VAD: Vectorized Scene Representation for Efficient Autonomous Driving
- 解决了什么问题?
- 相关工作
- 感知
- 运动预测
- 规划
- 提出了什么方法?
- 概览
- 1. 矢量化的场景学习
- 矢量化地图
- 交通参与者的矢量化运动
- 2. Planning via Interaction
- 自车-其它交通参与者的交流
- 自车-地图之间的交流
- 规划头
- 3. Vectorized Planning Constraint
- 自车-其它交通参与者的碰撞约束
- 自车-边界的越界约束
- 自车-车道线方向的约束
- 4. End-to-End Learning
- 矢量化的场景学习损失
- 矢量化约束损失
- 模仿学习损失
- 实验
- 实现细节
- 主要结果
- 开环规划结果
- 闭环规划结果
- 消融实验
- 设计的有效性
- 栅格化地图表示
- 每个模块的运行时间
- 定性结果
论文地址:https://arxiv.org/abs/2303.12077
代码地址:https://github.com/hustvl/VAD
解决了什么问题?
出于安全性考虑,自动驾驶需要对场景的全面理解;同时,为了实际部署考虑,也需要考虑到效率问题。自动驾驶车辆需要高效地感知驾驶场景,基于场景信息来做合理的规划。
传统的自动驾驶方法采用了模块化范式,感知和规划被解耦成两个单独的模块。缺点就是,规划模块无法获取传感器的原始数据,而这些数据具有丰富的语义信息。规划模块完全基于前面的感知结果,感知模块的错误会严重影响后面的规划任务,如果规划模块无法识别和纠正的话就会引发安全问题。
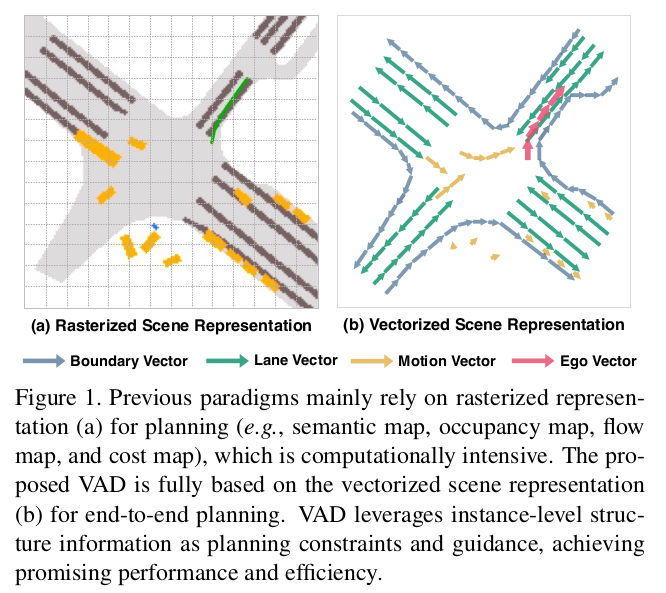
最近,端到端的自动驾驶方法将传感器数据作为输入,直接输出规划结果,整个过程由一个整体的模型完成。一些工作直接基于传感器数据输出规划结果,而没有学习场景表示,这就缺乏可解释性,很难对其做优化。大多数的工作为了做规划,将传感器数据转化为栅格化的场景表示(语义地图、占用地图、光流图和代价图)。虽然栅格化表示够直接,但非常消耗计算资源,丢失了重要的实例级的结构信息。
相关工作
感知
准确地感知驾驶场景是自动驾驶的基础。这里主要介绍了一些基于相机的 3D 目标检测和在线建图方法。DETR3D 使用 3D queries 采样相应的图像特征,没有用 NMS 来完成检测。PETR 在图像特征中引入了 3D 位置编码,通过注意力机制,使用检测 queries 来学习目标特征。BEV 表示逐渐流行起来,极大地促进了感知领域的发展。LSS 率先引入了深度预测,将透视视角的特征映射到 BEV 视角。BEVFormer 提出了空间和时域注意力,更好地编码 BEV 特征图,只用相机输入就取得了优异的检测效果。FIERY 和 BEVerse 使用 BEV 特征图来预测密集的地图分割。HDMapNet 将车道分割转化为矢量化地图,无需后处理步骤。VectorMapNet 以自回归的方式来预测地图元素。MapTR 识别地图实例点的排列不变性,能同时预测所有地图元素。LaneGAP 将车道地图建模为一系列的路径,而不是传统的像素或分段方式,更好地保留了车道的连续性,并编码了交通信息用于规划。本文使用 BEV queries、交通参与者 queries 和地图 queries 来做场景感知,在运动预测和规划阶段也使用了这些 query 特征和感知结果。
运动预测
传统的运动预测将感知结果作为输入(即交通参与者的历史轨迹、高精地图)。一些工作将驾驶场景渲染为 BEV 图像,采用 CNN 网络来预测未来的运动。另一些工作则使用矢量化表示,采用 GNN 或 Transformer 来完成学习和预测。最近的端到端工作协同优化感知和运动预测两个任务。部分工作将未来的运动看作为密集的占用和光流,而非各实例未来的轨迹点。ViP3D 基于跟踪结果和高精地图来预测未来的运动。PIP 则在动态参与者和静态矢量地图之间,提出了一种交互机制,无需高精地图,即取得了 SOTA 的成绩。VAD 通过在动态参与者和静态地图元素之间交流信息,学习交通参与者的矢量化的运动。
规划
最近,基于学习的规划方法风头无两。一些方法省去了中间步骤(如感知和运动预测),直接预测规划轨迹或控制信号。尽管这个想法简单直接,但缺乏可解释性、难以优化。强化学习也被应用在规划任务,非常有潜力。显式的代价图具有良好的可解释性,所以被广泛应用。有两种方式构建代价图,要么构建自感知或运动预测的结果,要么来自于一个学习模块。人们也经常采用人为规则,选取代价最小的规划轨迹。构建密集代价图是非常消耗算力的,而使用人为规则又会造成鲁棒性和泛化性的问题。UniAD 有效地融合了前述模块提供的信息,以目标导向的内核来辅助规划任务,在感知、预测和规划任务都取得了优异的表现。PlanT 将感知的结果作为输入,以目标级的表示来编码场景,进行规划。本文,作者探索了矢量化场景表示,摆脱了密集代价图和人为设计的后处理步骤。
提出了什么方法?
