最近这一两周看到不少互联网公司都已经开始秋招发放Offer。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
- 《大模型面试宝典》(2024版) 正式发布!
- 持续火爆!!!《AIGC 面试宝典》已圈粉无数!
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们
技术交流

随着GPT-4o的发布,在语音界面的Voice-Chat越来越受到大家的关注,对于低延迟,高准确性模型的speech-to-speech的需求日益增长,来自中科院计算所NLP组的LLaMA-Omni 有效的解决了这样的需求,该模型整合了预训练的语音编码器、语音adapter、LLM和流式语音解码器,并消除了对文本输出后再语音转录的需求,能够直接从语音指令中同时生成文本和语音响应。
研究团队使用最新的Llama-3.1-8B-Instruct模型构建了Llama-3.1-8B-Omni,同时构建了一个名为“InstructS2S-200K”的数据集,其中包含20万个语音指令及其对应的语音响应。实验结果表明,相比于之前的语音语言模型,LLaMA-Omni在内容和风格上提供了更好的响应,并且具有极低的响应延迟,仅为226毫秒。此外,训练LLaMA-Omni仅需要不到3天的时间,在只有4个GPU的情况下进行,为未来高效开发语音语言模型铺平了道路。
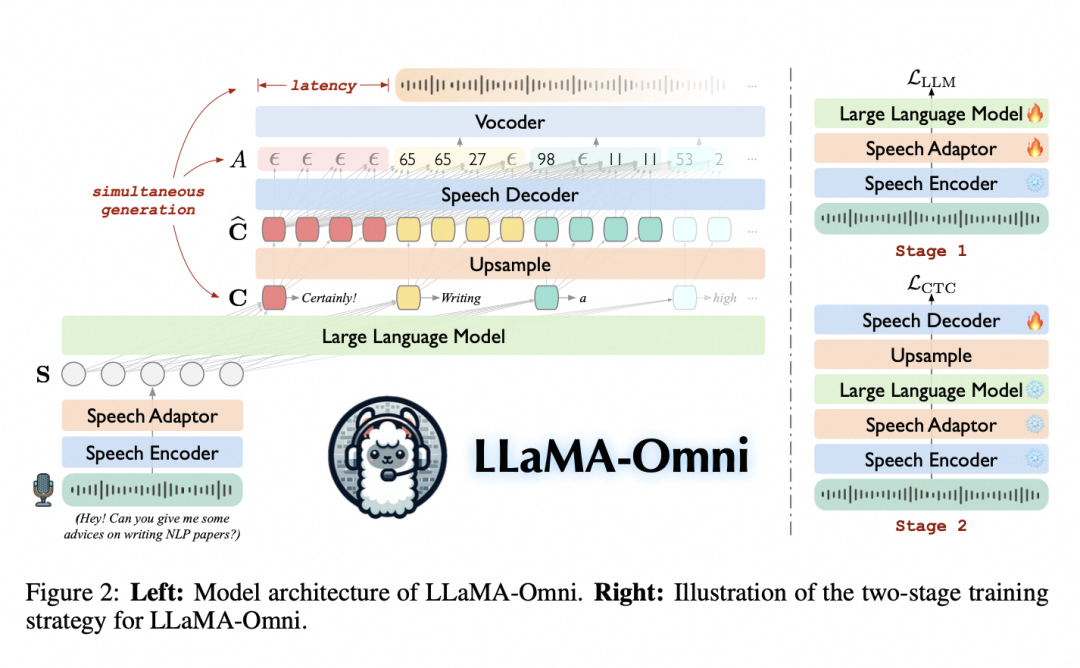
小编敲黑板,LLaMA-Omni 主要特点和进步:
高质量问答
基于LLaMA-3.1-8B训练,LLaMA-3.1-8B是同尺寸大小的比较领先的大语言模型,来确保回应质量高
同时语音和文本响应
LLaMA-Omni 能够根据用户语音输入生成语音和文本响应(如下图)。这使其成为语音助手或交互式代理等实时应用的理想选择。响应是同时生成的,无需繁琐的中间转录步骤,从而提高了对话的速度和流畅度。

