Python对PDF文件页面的旋转和切割
利用Python的.rotate()方法和.mediabox属性对PDF页面进行旋转和切割,最终生成一个PDF。下面结合案例进行说明,本示例中的名为split_and_rotate.pdf文件在practice_files文件夹中,
示例(1):
在home目录中创建一个新的PDF,命名为rotated.pdf。将split_and_rotate.pdf中的所有页面逆时针旋转90度后保存到该文件中。原始文件如下:
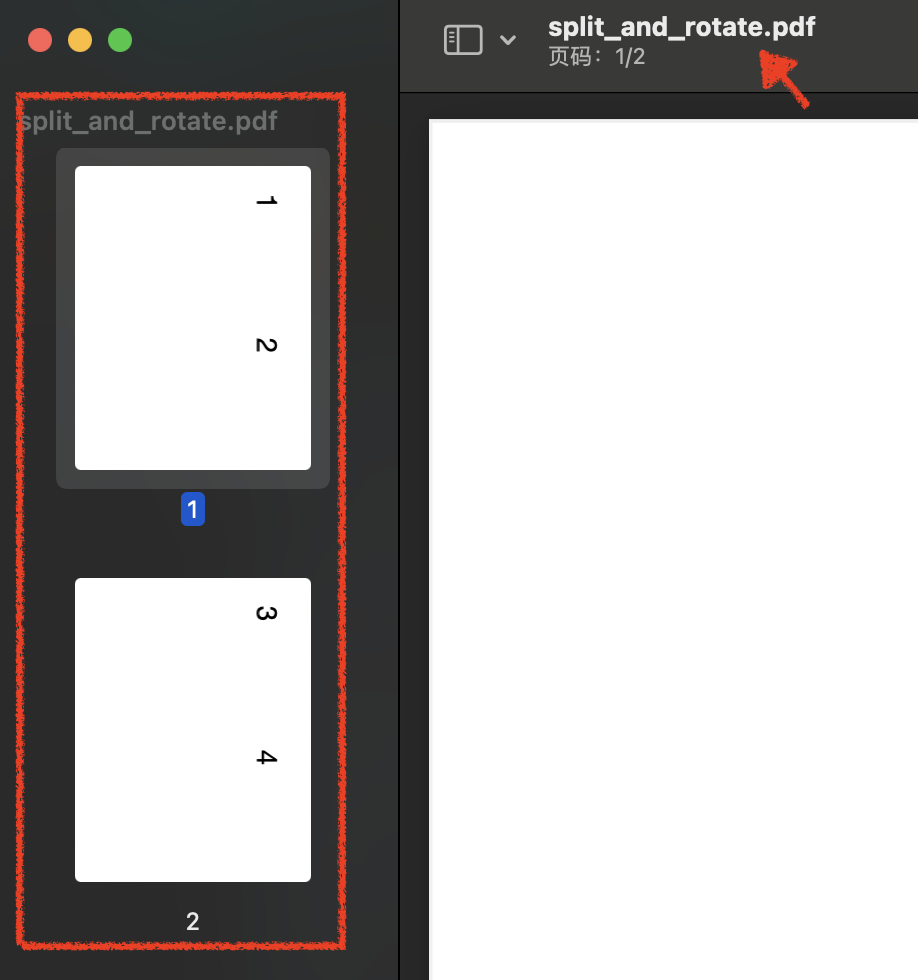
下面将以上的PDF文件逆时针旋转90度后保存。
源代码如下:
from pathlib import Path
from PyPDF2 import PdfReader, PdfWriter
# 定义 PDF 文件的路径,位置在当前工作目录下的 'practice_files' 文件夹中
pdf_path = Path.cwd() / 'practice_files' / 'split_and_rotate.pdf'
# 读取指定路径的 PDF 文件
pdf_reader = PdfReader(str(pdf_path))
# 创建一个 PDF 写入器对象,用于写入新的 PDF 文件
pdf_writer = PdfWriter()
# 遍历 PDF 文件中的每一页
for page in range(len(pdf_reader.pages)):
# 将当前页面旋转 -90 度,并添加到写入器中
pdf_writer.add_page(pdf_reader.pages[page].rotate(-90))
# 在用户的主目录下创建一个新的 PDF 文件 'rotated.pdf',以写入模式打开
with (Path.home() / 'rotated.pdf').open('wb') as f:
# 将合并后的内容写入到新创建的文件中
pdf_writer.write(f)
运行结果如下图:

代码解释
- 导入模块:
from pathlib import Path: 导入Path类,以方便处理文件路径。from PyPDF2 import PdfReader, PdfWriter: 从PyPDF2导入PdfReader和PdfWriter类,用于读取和写入 PDF 文件。
- 定义 PDF 文件路径:
pdf_path = Path.cwd() / 'practice_files' / 'split_and_rotate.pdf': 使用Path.cwd()获取当前工作目录,并与'practice_files'和'split_and_rotate.pdf'连接,构建出完整的 PDF 文件路径。
- 读取 PDF 文件:
pdf_reader = PdfReader(str(pdf_path)): 使用PdfReader类实例化一个对象pdf_reader,读取指定路径的 PDF 文件。此时,pdf_reader包含了所有页面的信息。
- 创建 PDF 写入器:
pdf_writer = PdfWriter(): 实例化一个PdfWriter对象,用于创建新的 PDF 文件并写入内容。
- 遍历 PDF 文件的每一页:
for page in range(len(pdf_reader.pages)): 使用循环遍历pdf_reader中的每一页,len(pdf_reader.pages)返回 PDF 文件的总页数。pdf_writer.add_page(pdf_reader.pages[page].rotate(-90)): 取出当前页 (pdf_reader.pages[page]),调用rotate(-90)方法将该页旋转 -90 度(向左旋转),然后使用add_page()方法将旋转后的页面添加到pdf_writer对象中。
- 写入新的 PDF 文件:
with (Path.home() / 'rotated.pdf').open('wb') as f: 在用户的主目录下创建一个新的 PDF 文件,命名为rotated.pdf,以二进制写入模式打开它。pdf_writer.write(f): 将pdf_writer中的内容写入到新创建的rotated.pdf文件中,完成旋转操作后的 PDF 文件创建。
示例(2):
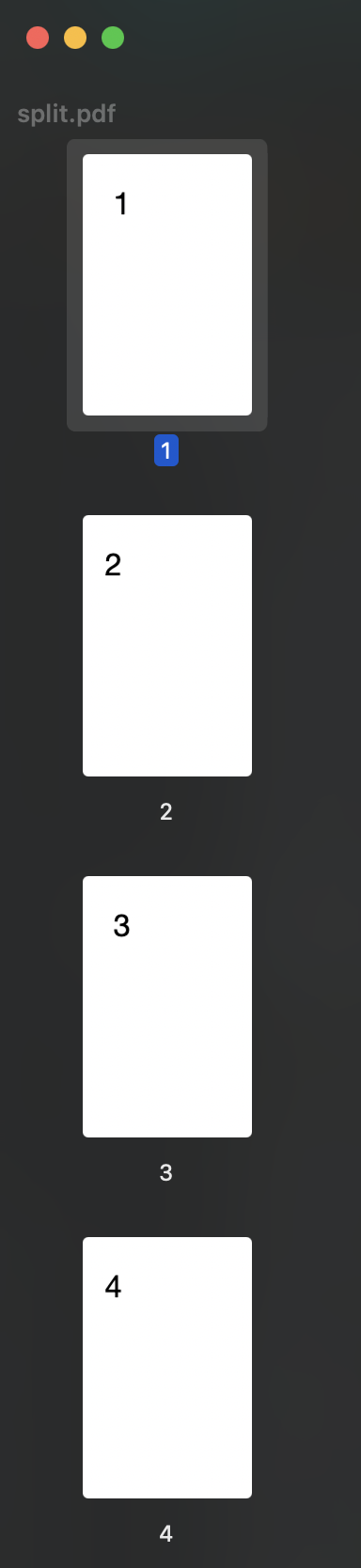
使用示例(1)中创建的rotated.pdf,将PDF中的每一页沿垂直中线分割开来,在home目录中创建一个新的PDF,命名为split.pdf。将分割后得到的页面保存在该文件中。示例源码如下:
from pathlib import Path
from PyPDF2 import PdfWriter, PdfReader
import copy
# 定义 PDF 文件的路径,位置在用户的主目录下,文件名为 'rotated.pdf'
pdf_path = (Path.home() / 'rotated.pdf')
# 读取指定路径的 PDF 文件
pdf_reader = PdfReader(str(pdf_path))
# 创建一个 PDF 写入器对象,用于写入新的 PDF 文件
pdf_writer = PdfWriter()
# 获取第一个页面的右上角坐标
current_coords = pdf_reader.pages[0].mediabox.upper_right
# 遍历 PDF 文件中的每一页
for page in pdf_reader.pages:
# 深拷贝当前页面,以创建左半边和右半边
left_side = copy.deepcopy(page)
right_side = copy.deepcopy(page)
# 计算新坐标,将右上角的 X 坐标除以 2,Y 坐标保持不变
new_coords = (current_coords[0] / 2, current_coords[1])
# 设置左半边的右上角坐标为新坐标
left_side.mediabox.upper_right = new_coords
# 设置右半边的左上角坐标为新坐标
right_side.mediabox.upper_left = new_coords
# 将修改后的左半边页面添加到写入器中
pdf_writer.add_page(left_side)
# 将修改后的右半边页面也添加到写入器中
pdf_writer.add_page(right_side)