本文提出了 VAD (Vectorized Autonomous Driving),它是一个针对自动驾驶任务的端到端的矢量化范式,将驾驶场景建模为一个完全矢量化的表示(即矢量化的交通参与者运动和矢量化地图),无需算力密集型的栅格化表示。矢量化地图(表示为边界矢量和车道矢量)提供了道路结构信息(如交通流、可行驶区域、车道方向),帮助自动驾驶车辆缩小轨迹的搜索空间,并规划出一条更加合理的轨迹。交通参与者的运动趋势(表示为交通参与者的运动矢量)则为防止碰撞发生,提供了实例级的约束。
这个矢量化范式有两个显著优势:
- VAD 将交通参与者的矢量化运动趋势和地图元素直接作为实例级的规划约束,有效提升了规划的安全性。
- VAD 要比之前的端到端规划方案快很多,因为它摆脱了计算密集型的栅格化表示和人为设计的后处理步骤。
VAD 充分利用了矢量化信息,直接或间接地指导规划。一方面,VAD 利用地图 queries 和交通参与者 queries 从传感器数据隐式地学习实例级地图特征和参与者的运动特征。通过 query 交流提取规划任务的指导信息。另一方面,VAD 基于直接的矢量化场景空间,提出了三个实例级的规划约束:
- 自车-交通参与者碰撞约束,在自车和其它动态参与者之间保持一定的纵向和横向安全距离;
- 自车边界越界约束,将规划的轨迹推向远离道路边界的方向,确保车辆不会驶出道路,从而提高行车安全性;
- 自车车道方向约束,规范自车未来的运动方向, 使其与矢量化的车道方向一致,有助于自车保持在车道内,并按照预期的方向行驶。
VAD 在 nuScenes 数据集上取得了 SOTA 的规划表现,大幅度地超越了之前的最佳方法。与之前的 SOTA 方法 UniAD 相比,基线模型 VAD-base 极大地降低了平均规划位移误差约 30.1 % 30.1\% 30.1%,平均碰撞率降低了 29 % 29\% 29%,而运行速度快了 2.5 × 2.5\times 2.5× 倍。此外,轻量级版本 VAD-Tiny 也显著地提升了推理速度(提升了 9.3 × 9.3\times 9.3×倍),平均位移错误为 0.78 m 0.78m 0.78m、平均碰撞率为 0.38 % 0.38\% 0.38%。
概览
VAD 的整体结构如下图所示。给定多帧的多视角图像作为输入,VAD 首先用一个主干网络编码图像特征,利用一组 BEV queries 将图像特征映射为 BEV 特征。其次,VAD 利用一组交通参与者 queries 和地图 queries,学习矢量化的场景表示,包括矢量化的地图和矢量化的参与者运动。然后,基于场景信息做规划。VAD 通过自车 query 与参与者 queries 和地图 queries 交流,隐式地学习场景信息。根据自车 query、自车状态特征和高层级的驾驶指令,规划头输出规划的轨迹。此外,VAD 引入了三个矢量化的规划约束,限制每个实例的规划轨迹。VAD 完全可微,以端到端的方式训练。
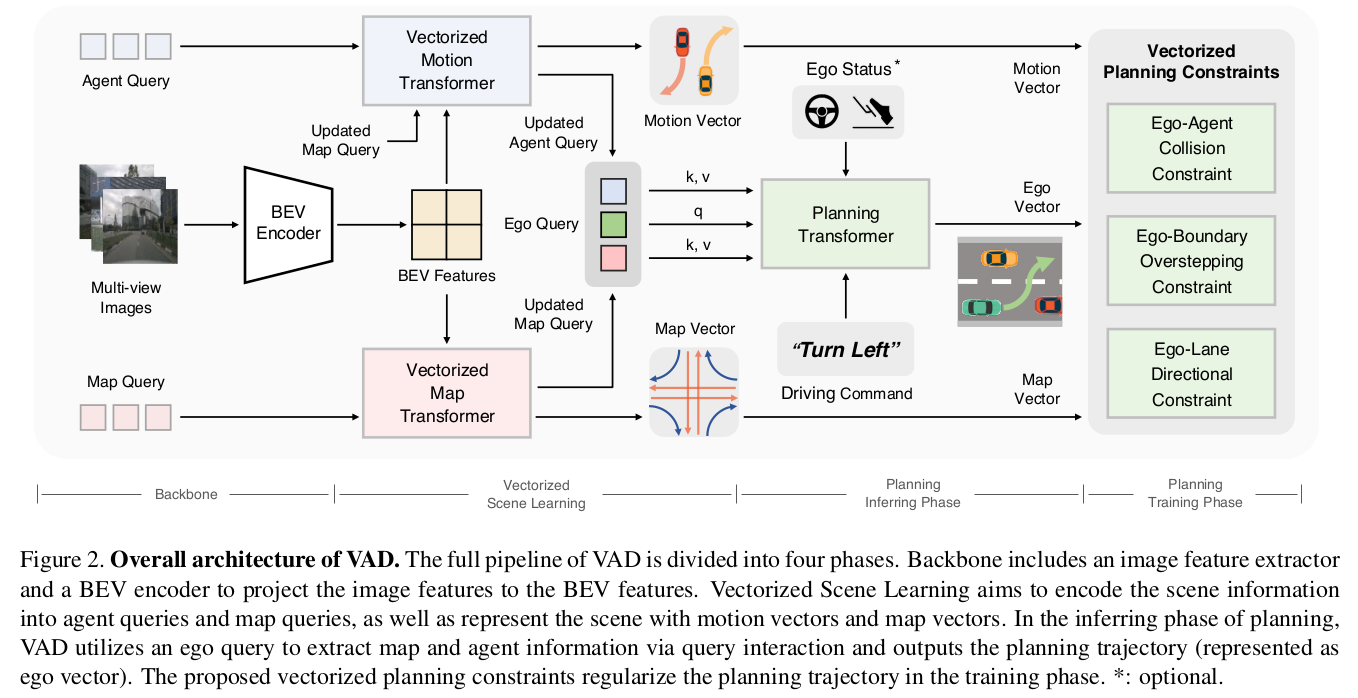
1. 矢量化的场景学习
感知交通参与者和地图元素对于场景理解非常重要。VAD 将场景信息编码为 query 特征,用地图矢量和交通参与者的运动矢量来表示场景。
矢量化地图
之前的工作使用栅格化语义图来指导规划,丢失了地图上重要的实例结构信息。VAD 使用一组地图 queries Q m Q_m Qm,从 BEV 特征图上提取地图信息,预测地图矢量 V ^ m ∈ R N m × N p × 2 \hat{V}_m \in \mathbb{R}^{N_m\times N_p\times 2} V^m∈RNm×Np×2 及每个地图矢量的类别分数, N m N_m Nm 和 N p N_p Np 分别是预测的地图矢量的个数和每个地图矢量里的点的个数。地图元素有三种:分道线、道路边缘和人行横道。分道线提供方向信息,道路边缘表示可行驶区域。利用地图 queries 和地图矢量来提升规划的表现。
交通参与者的矢量化运动
