iText2KG是一个基于大型语言模型的增量知识图谱构建工具,通过从文本文档中提取实体和关系来逐步构建知识图谱。该工具具有零样本学习能力,能够在无需特定训练的情况下,在多个领域中进行知识提取。它包括文档提炼、实体提取和关系提取模块,最终将提取的知识集成到Neo4j中进行可视化。
iText2KG解决了在将实体列表和上下文传递给 LLM 时,使用 LLM 进行 KG 构建时出现的两个主要 LLM 幻觉问题。这些问题是:
-
LLM 可能会虚构所提供的实体列表中不存在的实体。我们通过用输入实体列表中最相似的实体替换虚构的实体来处理此问题。
-
LLM 可能无法从输入实体列表中为某些实体分配关系,从而导致“遗忘效应”。我们通过重新提示 LLM 提取这些实体的关系来处理这个问题。

相关链接
论文地址:https://arxiv.org/pdf/2409.03284
代码地址:https://github.com/AuvaLab/itext2kg
论文阅读

iText2KG:使用大型语言模型构建增量知识图谱
摘要
大多数可用数据都是非结构化的,因此很难获取有价值的信息。自动构建知识图谱 (KG) 对于结构化数据和使其可访问至关重要,可让用户有效地搜索信息。KG 还有助于洞察、推理和推理。