# 在当前工作目录下创建一个新的 PDF 文件 'split.pdf',以写入模式打开
with Path.cwd().joinpath('split.pdf').open('wb') as f:
# 将合并后的内容写入到新创建的文件中
pdf_writer.write(f)
运行结果如下:
代码解释
- 导入模块:
from pathlib import Path: 导入Path类,用于处理文件路径。from PyPDF2 import PdfWriter, PdfReader: 从PyPDF2中导入PdfWriter和PdfReader,用于读取和生成 PDF 文件。import copy: 导入copy模块,以便可以进行深拷贝操作。
- 定义 PDF 文件路径:
pdf_path = (Path.home() / 'rotated.pdf'): 使用Path.home()获取用户主目录,并与'rotated.pdf'拼接,构建出完整的 PDF 文件路径。
- 读取 PDF 文件:
pdf_reader = PdfReader(str(pdf_path)): 实例化一个PdfReader对象,读取指定路径的 PDF 文件。这将把文件中的所有页面信息加载到内存中。
- 创建 PDF 写入器:
pdf_writer = PdfWriter(): 实例化一个PdfWriter对象,用于创建新的 PDF 文件并写入内容。
- 获取页面坐标:
current_coords = pdf_reader.pages[0].mediabox.upper_right: 获取 PDF 的第一个页面的右上角坐标,这个坐标用于确定后续生成的两部分的尺寸。
- 遍历 PDF 文件中的每一页:
for page in pdf_reader.pages:: 遍历所有页面。
- 创建页面的深拷贝:
left_side = copy.deepcopy(page): 创建当前页面的一个深拷贝,用于生成左半边页面。right_side = copy.deepcopy(page): 同样深拷贝当前页面,用于生成右半边页面。
- 计算新坐标:
new_coords = (current_coords[0] / 2, current_coords[1]): 将右上角的 X 坐标除以 2,保留 Y 坐标不变,计算出左半边和右半边的新边界坐标。
- 设置左右页面的坐标:
left_side.mediabox.upper_right = new_coords: 更新左半边页面的右上角坐标。right_side.mediabox.upper_left = new_coords: 更新右半边页面的左上角坐标。
- 写入修改后的页面:
pdf_writer.add_page(left_side): 将左半边页面添加到 PDF 写入器。pdf_writer.add_page(right_side): 将右半边页面也添加到 PDF 写入器。
- 输出新的 PDF 文件:
with Path.cwd().joinpath('split.pdf').open('wb') as f: 创建一个新的 PDF 文件,命名为split.pdf,在当前工作目录下,以二进制写入模式打开。pdf_writer.write(f): 将写入器中的内容(即左半边和右半边的页面)写入到新创建的split.pdf文件中。
希望此文对您有所启发和帮助,欢迎点赞、关注、转发!!!