一 定义
Large Language Model,称大规模语言模型或者大型语言模型,是一种基于大量数据训练的统计语言模型,可用于生成和翻译文本和其他内容,以及执行其他自然语言处理任务(NLP),通常基于深度神经网络构建,包含数百亿以上参数,使用自监督学习方法通过大量无标注文本进行训练。例如国外的有GPT-3、GPT-4、PaLM、Galactica和LLaMA等,国内的有ChatGLM、文心一言、通义千问、讯飞星火等。
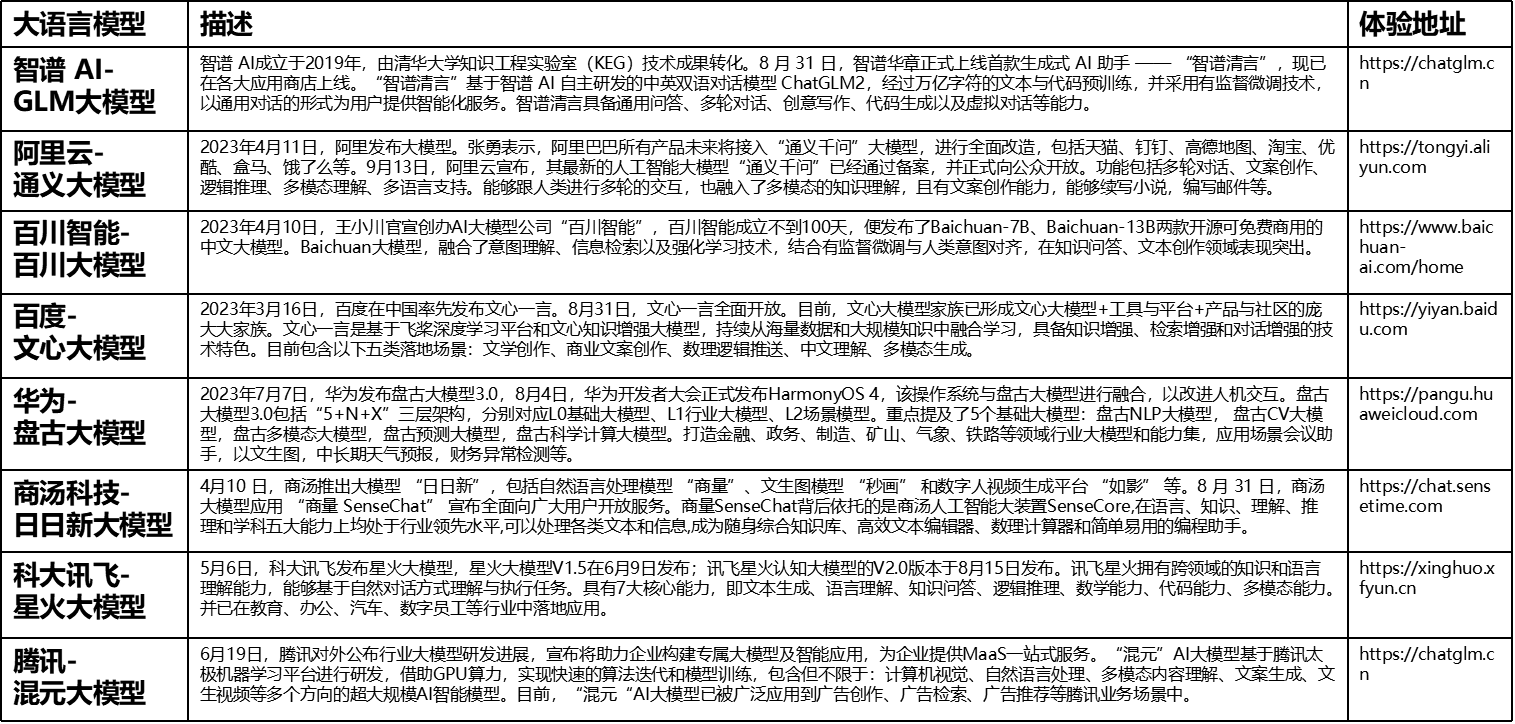
二 发展历程
- 早期语言模型:最初的语言模型通常是基于统计的n-gram模型,它们通过计算单词序列出现的概率来预测文本。
- 神经网络的引入:随着深度学习的发展,基于神经网络的语言模型开始流行,如循环神经网络(RNN)和长短期记忆网络(LSTM)。
- Transformer的革命:2017年,Google的“Attention Is All You Need”论文提出了Transformer架构,这成为了后续LLM的基础。
- BERT和GPT的出现:BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer)模型的发布标志着预训练语言模型的新时代。
- 参数数量的增长:随着硬件能力的提升,模型的参数数量从数百万增长到数十亿,甚至数万亿,如GPT-3和OpenAI的GPT系列的后续版本。
三 特点
- 巨大的规模:LLM通常具有巨大的参数规模,可以达到数十亿甚至数千亿个参数。这使得它们能够捕捉更多的语言知识和复杂的语法结构。
- 预训练和微调:LLM采用了预训练和微调的学习方法。它们首先在大规模文本数据上进行预训练(无标签数据),学会了通用的语言表示和知识,然后通过微调(有标签数据)适应特定任务,从而在各种NLP任务中表现出色。
- 上下文感知:LLM在处理文本时具有强大的上下文感知能力,能力理解和生成依赖于前文的文本内容。这使得它们在对话、文章生成和情境理解方面表现出色。
- 多语言支持:LLM可以用于多种语言,不仅限于英语。它们的多语言能力使得跨文化和跨语言的应用变得更加容易。
- 多模态支持:一些LLM已经扩展到支持多模态数据,包括文本、图像和语音。这意味着它们可以理解和生成不同媒体类型的内容,实现更多样化的应用。
- 涌现能力:LLM表现出令人惊讶的涌现能力,即在大规模模型中出现但在小型模型中不明显的性能提升。这使得它们能够处理更复杂的任务和问题。
- 多领域应用:LLM已经被广泛应用于文本生成、自动翻译、信息检索、摘要生成、聊天机器人、虚拟助手等多个领域,对人们的日常生活和工作产生了深远的影响。
- 伦理和风险问题:尽管LLM具有出色的能力,但它们也引发了伦理和风险问题,包括生成有害内容、隐私问题、认知偏差等。因此,研究和应用LLM需要谨慎。
涌现能力指的是一种令人惊讶的能力,它在小型模型中不明显,但在大型模型中显著出现。可以类比到物理学中的相变现象,涌现能力的显现就像是模型性能随着规模增大而迅速提升,超过了随机水平,也就是我们常说的量变引起了质变。
四 大语言模型代码文件解析
- gitignore :是一个纯文本文件,包含了项目中所有指定的文件和文件夹的列表,这些文件和文件夹是Git应该忽略和不追踪的
- MODEL_LICENSE:模型商用许可文件
- REDAME.md:略
- config.json:模型配置文件,包含了模型的各种参数设置,例如层数、隐藏层大小、注意力头数及Transformers API的调用关系等,用于加载、配置和使用预训练模型。
- configuration_chatglm.py:是该config.json文件的类表现形式,模型配置的Python类代码文件,定义了用于配置模型的 ChatGLMConfig 类。
