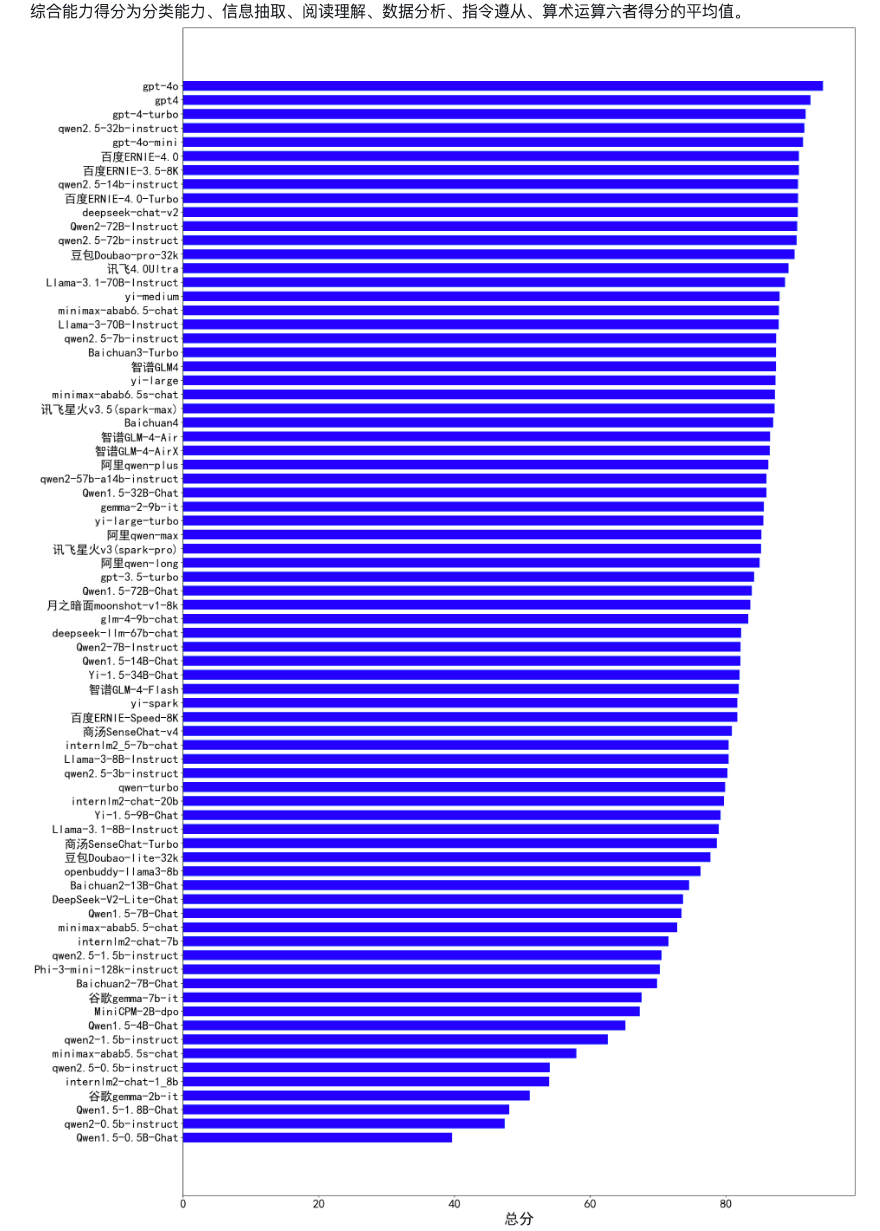
不同尺寸大模型在中文的能力评测:目前已囊括115个大模型,覆盖chatgpt、gpt4o、百度文心一言、阿里通义千问、讯飞星火、商汤senseChat、minimax等商用模型, 以及百川、qwen2、glm4、yi、书生internLM2、llama3等开源大模型,多维度能力评测。
参考链接:https://github.com/jeinlee1991/chinese-llm-benchmark
- 大语言模型【LLMs】后面跟的 175B、60B、540B等 指什么?
175B、60B、540B等:这些一般指参数的个数,B是Billion/十亿的意思,175B是1750亿参数,这是ChatGPT大约的参数规模。
- 大语言模型【LLMs】具有什么优点?
- 可以利用大量的无标注数据来训练一个通用的模型,然后再用少量的有标注数据来微调模型,以适应特定的任务。这种预训练和微调的方法可以减少数据标注的成本和时间,提高模型的泛化能力;
- 可以利用生成式人工智能技术来产生新颖和有价值的内容,例如图像、文本、音乐等。这种生成能力可以帮助用户在创意、娱乐、教育等领域获得更好的体验和效果;
- 可以利用涌现能力(Emergent Capabilities)来完成一些之前无法完成或者很难完成的任务,例如数学应用题、常识推理、符号操作等。这种涌现能力可以反映模型的智能水平和推理能力。
- 大语言模型【LLMs】具有什么缺点?
- 需要消耗大量的计算资源和存储资源来训练和运行,这会增加经济和环境的负担。据估计,训练一个GPT-3 模型需要消耗约30万美元,并产生约284吨二氧化碳排放;
- 需要面对数据质量和安全性的问题,例如数据偏见、数据泄露、数据滥用等。这些问题可能会导致模型产生不准确或不道德的输出,并影响用户或社会的利益;
- 需要考虑可解释性、可靠性、可持续性等方面的挑战,例如如何理解和控制模型的行为、如何保证模型的正确性和稳定性、如何平衡模型的效益和风险等。这些挑战需要多方面的研究和合作,以确保大模型能够健康地发展。
- 常见的大模型(LMs)分类有哪些?
大模型可以根据输入内容分类为如下三个类别:
-
语言大模型(NLP):
-
指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。
-
例如:GPT 系列(OpenAI)、Bard(Google)、文心一言(百度)Qwen(阿里)。
-
-
视觉大模型(CV):
-
指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。
-
例如:VIT 系列(Google)、文心UFO、华为盘古CV、INTERN(商汤)。
-
-
多模态大模型:
-
指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。
这类模型结合了 NLP 和 CV 的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。 -
例如:DALL-E(OpenAI)、midjourney。
-