import pandas as pd # 读取CSV文件
data = pd.read_csv('stock_data.csv')# 查看前几行数据 print(data.head())
输出结果:
Date Open High Low Close Volume
02023-01-01100.000105.000098.00000104.0000123456712023-01-02104.000107.0000101.0000106.0000234567822023-01-03106.000110.0000104.0000109.0000345678932023-01-04109.000112.0000107.0000111.0000456789042023-01-05111.000115.0000110.0000114.00005678901
Date Open High Low Close Volume
02023-01-01100.000105.000098.00000104.0000123456712023-01-02104.000107.0000101.0000106.0000234567822023-01-03106.000110.0000104.0000109.0000345678932023-01-04109.000112.0000107.0000111.0000456789042023-01-05111.000115.0000110.0000114.00005678901
Date Open High Low Close Volume price_change
02023-01-010.000000.000000-0.0000000.0000000.0000000.00000012023-01-020.000000.000000-0.0000000.0000000.0000000.20000022023-01-030.000000.000000-0.0000000.0000000.0000000.28571432023-01-040.000000.000000-0.0000000.0000000.0000000.27272742023-01-050.000000.000000-0.0000000.0000000.0000000.269231
from sklearn.model_selection
import train_test_split
# 定义特征和目标变量
X = data[['Open','High','Low','Volume','price_change']]
y = data['Close']# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 查看划分后的数据集大小 print(f"Training set size: {len(X_train)}")print(f"Testing set size: {len(X_test)}")
CentOS7安装redis 首先解压压缩包 redis-7.0.0.tar.gz
tar -xvf redis-7.0.0.tar.gz接着进入到redis中
cd redis-7.0.0.tar.gz执行make命令编译
make接着执行安装命令
make install之后编译安装完后 程序都会在/usr/local/bin目录下 这里需要将在redis目录中redis.conf配置…
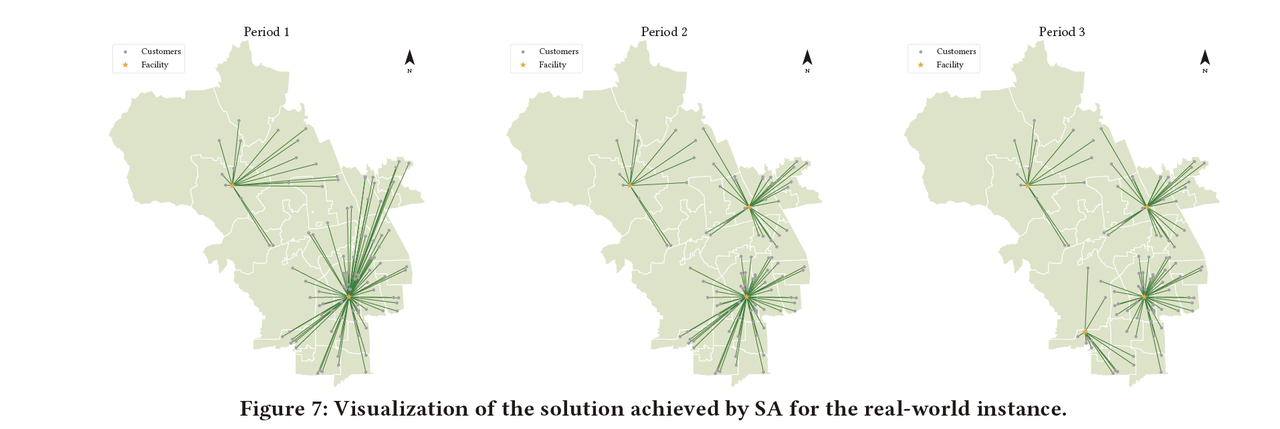
论文作者信息:Changhao Miao, Yuntian Zhang, Tongyu Wu, Fang Deng, and Chen Chen. 2024. Deep Reinforcement Learning for Multi-Period Facility Location: p k p_{k} pk-median Dynamic Location Problem. In The 32nd ACM International Conference on Ad…







![别再使用[]来获取字典的值了,来尝试一下这些方法](https://i-blog.csdnimg.cn/direct/3bf08b76f1224be6b7bfd5be66460ab1.png)