VAD 首先用一组参与者 queries Q a Q_a Qa 从 BEV 特征图上,通过可变形注意力来学习交通参与者的特征。用一个基于 MLP 的解码头,对参与者 queries 做解码,得到交通参与者的属性(位置、类别分数、朝向角等)。为了使参与者的特征更加丰富,VAD 通过注意力机制,进行了参与者之间的信息交流、参与者与地图的信息交流。VAD 预测每个参与者的未来轨迹,表示为多模态的运动矢量 V ^ ∈ R N a × N k × T f × 2 \hat{V} \in \mathbb{R}^{N_a \times N_k \times T_f \times 2} V^∈RNa×Nk×Tf×2, N a , N k , T f N_a, N_k, T_f Na,Nk,Tf 分别是参与者的个数、轨迹模态的个数和未来时间戳的个数。运动矢量的每个模态表示一种驾驶意图。VAD 针对每个模态都输出一个概率分数。参与者的运动矢量用来限制自车的规划轨迹,避免发生碰撞。同时,参与者 queries 会作为场景信息,被送入规划模块。
2. Planning via Interaction
自车-其它交通参与者的交流
VAD 使用一个随机初始化的自车 query Q e g o Q_{ego} Qego 来学习隐式的场景特征。为了学习其它动态交通参与者的位置和运动信息,自车 query 首先通过一个 Transformer 解码器与其它参与者 queries 做交流,自车 query Q e g o Q_{ego} Qego作为注意力的 query q q q 使用,而其它参与者的 queries Q a Q_a Qa 作为 key k k k 和 value v v v 使用。感知模块预测自车的位置 p e g o p_{ego} pego 和其它参与者的位置 p a p_a pa,然后用一个单层 MLP PE 1 \text{PE}_1 PE1 来编码 p e g o p_{ego} pego 和 p a p_a pa,得到 query 位置编码 q p o s q_{pos} qpos 和 key 位置编码 k p o s k_{pos} kpos 使用。位置编码提供了自车和其它交通参与者之间的相对位置关系,上述过程可以表述为:
Q e g o ′ = TransformerDecoder ( q , k , v , q p o s , k p o s ) q = Q e g o , k = v = Q a , q p o s = PE 1 ( p e g o ) , k p o s = PE 1 ( p a ) . \begin{equation} \begin{split} &Q_{ego}'=\text{TransformerDecoder}(q,k,v,q_{pos},k_{pos}) \\ &q=Q_{ego},\ k=v=Q_a,\\ &q_{pos}=\text{PE}_1 (p_{ego}),\ k_{pos}=\text{PE}_1(p_a). \end{split} \end{equation} Qego′=TransformerDecoder(q,k,v,qpos,kpos)q=Qego, k=v=Qa,qpos=PE1(pego), kpos=PE1(pa).
自车-地图之间的交流
当和其它参与者 queries 完成交流后,更新后的自车 query Q e g o ′ Q_{ego}' Qego′ 会和地图 queries Q m Q_m Qm 以相似的方式进一步做交流。唯一的区别就是使用了一个不同的 MLP PE 2 \text{PE}_2 PE2,编码自车的位置和地图元素的位置。输出的自车 query Q e g o ′ ′ Q_{ego}'' Qego′′包含了驾驶场景的动态和静态信息。该过程表述为:
Q e g o ′ ′ = TransformerDecoder ( q , k , v , q p o s , k p o s ) q = Q e g o ′ , k = v = Q m , q p o s = PE 2 ( p e g o ) , k p o s = PE 2 ( p a ) . \begin{equation} \begin{split} &Q_{ego}''=\text{TransformerDecoder}(q,k,v,q_{pos},k_{pos}) \\ &q=Q_{ego}',\ k=v=Q_m,\\ &q_{pos}=\text{PE}_2 (p_{ego}),\ k_{pos}=\text{PE}_2(p_a). \end{split} \end{equation} Qego′′=TransformerDecoder(q,k,v,qpos,kpos)q=Qego′, k=v=Qm,qpos=PE2(pego), kpos=PE2(pa).