传统的 NLP 方法(例如命名实体识别和关系提取)是信息检索的关键,但面临局限性,包括使用预定义的实体类型和需要监督学习。当前的研究利用大型语言模型的功能,例如零次或少量学习。然而,未解决和语义重复的实体和关系仍然带来挑战,导致图表不一致并需要大量的后处理。此外,大多数方法都依赖于主题。在本文中,我们提出了 iText2KG3,这是一种无需后处理的增量、主题独立的 KG 构建方法。这种即插即用的零样本方法适用于广泛的知识图谱构建场景,包括四个模块:文档提取器、增量实体提取器、增量关系提取器以及图形集成器和可视化。我们的方法在三个场景中表现出比基线方法更好的性能:将科学论文转换为图形、将网站转换为图形以及将简历转换为图形。
方法
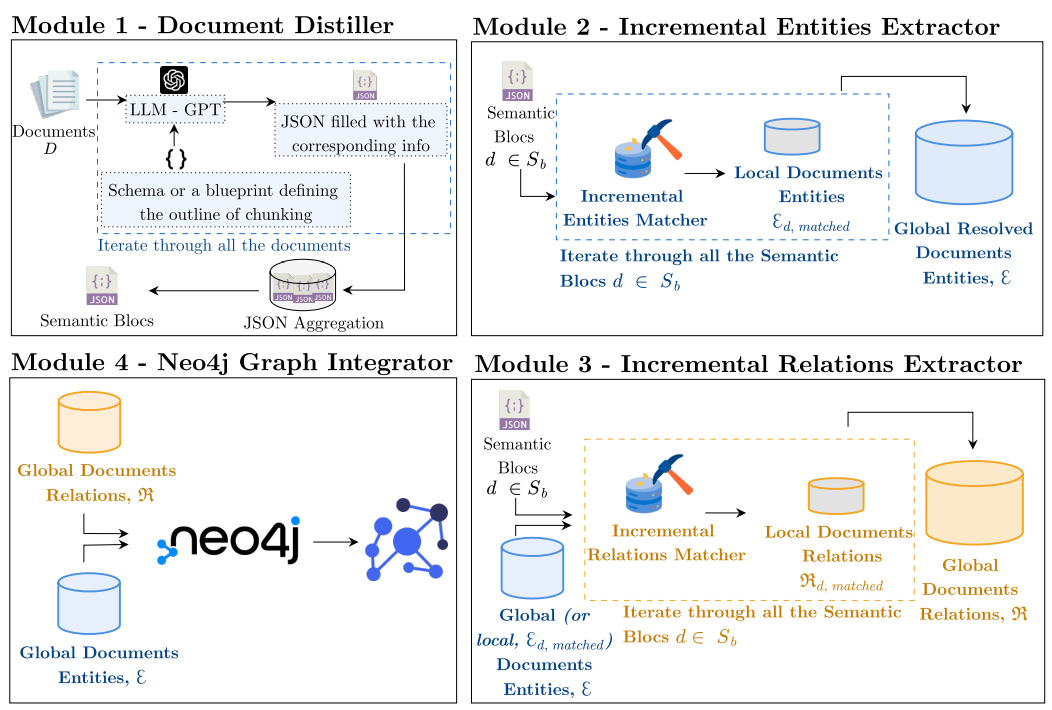
总体架构
该iText2KG软件包由四个主要模块组成,它们协同工作,从非结构化文本构建和可视化知识图谱。整体架构概述:
-
文档提取器:该模块处理原始文档,并根据用户定义的模式将其重新表述为语义块。它通过关注相关信息并以预定义的格式对其进行结构化来提高信噪比。
-
增量实体提取器:此模块从语义块中提取唯一实体并解决歧义以确保每个实体都有明确定义。它使用余弦相似度度量将局部实体与全局实体进行匹配。
-
