目录
- 一、【PPA】注意力机制
- 1.1【PPA】注意力介绍
- 1.2【PPA】核心代码
- 二、添加【PPA】注意力机制
- 2.1STEP1
- 2.2STEP2
- 2.3STEP3
- 2.4STEP4
- 三、yaml文件与运行
- 3.1yaml文件
- 3.2运行成功截图
一、【PPA】注意力机制
1.1【PPA】注意力介绍

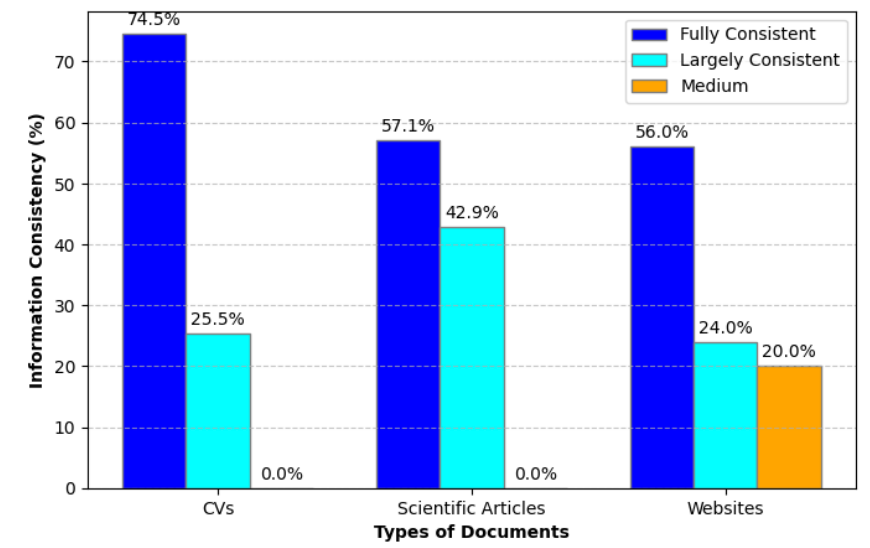
下图是PPA并行分块注意力机制结构图,大致分析一下工作流程和优势
-
工作流程
-
1.1 Patch-Aware 分支
输入的特征图大小为 𝐻′×𝑊′×𝐶。特征图通过 Pointwise Conv (PW Conv),它是一个 1×1 卷积,用来处理通道维度,改变每个通道上的信息。接下来,进入两个并行的 Patch-Aware 模块,分别使用不同的感受野大小 𝑝=2p=2 和 𝑝=4。这两个并行分支是为了捕获不同尺度下的局部信息。Patch-Aware 模块 通过以下步骤处理输入:
首先,输入的特征图被通过一个 Unfold 操作,这相当于将输入特征图划分成多个 𝑝×𝑝的局部块。然后对这些局部块进行求平均操作(Mean),获得局部感知特征。接着通过一个全连接层 FFN 和 Softmax 操作,为每个局部块生成注意力权重,最后进行 Feature Selection,即选择最重要的局部信息用于后续处理。 -
1.2 Attention 模块
Patch-Aware 模块 的输出与卷积层的输出进行相加,之后进入 Attention 模块 进行进一步处理。Attention 模块 包含 Channel Attention 和 Spatial Attention 两个部分:Channel Attention 计算每个通道的重要性,通过一个 1×1的卷积来生成权重,并与原特征进行逐元素相乘。Spatial Attention 则是关注空间维度的特征,通过计算每个空间位置的注意力权重来进一步加强特征。 -
1.3 输出
最终的特征图经过 Attention 模块后,生成的输出大小为 𝐻′×𝑊′×𝐶′,可以用于下游任务如分类或目标检测。 -
优势分析
-
2.1 多尺度感知
PPA 模块通过并行的 Patch-Aware 机制引入了不同的感受野,分别捕捉到小块和大块的局部特征。这种多尺度的感知能力使得模型能够同时关注局部细节和全局上下文信息,有助于处理多样化的输入数据。 -
2.2 强化特征选择
通过 Feature Selection,模块能够有效地选择重要的局部特征,并通过 Attention 机制在通道和空间维度进一步增强特征。这样能够显著提高模型的特征表达能力,尤其是在处理复杂场景时。 -
2.3 并行计算加速
该模块采用并行的 Patch-Aware 分支,同时处理不同尺度的信息,能够提高计算效率。与串行处理相比,并行结构使得模型在不增加太多计算负担的前提下,获得更丰富的特征表示。 -
2.4 通道和空间的自适应权重
Attention 模块提供了自适应的通道权重和空间权重,能够根据输入数据的不同动态调整特征的重要性。这种自适应性能够增强模型在处理不同任务时的灵活性,使其能够对特定任务或数据分布更具鲁棒性。