规划头
因为 VAD 所做的规划是不带高精地图的,因此需要高层级驾驶指令 c c c 来做导航。VAD 使用三种驾驶指令:左转、右转和直行。因此,规划头将 ( Q e g o ′ , Q e g o ′ ′ ) (Q_{ego}', Q_{ego}'') (Qego′,Qego′′) 和当前自车的状态 s e g o s_{ego} sego(可选的)作为自车特征 f e g o f_{ego} fego,以及指令 c c c 作为输入,输出规划轨迹 V ^ ∈ R T f × 2 \hat{V}\in\mathbb{R}^{T_f\times 2} V^∈RTf×2。VAD 使用一个简单的 MLP 规划头,解码过程如下所示:
V ^ e g o = PlanHead ( ft = f e g o , cmd = c ) , f e g o = [ Q e g o ′ , Q e g o ′ ′ , s e g o ] \begin{equation} \begin{split} &\hat{V}_{ego} = \text{PlanHead}(\text{ft}=f_{ego},\ \text{cmd}=c),\\ &f_{ego}=[Q_{ego}', Q_{ego}'', s_{ego}] \end{split} \end{equation} V^ego=PlanHead(ft=fego, cmd=c),fego=[Qego′,Qego′′,sego]
3. Vectorized Planning Constraint
基于地图矢量和运动矢量,VAD 在训练时通过实例级的矢量约束条件来正则化规划轨迹 V ^ e g o \hat{V}_{ego} V^ego,如下图所示。
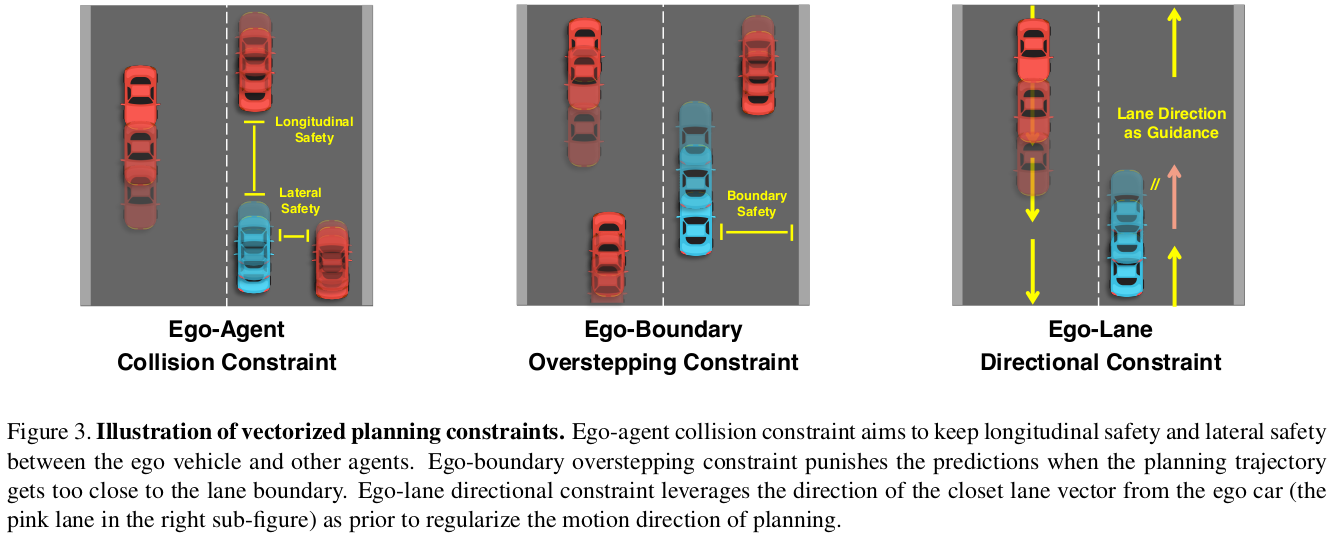
自车-其它交通参与者的碰撞约束
这个碰撞约束直接考虑了自车规划轨迹和其它车辆未来的轨迹之间的兼容性,提升规划的安全性,避免碰撞发生。之前的一些工作使用密集占用地图,而本文所使用矢量化的运动轨迹具有很强的可解释性,对算力要求也不高。作者首先通过一个阈值 ϵ a \epsilon_a ϵa 筛选出低置信度的参与者预测轨迹。对于多轨迹模态的运动预测,将置信度得分最高的那条轨迹作为最终的预测结果。本文将自车在横向和纵向上的安全距离作为碰撞约束。多台车可能在横向方向上靠的比较近,那么就需要在纵向方向上保持一段较安全的距离。因此,作者对不同的方向使用不同的距离阈值 δ X \delta_X δX 和 δ Y \delta_Y δY。关于未来的每个时间戳,我们在这两个方向上搜索在 δ a \delta_a δa 范围内最近的交通参与者。对于每个方向 i ∈ { X , Y } i\in \{X,Y\} i∈{X,Y},如果最近的交通参与者的距离 d a i d_a^i dai 小于阈值 δ i \delta_i δi,则这部分约束的损失项就是 L c o l i = δ i − d a i \mathcal{L}_{col}^i = \delta_i - d_a^i Lcoli=δi−dai,不然就是 0 0 0。自车-其它交通参与者的碰撞约束可以表述为:
L c o l = 1 T f ∑ t = 1 T f ∑ i L c o l i t , i ∈ { X , Y } , L c o l i t = { δ i − d a i t , if d a i t < δ i 0 , if d a i t ≥ δ i . \begin{equation} \begin{split} &\mathcal{L}_{col} = \frac{1}{T_f} \sum_{t=1}^{T_f} \sum_{i} \mathcal{L}_{col}^{it},\ i\in \{X,Y\}, \\ &\mathcal{L}_{col}^{it}=\left\{ \begin{array}{lr} \delta_i - d_a^{it},&\text{if} \ \ d_a^{it} < \delta_i & \\ 0, &\text{if} \ \ d_a^{it} \geq \delta_i. \end{array} \right. \end{split} \end{equation} Lcol=Tf1t=1∑Tfi∑Lcolit, i∈{X,Y},Lcolit={δi−dait,0,if dait<δiif dait≥δi.
