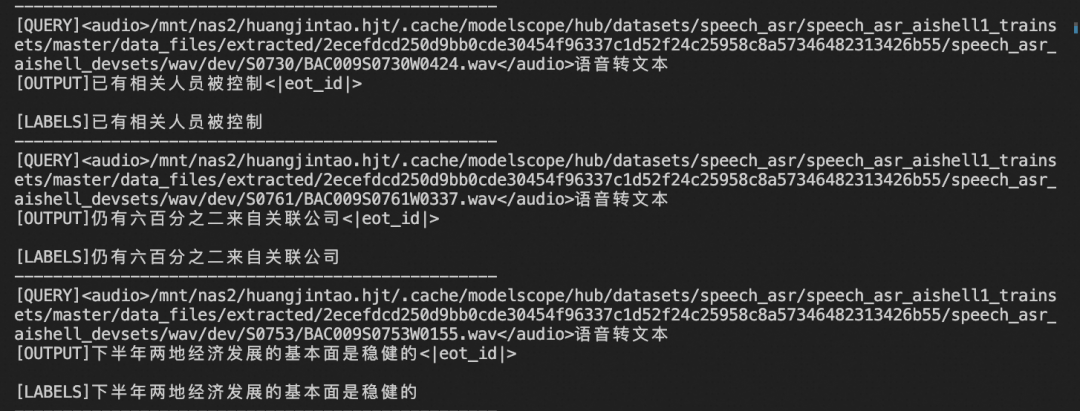
随着大模型的火热很多项目中都使用到了开源大模型,这时候准确评估大模型的GPU资源非常重要,主要有下面几个方面
成本效率:GPU是昂贵的资源。高估内存需求可能导致在硬件上的不必要支出,而低估则可能导致系统故障或性能下降。
性能优化:适当的内存管理确保模型高效运行,能够更快地响应用户并处理更多并发请求。
可扩展性:随着需求的增长,理解内存需求对于在不牺牲性能或产生高昂成本的情况下扩展服务至关重要。
尽管其重要性显而易见,但计算用于服务大型语言模型(LLM)的GPU内存并不简单。模型大小、序列长度、批处理大小和解码算法等因素以复杂的方式影响内存消耗。此外,传统的内存分配方法往往由于内存碎片化和动态内存组件(如键值(KV)缓存)的低效管理而导致大量浪费。
在本文中,我将尽力阐述用于服务大型语言模型(LLM)的GPU内存需求的计算过程。我会逐步分解导致内存占用的各个组成部分,并根据不同的模型参数和工作负载特性,提供指导以估算内存使用。此外,我还将探讨诸如Paged Attention和vLLM服务系统等先进的优化技术,这些技术能够显著减少内存消耗并提升吞吐量。通过本文,读者将全面了解如何规划和优化LLM的GPU内存使用,以实现实际应用中的高效且具成本效益的部署。
在深入探讨之前,我推荐大家阅读这篇优秀的论文《Efficient Memory Management for Large Language Model Serving with PagedAttention[1]》,该论文提供了详尽的视角和深入的技术分析。同时,我要指出,当前我对GPU内存需求估算的理解和方法在很大程度上借鉴了这篇论文的内容。此外,本文后续将探讨的其他参考资料也对这些见解的形成起到了重要作用。
理解LLM服务中的GPU内存组件
我认为理解GPU内存计算的最佳方式是从基本上了解不同组件如何消耗GPU内存。了解内存的去向有助于规划和优化资源。在LLM推理过程中,主要的GPU内存消耗者是权重(模型参数)、键值(KV)缓存内存、激活和临时缓冲区以及开销(您可能对并行处理或分布式计算中的开销有一定的直觉)。
1. 模型参数(权重)
模型参数是神经网络在训练过程中学到的数值(权重和偏置)。这些参数定义了模型如何处理输入数据以生成输出。
模型大小对GPU内存的影响
•直接关系:模型越大(参数越多),存储这些权重所需的GPU内存就越多。•内存计算:每个参数在使用半精度(FP16)格式时通常需要2字节,这在推理中很常见,因为它可以在不显著丧失精度的情况下节省内存。
让我们看一些模型大小的例子:
•考虑一个拥有3.45亿参数的小型LLM:
•所需内存:3.45亿 × 2字节 = 690 MB。这可以轻松地装在单个GPU上。
•如果我们以llama2-13b模型为例:
•拥有130亿参数,•所需内存:130亿 × 2字节 = 26 GB。在这种情况下,我们需要一块40 GB内存的A100 GPU。
•再看GPT-3,据称拥有1750亿参数:
•所需内存:1750亿 × 2字节 = 350 GB。•我们至少需要9块GPU才能容纳模型权重。
请记住,对于像GPT-3及更大模型,必须使用模型并行将模型分布在多个GPU上。
2. 键值(KV)缓存内存
KV缓存存储在生成序列中的每个token时所需的中间表示。简单来说,当模型一次生成一个token时,它需要记住先前的token以保持上下文。KV缓存存储迄今为止生成的每个token的键和值向量,使模型能够有效地关注过去的token,而无需重新计算它们。
工作原理:
•键和值:对于每个token,模型在注意力机制中计算一个键向量和一个值向量。•存储:这些向量存储在KV缓存中,并在后续步骤中用于生成新token。
序列长度和并发请求的影响:
•较长的序列:更多的token意味着KV缓存中的条目更多,增加了内存使用。•多用户:同时服务多个请求会成倍增加所需的KV缓存内存。
每个token的KV缓存大小计算
让我们分解如何得出每个token的KV缓存大小:
•每个token的KV缓存组成部分:
•键向量(每层一个键向量)和值向量(每层一个值向量)
•每个token的总向量数:
•层数(L):模型的深度•隐藏大小(H):每个向量的维度
以llama-13b模型为参考,假设模型具有:
•层数(L):40层•隐藏大小(H):5120维(适用于此规模的模型)
计算每个token的内存:
•键向量:
•总元素数:40层 × 5120维 = 204,800个元素•内存大小:204,800 × 2字节(FP16) = 409,600字节(约400 KB)
•值向量:
•与键向量相同:约400 KB
•每个token的KV缓存总量:
•键 + 值:400 KB + 400 KB = 800 KB
现在假设输出2000个token:
