-
题目:
-

-
Sql 测试用例:
-
Create table If Not Exists Friends (id int, name varchar(30), activity varchar(30)); Create table If Not Exists Activities (id int, name varchar(30)); Truncate table Friends; insert into Friends (id, name, activity) values ('1', 'Jonathan D.', 'Eating'); insert into Friends (id, name, activity) values ('2', 'Jade W.', 'Singing'); insert into Friends (id, name, activity) values ('3', 'Victor J.', 'Singing'); insert into Friends (id, name, activity) values ('4', 'Elvis Q.', 'Eating'); insert into Friends (id, name, activity) values ('5', 'Daniel A.', 'Eating'); insert into Friends (id, name, activity) values ('6', 'Bob B.', 'Horse Riding'); Truncate table Activities; insert into Activities (id, name) values ('1', 'Eating'); insert into Activities (id, name) values ('2', 'Singing'); insert into Activities (id, name) values ('3', 'Horse Riding'); -
分析:首先,我们可以先按照活动分组,然后算出每个活动中的id个数,然后按照这个总数进行排序,正序和倒序,然后不要排名为一的数据。
-

-
sql实现:
-
with t1 as ( select activity,count(1) nu from Friends group by activity -- 按照活动分组,然后算出每个组内id的个数 ), t2 as ( select activity,rank() over (order by nu) rk1,rank() over (order by nu desc ) rk2 from t1 -- 然后按照个数排序,算出升序和降序的排名(这里使用rank函数,因为需要考虑并列的情况) ) select activity from t2 where rk1 !=1 and rk2 !=1 -- 然后取出升序和降序排名不为1的活动名称 -
pandas测试例子:
-
data = [[1, 'Jonathan D.', 'Eating'], [2, 'Jade W.', 'Singing'], [3, 'Victor J.', 'Singing'], [4, 'Elvis Q.', 'Eating'], [5, 'Daniel A.', 'Eating'], [6, 'Bob B.', 'Horse Riding']] friends = pd.DataFrame(data, columns=['id', 'name', 'activity']).astype({'id':'Int64', 'name':'object', 'activity':'object'}) data = [[1, 'Eating'], [2, 'Singing'], [3, 'Horse Riding']] activities = pd.DataFrame(data, columns=['id', 'name']).astype({'id':'Int64', 'name':'object'}) -
pandas分析:和sql 的解法差不多
-
pandas实现:
-
import pandas as pd def activity_participants(friends: pd.DataFrame, activities: pd.DataFrame) -> pd.DataFrame: friend=friends.groupby('activity')['id'].count().reset_index() -- 分组,算出每个组内id个数 friend['rn']=friend['id'].rank(method='min') -- 升序排序考虑次数相同 friend['rn1']=friend['id'].rank(method='min',ascending=False) -- 降序排序考虑次数相同 friend=friend[(friend['rn']!=1) & (friend['rn1']!=1)]['activity'] --然后取出升序和降序排名不为1的活动名称 return friend.to_frame() -- 转换成dataframe对象
力扣之1355.活动参与者
news2026/3/17 20:26:15
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2201573.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

FreeRTOS学习总结
背景:在裸机开发上,有时候我们需要等待某个信号或者需要延迟时,CPU的运算是白白浪费掉了的,CPU的利用率并不高,我们希望当一个函数在等待的时候,可以去执行其他内容,提高CPU的效率,同…

朝花夕拾:多模态图文预训练的前世今生
Diffusion Models专栏文章汇总:入门与实战 前言:时间来到2024年,多模态大模型炙手可热。在上一个时代的【多模态图文预训练】宛若时代的遗珠,本文的时间线从2019年到2022年,从BERT横空出世讲到ViT大杀四方,…
通过阿里云Milvus与PAI搭建高效的检索增强对话系统
阿里云Milvus现已无缝集成于阿里云PAI平台,一站式赋能用户构建高性能的RAG(Retrieval-Augmented Generation)对话系统。您可以利用Milvus作为向量数据的实时存储与检索核心,高效结合PAI和LangChain技术栈,实现从理论到…

数学建模算法与应用 第8章 时间序列分析
目录 8.1 确定性时间序列分析方法
Matlab代码示例:移动平均法提取趋势
8.2 平稳时间序列模型
Matlab代码示例:差分法与ADF检验
8.3 时间序列的Matlab相关工具箱及命令
Matlab代码示例:ARIMA模型的建立
8.4 ARIMA序列与季节性序列
Matl…

【Golang】Go语言中缓冲bufio的原理解读与应用实战
✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…

Ubuntu关闭anaconda自动进入base虚拟环境
问题描述:安装好Anconda后,每次打开终端后都会自动进入到base的虚拟环境中去
直接使用通常情况下也不会有什么影响,但是为了避免,有以下两个方法:
1.使用conda deactivate
#每次使用conda deactivate,退…