自车-边界的越界约束
该约束的目的是迫使规划轨迹远离道路的边缘,这样轨迹能保持在可行驶区域里面。我们首先用阈值 ϵ m \epsilon_m ϵm 筛选出低置信度的地图预测。然后,对于每个未来时间戳,计算规划路径点和最近的地图边界线之间的距离 d b d t d_{bd}^t dbdt。那么,该项的损失就是:
L b d = 1 T f ∑ t = 1 T f L b d t , L c o l i t = { δ b d − d b d i t , if d b d t < δ b d 0 , if d b d t ≥ δ b d . \begin{equation} \begin{split} &\mathcal{L}_{bd} = \frac{1}{T_f} \sum_{t=1}^{T_f} \mathcal{L}_{bd}^{t}, \\ &\mathcal{L}_{col}^{it}=\left\{ \begin{array}{lr} \delta_{bd} - d_{bd}^{it},&\text{if} \ \ d_{bd}^{t} < \delta_{bd} & \\ 0, &\text{if} \ \ d_{bd}^{t} \geq \delta_{bd}. \end{array} \right. \end{split} \end{equation} Lbd=Tf1t=1∑TfLbdt,Lcolit={δbd−dbdit,0,if dbdt<δbdif dbdt≥δbd.
δ b d \delta_{bd} δbd 就是地图边界的阈值。
自车-车道线方向的约束
车辆的运动方向应该和该车所处的车道线方向保持一致,基于这个先验产生了自车和车道线方向的约束条件。该方向约束通过矢量化的车道线方向来正则化规划轨迹的运动方向。首先,通过阈值 ϵ m \epsilon_m ϵm 筛选出低置信度的地图预测。然后,找到距离每个时刻的预测路径点最近的分道线矢量 v ^ ∈ R T f × 2 × 2 \hat{v}\in \mathbb{R}^{T_f\times 2\times 2} v^∈RTf×2×2(在一定的范围 δ d i r \delta_{dir} δdir 内)。最后,该项损失就是不同时刻,自车矢量和车道线矢量的角度距离的平均值:
L d i r = 1 T f ∑ t = 1 T f F a n g ( v ^ m t , v ^ e g o t ) \begin{equation} \begin{split} &\mathcal{L}_{dir} = \frac{1}{T_f} \sum_{t=1}^{T_f} \text{F}_{ang}(\hat{v}_m^t, \hat{v}_{ego}^t) \end{split} \end{equation} Ldir=Tf1t=1∑TfFang(v^mt,v^egot)
v ^ e g o ∈ R T f × 2 × 2 \hat{v}_{ego} \in \mathbb{R}^{T_f \times 2\times 2} v^ego∈RTf×2×2 是规划的自车矢量。 v ^ e g o t \hat{v}_{ego}^t v^egot 表示从 t − 1 t-1 t−1 时刻的规划路径点指向 t t t 时刻的路径点的自车矢量。 F a n g \text{F}_{ang} Fang 表示矢量 v 1 v_1 v1 和矢量 v 2 v_2 v2 之间的角度距离。
4. End-to-End Learning