•800 KB/token × 2000token = 1.6 GB每个序列
如果有10个并发请求(为10个用户同时提供模型服务):
•1.6 GB/序列 × 10序列 = 16 GB KV缓存内存
KV缓存随着序列长度和并发请求数量线性增长。根据论文中的内容,KV缓存在LLM服务过程中可能占据GPU内存的30%或更多。
3. 激活和临时缓冲区
激活是推理过程中神经网络层的输出,临时缓冲区用于中间计算。激活和缓冲区通常消耗的内存比模型权重和KV缓存要少。
它们可能占用总GPU内存的约5-10%。
尽管其规模较小,激活仍然是模型在每层计算输出所必需的。它们在前向传递过程中被创建并丢弃,但仍需要足够的内存分配。
4. 内存开销
额外的内存使用源自内存分配和使用方式的低效。以下是简要概述:
碎片化:
•内部碎片化:当分配的内存块未被完全利用时发生。•外部碎片化:当空闲内存随着时间分割成小块时发生,使得在需要时难以分配较大的连续块。
中间计算:
•临时数据:矩阵乘法等操作可能会生成消耗内存的临时张量。
低效内存管理的影响:
•性能降低:浪费的内存可能限制系统可处理的并发请求数量。•吞吐量降低:低效可能导致延迟并降低为用户提供响应的整体速度。
示例:如果碎片化在40 GB GPU上浪费了20%的内存,则有8 GB的内存本可以用于服务更多请求。
计算GPU内存需求
现在我们对关键概念有了足够的理解,让我们计算完整的GPU内存需求。
逐步计算:
要计算任何模型的内存需求,我们基本需要以下内容:权重、KV缓存、激活和临时缓冲区以及开销。以llama-2 13B模型为参考,公式如下:
总所需内存 = 权重 + KV缓存 + 激活和开销
对于13B模型:
•权重 = 参数数量 × 每个参数的字节数•总KV缓存内存 = 每个token的KV缓存内存 × 序列长度 × 请求数量•激活和开销 = 总GPU内存的5-10%
激活和开销通常占模型参数和KV缓存总内存的5-10%。为了估算,可以分配总内存的额外10%。
具体计算:
•权重 = 130亿 × 2字节 = 26 GB•总KV缓存内存 = 800 KB × 8192token × 10并发请求 = 66 GB•激活和开销 = 0.1 × (26 GB + 66 GB) = 9.2 GB
(假设模型有8192个token,并有10个并发请求)
总所需内存 = 26 GB + 66 GB + 9.2 GB = 101.2 GB
因此,运行llama-2 13B模型至少需要3块40 GB的A100 GPU。
如果我想托管GPT-3模型,计算方法类似,但这次假设是单个请求,并以OPT-175B模型为参考。(96层,12288维)
•权重 = 1750亿 × 2字节 = 350 GB•总KV缓存内存 = 4.5 MB × 8192token × 1并发请求 = 36 GB•激活和开销 = 0.1 × (350 GB + 36 GB) = 38.6 GB
总所需内存 = 350 GB + 36 GB + 38.6 GB = 424.6 GB
几乎需要11块A100 GPU。
如果假设GPT-4是1万亿参数模型,在相同假设下,我将需要2.3 TB的内存。
根据公开的模型大小和参数信息,内存计算的表格如下:

类似地,如果我为许多用户部署一个模型(例如10个):

当处理多个请求时,内存消耗显著上升。其中一个主要组件是KV缓存,因为模型权重和开销保持不变,KV缓存随着token数和并发请求数量的增加而显著增长,这些矩阵的行数越多,内存消耗就直接增加。
GPU内存中的挑战及其优化方法
挑战1:内存碎片化和过度分配
在托管过程中,我们经常为KV缓存静态分配内存,为每个请求预留最大可能的空间。这导致了过度分配,因为系统为最长可能的序列预留空间,即使实际序列较短。
类似地,碎片化减少了有效可用内存,限制了系统可以同时处理的请求数量。我们有两种类型的内存碎片化:内部碎片化和外部碎片化。内部碎片化是指分配的内存块未被完全利用,留下未使用的空间。外部碎片化是指空闲内存随着时间被分割成小的、不连续的块,使得在需要时难以分配较大的连续块。
内存使用低效意味着GPU计算资源未被充分利用。因此,系统变成了内存绑定而不是计算绑定,浪费了潜在的处理能力(这是我们在并行或分布式设置中希望避免的)。
挑战2:解码算法
许多LLM应用程序经常使用先进的解码算法来提高输出质量或生成多个输出。虽然这些方法有益,但它们带来了额外的内存挑战。例如,Beam Search生成多个候选序列(束),并根据评分函数保留最优的那些。对于内存,每个束需要自己的KV缓存,增加了内存使用。此外,平行采样通过从模型的概率分布中采样同时生成多个独立的输出。每个平行采样需要自己的KV缓存,导致更高的内存消耗。