增量关系提取器:此模块识别提取实体之间的关系。它可以以两种模式运行:使用全局实体丰富图形中的潜在信息,或使用局部实体建立更精确的关系。
-
图形集成器和可视化:此模块将提取的实体和关系集成到 Neo4j 数据库中,提供知识图谱的可视化表示。它允许对结构化数据进行交互式探索和分析。

iEntities Matcher的算法
LLM 被提示提取代表一个唯一概念的实体,以避免语义混合的实体。下图显示了使用 Langchain JSON 解析器的实体和关系提取提示。它们分类如下:蓝色 - 由 Langchain 自动格式化的提示;常规 - 我们设计的提示;斜体 - 专门为实体和关系提取设计的提示。(a)关系提取提示和(b)实体提取提示。

实验
数据集
该数据集包括使用 GPT-4 生成的五份简历、五篇随机选择的代表不同研究领域且结构各异的科学文章,以及来自不同行业且规模各异的五个公司网站。此外,我们还根据预定义的模式包含了简历和科学文章的精简版本。
添加了另一个数据集,其中包含 1,500 个相似实体对和 500 个关系,灵感来自各个领域(例如新闻、科学文章、人力资源实践),以估计基于余弦相似度合并实体和关系的阈值。
下图中,我们为seasonal文章和公司公司构建了一个 KG,并获得了该公司公开发布的许可。此外,简历 (CV) KG 基于以下生成的 CV。