矢量化的场景学习损失
矢量化的场景学习包括矢量化地图学习和矢量化的运动预测。对于矢量化地图学习,采用了曼哈顿距离来计算预测地图点和 ground-truth 地图点之间的回归损失。此外,使用 focal loss 作为地图分类损失。整体损失记作 L m a p \mathcal{L}_{map} Lmap。
对于矢量化运动预测,使用 l 1 l_1 l1 损失作为回归损失,预测交通参与者的属性(位置、朝向角和大小等),用 focal loss 预测交通参与者的类别。对于每个与 ground-truth 匹配的交通参与者,预测 N k N_k Nk 条未来的轨迹,使用最终位移损失最低的那条轨迹作为预测值。然后,计算该预测轨迹和 ground-truth 轨迹的 l 1 l_1 l1 损失,作为运动回归损失。使用 focal loss 作为多模态运动的分类损失。整体的运动损失记作 L m o t \mathcal{L}_{mot} Lmot。
矢量化约束损失
矢量化的约束损失包括三项约束条件:自车-其它交通参与者的碰撞约束 L c o l \mathcal{L}_{col} Lcol、自车-边界的越界约束 L b d \mathcal{L}_{bd} Lbd、自车-车道线方向的约束 L d i r \mathcal{L}_{dir} Ldir,用矢量化场景表示对规划轨迹 V ^ e g o \hat{V}_{ego} V^ego做正则。
模仿学习损失
模仿学习损失 L i m i \mathcal{L}_{imi} Limi 是规划轨迹 V ^ e g o \hat{V}_{ego} V^ego 和 ground-truth 的自车轨迹 V e g o V_{ego} Vego 之间的 l 1 l_1 l1 损失,目的是用专家驾驶行为来指导规划轨迹。 L i m i \mathcal{L}_{imi} Limi 表示如下:
L i m i = 1 T f ∑ t = 1 T f ∥ V e g o t − V ^ e g o t ∥ 1 \begin{equation} \begin{split} &\mathcal{L}_{imi} = \frac{1}{T_f} \sum_{t=1}^{T_f} \left\| V_{ego}^t - \hat{V}^t_{ego} \right\|_1 \end{split} \end{equation} Limi=Tf1t=1∑Tf Vegot−V^egot 1
基于矢量化规划约束,VAD 可以做到端到端训练。整体损失是矢量化场景学习损失、矢量化规划约束损失和模仿学习损失的加权和:
L = ω 1 L m a p + ω 2 L m o t + ω 3 L c o l + ω 4 L b d + ω 5 L d i r + ω 6 L i m i \begin{equation} \begin{split} \mathcal{L} = &\omega_1 \mathcal{L}_{map} + \omega_2 \mathcal{L}_{mot} + \omega_3 \mathcal{L}_{col} +\\ &\omega_4 \mathcal{L}_{bd} + \omega_5 \mathcal{L}_{dir}+ \omega_6 \mathcal{L}_{imi} \end{split} \end{equation} L=ω1Lmap+ω2Lmot+ω3Lcol+ω4Lbd+ω5Ldir+ω6Limi
实验