在动态内存分配的情况下,束或样本的数量可以在解码过程中变化,导致不可预测的内存需求。动态分配和释放内存而不导致碎片化或开销是具有挑战性的。另一个问题是,这些解码方法可能会成倍增加内存需求,有时超过GPU的容量。如果GPU内存耗尽,系统可能需要将数据迁移到较慢的CPU内存或磁盘上,从而增加延迟。
如何克服这些限制?
这时就需要引入PagedAttention和vLLM的概念了。
PagedAttention
受操作系统管理内存方式的启发,PagedAttention将虚拟内存分页的概念应用于KV缓存。这允许KV缓存数据存储在非连续的内存块(页面)中,而不需要一个大的连续块。PagedAttention通过动态内存分配工作,即按需分配KV缓存的内存,而不是预先分配最大序列长度。注意力机制可以无缝地从不同的内存位置检索KV缓存数据。
PagedAttention的好处:
•减少碎片化:通过使用较小的内存块,最小化因碎片化导致的空间浪费。•提高内存利用率。
vLLM
简单来说,vLLM是建立在PagedAttention之上的高吞吐量LLM服务系统,核心目的是在推理过程中高效管理GPU内存,特别是KV缓存。理论上,vLLM是一种近零内存浪费的解决方案。通过动态分配和非连续存储,它几乎消除了内存浪费。原则上,它还支持在请求内和请求之间共享KV缓存数据,对于先进的解码方法特别有用。基于这些,vLLM可以处理更大的批量和更多的并发请求,提升整体性能。
即使经过优化,仍可能出现GPU内存不足的情况。vLLM通过交换和再计算来解决这一问题。让我们仔细看看。
将KV缓存交换到CPU内存
交换:当GPU内存满时,临时将KV缓存数据从GPU内存移动到CPU内存。
好处:
•内存缓解:释放GPU内存以处理新请求。
权衡:
•延迟增加:从CPU内存访问数据比从GPU内存访问更慢。•数据传输开销:在CPU和GPU之间移动数据会消耗带宽和时间。
再计算
概念:
•不是存储所有KV缓存数据,而是在需要时按需重新计算。
好处:
•减少内存使用:需要存储的数据更少。
权衡:
•计算增加:需要额外的处理能力来重新计算数据。•延迟影响:由于额外的计算,可能导致响应时间更长。
交换与再计算的比较

在某些情况下,交换和再计算的组合可能提供最佳平衡。
基于本篇文章我写了一个大模型GPU资源计算器可以参考
https://github.com/liugddx/gpu_resource_calculator.git[2]
References
[1] Efficient Memory Management for Large Language Model Serving with PagedAttention: https://arxiv.org/pdf/2309.06180[2]: https://github.com/liugddx/gpu_resource_calculator.git[3] Efficient Memory Management for Large Language Model Serving with PagedAttention: https://arxiv.org/pdf/2309.06180[4] FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU: https://arxiv.org/pdf/2303.06865[5] LLM Inference Series: 4. KV caching, a deeper look: https://medium.com/@plienhar/llm-inference-series-4-kv-caching-a-deeper-look-4ba9a77746c8[6] Why 7, 13, 30B?: https://www.reddit.com/r/LocalLLaMA/comments/15514s1/why_7_13_30b/[7] GPU Requirements for LLMs: https://www.reddit.com/r/LocalLLaMA/comments/1agbf5s/gpu_requirements_for_llms/[8] Transformer Inference Arithmetic: https://kipp.ly/transformer-inference-arithmetic/[9] vllm-project: https://github.com/vllm-project[10] vllm: https://github.com/vllm-project/vllm













![[已解决] Install PyTorch 报错 —— OpenOccupancy 配环境](https://i-blog.csdnimg.cn/direct/fca3e40a722b4e61baf548b46a7d26fd.png)