鸿蒙开发(NEXT/API 12)【ArkWeb接入密码保险箱】系统安全
网页中的登录表单,登录成功后,用户可将用户名和密码保存到鸿蒙系统密码保险箱中。再次打开该网页时,密码保险箱可以提供用户名、密码的自动填充。
手机使用场景 在网站中输入用户名、密码,登陆成功后,ArkWeb会提示将用…
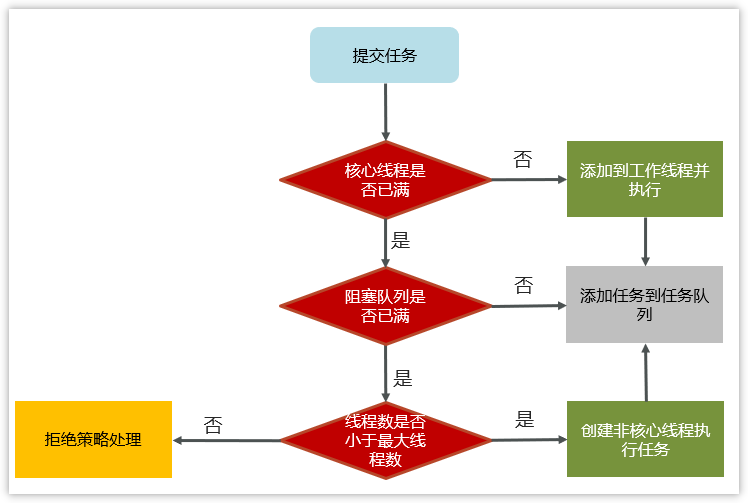
线程池的核心参数——Java全栈知识(50)
线程池的核心参数
线程池核心参数主要参考ThreadPoolExecutor这个类的7个参数的构造函数 corePoolSize 核心线程数目maximumPoolSize 最大线程数目 (核心线程救急线程的最大数目)keepAliveTime 生存时间 - 救急线程的生存时间,生存时间内没有新任务,此…

前端Vue3字体优化三部曲(webFont、font-spider、spa-font-spider-webpack-plugin)
前端Vue字体优化三部曲(webFont、font-spider、spa-font-spider-webpack-plugin)
引言
最近前端引入了UI给的思源黑体字体文件,但是字体文件过于庞大,会降低页面首次加载的速度,目前我的项目中需要用到如下三个字体文…


PMP--冲刺题--解题--71-80
文章目录 14.敏捷--合规--测试无问题,安全团队却拒绝部署,则意味着可能存在某方面安全问题71、 [单选] 一个项目经理正在为一家政府所有的公司管理一个采用迭代方法的项目。第一个有用的生产发布由三次迭代组成。每次迭代都在测试环境中成功通过了客户代…

qwt实现码流柱状图多色柱体显示
qwt实现码流柱状图多色柱体显示 1. 前言2. qt实现柱状图3.qwt基础说明3.1 qwt安装与使用3.1.1 下载qwt源码3.1.2 编译3.1.3 安装3.1.4 使用3.2 QwtPlotBarChart类3.2.1画图步骤3.2.2 specialSymbol3.3.3 barTitle4 BsBarChart定制4.1 每个柱体可以显示不同的颜色4.2 每个柱体可…

网络安全-IPv4和IPv6的区别
1. 2409:8c20:6:1135:0:ff:b027:210d。
这是一个IPv6地址。IPv6(互联网协议版本6)是用于标识网络中的设备的一种协议,它可以提供比IPv4更大的地址空间。这个地址由八组十六进制数字组成,每组之间用冒号分隔。IPv6地址通常用于替代…

大数据毕业设计选题推荐-B站热门视频数据分析-Python数据可视化-Hive-Hadoop-Spark
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…

Python 工具库每日推荐【Pillow】
文章目录 引言Python图像处理库的重要性今日推荐:Pillow工具库主要功能:使用场景:安装与配置快速上手示例代码代码解释实际应用案例案例:创建图像拼贴案例分析高级特性图像增强图像水印扩展阅读与资源优缺点分析优点:缺点:总结【 已更新完 TypeScript 设计模式 专栏,感兴…

数学建模算法与应用 第5章 插值与拟合方法
目录 5.1 插值方法
Matlab代码示例:线性插值
Matlab代码示例:样条插值
5.2 曲线拟合的线性最小二乘法
Matlab代码示例:线性拟合
5.3 最小二乘优化与多项式拟合
Matlab代码示例:多项式拟合
5.4 曲线拟合与函数逼近
Matlab代…

深入理解链表(SList)操作
目录: 一、 链表介绍1.1、 为什么引入链表1.2、 链表的概念及结构1.3、 链表的分类 二、 无头单向非[循环链表](https://so.csdn.net/so/search?q循环链表&spm1001.2101.3001.7020)的实现2.1、 [单链表](https://so.csdn.net/so/search?q单链表&spm1001.2…

系统架构师备考记忆不太清楚的点-信息系统-需求分析
霍尔三维结构
逻辑维:解决问题的逻辑过程
过程有明确问题、确立目标、系统综合、系统分析、优化、系统决策、实施计划
时间维:工作进度
这个纬度则是做工作计划的输出
有 规划阶段、拟定方案、研制阶段、生产阶段、安装阶段、运行阶段、更新阶段
知…

TiDB 优化器丨执行计划和 SQL 算子解读最佳实践
导读
在数据库系统中,查询优化器是数据库管理系统的核心组成部分,负责将用户的 SQL 查询转化为高效的执行计划,因而会直接影响用户体感的性能与稳定性。优化器的设计与实现过程充满挑战,有人比喻称这是数据库技术要持续攀登的珠穆…

Android SELinux——基础介绍(一)
Android 系统的安全策略是保护用户的隐私和数据不受侵害的重要保证,一个相对安全的计算环境对于确保移动设备的安全至关重要。随着新的威胁不断出现,Android 的安全策略也在不断发展和完善,以应对新的挑战。
一、概念介绍
1、SELinux SELin…