作者在 nuScenes 数据集上进行了实验,该数据集包含 1000 段驾驶场景,每个场景大约 20 秒时长。nuScenes 提供了 140 万个 3D 框,属于 23 个类别。用 6 个相机采集了场景的图像,水平覆盖了 360 ° 360\degree 360° FOV,以 2Hz 的频率标注了关键帧。使用位移损失和碰撞率来综合评价规划的表现。
对于闭环设定,使用 CARLA 模拟器和 Town05 基准来做仿真。使用 Route Completion 和驾驶得分来评价规划的表现。
实现细节
VAD 基于两秒钟的历史信息,规划一个三秒钟的未来轨迹。使用 ResNet-50 作为主干网络,编码图像特征。VAD 在一个 60 m × 30 m 60m \times 30m 60m×30m 的纵向和横向距离的范围内做矢量化建图和运动预测。本文提供了两个版本的 VAD:VAD-Tiny 和 VAD-Base。VAD-Base 是实验的默认模型。BEV query、map query 和 agent query 的个数分别是 200 × 200 , 100 × 20 200\times 200, 100\times 20 200×200,100×20 和 300 300 300 个。总共有 100 100 100 个地图矢量 queries,每个包含 20 20 20 个地图点。特征维度和默认的隐藏大小是 256 256 256。与 VAD-Base 相比,VAD-Tiny 所拥有的 BEV queries 个数为 100 × 100 100\times 100 100×100。在运动和地图模块中,BEV 编码层和解码层的个数从 6 6 6 降到了 3 3 3,输入图像的尺寸从 1280 × 720 1280\times 720 1280×720 降低到了 640 × 360 640\times 360 640×360。
训练时,置信度阈值 ϵ a \epsilon_a ϵa 和 ϵ m \epsilon_m ϵm 设为 0.5 0.5 0.5,距离阈值 δ a \delta_a δa、 δ b d \delta_{bd} δbd 和 δ d i r \delta_{dir} δdir 设为了 3米、1米和2米。交通参与者的安全阈值 δ X \delta_X δX 和 δ Y \delta_Y δY 设为了 1.5米和3米。在训练 VAD 时,使用 AdamW 优化器和余弦退火,weight decay 为 0.01 0.01 0.01,初始学习率设为了 2 × 1 0 − 4 2\times 10^{-4} 2×10−4。在 8 张 GeForce RTX 3090 显卡上训练了 60 个 epochs,每张卡的 batch size 为 1。
用 VAD-Base 做闭环评测。输入图像大小是 640 × 320 640\times 320 640×320。导航信息包括一个稀疏的目的地坐标和对应的离散导航指令。用一个 MLP 编码这部分的导航信息,作为一个输入特征,被送入规划头。
此外,作者加入了一个交通灯识别分支,识别交通信号。它包括一个 ResNet-50 网络和一个 MLP 分类头。该分支的输入是裁剪后的前视图像,对应着图像的上中部分区域。对图像特征图做 flatten 操作,然后送入规划头,帮助模型感知到交通灯信息。
主要结果
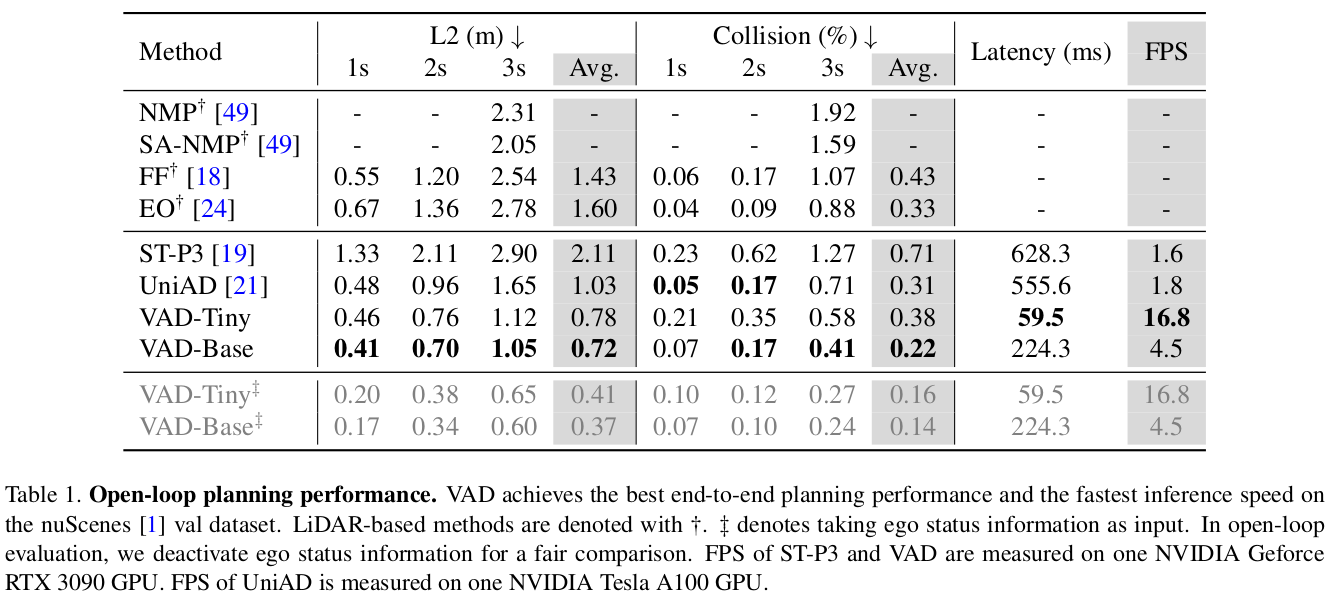
开环规划结果