低延迟
LLaMA-Omni 最令人印象深刻的功能是低延迟,其响应时间低至226 毫秒。这使其成为目前最快的语音对语音交互模型之一,可确保用户体验近乎即时的反馈。和传统的方式不同之处在于输出的时候不是先输出完文本再把文本转换成语音,而是流式的边输出文本边输出语音,类似人的同声传译,大幅度降低了延迟。
高效训练
LLaMA-Omni 不仅延迟低,开发效率也高,训练LLaMA-Omni仅需要不到3天的时间,在只有4个GPU的情况下进行,为未来高效开发语音语言模型铺平了道路,凸显了其对各类 AI 开发者和研究人员的可扩展性和可访问性。
优化数据集
构建了一个名为“InstructS2S-200K”的数据集,其中包含20万个语音指令及其对应的语音响应。此数据集确保模型高度适应处理各种语音输入并生成适当的上下文感知响应。
模型地址:
https://modelscope.cn/models/ICTNLP/Llama-3.1-8B-Omni
论文地址:
https://arxiv.org/abs/2409.06666
代码地址:
https://github.com/ictnlp/LLaMA-Omni
模型使用
下载代码repo
git clone https://github.com/ictnlp/LLaMA-Omni
cd LLaMA-Omni
安装Omni包
pip install pip==24.0
pip install -e .
安装fairseq
git clone https://github.com/pytorch/fairseq
cd fairseq
pip install -e . --no-build-isolation
安装flash-attention
pip install flash-attn --no-build-isolation
模型下载
下载Llama-3.1-8B-Omni
modelscope download --model=ICTNLP/Llama-3.1-8B-Omni --local_dir ./Llama-3.1-8B-Omni
下载whisper-large-v3
wget "https://modelscope.cn/models/ai-modelscope/large-v3.pt/resolve/master/large-v3.pt" -P models/speech_encoder/
下载HiFi-GAN vocoder.
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 -P vocoder/
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -P vocoder/
模型推理
要进行本地推理,请按照 omni_speech/infer/examples 目录中的格式组织语音指令文件,然后参考以下脚本。
bash omni_speech/infer/run.sh omni_speech/infer/examples
模型微调
我们使用ms-swift对Llama3.1-8B-Omni进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型微调部署框架。
ms-swift开源地址:
https://github.com/modelscope/ms-swift
这里展示可运行的demo,自定义数据集可以查看这里:https://swift.readthedocs.io/zh-cn/latest/Instruction/%E8%87%AA%E5%AE%9A%E4%B9%89%E4%B8%8E%E6%8B%93%E5%B1%95.html
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .[llm]
我们使用 aishell1-zh-mini 数据集:https://modelscope.cn/datasets/speech_asr/speech_asr_aishell1_trainsets 进行微调。
微调脚本:
# 默认:微调LLM和projector, 冻结vision encoder和generator
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type llama3_1-8b-omni \
--model_id_or_path ICTNLP/Llama-3.1-8B-Omni \
--sft_type lora \
--dataset aishell1-zh-mini#5000
# Deepspeed ZeRO2
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type llama3_1-8b-omni \
--model_id_or_path ICTNLP/Llama-3.1-8B-Omni \
--sft_type lora \
--dataset aishell1-zh-mini#5000 \
--deepspeed default-zero2
训练显存占用:

如果要使用自定义数据集,只需按以下方式进行指定:
# val_dataset可选,如果不指定,则会从dataset中切出一部分数据集作为验证集
--dataset train.jsonl \
--val_dataset val.jsonl \
自定义数据集格式如下,分别代表单音频、多音频和纯文本的格式:
{"query": "<audio>55555", "response": "66666", "audios": ["audio_path"]}
{"query": "<audio><audio>eeeee", "response": "fffff", "history": [], "audios": ["audio_path1", "audio_path2"]}
{"query": "query3", "response": "response3", "history": [["query1", "response1"], ["query2", "response2"]]}
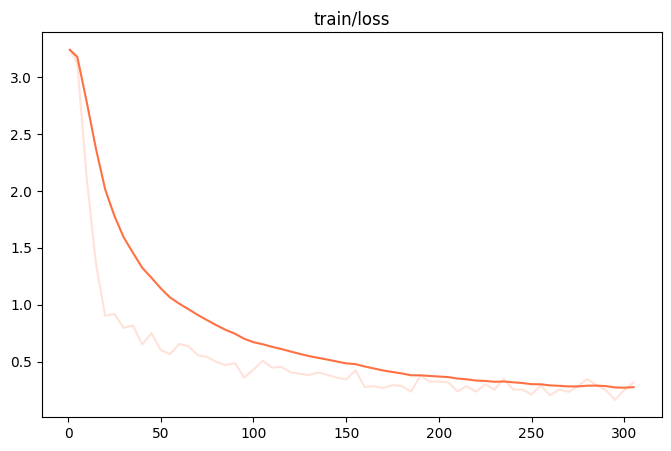
训练loss图:
微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的last_checkpoint文件夹。
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/llama3_1-8b-omni/vx-xxx/checkpoint-xxx \
--load_dataset_config true
# or merge-lora & infer
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/llama3_1-8b-omni/vx-xxx/checkpoint-xxx \
--load_dataset_config true --merge_lora true
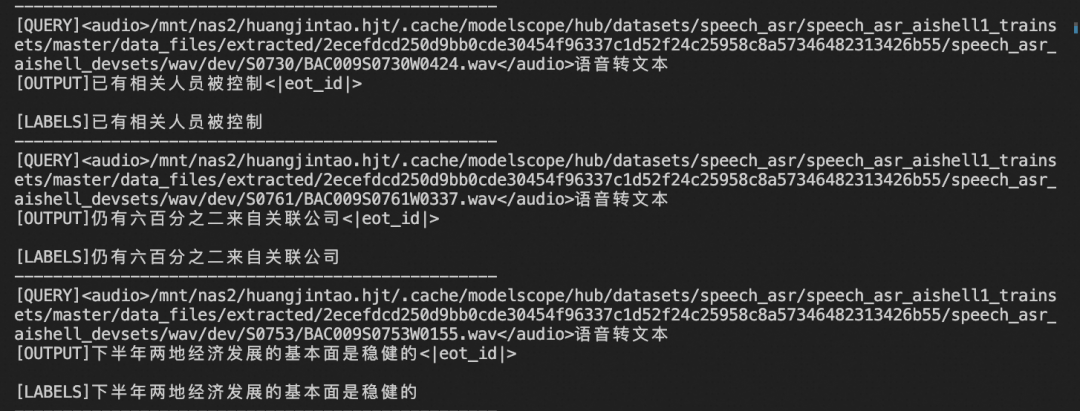
微调后模型对验证集进行推理的结果:












![[Linux][进程] 命令行参数](https://i-blog.csdnimg.cn/direct/2fa0157c28d84b7dbd538c78dd104442.png)