1.2【PPA】核心代码
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(
in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out * x
class LocalGlobalAttention(nn.Module):
def __init__(self, output_dim, patch_size):
super().__init__()
self.output_dim = output_dim
self.patch_size = patch_size
self.mlp1 = nn.Linear(patch_size * patch_size, output_dim // 2)
self.norm = nn.LayerNorm(output_dim // 2)
self.mlp2 = nn.Linear(output_dim // 2, output_dim)
self.conv = nn.Conv2d(output_dim, output_dim, kernel_size=1)
self.prompt = torch.nn.parameter.Parameter(
torch.randn(output_dim, requires_grad=True)
)
self.top_down_transform = torch.nn.parameter.Parameter(
torch.eye(output_dim), requires_grad=True
)
def forward(self, x):
x = x.permute(0, 2, 3, 1)
B, H, W, C = x.shape
P = self.patch_size
# Local branch
local_patches = x.unfold(1, P, P).unfold(2, P, P) # (B, H/P, W/P, P, P, C)
local_patches = local_patches.reshape(B, -1, P * P, C) # (B, H/P*W/P, P*P, C)
local_patches = local_patches.mean(dim=-1) # (B, H/P*W/P, P*P)
local_patches = self.mlp1(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.norm(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.mlp2(local_patches) # (B, H/P*W/P, output_dim)
local_attention = F.softmax(local_patches, dim=-1) # (B, H/P*W/P, output_dim)
local_out = local_patches * local_attention # (B, H/P*W/P, output_dim)
cos_sim = F.normalize(local_out, dim=-1) @ F.normalize(
self.prompt[None, ..., None], dim=1
) # B, N, 1
mask = cos_sim.clamp(0, 1)
local_out = local_out * mask
local_out = local_out @ self.top_down_transform
# Restore shapes
local_out = local_out.reshape(
B, H // P, W // P, self.output_dim
) # (B, H/P, W/P, output_dim)
local_out = local_out.permute(0, 3, 1, 2)
local_out = F.interpolate(
local_out, size=(H, W), mode="bilinear", align_corners=False
)
output = self.conv(local_out)
return output
class ECA(nn.Module):
def __init__(self, in_channel, gamma=2, b=1):
super(ECA, self).__init__()
k = int(abs((math.log(in_channel, 2) + b) / gamma))
kernel_size = k if k % 2 else k + 1
padding = kernel_size // 2
self.pool = nn.AdaptiveAvgPool2d(output_size=1)
self.conv = nn.Sequential(
nn.Conv1d(
in_channels=1,
out_channels=1,
kernel_size=kernel_size,
padding=padding,
bias=False,
),
nn.Sigmoid(),
)
def forward(self, x):
out = self.pool(x)
out = out.view(x.size(0), 1, x.size(1))
out = self.conv(out)
out = out.view(x.size(0), x.size(1), 1, 1)
return out * x
class conv_block(nn.Module):
def __init__(
self,
in_features,
out_features,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
dilation=(1, 1),
norm_type="bn",
activation=True,
use_bias=True,
groups=1,
):
super().__init__()
self.conv = nn.Conv2d(
in_channels=in_features,
out_channels=out_features,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
bias=use_bias,
groups=groups,
)
self.norm_type = norm_type
self.act = activation
if self.norm_type == "gn":
self.norm = nn.GroupNorm(
32 if out_features >= 32 else out_features, out_features
)
if self.norm_type == "bn":
self.norm = nn.BatchNorm2d(out_features)
if self.act:
# self.relu = nn.GELU()
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
if self.norm_type is not None:
x = self.norm(x)
if self.act:
x = self.relu(x)
return x
class PPA(nn.Module):
def __init__(self, in_features, filters) -> None:
super().__init__()
self.skip = conv_block(
in_features=in_features,
out_features=filters,
kernel_size=(1, 1),
padding=(0, 0),
norm_type="bn",
activation=False,
)
self.c1 = conv_block(
in_features=in_features,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type="bn",
activation=True,
)
self.c2 = conv_block(
in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type="bn",
activation=True,
)
self.c3 = conv_block(
in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type="bn",
activation=True,
)
self.sa = SpatialAttentionModule()
self.cn = ECA(filters)
self.lga2 = LocalGlobalAttention(filters, 2)
self.lga4 = LocalGlobalAttention(filters, 4)
self.bn1 = nn.BatchNorm2d(filters)
self.drop = nn.Dropout2d(0.1)
self.relu = nn.ReLU()
self.gelu = nn.GELU()
def forward(self, x):
x_skip = self.skip(x)
x_lga2 = self.lga2(x_skip)
x_lga4 = self.lga4(x_skip)
x1 = self.c1(x)
x2 = self.c2(x1)
x3 = self.c3(x2)
x = x1 + x2 + x3 + x_skip + x_lga2 + x_lga4
x = self.cn(x)
x = self.sa(x)
x = self.drop(x)
x = self.bn1(x)
x = self.relu(x)
return x
if __name__ == "__main__":
block = PPA(64, 64)
input = torch.rand(3, 64, 128, 128)
output = block(input)
print(input.size())
print(output.size())
二、添加【PPA】注意力机制
2.1STEP1
首先找到ultralytics/nn文件路径下新建一个Add-module的python文件包【这里注意一定是python文件包,新建后会自动生成_init_.py】,如果已经跟着我的教程建立过一次了可以省略此步骤,随后新建一个PPA.py文件并将上文中提到的注意力机制的代码全部粘贴到此文件中,如下图所示
2.2STEP2
在STEP1中新建的_init_.py文件中导入增加改进模块的代码包如下图所示
2.3STEP3
找到ultralytics/nn文件夹中的task.py文件,在其中按照下图添加
2.4STEP4
定位到ultralytics/nn文件夹中的task.py文件中的def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)函数添加如图代码,【如果不好定位可以直接ctrl+f搜索定位】

三、yaml文件与运行
3.1yaml文件
以下是添加【PPA】注意力机制在最小层检测头中的yaml文件,大家可以注释自行调节,效果以自己的数据集结果为准
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1,1,PPA,[256]]
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
以上添加位置仅供参考,具体添加位置以及模块效果以自己的数据集结果为准 ,同时中目标检测层中参数为[512],大目标检测层中参数为[1024]
3.2运行成功截图

OK 以上就是添加【PPA】注意力机制的全部过程了,后续将持续更新尽情期待