如下表所示,和当前的 SOTA 方法相比,VAD 在速度和表现方面都具有优势。一方面,VAD-Tiny 和 VAD-Base 极大地降低了规划位移错误: 0.25 m 0.25m 0.25m和 0.31 m 0.31m 0.31m。同时,VAD-Base 降低了 29 % 29\% 29% 的碰撞率。另一方面,由于 VAD 不需要辅助任务(如跟踪和占用图预测)以及繁琐的后处理,它能实现最快的推理速度。VAD-Tiny 在保持准确率的同时,速度提升了 9.3 × 9.3\times 9.3×。VAD-Base 取得了最佳的规划表现,运行速度快了 2.5 × 2.5\times 2.5×。在开环规划任务,为了防止出现捷径学习,VAD 省略了自车的状态特征,但在下表中,仍然保留了使用自车状态特征的 VAD 结果。
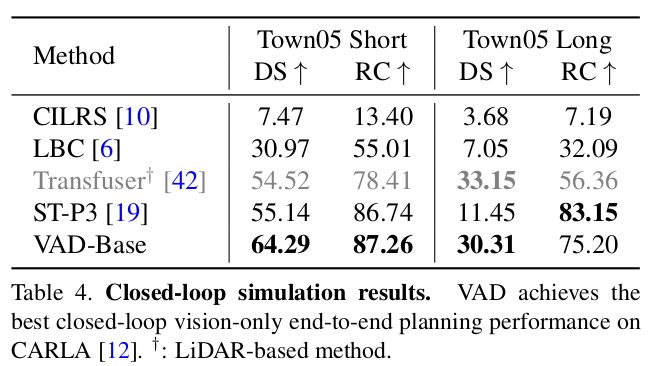
闭环规划结果
VAD 在 Town05 short 基准上,超越了当前 SOTA 的纯视觉端到端规划方法。与 ST-P3 相比,VAD 提升了 9.15 9.15 9.15 驾驶得分,并有着更优异的 Route Completion。在 Town05 Long 基准上,VAD 取得了 30.31 30.31 30.31 的驾驶得分,接近基于激光雷达的方法,并且显著地提升了 Route Completion(从 56.36 56.36 56.36 提升到了 75.2 75.2 75.2)。ST-P3 取得了更优异的 Route Completion,但是驾驶得分比较差。
消融实验
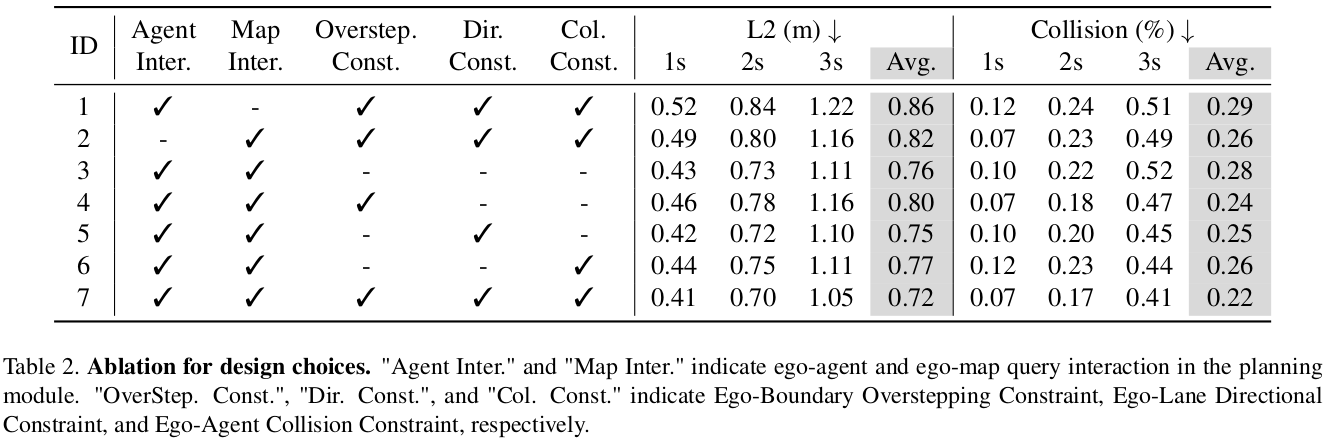
设计的有效性
下表展示了各设计选项的有效性。首先,地图能为规划提供重要的指导,如果没有自车和地图的交流(ID 1),则规划的距离错误就会很大。其次,自车和其它交通参与者的交流、自车和地图的交流能为自车 query 提供隐式的场景特征,这样自车能了解到其它车辆的驾驶意图,从而安全地规划轨迹。如果没有这些交流(ID 1-2),碰撞率会变得很高。最后,加入了任意的矢量化规划约束后(ID 4-6),碰撞率就会降低。当使用了三种碰撞约束后,VAD 实现了最低的碰撞率和最佳的规划准确率(ID 7)。
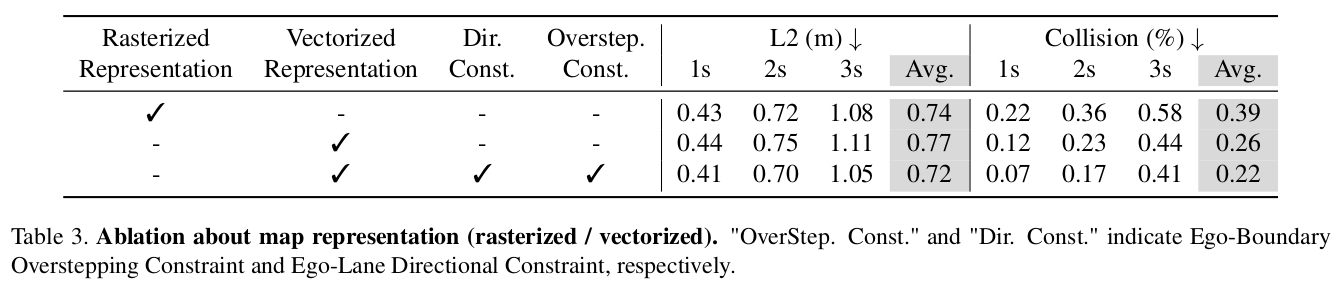
栅格化地图表示
在下表,作者展示了用栅格化地图表示的 VAD 变种。该 VAD 变种使用地图 queries 做 BEV 地图分割(而非矢量化地图检测),在规划 transformer 中使用更新后的地图 queries。如下表所示,使用栅格化地图表示的 VAD 的碰撞率很高。
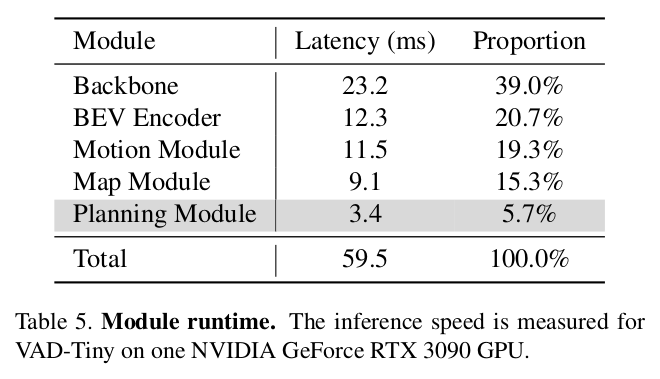
每个模块的运行时间
作者评测了 VAD-Tiny 的每个模块的运行时间,如下表所示。主干网络和 BEV 编码器占据了最多的运行时间,做特征提取和变换。运动模块和地图模块占据了 34.6 % 34.6\% 34.6% 的运行时间,完成多个参与者的矢量化运动预测和矢量化地图预测。得益于稀疏的矢量化表示和简洁设计,规划模块的运行时间只有 3.4 毫秒。
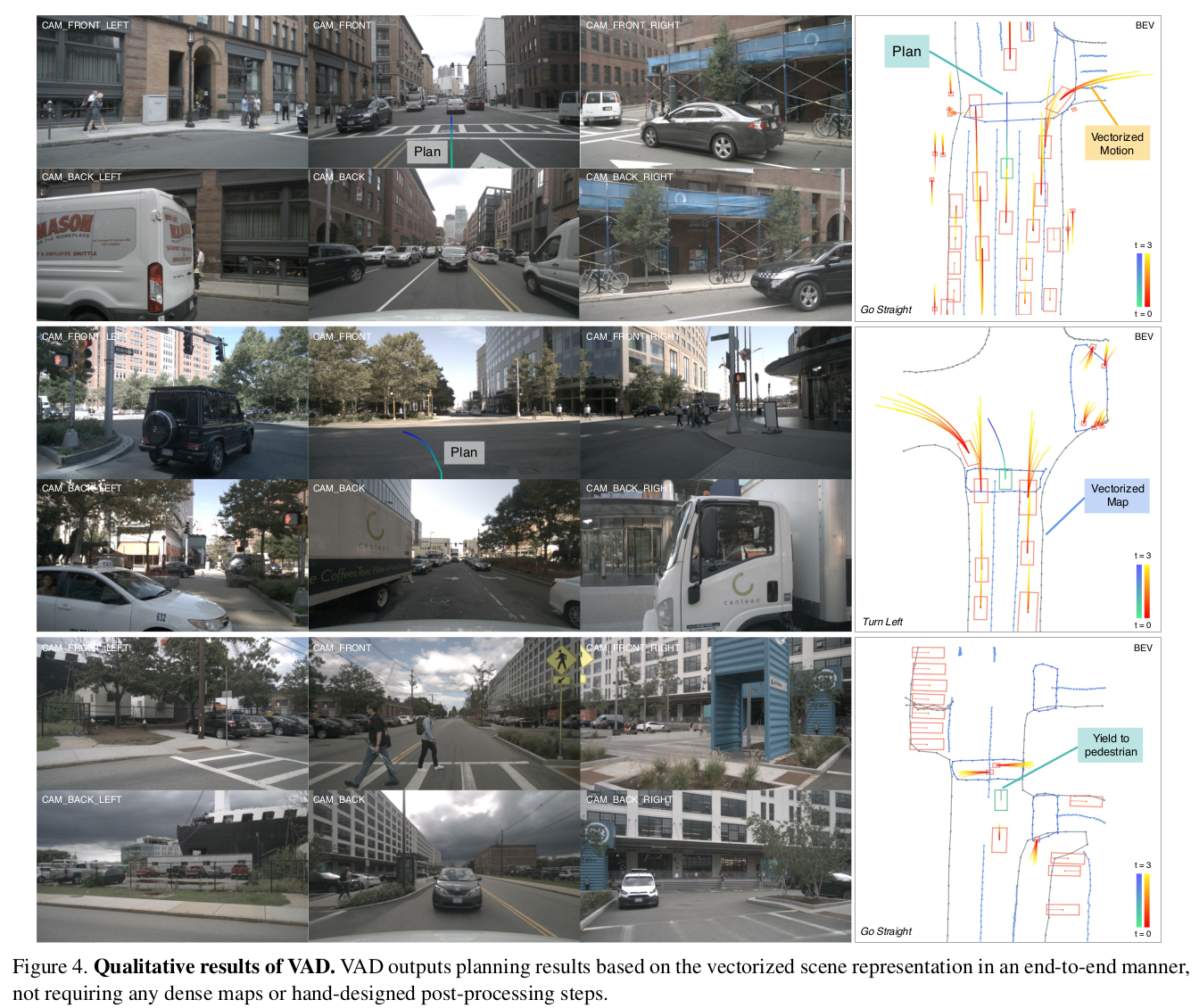
定性结果
在下图中,作者展示了 VAD 的矢量化场景学习和规划结果。为了更好地理解场景,作者也提供了环视相机的原始图像,将规划轨迹投影到前视画面。VAD 能准确地预测交通参与者的多模态的运动和地图元素,并能根据矢量化的场景表示规划出自车合理的未来轨迹。