- modeling_chatglm.py:源码文件,ChatGLM对话模型的所有源码细节都在该文件中,定义了模型的结构和前向传播过程,例如ChatGLMForConditionalGeneration 类。
- model-XXXXX-of-XXXXX.safetensors:安全张量文件,保存了模型的权重信息。这个文件通常是 TensorFlow 模型的权重文件。
- model.safetensors.index.json:模型权重索引文件,提供了 safetensors 文件的索引信息。
- pytorch_model-XXXXX-of-XXXXX.bin:PyTorch模型权重文件,保存了模型的权重信息。这个文件通常是 PyTorch模型的权重文件。
- pytorch_model.bin.index.json:PyTorch模型权重索引文件,提供了 bin 文件的索引信息。
- quantization.py:量化代码文件,包含了模型量化的相关代码。
- special_tokens_map.json:特殊标记映射文件,用于指定特殊标记(如起始标记、终止标记等)的映射关系。
- tokenization_chatglm.py:分词器的Python类代码文件,用于chatglm3-6b模型的分词器,它是加载和使用模型的必要部分,定义了用于分词的 ChatGLMTokenizer 类。
- tokenizer.model:包含了训练好的分词模型,保存了分词器的模型信息,用于将输入文本转换为标记序列;通常是二进制文件,使用pickle或其他序列化工具进行存储和读取。
- tokenizer_config.json:含了分词模型的配置信息,用于指定分词模型的超参数和其他相关信息,例如分词器的类型、词汇表大小、最大序列长度、特殊标记等
- LFS:Large File Storage,大文件存储
五 作用
LLM在许多NLP任务中都有广泛的应用,包括但不限于:
- 文本生成:如文章撰写、代码生成、诗歌创作等。
- 机器翻译:将一种语言翻译成另一种语言。
- 问答系统:回答用户的问题。
- 文本摘要:生成文本的简短摘要。
- 情感分析:判断文本的情感倾向。
- 自然语言理解:理解和解释自然语言。
六 工作原理
LLM通常基于Transformer架构,它依赖于自注意力机制来处理输入的文本序列。工作原理可以分为以下几个步骤:
- 输入嵌入:将文本转换为数值形式的嵌入向量。
- 自注意力:模型通过自注意力机制学习文本中不同单词之间的关系。
- 层叠的Transformer块:多个Transformer块层叠起来,每个块包含自注意力层和前馈神经网络。
- 输出:最后一层的输出被转换为预测,如下一个单词的概率分布。
七 使用方法
使用LLM通常涉及以下步骤:
- 选择模型:根据需求选择合适的LLM,如GPT-3、BERT等。
- 预训练:模型在大规模文本数据集上进行预训练。
- 微调:在特定任务的数据集上对模型进行微调。
- 部署:将训练好的模型部署到应用中,进行推理。
八 优缺点
优点:
- 多功能性:LLM能够处理多种语言任务,具有很高的灵活性。
- 强大的语言理解能力:由于在大量文本上进行训练,LLM通常能够很好地理解和生成自然语言。
- 易于集成:许多LLM(如GPT-3)提供了API,可以轻松集成到各种应用中。
缺点:
- 计算成本高:训练和运行LLM需要大量的计算资源。
- 数据偏见:LLM可能会从训练数据中学习到偏见,并在生成的文本中反映出来。
- 解释性差:LLM的决策过程通常是不透明的,难以解释其输出的原因。







![[考研数学]多元函数,向量函数,向量场辨析](https://i-blog.csdnimg.cn/direct/2ae63f4b15734477a470627575d9c3fd.jpeg)