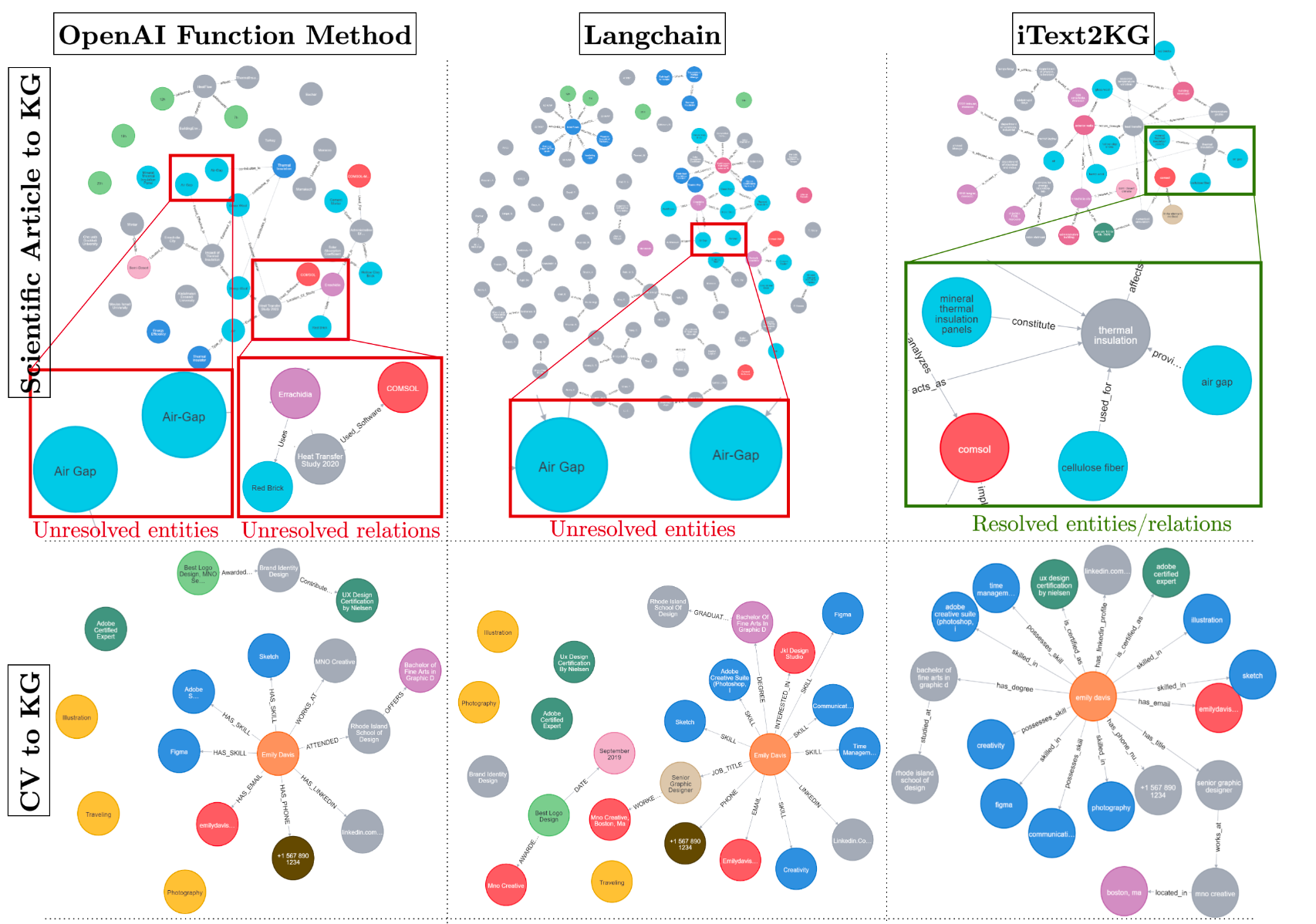
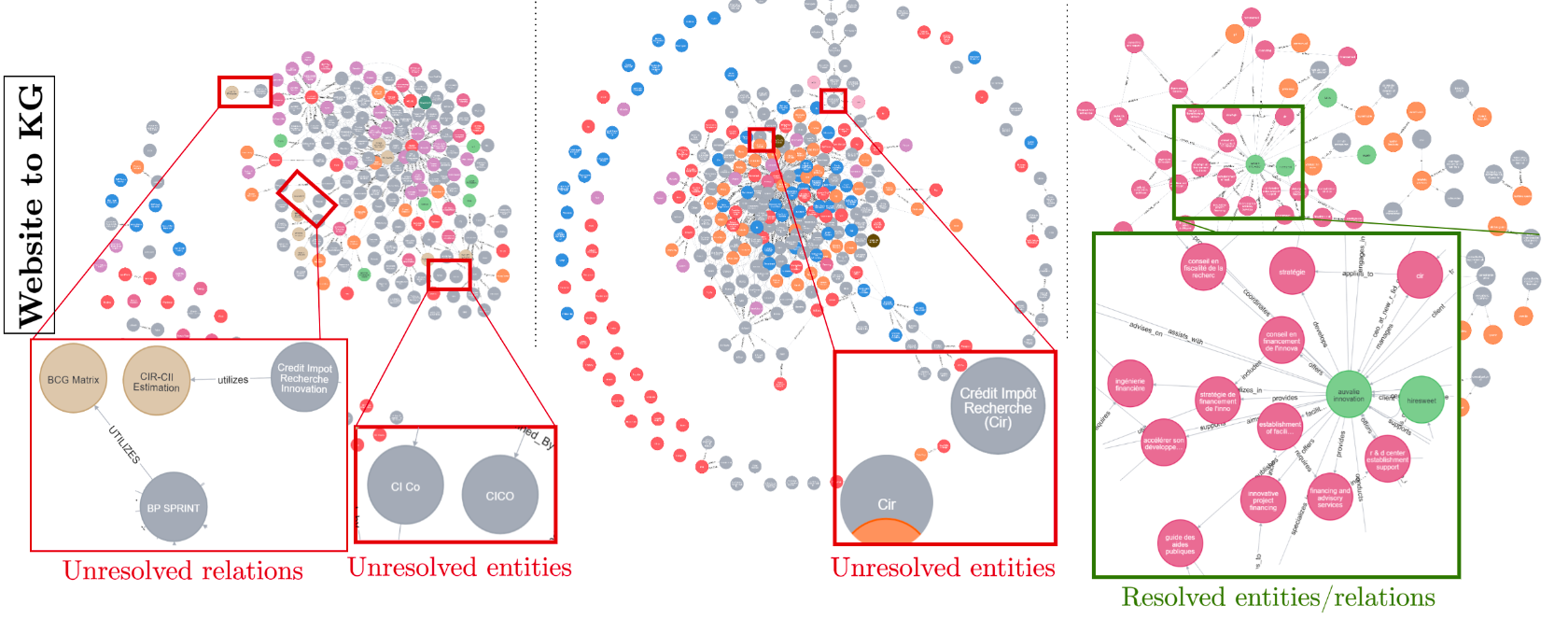
基线方法和iText2KG在三种情况下的KG构建比较。
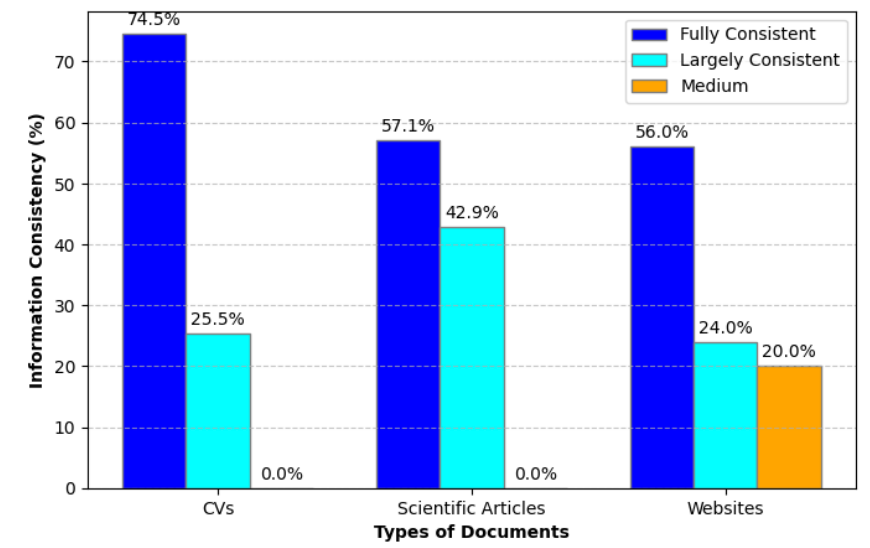
不同类型的信息一致性得分柱状图文档。
结论
本文介绍了 iText2KG,这是一种利用 LLM 的零样本能力进行增量式 KG 构建的方法。该方法解决了传统 KG 构建过程中固有的局限性,这些过程通常依赖于预定义的本体和广泛的监督训练。iText2KG 方法的一个关键优势是它的灵活性,这源于使用用户定义的蓝图,该蓝图概述了在 KG 构建过程中要提取的关键组件。这使得该方法能够适应广泛的场景,因为没有适用于所有用例的通用蓝图;相反,设计因具体应用而异。此外,iText2KG 方法通过使用灵活的用户定义蓝图来指导提取过程,实现了文档类型独立性,使其能够处理结构化和非结构化文本。











![[OS] 2.Wait for signal (do_wait),task_struct](https://i-blog.csdnimg.cn/direct/2311ae9d1fa046c1a365dc9b7c40c127.png)






